Recognition: 2 theorem links
· Lean TheoremSignal Reshaping for GRPO in Weak-Feedback Agentic Code Repair
Pith reviewed 2026-05-11 01:18 UTC · model grok-4.3
The pith
GRPO requires reshaping of outcome rewards, process signals, and rollout comparability to make within-group comparisons meaningful under weak feedback.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
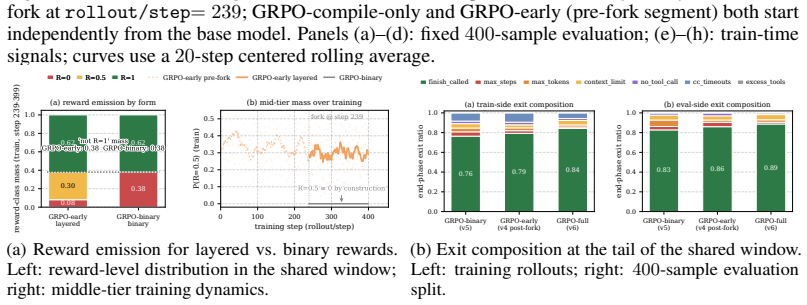
Our central claim is that GRPO's within-group comparison is meaningful only after three kinds of signals are reshaped: outcome rewards recover semantic ranking, process signals localize intra-trajectory credit, and rollouts from the same prompt remain execution-comparable. We operationalize these conditions with a minimal signal-reshaping construction that leaves GRPO's group-normalized advantage construction unchanged: compile-and-semantic layered rewards reshape trajectory ranking, step-level process scores outside group reward normalization reshape within-trajectory update strength, and failure-cause-aware rollout governance reshapes within-group comparability. Experiments show a clear 0.
What carries the argument
The minimal signal-reshaping construction (layered compile-and-semantic rewards, step-level process scores held outside group normalization, and failure-cause-aware rollout governance) that satisfies semantic ranking, intra-trajectory credit, and execution comparability while preserving GRPO's group-normalized advantage.
If this is right
- Binary rewards remove the compile-only middle tier and degrade trajectory control.
- Adding process-score weighting on top of layered rewards raises accuracy from 0.48 to 0.53 and cuts average evaluation steps from 23.50 to 17.02.
- Privileged-prompt token-level distillation optimizes only local distributional alignment and is diluted by non-critical tokens in long tool-use trajectories.
Where Pith is reading between the lines
- The same three-condition reshaping logic could be tested in other weak-feedback agentic domains such as API orchestration or mathematical proof search.
- Automating the failure-cause detection step would remove the need for hand-crafted governance rules and allow scaling across tasks.
- Keeping process scores outside group normalization may reduce variance in credit assignment for any RL setting that uses variable-length trajectories.
Load-bearing premise
The minimal signal-reshaping construction successfully achieves the three reshaping conditions without introducing new biases or requiring privileged information.
What would settle it
Running the same base model and GRPO optimizer with the proposed layered rewards and process scores but observing no accuracy gain over the unreshaped baseline, or finding that reshaped groups show lower execution comparability than unreshaped groups, would falsify the claim.
Figures




read the original abstract
Code-agent RL often receives weak feedback: rollout-time signals are reliable and executable, but capture only necessary or surface conditions for task success rather than the target semantic predicate. Using agentic compile-fix as the setting, we study signal reshaping for standard GRPO under such feedback. Our central claim is that GRPO's within-group comparison is meaningful only after three kinds of signals are reshaped: outcome rewards recover semantic ranking, process signals localize intra-trajectory credit, and rollouts from the same prompt remain execution-comparable. We operationalize these conditions with a minimal signal-reshaping construction that leaves GRPO's group-normalized advantage construction unchanged: compile-and-semantic layered rewards reshape trajectory ranking, step-level process scores outside group reward normalization reshape within-trajectory update strength, and failure-cause-aware rollout governance reshapes within-group comparability. Experiments show a clear end-to-end gain: full signal-reshaped GRPO improves strict compile-and-semantic accuracy from the base model's zero-shot $0.385$ to $0.535$. Controlled comparisons further explain the source of this gain: binary rewards remove the compile-only middle tier and degrade trajectory control; on top of layered rewards, process-score weighting further improves accuracy from $0.48$ to $0.53$ and reduces average evaluation steps from $23.50$ to $17.02$. As a boundary comparison, privileged-prompt token-level distillation mainly optimizes local distributional alignment; in long tool-use trajectories, this signal is diluted by non-critical tokens and cannot replace outcome semantics, process credit, or within-group comparability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that for GRPO in weak-feedback agentic code repair, within-group comparisons require reshaping of three signal types: outcome rewards to recover semantic ranking, process signals to localize intra-trajectory credit, and rollouts to ensure execution comparability. It presents a minimal construction using compile-and-semantic layered rewards, step-level process scores outside normalization, and failure-cause-aware governance, and reports empirical improvements in strict accuracy from 0.385 to 0.535, with ablations attributing gains to each component.
Significance. If validated, the work offers a targeted approach to making group-relative policy optimization effective in settings with partial or surface-level feedback, common in code agents. The ablations and comparison to distillation provide useful insights into signal design, potentially influencing RL applications in program synthesis and repair.
major comments (1)
- [Abstract and Experiments] The central necessity claim—that GRPO within-group comparison is meaningful 'only after' the three reshaping conditions—is supported indirectly via end-to-end accuracy gains and partial ablations (e.g., binary rewards degrade control, process scores improve from 0.48 to 0.53 accuracy). However, no direct diagnostics are presented, such as pre/post-reshaping correlations between rewards and semantic success or within-group advantage variance under raw vs. reshaped signals, leaving the 'only after' as an inference rather than verified precondition.
minor comments (2)
- [Abstract] The description of the privileged-prompt token-level distillation as a boundary comparison could benefit from more detail on how it was implemented to allow replication.
- [Abstract] Clarify if the accuracy numbers (0.385, 0.535, 0.48, 0.53) are from the same test set and include standard deviations or statistical significance.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive evaluation of the work's potential contributions to signal design in RL for code agents. We respond to the major comment below and outline revisions to address the concern.
read point-by-point responses
-
Referee: The central necessity claim—that GRPO within-group comparison is meaningful 'only after' the three reshaping conditions—is supported indirectly via end-to-end accuracy gains and partial ablations (e.g., binary rewards degrade control, process scores improve from 0.48 to 0.53 accuracy). However, no direct diagnostics are presented, such as pre/post-reshaping correlations between rewards and semantic success or within-group advantage variance under raw vs. reshaped signals, leaving the 'only after' as an inference rather than verified precondition.
Authors: We appreciate the referee's point that the necessity of the three reshaping conditions for meaningful GRPO within-group comparisons is currently evidenced indirectly through end-to-end gains and ablations. The controlled experiments (binary rewards removing the middle tier and degrading control; process scores lifting accuracy from 0.48 to 0.53 while reducing steps) isolate each component's role, consistent with the claim that reshaping is required before within-group comparisons become reliable under weak feedback. We agree, however, that direct diagnostics would provide stronger verification. In the revised manuscript we will add pre/post-reshaping analysis of within-group advantage variance and correlations between (raw vs. reshaped) rewards and semantic success, using the existing experimental setup. revision: yes
Circularity Check
No circularity: empirical gains from signal reshaping do not reduce to fitted inputs or self-referential derivations
full rationale
The paper presents its central claim as a hypothesis about the conditions under which GRPO within-group comparisons become meaningful, then operationalizes a minimal reshaping construction (layered rewards, step-level process scores, failure-cause-aware governance) that explicitly leaves GRPO's group-normalized advantage unchanged. All reported results are end-to-end accuracy lifts and ablation comparisons (0.385→0.535, binary vs. layered rewards, process-score weighting) rather than any closed-form derivation, parameter fit, or prediction that equals its own inputs by construction. No equations are given that would allow a self-definitional reduction, no fitted parameters are renamed as predictions, and no self-citations are used to justify uniqueness or load-bearing premises. The work is therefore self-contained against external benchmarks (base model zero-shot and controlled ablations) with no circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Rollout-time signals are reliable and executable but capture only necessary or surface conditions for task success rather than the target semantic predicate.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearOur central claim is that GRPO's within-group comparison is meaningful only after three kinds of signals are reshaped: outcome rewards recover semantic ranking, process signals localize intra-trajectory credit, and rollouts from the same prompt remain execution-comparable.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclearlayered rewards reshape outcome ranking, step-level process scores reshape intra-trajectory credit, and rollout governance reshapes within-group comparability
Reference graph
Works this paper leans on
-
[1]
On-policy distillation of language models: Learning from self-generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. InThe Twelfth International Conference on Learning Representations,
-
[2]
URLhttps://openreview.net/forum?id=3zKtaqxLhW
-
[3]
Concrete Problems in AI Safety
Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman, and Dan Mané. Concrete problems in AI safety.arXiv preprint arXiv:1606.06565, 2016
work page internal anchor Pith review arXiv 2016
-
[4]
Zimin Chen, Steve James Kommrusch, Michele Tufano, Louis-Noel Pouchet, Denys Poshy- vanyk, and Martin Monperrus. SEQUENCER: Sequence-to-sequence learning for end-to-end program repair.IEEE Transactions on Software Engineering, 2021. doi: 10.1109/TSE.2019. 2940179. URLhttps://doi.org/10.1109/TSE.2019.2940179
-
[5]
Jie Cheng, Gang Xiong, Ruixi Qiao, Lijun Li, Chao Guo, Junle Wang, Yisheng Lv, and Fei-Yue Wang. Stop summation: Min-form credit assignment is all process reward model needs for reasoning.arXiv preprint arXiv:2504.15275, 2025
-
[6]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Shirong Ma, Mingchuan Zhang, et al. DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning.Nature, 645(8081):633–638, September 2025. doi: 10.1038/s41586-025-09422-z
-
[7]
StepCoder: Improving code generation with reinforcement learning from compiler feedback
Shihan Dou, Yan Liu, Haoxiang Jia, Enyu Zhou, Limao Xiong, Junjie Shan, Caishuang Huang, Xiao Wang, Xiaoran Fan, Zhiheng Xi, Yuhao Zhou, Tao Ji, Rui Zheng, Qi Zhang, Tao Gui, and Xuanjing Huang. StepCoder: Improving code generation with reinforcement learning from compiler feedback. InProceedings of the 62nd Annual Meeting of the Association for Computati...
work page 2024
-
[8]
Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes
Yuqian Fu, Haohuan Huang, Kaiwen Jiang, Yuanheng Zhu, and Dongbin Zhao. Revisiting on- policy distillation: Empirical failure modes and simple fixes.arXiv preprint arXiv:2603.25562, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Training long-context, multi-turn software engineering agents with reinforcement learning, 2025
Alexander Golubev, Maria Trofimova, Sergei Polezhaev, Ibragim Badertdinov, Maksim Nekra- shevich, Anton Shevtsov, Simon Karasik, Sergey Abramov, Andrei Andriushchenko, Filipp Fisin, Sergei Skvortsov, and Boris Yangel. Training long-context, multi-turn software engineer- ing agents with reinforcement learning.arXiv preprint arXiv:2508.03501, 2025
-
[10]
Yuki Ichihara, Yuu Jinnai, Tetsuro Morimura, Mitsuki Sakamoto, Ryota Mitsuhashi, and Eiji Uchibe. MO-GRPO: Mitigating reward hacking of group relative policy optimization on multi-objective problems.arXiv preprint arXiv:2509.22047, 2026
-
[11]
CURE: Code-aware neural machine translation for automatic program repair
Nan Jiang, Thibaud Lutellier, and Lin Tan. CURE: Code-aware neural machine translation for automatic program repair. In2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE), pages 1161–1173, 2021. doi: 10.1109/ICSE43902.2021.00107. URL https://doi.org/10.1109/ICSE43902.2021.00107
-
[12]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. SWE-bench: Can language models resolve real-world github issues? InThe Twelfth International Conference on Learning Representations, 2024. URL https: //openreview.net/forum?id=VTF8yNQM66
work page 2024
-
[13]
Search-r1: Training LLMs to reason and leverage search engines with reinforcement learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan O Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-r1: Training LLMs to reason and leverage search engines with reinforcement learning. InSecond Conference on Language Modeling, 2025. URL https://openreview.net/forum?id=Rwhi91ideu
work page 2025
-
[14]
Kimi K2.5: Visual Agentic Intelligence
Kimi Team. Kimi K2.5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
Hung Le, Yue Wang, Akhilesh Deepak Gotmare, Silvio Savarese, and Steven C. H. Hoi. CodeRL: Mastering code generation through pretrained models and deep reinforcement learning. In Advances in Neural Information Processing Systems (NeurIPS), pages 21314–21328, 2022. doi: 10.52202/068431-1549. 10
-
[16]
Jia Li, Zhuangbin Chen, Yuxin Su, and Michael R. Lyu. VulKey: Automated vulnerability repair guided by domain-specific repair patterns.arXiv preprint arXiv:2605.01769, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Jia Li, Yuxin Su, and Michael R. Lyu. From laboratory to real-world applications: Benchmarking agentic code reasoning at the repository level.arXiv preprint arXiv:2601.03731, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations, 2024. URL https: //openreview.net/forum?id=v8L0pN6EOi
work page 2024
-
[19]
RLTF: Reinforcement learning from unit test feedback.Transactions on Machine Learning Research,
Jiate Liu, Yiqin Zhu, Kaiwen Xiao, QIANG FU, Xiao Han, Yang Wei, and Deheng Ye. RLTF: Reinforcement learning from unit test feedback.Transactions on Machine Learning Research,
-
[20]
URLhttps://openreview.net/forum?id=hjYmsV6nXZ
ISSN 2835-8856. URLhttps://openreview.net/forum?id=hjYmsV6nXZ
-
[21]
Gdpo: Group reward-decoupled normalization policy optimization for multi-reward rl optimization,
Shih-Yang Liu, Xin Dong, Ximing Lu, Shizhe Diao, Peter Belcak, Mingjie Liu, Min-Hung Chen, Hongxu Yin, Yu-Chiang Frank Wang, Kwang-Ting Cheng, Yejin Choi, Jan Kautz, and Pavlo Molchanov. GDPO: Group reward-decoupled normalization policy optimization for multi-reward RL optimization.arXiv preprint arXiv:2601.05242, 2026
-
[22]
Understanding R1-Zero-Like Training: A Critical Perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding R1-Zero-Like training: A critical perspective.arXiv preprint arXiv:2503.20783, 2025
work page internal anchor Pith review arXiv 2025
-
[23]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019. URL https://openreview.net/forum? id=Bkg6RiCqY7
work page 2019
-
[24]
Improve Mathematical Reasoning in Language Models by Automated Process Supervision
Liangchen Luo, Yinxiao Liu, Rosanne Liu, Samrat Phatale, Meiqi Guo, Harsh Lara, Yunxuan Li, Lei Shu, Yun Zhu, Lei Meng, Jiao Sun, and Abhinav Rastogi. Improve mathematical reasoning in language models by automated process supervision.arXiv preprint arXiv:2406.06592, 2024
work page internal anchor Pith review arXiv 2024
-
[25]
DeepSWE: Training a fully open-sourced, state-of-the-art coding agent by scaling RL
Michael Luo, Sijun Tan, Colin Cai, Roy Hao, Lambda Lu, Tarun Venkat, Tianjun Zhang, Manan Roongta, Tianhao Wu, Justin Wong, Ion Stoica, and Raluca Ada Popa. DeepSWE: Training a fully open-sourced, state-of-the-art coding agent by scaling RL. Together AI Blog,
-
[26]
Agentica Project, UC Berkeley Sky Computing Lab and Together AI
URL https://www.together.ai/blog/deepswe. Agentica Project, UC Berkeley Sky Computing Lab and Together AI
-
[27]
arXiv preprint arXiv:2509.14257 , year =
Yuanjie Lyu, Chengyu Wang, Jun Huang, and Tong Xu. From correction to mastery: Reinforced distillation of large language model agents.arXiv preprint arXiv:2509.14257, 2025
-
[28]
Youssef Mroueh. Reinforcement learning with verifiable rewards: GRPO’s effective loss, dynamics, and success amplification.arXiv preprint arXiv:2503.06639, 2025
-
[29]
Zhongqiang Pan, Chuanyi Li, Wenkang Zhong, Yi Feng, Bin Luo, and Vincent Ng. RepoRepair: Leveraging code documentation for repository-level automated program repair.arXiv preprint arXiv:2603.01048, 2026
-
[30]
arXiv preprint arXiv:2602.04942 , year =
Emiliano Penaloza, Dheeraj Vattikonda, Nicolas Gontier, Alexandre Lacoste, Laurent Charlin, and Massimo Caccia. Privileged information distillation for language models.arXiv preprint arXiv:2602.04942, 2026
-
[31]
ToolRL: Reward is all tool learning needs
Cheng Qian, Emre Can Acikgoz, Qi He, Hongru WANG, Xiusi Chen, Dilek Hakkani-Tür, Gokhan Tur, and Heng Ji. ToolRL: Reward is all tool learning needs. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview. net/forum?id=eOLdGbXT6t
work page 2025
-
[32]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. arXiv preprint arXiv:2305.18290, 2023
work page internal anchor Pith review arXiv 2023
-
[33]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017. 11
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[34]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Yu Wu, and Daya Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Parshin Shojaee, Aneesh Jain, Sindhu Tipirneni, and Chandan K. Reddy. Execution-based code generation using deep reinforcement learning.Transactions on Machine Learning Research,
-
[36]
URLhttps://openreview.net/forum?id=0XBuaxqEcG
ISSN 2835-8856. URLhttps://openreview.net/forum?id=0XBuaxqEcG
-
[37]
Repairllama: Efficient representations and fine-tuned adapters for program repair
André Silva, Sen Fang, and Martin Monperrus. RepairLLaMA: Efficient representations and fine-tuned adapters for program repair.IEEE Transactions on Software Engineering, 2025. doi: 10.1109/TSE.2025.3581062. URLhttps://doi.org/10.1109/TSE.2025.3581062
-
[38]
Joar Skalse, Nikolaus H. R. Howe, Dmitrii Krasheninnikov, and David Krueger. Defining and characterizing reward hacking. InAdvances in Neural Information Processing Systems (NeurIPS), pages 9460–9471, 2022. doi: 10.52202/068431-0687
-
[39]
A Survey of On-Policy Distillation for Large Language Models
Mingyang Song and Mao Zheng. A survey of on-policy distillation for large language models. arXiv preprint arXiv:2604.00626, 2026
work page internal anchor Pith review arXiv 2026
-
[40]
Alex Stein, Furong Huang, and Tom Goldstein. GATES: Self-distillation under privileged context with consensus gating.arXiv preprint arXiv:2602.20574, 2026
-
[41]
Shaked Brody, Uri Alon, and Eran Yahav
Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. Math-Shepherd: Verify and reinforce LLMs step-by-step without human annotations. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9426–9439, 2024. doi: 10.18653/v1/2024.acl-long. 510
-
[42]
Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, Robert Brennan, Hao Peng, Heng Ji, and Graham Neubig. Openhands: An open platform for AI soft...
work page 2025
-
[43]
RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning
Zihan Wang, Kangrui Wang, Qineng Wang, Pingyue Zhang, Linjie Li, Zhengyuan Yang, Xing Jin, Kefan Yu, Minh Nhat Nguyen, Licheng Liu, Eli Gottlieb, Yiping Lu, Kyunghyun Cho, Jiajun Wu, Li Fei-Fei, Lijuan Wang, Yejin Choi, and Manling Li. RAGEN: Under- standing self-evolution in LLM agents via multi-turn reinforcement learning.arXiv preprint arXiv:2504.20073, 2025
work page internal anchor Pith review arXiv 2025
-
[44]
RAGEN-2: Reasoning Collapse in Agentic RL
Zihan Wang, Chi Gui, Xing Jin, Qineng Wang, Licheng Liu, Kangrui Wang, Shiqi Chen, Linjie Li, Zhengyuan Yang, Pingyue Zhang, Yiping Lu, Jiajun Wu, Li Fei-Fei, Lijuan Wang, Yejin Choi, and Manling Li. RAGEN-2: Reasoning collapse in agentic RL.arXiv preprint arXiv:2604.06268, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[45]
SWE-RL: Advancing LLM reasoning via reinforcement learning on open software evolution
Yuxiang Wei, Olivier Duchenne, Jade Copet, Quentin Carbonneaux, LINGMING ZHANG, Daniel Fried, Gabriel Synnaeve, Rishabh Singh, and Sida Wang. SWE-RL: Advancing LLM reasoning via reinforcement learning on open software evolution. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview. net/forum?id=ULblO61XZ0
work page 2025
-
[46]
arXiv preprint arXiv:2506.02208 , year =
Hongling Xu, Qi Zhu, Heyuan Deng, Jinpeng Li, Lu Hou, Yasheng Wang, Lifeng Shang, Ruifeng Xu, and Fei Mi. KDRL: Post-training reasoning LLMs via unified knowledge distilla- tion and reinforcement learning.arXiv preprint arXiv:2506.02208, 2025
-
[47]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik R Narasimhan, and Ofir Press. SWE-agent: Agent-computer interfaces enable automated soft- ware engineering. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URLhttps://arxiv.org/abs/2405.15793. 12
work page internal anchor Pith review arXiv 2024
-
[48]
Zhuolin Yang, Zihan Liu, Yang Chen, Wenliang Dai, Boxin Wang, Sheng-Chieh Lin, Chankyu Lee, Yangyi Chen, Dongfu Jiang, Jiafan He, Renjie Pi, Grace Lam, Nayeon Lee, Alexan- der Bukharin, Mohammad Shoeybi, Bryan Catanzaro, and Wei Ping. Nemotron-Cascade 2: Post-training LLMs with cascade RL and multi-domain on-policy distillation.arXiv preprint arXiv:2603.1...
-
[49]
Kimi-dev: Agentless training as skill prior for swe-agents, 2025 c
Zonghan Yang, Shengjie Wang, Kelin Fu, Wenyang He, Weimin Xiong, Yibo Liu, Yibo Miao, Bofei Gao, Yejie Wang, Yingwei Ma, Yanhao Li, Yue Liu, Zhenxing Hu, Kaitai Zhang, Shuyi Wang, Huarong Chen, Flood Sung, Yang Liu, Yang Gao, Zhilin Yang, and Tianyu Liu. Kimi- Dev: Agentless training as skill prior for SWE-agents.arXiv preprint arXiv:2509.23045, 2025
-
[50]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR), 2023
work page 2023
-
[51]
DAPO: An open-source LLM reinforcement learning system at scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, YuYue, Weinan Dai, Tiantian Fan, Gaohong Liu, Juncai Liu, LingJun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Ru Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao ...
work page 2025
-
[52]
Free process rewards without process labels
Lifan Yuan, Wendi Li, Huayu Chen, Ganqu Cui, Ning Ding, Kaiyan Zhang, Bowen Zhou, Zhiyuan Liu, and Hao Peng. Free process rewards without process labels. InProceedings of the 42nd International Conference on Machine Learning (ICML), volume 267 ofProceedings of Machine Learning Research, pages 73511–73525. PMLR, 2025. URLhttps://proceedings. mlr.press/v267...
work page 2025
-
[53]
Multi-swe-bench: A multilingual benchmark for issue resolving.arXiv preprint arXiv:2504.02605, 2025
Daoguang Zan, Zhirong Huang, Wei Liu, Hanwu Chen, Linhao Zhang, Shulin Xin, Lu Chen, Qi Liu, Xiaojian Zhong, Aoyan Li, Siyao Liu, Yongsheng Xiao, Liangqiang Chen, Yuyu Zhang, Jing Su, Tianyu Liu, Rui Long, Kai Shen, and Liang Xiang. Multi-SWE-bench: A multilingual benchmark for issue resolving.arXiv preprint arXiv:2504.02605, 2025
-
[54]
Control-oriented model-based reinforcement learning with implicit differentiation
Jian Zhao, Runze Liu, Kaiyan Zhang, Zhimu Zhou, Junqi Gao, Dong Li, Jiafei Lyu, Zhouyi Qian, Biqing Qi, Xiu Li, and Bowen Zhou. GenPRM: Scaling test-time compute of process reward models via generative reasoning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 34932–34940. AAAI Press, March 2026. doi: 10.1609/aaai. v40i41.40797
-
[55]
ProcessBench: Identifying process errors in mathematical reasoning
Chujie Zheng, Zhenru Zhang, Beichen Zhang, Runji Lin, Keming Lu, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. ProcessBench: Identifying process errors in mathematical reasoning. InProceedings of the 63rd Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), pages 1009–1024. Association for Computational Linguistics,
-
[56]
Signal Reshaping for GRPO in Weak-Feedback Agentic Code Repair
URLhttps://aclanthology.org/2025.acl-long.50/. Appendix for “Signal Reshaping for GRPO in Weak-Feedback Agentic Code Repair” Table of Contents A Related Work 14 13 B Limitations 16 C Environment and Tool-Interface Implementation Details 17 C.1 Retention Rates of the Data-Construction Pipeline . . . . . . . . . . . . . . . . . . 18 C.2 Semantic Judge Valid...
work page 2025
-
[57]
Fix only the code that causes compilation ERRORs; do not fix WARNINGs
-
[58]
Ignore all compilation warnings and focus only on compilation errors
-
[59]
Do not break the original logic or functionality of the code; remain consistent with the original intent
-
[60]
Make only necessary changes and do not introduce new issues
-
[61]
Warnings are allowed, but errors are not
Ensure that the repaired code compiles successfully. Warnings are allowed, but errors are not. ## Workflow
-
[62]
**Analyze errors**: Carefully read the compiler error messages and understand the specific cause of each error
-
[63]
**Make a plan**: Use the plan command of task_tracker to create a task list
-
[64]
**Locate the issue**: Use the view command of str_replace_editor to inspect the reported file
-
[65]
**Understand context**: When necessary, use bash to search for relevant definitions, declarations, or usages
-
[66]
**Make a precise fix**: Use str_replace in str_replace_editor to make a minimal modification
-
[67]
**Update progress**: After completing each repair, update the task status with task_tracker
-
[68]
**Verify the result**: Call compile_code to recompile
-
[69]
**Iterate**: If errors remain, repeat steps 3--7
-
[70]
**Submit**: After confirming successful compilation, call finish to submit. ## Available Tools - task_tracker: task management (plan / view) - str_replace_editor: file operations (view / str_replace / create / insert) - bash: execute shell commands - compile_code: compile and verify - finish: submit after the repair is complete ## Notes - Make precise cha...
-
[71]
Analyze the compilation errors above and identify the root cause
-
[72]
Propose a minimal code modification
-
[73]
Please start analyzing and fixing the compilation error
Ensure that the repaired code compiles successfully. Please start analyzing and fixing the compilation error. E.3 Semantic-Consistency Judgment Prompt: Terminal Rewardr semantic Both training and evaluation use Kimi-K2.5 for outcome semantic judgment with the following prompt. The output is strict JSON containing intent_consistency, confidence_score, and ...
-
[74]
**Semantic equivalence**: The repair generated by the model is semantically equivalent to the GT repair
-
[75]
**Functional consistency**: The repaired program produces the same output under the same input
-
[76]
**Behavior preservation**: The repair does not change the logical flow or computation process of the program. **Evaluation requirements:** - Compare only the modifications related to the target compilation error. - The GT may contain changes unrelated to the target error; these should not affect the judgment. - Focus on the semantic intent and runtime beh...
-
[77]
Semantic equivalence: a model-generated repair is correct if it is semantically equivalent to the GT
-
[78]
Functional consistency: the repaired program should produce the same output under the same input
-
[79]
Behavior preservation: the repair should not change the logical flow or computation process of the program. Evaluation requirements: - Compare only the modifications related to the target compilation error. - The GT may contain modifications unrelated to the target error; these should not affect the judgment. - Focus on the semantic intent and runtime beh...
-
[80]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.