Recognition: unknown
VulKey: Automated Vulnerability Repair Guided by Domain-Specific Repair Patterns
Pith reviewed 2026-05-10 14:53 UTC · model grok-4.3
The pith
A framework guides LLMs using a three-level hierarchy of security knowledge to generate more accurate vulnerability patches.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that by using a hierarchical abstraction of expert security knowledge—structured as CWE type, syntactic actions, and semantic key elements—to match and guide a fine-tuned large language model, the system can produce correct and generalizable patches for vulnerabilities more effectively than existing LLM-based approaches.
What carries the argument
The three-level hierarchical abstraction that formulates repair strategies in terms of CWE type, syntactic actions, and semantic key elements, which is matched to the vulnerability and used to guide the LLM.
If this is right
- Improved repair accuracy of 31.5 percent on a real-world C/C++ vulnerability dataset.
- Outperforms the best baseline approach by 7.6 percentage points.
- State-of-the-art results on a Java vulnerability benchmark.
- Generalizability across different programming languages and language models.
Where Pith is reading between the lines
- This structured knowledge approach could be adapted to other code-related tasks that benefit from domain-specific guidance, such as bug fixing or code optimization.
- Automating the extraction of these hierarchical patterns from vulnerability databases might further scale the method.
- Combining this with static analysis tools could provide even stronger guarantees on patch correctness.
- The results suggest that domain knowledge integration is more effective than scaling model size alone for security applications.
Load-bearing premise
The three-level hierarchical abstraction can be reliably matched to previously unseen vulnerabilities and will sufficiently guide the model to produce correct patches that generalize beyond the training patterns.
What would settle it
A significant drop in repair accuracy when the method is tested on a new vulnerability dataset where the expert-derived patterns fail to match the required fixes or lead to incorrect patches.
Figures



read the original abstract
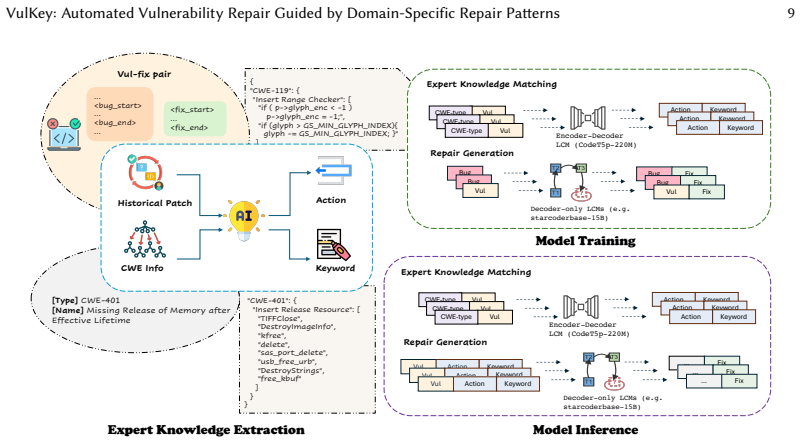
The increasing prevalence of software vulnerabilities highlights the need for effective Automatic Vulnerability Repair (AVR) tools. While LLM-based approaches are promising, they struggle to incorporate structured security knowledge from sources like CWE and NVD. Current methods either use this information superficially by concatenating the CWE-ID into the input prompt, yielding negligible benefits, or rely on few-shot learning with rigid, non-generalizable examples, which limits their effectiveness in real-world scenarios. To address this gap, we propose VulKey, an LLM-based AVR framework that leverages a hierarchical abstraction of expert knowledge to guide patch generation. Our novel three-level abstraction formulates repair strategies in terms of CWE type, syntactic actions, and semantic key elements. This approach captures the essence of a security fix with greater generality than concrete examples and more semantic richness than traditional syntax-based templates, overcoming the coverage limitations of prior methods. VulKey is implemented as a two-stage pipeline: first, expert knowledge matching predicts an appropriate repair pattern for the vulnerability; second, repair code generation uses a pattern-guided, fine-tuned LLM to produce secure patches. On the real-world C/C++ dataset PrimeVul, VulKey achieves 31.5% repair accuracy, surpassing the best baseline by 7.6% and outperforming leading tools such as VulMaster and GPT-5. Moreover, VulKey demonstrates cross-language and cross-model generalizability, with state-of-the-art performance on the Java benchmark Vul4J. These results underscore the importance of structured expert knowledge in advancing AVR effectiveness. Our work demonstrates that explicitly modeling and integrating expert security knowledge through hierarchical patterns is a crucial step toward building more effective and reliable AVR tools.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents VulKey, an LLM-based automatic vulnerability repair (AVR) framework that employs a novel three-level hierarchical abstraction of repair patterns (CWE type, syntactic actions, and semantic key elements) to guide patch generation. It is implemented as a two-stage pipeline: expert knowledge matching to predict a repair pattern for a given vulnerability, followed by pattern-guided fine-tuning and inference with an LLM to produce secure patches. The authors claim that on the real-world C/C++ PrimeVul dataset, VulKey attains 31.5% repair accuracy (7.6% above the best baseline) and outperforms tools including VulMaster and GPT-5; it also reports state-of-the-art results on the Java Vul4J benchmark, indicating cross-language and cross-model generalizability.
Significance. If the results hold after addressing evaluation gaps, the work would usefully demonstrate that hierarchical, domain-specific abstractions of expert security knowledge can improve LLM-based AVR beyond superficial CWE concatenation or rigid few-shot examples. The cross-language transfer results would be particularly valuable if substantiated, as they suggest a path toward more generalizable repair systems that explicitly encode semantic and syntactic repair strategies.
major comments (2)
- The central performance claim (31.5% accuracy on PrimeVul, +7.6% over baselines) rests on the first-stage expert knowledge matching reliably predicting the three-level pattern for unseen test vulnerabilities. The abstract and evaluation provide no accuracy, precision, or recall figures for this matcher on held-out data, and no ablation comparing oracle (ground-truth) patterns against predicted patterns. Without these, it is impossible to isolate whether gains derive from the abstraction's guidance or from matcher behavior on training-similar instances. This is load-bearing for the two-stage pipeline's contribution.
- Dataset construction, pattern extraction, and train/test splits for PrimeVul and Vul4J are not described with sufficient detail to rule out leakage. It is unclear how the three-level patterns were derived from CWE/NVD sources or whether any information from the evaluation vulnerabilities influenced pattern definition or matcher training. This directly affects the validity of the held-out accuracy numbers and the cross-language generalizability claim.
minor comments (2)
- The abstract refers to 'GPT-5'; clarify whether this denotes a specific model variant, a hypothetical, or a typographical reference to an existing model such as GPT-4.
- Include at least one table or figure summarizing matcher-stage performance and the oracle-vs-predicted ablation to make the evaluation self-contained.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, indicating where revisions will be made to strengthen the paper.
read point-by-point responses
-
Referee: The central performance claim (31.5% accuracy on PrimeVul, +7.6% over baselines) rests on the first-stage expert knowledge matching reliably predicting the three-level pattern for unseen test vulnerabilities. The abstract and evaluation provide no accuracy, precision, or recall figures for this matcher on held-out data, and no ablation comparing oracle (ground-truth) patterns against predicted patterns. Without these, it is impossible to isolate whether gains derive from the abstraction's guidance or from matcher behavior on training-similar instances. This is load-bearing for the two-stage pipeline's contribution.
Authors: We agree that the matcher's performance on held-out data is critical to interpreting the end-to-end results and isolating the contribution of the hierarchical patterns. In the revised manuscript, we will add a new subsection in the evaluation section reporting the accuracy, precision, and recall of the expert knowledge matcher on the held-out test set. We will also include an ablation study comparing repair accuracy when using oracle (ground-truth) patterns versus the predicted patterns from the matcher. This will clarify the source of the observed gains and address the load-bearing nature of the two-stage pipeline. revision: yes
-
Referee: Dataset construction, pattern extraction, and train/test splits for PrimeVul and Vul4J are not described with sufficient detail to rule out leakage. It is unclear how the three-level patterns were derived from CWE/NVD sources or whether any information from the evaluation vulnerabilities influenced pattern definition or matcher training. This directly affects the validity of the held-out accuracy numbers and the cross-language generalizability claim.
Authors: We acknowledge that insufficient detail on dataset construction and pattern derivation could raise concerns about leakage. In the revised manuscript, we will expand the relevant sections to provide a full description of PrimeVul and Vul4J dataset construction, the exact process for extracting the three-level patterns from CWE and NVD sources, and the train/test split methodology. We will explicitly state that pattern definition and matcher training used only training data, with no information from evaluation vulnerabilities. This will substantiate the validity of the held-out results and the cross-language claims. revision: yes
Circularity Check
No circularity: empirical results on held-out benchmarks
full rationale
The paper describes a two-stage empirical framework (pattern matching followed by LLM-based patch generation) and reports direct accuracy measurements on separate real-world datasets (PrimeVul for C/C++, Vul4J for Java). No equations, derivations, or fitted parameters are present that reduce the reported 31.5% accuracy or relative gains to quantities defined by the inputs themselves. The central claims rest on standard train/test splits and cross-benchmark comparisons rather than self-definitional or self-citation load-bearing steps. This is the expected non-finding for an applied ML engineering paper whose value is measured by external benchmark performance.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert security knowledge from CWE and NVD can be effectively abstracted into a hierarchical structure of CWE type, syntactic actions, and semantic key elements that generalizes across vulnerabilities.
invented entities (1)
-
Three-level hierarchical repair pattern abstraction
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Signal Reshaping for GRPO in Weak-Feedback Agentic Code Repair
Reshaping outcome rewards, process signals, and rollout comparability in GRPO raises strict compile-and-semantic accuracy in agentic code repair from 0.385 to 0.535 under weak feedback.
Reference graph
Works this paper leans on
-
[1]
Afsah Anwar, Ahmed Abusnaina, Songqing Chen, Frank Li, and David Mohaisen. 2021. Cleaning the NVD: Compre- hensive quality assessment, improvements, and analyses.IEEE Transactions on Dependable and Secure Computing19, 6 (2021), 4255–4269. doi:10.1109/TDSC.2021.3125270
-
[2]
Guru Bhandari, Amara Naseer, and Leon Moonen. 2021. CVEfixes: automated collection of vulnerabilities and their fixes from open-source software. InProceedings of the 17th International Conference on Predictive Models and Data Analytics in Software Engineering. ACM, New York, NY, USA, 30–39. doi:10.1145/3475960.3475985
-
[3]
BigCode. 2024. Data Portraits. https://stack.dataportraits.org/
2024
-
[4]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin...
2020
-
[5]
Quang-Cuong Bui, Riccardo Scandariato, and Nicolás E. Díaz Ferreyra. 2022. Vul4J: a dataset of reproducible Java vulnerabilities geared towards the study of program repair techniques. InProceedings of the 19th International Conference on Mining Software Repositories. Association for Computing Machinery, New York, NY, USA, 464–468. doi:10.1145/ 3524842.3528482
-
[6]
Xiansheng Cao, Junfeng Wang, and Peng Wu. 2024. Enhancing Vulnerability Repair Through Summarization of Repair Patterns and Optimal Matching.SSRN preprint SSRN:5025384(2024). doi:10.2139/ssrn.5025384
-
[7]
Yizheng Chen, Zhoujie Ding, Lamya Alowain, Xinyun Chen, and David Wagner. 2023. DiverseVul: A New Vulnerable Source Code Dataset for Deep Learning Based Vulnerability Detection. InProceedings of the 26th International Sym- posium on Research in Attacks, Intrusions and Defenses. Association for Computing Machinery, New York, NY, USA, 654–668. doi:10.1145/3...
-
[8]
Zimin Chen, Steve Kommrusch, and Martin Monperrus. 2022. Neural Transfer Learning for Repairing Security Vulnerabilities in C Code.IEEE Transactions on Software Engineering48, 9 (2022), 3582–3597. doi:10.1109/TSE.2019. 2940179
- [9]
-
[10]
Jacob Cohen. 1960. A coefficient of agreement for nominal scales.Educational and psychological measurement20, 1 (1960), 37–46. doi:10.1177/001316446002000104
-
[11]
The MITRE Corporation. 2025. Common Vulnerabilities and Exposures. https://www.cve.org/
2025
-
[12]
The MITRE Corporation. 2025. Common Weakness Enumeration. https://cwe.mitre.org/. , Vol. 1, No. 1, Article . Publication date: May 2026. 22 Jia Li, Zhuangbin Chen, Yuxin Su, and Michael R. Lyu
2025
-
[13]
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. 2023. QLoRA: Efficient Finetuning of Quantized LLMs. InAdvances in Neural Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (Eds.), Vol. 36. Curran Associates, Inc., Red Hook, NY, USA, 10088–10115. https://proceedings.neurips. cc/paper_fil...
2023
-
[14]
Yangruibo Ding, Yanjun Fu, Omniyyah Ibrahim, Chawin Sitawarin, Xinyun Chen, Basel Alomair, David Wagner, Baishakhi Ray, and Yizheng Chen. 2025. Vulnerability Detection with Code Language Models: How Far Are We?. In 2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE Computer Society, Los Alamitos, CA, USA, 469–481. doi:10.1109...
-
[15]
2024.A Global View of the CISA KEV Catalog: Prevalence and Remediation
Ben Edwards. 2024.A Global View of the CISA KEV Catalog: Prevalence and Remediation. Technical Report. Bitsight. https://www.bitsight.com/resources/slicing-through-cisas-kev-catalog
2024
-
[16]
Hugging Face. 2023. codet5p-220m. https://huggingface.co/Salesforce/codet5p-220m
2023
-
[17]
Hugging Face. 2023. Quantization. https://huggingface.co/docs/transformers/main/en/main_classes/quantization
2023
-
[18]
Hugging Face. 2023. starcoderbase. https://huggingface.co/bigcode/starcoderbase
2023
-
[19]
Hugging Face. 2024. CodeLlama-70b-hf. https://huggingface.co/codellama/CodeLlama-70b-hf
2024
-
[20]
Hugging Face. 2024. DeepSeek-Coder-V2-Lite-Base. https://huggingface.co/deepseek-ai/DeepSeek-Coder-V2-Lite- Base
2024
-
[21]
Hugging Face. 2024. Qwen2.5-Coder-32B. https://huggingface.co/Qwen/Qwen2.5-Coder-32B
2024
-
[22]
Jiahao Fan, Yi Li, Shaohua Wang, and Tien N. Nguyen. 2020. A C/C++ Code Vulnerability Dataset with Code Changes and CVE Summaries. InProceedings of the 17th International Conference on Mining Software Repositories. Association for Computing Machinery, New York, NY, USA, 508–512. doi:10.1145/3379597.3387501
-
[23]
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, and Qing Li. 2024. A survey on rag meeting llms: Towards retrieval-augmented large language models. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. Association for Computing Machinery, New York, NY, USA, 6491–6501. doi:10.1145/3...
-
[24]
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, et al. 2020. CodeBERT: A Pre-Trained Model for Programming and Natural Languages. InFindings of the Association for Computational Linguistics: EMNLP 2020. Association for Computational Linguistics, Online, 1536–1547. doi:10.18653/v1/2020....
-
[25]
Markus Freitag and Yaser Al-Onaizan. 2017. Beam Search Strategies for Neural Machine Translation. InProceedings of the First Workshop on Neural Machine Translation. Association for Computational Linguistics, Vancouver, Canada, 56–60. doi:10.18653/v1/w17-3207
-
[26]
Michael Fu, Chakkrit Tantithamthavorn, Trung Le, Van Nguyen, and Phung Dinh. 2022. VulRepair: A T5-based Automated Software Vulnerability Repair. InProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. Association for Computing Machinery, New York, NY, USA, 935–947. doi:10.1145...
-
[27]
Qing Gao, Yingfei Xiong, Yaqing Mi, Lu Zhang, Weikun Yang, Zhaoping Zhou, Bing Xie, and Hong Mei. 2015. Safe memory-leak fixing for C programs. InProceedings of the 37th International Conference on Software Engineering - Volume 1. IEEE Press, Piscataway, NJ, USA, 459–470
2015
-
[28]
GitHub. 2026. CodeQL. https://codeql.github.com/
2026
-
[29]
Seongjoon Hong, Junhee Lee, Jeongsoo Lee, and Hakjoo Oh. 2020. SAVER: scalable, precise, and safe memory-error repair. InProceedings of the ACM/IEEE 42nd International Conference on Software Engineering. Association for Computing Machinery, New York, NY, USA, 271–283. doi:10.1145/3377811.3380323
-
[30]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
-
[31]
LoRA: Low-Rank Adaptation of Large Language Models.arXiv preprint arXiv:2106.09685(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[32]
Kai Huang, Zhengzi Xu, Su Yang, Hongyu Sun, Xuejun Li, Zheng Yan, and Yuqing Zhang. 2024. Evolving Paradigms in Automated Program Repair: Taxonomy, Challenges, and Opportunities.Comput. Surveys57, 2, Article 36 (2024), 43 pages. doi:10.1145/3696450
-
[33]
Kai Huang, Jian Zhang, Xiangxin Meng, and Yang Liu. 2025. Template-Guided Program Repair in the Era of Large Language Models. In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE Computer Society, Los Alamitos, CA, USA, 367–379. doi:10.1109/ICSE55347.2025.00030
-
[34]
J Richard Landis and Gary G Koch. 1977. The measurement of observer agreement for categorical data.Biometrics33, 1 (1977), 159–174. doi:10.2307/2529310
-
[35]
Junhee Lee, Seongjoon Hong, and Hakjoo Oh. 2018. MemFix: static analysis-based repair of memory deallocation errors for C. InProceedings of the 2018 26th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. Association for Computing Machinery, New York, NY, USA, 95–106. doi:10.1145/3236024...
-
[36]
Kui Liu, Anil Koyuncu, Dongsun Kim, and Tegawendé F. Bissyandé. 2019. TBar: revisiting template-based automated program repair. InProceedings of the 28th ACM SIGSOFT International Symposium on Software Testing and Analysis. ACM, New York, NY, USA, 31–42. doi:10.1145/3293882.3330577
-
[37]
Xiangxin Meng, Xu Wang, Hongyu Zhang, Hailong Sun, and Xudong Liu. 2022. Improving fault localization and program repair with deep semantic features and transferred knowledge. InProceedings of the 44th International Conference on Software Engineering. Association for Computing Machinery, New York, NY, USA, 1169–1180. doi:10. 1145/3510003.3510147
-
[38]
Georgios Nikitopoulos, Konstantina Dritsa, Panos Louridas, and Dimitris Mitropoulos. 2021. CrossVul: a cross-language vulnerability dataset with commit data. InProceedings of the 29th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. Association for Computing Machinery, New York, NY, USA, 1565–156...
-
[39]
Changan Niu, Chuanyi Li, Vincent Ng, Dongxiao Chen, Jidong Ge, and Bin Luo. 2023. An Empirical Comparison of Pre-Trained Models of Source Code. InProceedings of the 45th International Conference on Software Engineering. IEEE Press, Piscataway, NJ, USA, 2136–2148. doi:10.1109/ICSE48619.2023.00180
-
[40]
Yu Nong, Haoran Yang, Long Cheng, Hongxin Hu, and Haipeng Cai. 2025. APPATCH: automated adaptive prompting large language models for real-world software vulnerability patching. InProceedings of the 34th USENIX Conference on Security Symposium. USENIX Association, USA, Article 231, 20 pages
2025
-
[41]
OpenAI. 2024. ChatGPT. https://openai.com/blog/chatgpt/
2024
-
[42]
John W Ratcliff, David E Metzener, et al. 1988. Pattern matching: The gestalt approach.Dr. Dobbś Journal13, 7 (1988), 46
1988
-
[43]
Stephen Robertson and Hugo Zaragoza. 2009. The Probabilistic Relevance Framework: BM25 and beyond.Foundations and Trends®in Information Retrieval3, 4 (2009), 333–389. doi:10.1561/1500000019
-
[44]
Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, et al. 2023. Code Llama: Open Foundation Models for Code.arXiv preprint arXiv:2308.12950 (2023)
work page internal anchor Pith review arXiv 2023
-
[45]
US-CERT Security. 2025. National Vulnerability Database. https://nvd.nist.gov/
2025
- [46]
-
[47]
Nima Shiri Harzevili, Alvine Boaye Belle, Junjie Wang, Song Wang, Zhen Ming (Jack) Jiang, and Nachiappan Nagappan
-
[48]
A Systematic Literature Review on Automated Software Vulnerability Detection Using Machine Learning. Comput. Surveys57, 3 (2024), 55. doi:10.1145/3699711
-
[49]
SonarSource. 2026. SonarQube. https://www.sonarsource.com/products/sonarqube/
2026
-
[50]
Rijnard van Tonder and Claire Le Goues. 2018. Static automated program repair for heap properties. InProceedings of the 40th International Conference on Software Engineering. Association for Computing Machinery, New York, NY, USA, 151–162. doi:10.1145/3180155.3180250
-
[51]
Yue Wang, Weishi Wang, Shafiq Joty, and Steven C.H. Hoi. 2021. CodeT5: Identifier-aware Unified Pre-trained Encoder- Decoder Models for Code Understanding and Generation. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Online and Punta Cana, Dominican Republic, 8696–8708....
-
[52]
Yi Wu, Nan Jiang, Hung Viet Pham, Thibaud Lutellier, Jordan Davis, Lin Tan, Petr Babkin, and Sameena Shah. 2023. How Effective Are Neural Networks for Fixing Security Vulnerabilities. InProceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis. Association for Computing Machinery, New York, NY, USA, 1282–1294. doi:10.114...
-
[53]
Chunqiu Steven Xia and Lingming Zhang. 2024. Automated Program Repair via Conversation: Fixing 162 out of 337 Bugs for $0.42 Each using ChatGPT. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis. Association for Computing Machinery, New York, NY, USA, 819–831. doi:10.1145/3650212.3680323
-
[54]
Xin Yin, Chao Ni, Shaohua Wang, Zhenhao Li, Limin Zeng, and Xiaohu Yang. 2024. ThinkRepair: Self-Directed Automated Program Repair. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis. Association for Computing Machinery, New York, NY, USA, 1274–1286. doi:10.1145/3650212.3680359
-
[55]
Jian Zhang, Chong Wang, Anran Li, Wenhan Wang, Tianlin Li, and Yang Liu. 2024. VulAdvisor: Natural Language Suggestion Generation for Software Vulnerability Repair. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. Association for Computing Machinery, New York, NY, USA, 1932–1944. doi:10. 1145/3691620.3695555
-
[56]
Xin Zhou, Sicong Cao, Xiaobing Sun, and David Lo. 2025. Large Language Model for Vulnerability Detection and Repair: Literature Review and the Road Ahead.ACM Transactions on Software Engineering and Methodology34, 5 (2025), 1–31. doi:10.1145/3708522 , Vol. 1, No. 1, Article . Publication date: May 2026. 24 Jia Li, Zhuangbin Chen, Yuxin Su, and Michael R. Lyu
-
[57]
Xin Zhou, Kisub Kim, Bowen Xu, Donggyun Han, and David Lo. 2024. Out of Sight, Out of Mind: Better Automatic Vulnerability Repair by Broadening Input Ranges and Sources. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering. Association for Computing Machinery, New York, NY, USA, 1–13. doi:10.1145/ 3597503.3639222 , Vol. 1, N...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.