Recognition: no theorem link
LaTER: Efficient Test-Time Reasoning via Latent Exploration and Explicit Verification
Pith reviewed 2026-05-11 01:59 UTC · model grok-4.3
The pith
LaTER lets models explore reasoning in continuous latent space then switch to explicit verification, cutting tokens 16-32% while matching or raising accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
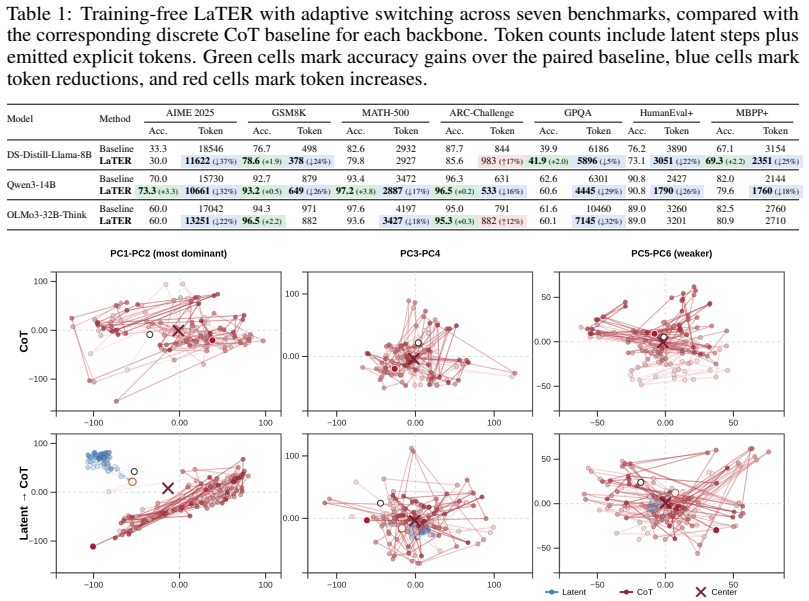
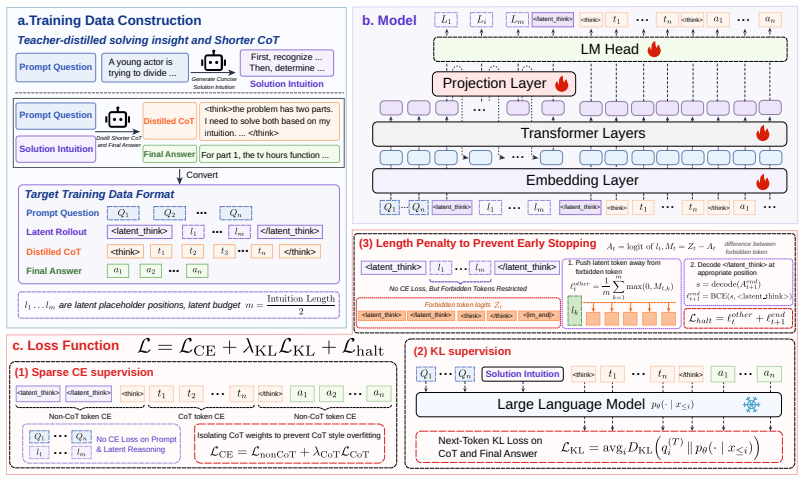
Strong reasoning models already exhibit structured trajectories in latent space. Projecting the final-layer hidden states into the input embedding space while preserving the KV cache allows the model to continue from that trajectory into explicit tokens. Entropy measurements and native stop-token predictions identify when the latent phase has produced a usable intuition, triggering a safe handoff to verification. On Qwen3-14B the training-free version reduces tokens 16-32% across benchmarks while matching or improving accuracy; fine-tuning on Latent-Switch-69K further raises AIME 2025 accuracy to 80% with 33% fewer tokens than standard chain-of-thought.
What carries the argument
The LaTER two-stage switch: bounded latent exploration via hidden-state projection and KV-cache reuse, followed by explicit CoT triggered by entropy and stop-token probes.
If this is right
- Training-free LaTER reduces total token usage by 16%-32% on several benchmarks while matching or improving accuracy.
- On Qwen3-14B it improves AIME 2025 from 70.0% to 73.3% accuracy while lowering tokens from 15,730 to 10,661.
- Fine-tuned LaTER reaches 80.0% accuracy on AIME 2025 using 33% fewer tokens than standard CoT.
- Strong reasoning models produce structured latent trajectories that the projection interface can access.
Where Pith is reading between the lines
- Latent space appears to hold condensed solution intuitions that explicit verification can confirm or correct.
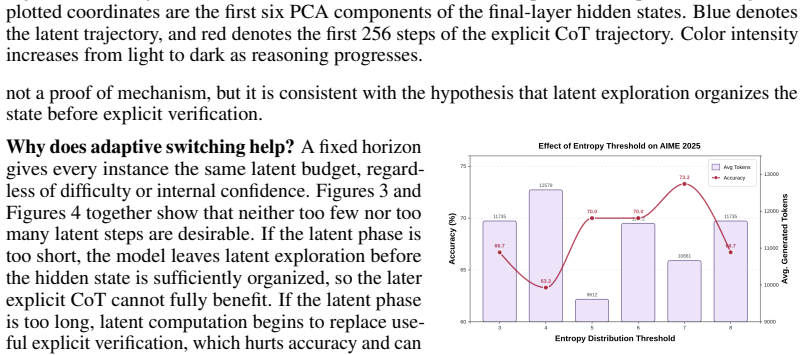
- The switch detection could be made adaptive to problem difficulty, allocating more latent steps to harder instances.
- The same latent-to-explicit handoff might combine with other inference techniques such as speculative decoding for additional savings.
Load-bearing premise
Projecting final-layer hidden states back to the input embedding space and using entropy plus model-native stop-token probes can reliably detect structured latent trajectories and trigger a safe switch to explicit verification without losing essential reasoning content.
What would settle it
Applying the training-free LaTER procedure to Qwen3-14B on AIME 2025 and finding that token counts remain at or above the 15,730 baseline while accuracy stays at or below 70% would show that the claimed efficiency gain does not occur.
Figures














read the original abstract
Chain-of-thought (CoT) reasoning improves large language models (LLMs) on difficult tasks, but it also makes inference expensive because every intermediate step must be generated as a discrete token. Latent reasoning reduces visible token generation by propagating continuous states, yet replacing explicit derivations with latent computation can hurt tasks that require symbolic checking. We propose Latent-Then-Explicit Reasoning (LaTER), a two-stage paradigm that first performs bounded exploration in a continuous latent space and then switches to explicit CoT for verification and answer generation. In a training-free instantiation, LaTER projects final-layer hidden states back to the input embedding space, preserves the latent KV cache, and uses entropy and model-native stop-token probes to decide when to switch. We find that strong reasoning models already exhibit structured latent trajectories under this interface. On Qwen3-14B, training-free LaTER reduces total token usage by 16%-32% on several benchmarks while matching or improving accuracy on most of them; for example, it improves AIME 2025 from 70.0% to 73.3% while reducing tokens from 15,730 to 10,661. We further construct Latent-Switch-69K, a supervised corpus that pairs condensed solution intuitions with shortened explicit derivations. Fine-tuning with latent rollout and halting supervision yields additional gains: trained LaTER reaches 80.0% accuracy on AIME 2025, 10.0 points above the standard CoT baseline, while using 33% fewer tokens. Our code, data, and model are available at https://github.com/TioeAre/LaTER.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes LaTER, a two-stage reasoning paradigm for LLMs: bounded exploration in continuous latent space (via projection of final-layer hidden states back to input embeddings while preserving KV cache) followed by explicit CoT verification triggered by entropy and model-native stop-token probes. Training-free LaTER on Qwen3-14B reduces token usage by 16-32% on benchmarks while matching or improving accuracy (e.g., AIME 2025: 70.0% to 73.3%, tokens 15,730 to 10,661). Fine-tuning on the new Latent-Switch-69K corpus yields further gains (80.0% on AIME 2025 with 33% fewer tokens than standard CoT). Code, data, and models are released.
Significance. If the latent-to-explicit switch reliably preserves reasoning content, LaTER could meaningfully advance efficient test-time reasoning by exploiting structured latent trajectories in strong models without full token generation. The public release of code, Latent-Switch-69K data, and models is a clear strength supporting reproducibility. The reported efficiency-accuracy trade-offs are practically relevant for long-horizon tasks, but hinge on unverified assumptions about probe robustness.
major comments (2)
- [§3 (Methods)] §3 (Methods): The training-free LaTER claims rest on the entropy and stop-token probes (applied to projected hidden states) safely detecting usable latent structure before switching. No ablation on probe thresholds, no qualitative inspection of projected tokens or trajectories, and no failure-case analysis on long-horizon tasks (e.g., AIME) are provided. This leaves open whether the 16-32% token reductions and accuracy lifts (e.g., +3.3 on AIME) arise from genuine latent reasoning or simply shorter sampling.
- [§4 (Experiments)] §4 (Experiments): Accuracy improvements such as the 3.3-point AIME 2025 gain and the fine-tuned 10-point lift are reported without error bars, multiple random seeds, statistical significance tests, or details on run variance. This undermines assessment of whether gains are robust or affected by benchmark selection/post-hoc choices, especially given the abstract's limited methodological visibility.
minor comments (2)
- [Abstract and §4] Abstract and §4: Explicitly state the number of evaluation runs or variance for all reported metrics to aid interpretation.
- [Throughout] Throughout: Ensure any figures depicting latent trajectories or probe decisions include detailed captions and axis labels for clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and describe the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [§3 (Methods)] §3 (Methods): The training-free LaTER claims rest on the entropy and stop-token probes (applied to projected hidden states) safely detecting usable latent structure before switching. No ablation on probe thresholds, no qualitative inspection of projected tokens or trajectories, and no failure-case analysis on long-horizon tasks (e.g., AIME) are provided. This leaves open whether the 16-32% token reductions and accuracy lifts (e.g., +3.3 on AIME) arise from genuine latent reasoning or simply shorter sampling.
Authors: We acknowledge that the current version lacks ablations on probe thresholds, qualitative trajectory inspections, and explicit failure-case analysis. In the revision we will add a dedicated subsection with threshold ablations (varying entropy and stop-token cutoffs) and report resulting accuracy/token trade-offs on AIME and other benchmarks. We will also include qualitative examples of projected tokens and latent trajectories for selected AIME problems, plus a short failure-case study showing when the switch occurs too early or too late. These additions will directly test whether gains derive from structured latent reasoning rather than reduced sampling length. revision: yes
-
Referee: [§4 (Experiments)] §4 (Experiments): Accuracy improvements such as the 3.3-point AIME 2025 gain and the fine-tuned 10-point lift are reported without error bars, multiple random seeds, statistical significance tests, or details on run variance. This undermines assessment of whether gains are robust or affected by benchmark selection/post-hoc choices, especially given the abstract's limited methodological visibility.
Authors: We agree that the absence of error bars, multi-seed statistics, and significance tests limits evaluation of robustness. In the revised manuscript we will rerun the main experiments (training-free and fine-tuned) with five random seeds, report mean and standard deviation for accuracy and token counts, and include paired statistical tests (e.g., Wilcoxon signed-rank) for the reported gains. We will also expand the abstract and experimental setup description to improve methodological visibility. revision: yes
Circularity Check
No circularity: empirical head-to-head evaluation on public benchmarks with no self-referential equations or fitted predictions
full rationale
The paper introduces LaTER as a two-stage procedure (latent exploration then explicit verification) whose training-free version projects final-layer states, preserves KV cache, and switches via entropy plus native stop-token probes. All headline results—16-32% token reduction and accuracy gains such as AIME 2025 from 70.0% to 73.3%—are obtained by direct comparison against standard CoT on fixed public benchmarks. No equation or derivation reduces the reported token counts or accuracies to parameters whose values are defined by those same metrics. The observation that strong models exhibit structured latent trajectories is presented as an empirical finding, not as an input that is re-derived by construction. No self-citation chain, ansatz smuggling, or renaming of known results is used to justify the central claims. The method is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Strong reasoning models exhibit structured latent trajectories in final-layer hidden states that can be projected and probed for switching decisions.
Reference graph
Works this paper leans on
-
[1]
Chain-of-thought prompting elicits reason- ing in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou. Chain-of-thought prompting elicits reason- ing in large language models. InAdvances in Neural Information Processing Sys- tems, 2022. URL https://proceedings.neurips.cc/paper_files/paper/2022/ file/9d5609613524ecf4f15af0f7b31abca4-Paper-Conference.pdf
work page 2022
-
[2]
Available: http://dx.doi.org/10.1038/s41586-025-09422-z
Daya Guo, Dejian Yang, Haowei Zhang, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, September 2025. doi: 10.1038/s41586-025-09422-z. URLhttp://dx.doi.org/10.1038/s41586-025-09422-z
-
[3]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Informa- tion Processing Systems, 2017. URL https://proceedings.neurips.cc/paper_files/ paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
work page 2017
-
[4]
Training large language models to reason in a continuous latent space
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason E Weston, and Yuandong Tian. Training large language models to reason in a continuous latent space. InSecond Conference on Language Modeling, 2025. URL https://openreview.net/forum?id= Itxz7S4Ip3
work page 2025
-
[6]
arXiv preprint arXiv:2511.20639 , year =
Jiaru Zou, Xiyuan Yang, Ruizhong Qiu, Gaotang Li, Katherine Tieu, Pan Lu, Ke Shen, Hang- hang Tong, Yejin Choi, Jingrui He, James Zou, Mengdi Wang, and Ling Yang. Latent collabora- tion in multi-agent systems, 2025. URLhttps://arxiv.org/abs/2511.20639
-
[7]
SoftCoT: Soft chain-of-thought for efficient reasoning with LLMs
Yige Xu, Xu Guo, Zhiwei Zeng, and Chunyan Miao. SoftCoT: Soft chain-of-thought for efficient reasoning with LLMs. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vienna, Austria, July 2025. doi: 10.18653/ v1/2025.acl-long.1137. URLhttps://aclanthology.org/2025.acl-long.1137/
work page 2025
-
[8]
The latent space: Foundation, evolution, mechanism, ability, and outlook,
Xinlei Yu, Zhangquan Chen, Yongbo He, Tianyu Fu, Cheng Yang, Chengming Xu, Yue Ma, Xiaobin Hu, Zhe Cao, Jie Xu, Guibin Zhang, Jiale Tao, Jiayi Zhang, Siyuan Ma, Kaituo Feng, Haojie Huang, Youxing Li, Ronghao Chen, Huacan Wang, Chenglin Wu, Zikun Su, Xiaogang Xu, Kelu Yao, Kun Wang, Chen Gao, Yue Liao, Ruqi Huang, Tao Jin, Cheng Tan, Jiangning Zhang, Wenqi...
- [9]
-
[10]
A survey on latent reasoning.arXiv preprint arXiv:2507.06203, 2025
Rui-Jie Zhu, Tianhao Peng, Tianhao Cheng, Xingwei Qu, Jinfa Huang, Dawei Zhu, Hao Wang, Kaiwen Xue, Xuanliang Zhang, Yong Shan, Tianle Cai, Taylor Kergan, Assel Kembay, Andrew Smith, Chenghua Lin, Binh Nguyen, Yuqi Pan, Yuhong Chou, Zefan Cai, Zhenhe Wu, Yongchi Zhao, Tianyu Liu, Jian Yang, Wangchunshu Zhou, Chujie Zheng, Chongxuan Li, Yuyin Zhou, Zhoujun...
-
[11]
Latent reasoning in llms as a vocabulary-space superposition,
Jingcheng Deng, Liang Pang, Zihao Wei, Shicheng Xu, Zenghao Duan, Kun Xu, Yang Song, Huawei Shen, and Xueqi Cheng. Latent reasoning in llms as a vocabulary-space superposition,
- [12]
-
[13]
Think silently, think fast: Dynamic latent compression of LLM reasoning chains
Wenhui Tan, Jiaze Li, Jianzhong Ju, Zhenbo Luo, Ruihua Song, and Jian Luan. Think silently, think fast: Dynamic latent compression of LLM reasoning chains. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview. net/forum?id=AQsko3PPUe
work page 2026
-
[14]
CODI: Com- pressing chain-of-thought into continuous space via self-distillation
Zhenyi Shen, Hanqi Yan, Linhai Zhang, Zhanghao Hu, Yali Du, and Yulan He. CODI: Com- pressing chain-of-thought into continuous space via self-distillation. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, Suzhou, China, November
work page 2025
-
[15]
CODI: compress- ing chain-of-thought into continuous space via self-distillation
doi: 10.18653/v1/2025.emnlp-main.36. URL https://aclanthology.org/2025. emnlp-main.36/
-
[16]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, et al. Qwen3 technical report, 2025. URL https://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Team Olmo, Allyson Ettinger, Amanda Bertsch, et al. Olmo 3, 2026. URL https://arxiv. org/abs/2512.13961
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Matharena: Evaluating llms on uncontaminated math competitions, February 2025
Mislav Balunovi ´c, Jasper Dekoninck, Ivo Petrov, Nikola Jovanovi ´c, and Martin Vechev. Matharena: Evaluating llms on uncontaminated math competitions, February 2025. URL https://matharena.ai/
work page 2025
-
[19]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step.arXiv preprint arXiv:2305.20050, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems, 2021. URL https://arxiv.org/ abs/2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[21]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA: A graduate-level google- proof q&a benchmark. InFirst Conference on Language Modeling, 2024. URL https: //openreview.net/forum?id=Ti67584b98
work page 2024
-
[22]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv:1803.05457v1, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[23]
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. Is your code generated by chatGPT really correct? rigorous evaluation of large language models for code generation. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URL https: //openreview.net/forum?id=1qvx610Cu7
work page 2023
-
[24]
Evaluating language models for efficient code generation
Jiawei Liu, Songrun Xie, Junhao Wang, Yuxiang Wei, Yifeng Ding, and Lingming Zhang. Evaluating language models for efficient code generation. InFirst Conference on Language Modeling, 2024. URLhttps://openreview.net/forum?id=IBCBMeAhmC
work page 2024
-
[25]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models, 2026. URLhttps://arxiv.org/abs/2601.18734
work page internal anchor Pith review arXiv 2026
-
[26]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019. URL https://openreview.net/forum? id=Bkg6RiCqY7
work page 2019
-
[27]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning, 2023. URLhttps://arxiv.org/abs/2307.08691
work page internal anchor Pith review arXiv 2023
-
[28]
Zero: memory optimiza- tions toward training trillion parameter models
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: memory optimiza- tions toward training trillion parameter models. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC ’20. IEEE Press, 2020. 11
work page 2020
-
[29]
Soft thinking: Unlocking the reasoning potential of LLMs in continuous concept space
Zhen Zhang, Xuehai He, Weixiang Yan, Ao Shen, Chenyang Zhao, and Xin Eric Wang. Soft thinking: Unlocking the reasoning potential of LLMs in continuous concept space. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview.net/forum?id=ByQdHPGKgU
work page 2026
-
[30]
Swireasoning: Switch-thinking in latent and explicit for pareto-superior reasoning llms,
Dachuan Shi, Abedelkadir Asi, Keying Li, Xiangchi Yuan, Leyan Pan, Wenke Lee, and Wen Xiao. Swireasoning: Switch-thinking in latent and explicit for pareto-superior reasoning llms,
- [31]
-
[32]
SeLaR: Selective Latent Reasoning in Large Language Models
Renyu Fu and Guibo Luo. Selar: Selective latent reasoning in large language models, 2026. URLhttps://arxiv.org/abs/2604.08299. 12 A Per-step entropy heterogeneity in training-free latent reasoning We provide a finer-grained view of the stopping signals used by the training-free version of LaTER. For each AIME 2025 problem, we begin with latent reasoning a...
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.