Recognition: no theorem link
SeLaR: Selective Latent Reasoning in Large Language Models
Pith reviewed 2026-05-10 18:22 UTC · model grok-4.3
The pith
SeLaR activates soft embeddings only at high-entropy steps while using discrete tokens elsewhere to boost reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SeLaR is a training-free framework that gates soft embeddings behind an entropy threshold so they activate only at low-confidence steps and remain inactive at high-confidence steps, while an entropy-aware contrastive loss keeps the activated soft embeddings from collapsing toward the highest-probability token and thereby sustains exploration of multiple latent reasoning trajectories.
What carries the argument
Entropy-gated activation of soft embeddings together with entropy-aware contrastive regularization, which measures per-step entropy to decide when to replace discrete token sampling with probability-weighted mixtures and then repels those mixtures from the mode token.
If this is right
- Reasoning accuracy rises on five standard benchmarks compared with plain chain-of-thought and other training-free baselines.
- High-confidence steps stay stable because discrete tokens are never replaced by noisy mixtures.
- Alternative reasoning paths remain open longer because soft embeddings are actively pushed away from the single most likely token.
- The entire procedure runs on existing models with no extra training or parameter updates.
Where Pith is reading between the lines
- The same entropy gate could be tested with other uncertainty signals such as token variance or self-consistency scores.
- Limiting soft embeddings to only uncertain steps may cut the extra compute that full latent methods incur on long chains.
- Combining the selective gate with tree search or self-refinement loops might amplify gains on problems that contain both easy and hard sub-steps.
Load-bearing premise
An entropy threshold can reliably mark the steps where soft embeddings help rather than harm, and the contrastive term sustains useful exploration without lowering final answer correctness.
What would settle it
Running SeLaR and standard chain-of-thought on the same five benchmarks and finding equal or lower accuracy for SeLaR would falsify the claim that selective activation plus contrastive regularization produces consistent gains.
Figures



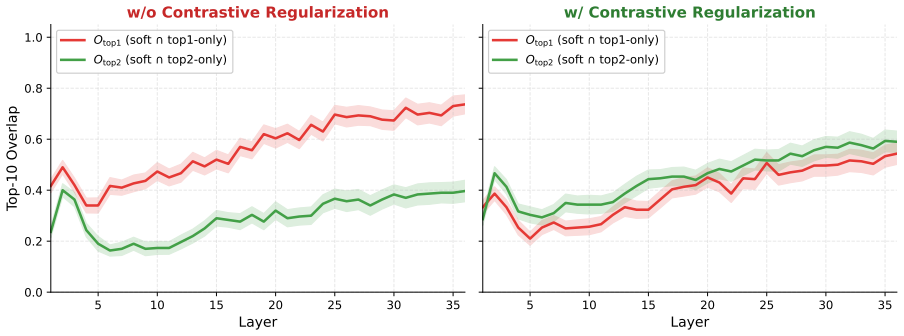

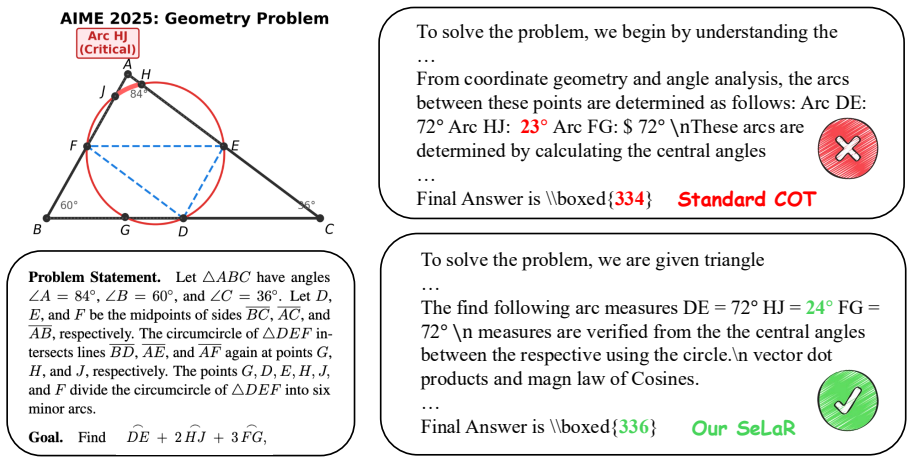

read the original abstract
Chain-of-Thought (CoT) has become a cornerstone of reasoning in large language models, yet its effectiveness is constrained by the limited expressiveness of discrete token sampling. Recent latent reasoning approaches attempt to alleviate this limitation by replacing discrete tokens with soft embeddings (probability-weighted mixtures of token embeddings) or hidden states, but they commonly suffer from two issues: (1) global activation injects perturbations into high-confidence steps, impairing reasoning stability; and (2) soft embeddings quickly collapse toward the highest-probability token, limiting exploration of alternative trajectories. To address these challenges, we propose SeLaR (Selective Latent Reasoning), a lightweight and training-free framework. SeLaR introduces an entropy-gated mechanism that activates soft embeddings only at low-confidence steps, while preserving discrete decoding at high-confidence steps. Additionally, we propose an entropy-aware contrastive regularization that pushes soft embeddings away from the dominant (highest-probability) token's direction, encouraging sustained exploration of multiple latent reasoning paths. Experiments on five reasoning benchmarks demonstrate that SeLaR consistently outperforms standard CoT and state-of-the-art training-free methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SeLaR, a training-free framework for improving Chain-of-Thought reasoning in LLMs. It introduces an entropy-gated selector that activates soft embeddings (latent representations) only at low-confidence steps while using discrete decoding elsewhere, plus an entropy-aware contrastive regularization term to prevent soft embeddings from collapsing to the dominant token and to sustain exploration of alternative reasoning paths. The central claim is that SeLaR consistently outperforms standard CoT and prior training-free latent reasoning methods across five reasoning benchmarks.
Significance. If the empirical results and robustness claims hold, SeLaR would represent a practical advance in training-free reasoning enhancement by selectively mitigating the stability issues of global soft-embedding methods and the exploration limits of discrete sampling. The combination of gating and contrastive regularization offers a lightweight mechanism that could generalize to other latent-space interventions in LLMs.
major comments (3)
- [§3] §3 (Method), entropy-gated mechanism: the entropy threshold is introduced as a fixed, reliable proxy for distinguishing low- vs. high-confidence steps, yet no sensitivity analysis, cross-model transfer results, or justification for its specific value is provided; this directly undermines the claim that selective activation reliably avoids injecting noise at high-confidence steps.
- [Experiments] Experiments section: the manuscript states outperformance on five benchmarks but supplies no tables with per-benchmark scores, baseline descriptions, number of runs, variance estimates, or statistical significance tests, rendering the headline empirical claim impossible to assess or reproduce from the provided information.
- [§3.3] §3.3 (Contrastive regularization): while the term is motivated as preventing collapse and sustaining exploration, no ablation isolating its contribution (with vs. without the contrastive loss) is reported, leaving open whether it maintains final answer quality or merely trades one form of degradation for another.
minor comments (2)
- [Abstract] The abstract lists 'five reasoning benchmarks' without naming them; adding the specific datasets (e.g., GSM8K, MATH) would improve clarity.
- [§3] Notation for soft embeddings and entropy calculation could be formalized with an equation in §3 to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major point below and will revise the manuscript to incorporate the requested analyses and details.
read point-by-point responses
-
Referee: [§3] §3 (Method), entropy-gated mechanism: the entropy threshold is introduced as a fixed, reliable proxy for distinguishing low- vs. high-confidence steps, yet no sensitivity analysis, cross-model transfer results, or justification for its specific value is provided; this directly undermines the claim that selective activation reliably avoids injecting noise at high-confidence steps.
Authors: We acknowledge that the manuscript does not provide a sensitivity analysis, cross-model results, or explicit justification for the entropy threshold value. In the revised manuscript, we will add a sensitivity analysis varying the threshold, report results across different models to show transfer, and include justification for the chosen value to support the claim of reliable selective activation. revision: yes
-
Referee: [Experiments] Experiments section: the manuscript states outperformance on five benchmarks but supplies no tables with per-benchmark scores, baseline descriptions, number of runs, variance estimates, or statistical significance tests, rendering the headline empirical claim impossible to assess or reproduce from the provided information.
Authors: We agree that detailed experimental information is necessary for assessing and reproducing the claims. We will revise the Experiments section to include tables with per-benchmark scores, full descriptions of baselines, the number of runs, variance estimates, and statistical significance tests. revision: yes
-
Referee: [§3.3] §3.3 (Contrastive regularization): while the term is motivated as preventing collapse and sustaining exploration, no ablation isolating its contribution (with vs. without the contrastive loss) is reported, leaving open whether it maintains final answer quality or merely trades one form of degradation for another.
Authors: We concur that an ablation is required to isolate the effect of the contrastive regularization. In the revision, we will report an ablation study with and without this term, demonstrating its impact on maintaining answer quality and exploration. revision: yes
Circularity Check
No circularity: SeLaR proposes independent entropy-gated and contrastive components without reduction to fitted inputs or self-citations
full rationale
The paper describes SeLaR as a lightweight training-free framework that adds an entropy-gated mechanism (activating soft embeddings only at low-confidence steps) and an entropy-aware contrastive regularization term. These are presented as direct solutions to two stated limitations of prior latent reasoning methods, with no equations, derivations, or predictions that reduce by construction to the inputs themselves. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. Empirical outperformance is claimed via experiments on benchmarks rather than tautological re-derivations. This is a standard proposal of algorithmic components whose validity rests on external evaluation, not internal definitional equivalence.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
LaTER: Efficient Test-Time Reasoning via Latent Exploration and Explicit Verification
LaTER reduces LLM token usage 16-33% on reasoning benchmarks by exploring in latent space then switching to explicit CoT verification, with gains like 70% to 73.3% on AIME 2025 in the training-free version.
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Marah Abdin, Sahaj Agarwal, Ahmed Awadallah, Vidhisha Balachandran, Harkirat Behl, Lingjiao Chen, Gustavo de Rosa, Suriya Gunasekar, Mojan Javaheripi, Neel Joshi, Piero Kauffmann, Yash Lara, Caio César Teodoro Mendes, Arindam Mitra, Besmira Nushi, Dimitris Papailiopoulos, Olli Saarikivi, Shital Shah, Vaishnavi Shrivastava, and 4 others. 2025. https://arxi...
-
[4]
Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, and Torsten Hoefler. 2024. https://doi.org/10.1609/aaai.v38i16.29720 Graph of thoughts: Solving elaborate problems with large language models . Proceedings of the AAAI Conference on Artificial ...
-
[5]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, and 12 others. 2020. https://arxiv.org/abs/2005.14165 Lan...
work page internal anchor Pith review Pith/arXiv arXiv 2020
- [6]
-
[7]
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, Kensen Shi, Sasha Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam Shazeer, Vinodkumar Prabhakaran, and 48 others. 2022. https://arxiv.org/abs/2204.02311 Palm: ...
work page internal anchor Pith review arXiv 2022
-
[8]
Zheng Chu, Jingchang Chen, Qianglong Chen, Weijiang Yu, Tao He, Haotian Wang, Weihua Peng, Ming Liu, Bing Qin, and Ting Liu. 2024. https://arxiv.org/abs/2309.15402 Navigate through enigmatic labyrinth a survey of chain of thought reasoning: Advances, frontiers and future . Preprint, arXiv:2309.15402
-
[9]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, and 181 others. 2025. https://arxiv.org/abs/2501.12948 Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement lea...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [10]
- [11]
-
[12]
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
Jonas Geiping, Sean McLeish, Neel Jain, John Kirchenbauer, Siddharth Singh, Brian R. Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein. 2025. https://arxiv.org/abs/2502.05171 Scaling up test-time compute with latent reasoning: A recurrent depth approach . Preprint, arXiv:2502.05171
work page internal anchor Pith review arXiv 2025
- [13]
-
[14]
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. 2025. https://arxiv.org/abs/2412.06769 Training large language models to reason in a continuous latent space . Preprint, arXiv:2412.06769
work page internal anchor Pith review arXiv 2025
-
[15]
Alex Havrilla, Yuqing Du, Sharath Chandra Raparthy, Christoforos Nalmpantis, Jane Dwivedi-Yu, Maksym Zhuravinskyi, Eric Hambro, Sainbayar Sukhbaatar, and Roberta Raileanu. 2024. https://arxiv.org/abs/2403.04642 Teaching large language models to reason with reinforcement learning . Preprint, arXiv:2403.04642
-
[16]
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021. https://arxiv.org/abs/2103.03874 Measuring mathematical problem solving with the math dataset . Preprint, arXiv:2103.03874
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[17]
HuggingFaceH4 . 2024. https://huggingface.co/datasets/HuggingFaceH4/aime_2024 AIME 2024: American Invitational Mathematics Examination . Hugging Face Dataset
2024
- [18]
- [19]
- [20]
- [21]
-
[22]
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. 2023. https://arxiv.org/abs/2303.17651 Self-refine: Iterative refinement with self-feedback . Preprin...
work page internal anchor Pith review arXiv 2023
- [23]
-
[24]
Nostalgebraist. 2020. https://www.lesswrong.com/posts/AcKRB8wDpdaN6v6ru/interpreting-gpt-the-logit-lens Interpreting gpt: The logit lens . Blog post on LessWrong
2020
-
[25]
gpt-oss-120b & gpt-oss-20b Model Card
OpenAI, :, Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K. Arora, Yu Bai, Bowen Baker, Haiming Bao, Boaz Barak, Ally Bennett, Tyler Bertao, Nivedita Brett, Eugene Brevdo, Greg Brockman, Sebastien Bubeck, and 108 others. 2025. https://arxiv.org/abs/2508.10925 gpt-oss-120b & gpt-oss-20b model card . Preprint, arXiv:...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
OpenAI, :, Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, Alex Iftimie, Alex Karpenko, Alex Tachard Passos, Alexander Neitz, Alexander Prokofiev, Alexander Wei, Allison Tam, and 244 others. 2024 a . https://arxiv.org/abs/2412.16720 Openai o1 system card . Preprint,...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Mohammad Bavarian, Jeff Belgum, and 262 others. 2024 b . https://arxiv.org/abs/2303.08774 Gpt-4 technica...
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [28]
-
[29]
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, and 25 others. 2025. https://arxiv.org/abs/2412.15115 Qwen2.5 technical report . Preprint, arXiv:2412.15115
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. 2024. https://openreview.net/forum?id=Ti67584b98 GPQA : A graduate-level google-proof q&a benchmark . In First Conference on Language Modeling
2024
-
[31]
Nikunj Saunshi, Stefani Karp, Shankar Krishnan, Sobhan Miryoosefi, Sashank J. Reddi, and Sanjiv Kumar. 2024. https://arxiv.org/abs/2409.19044 On the inductive bias of stacking towards improving reasoning . Preprint, arXiv:2409.19044
- [32]
-
[33]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. https://arxiv.org/abs/2402.03300 Deepseekmath: Pushing the limits of mathematical reasoning in open language models . Preprint, arXiv:2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [34]
-
[35]
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. https://arxiv.org/abs/2303.11366 Reflexion: Language agents with verbal reinforcement learning . Preprint, arXiv:2303.11366
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, Akshay Nathan, Alan Luo, Alec Helyar, Aleksander Madry, Aleksandr Efremov, Aleksandra Spyra, Alex Baker-Whitcomb, Alex Beutel, Alex Karpenko, and 465 others. 2025. https://arxiv.org/abs/2601.03267 Openai gpt-5 system ca...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [37]
- [38]
-
[39]
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, Chuning Tang, Congcong Wang, Dehao Zhang, Enming Yuan, Enzhe Lu, Fengxiang Tang, Flood Sung, Guangda Wei, Guokun Lai, and 77 others. 2025. https://arxiv.org/abs/2501.12599 Kimi k1.5: Scaling reinforcement learning with llms . Prep...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023. https://arxiv.org/abs/2302.13971 Llama: Open and efficient foundation language models . Preprint, arXiv:2302.13971
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Peiyi Wang, Lei Li, Zhihong Shao, R. X. Xu, Damai Dai, Yifei Li, Deli Chen, Y. Wu, and Zhifang Sui. 2024 a . https://arxiv.org/abs/2312.08935 Math-shepherd: Verify and reinforce llms step-by-step without human annotations . Preprint, arXiv:2312.08935
work page internal anchor Pith review arXiv 2024
- [42]
- [43]
-
[44]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. https://arxiv.org/abs/2203.11171 Self-consistency improves chain of thought reasoning in language models . Preprint, arXiv:2203.11171
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. 2023. https://arxiv.org/abs/2201.11903 Chain-of-thought prompting elicits reasoning in large language models . Preprint, arXiv:2201.11903
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [46]
-
[47]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, and 3 others. 2020. https://arxiv.org/abs/1910.03771 Huggingface's transformers: Sta...
work page internal anchor Pith review arXiv 2020
- [48]
- [49]
- [50]
-
[51]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others. 2025 a . https://arxiv.org/abs/2505.09388 Qwen3 technical report . Preprint, arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [52]
-
[53]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. https://arxiv.org/abs/2210.03629 React: Synergizing reasoning and acting in language models . Preprint, arXiv:2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[54]
Yentinglin . 2025. https://huggingface.co/datasets/yentinglin/aime_2025 AIME 2025: American Invitational Mathematics Examination . Hugging Face Dataset
2025
- [55]
- [56]
- [57]
- [58]
-
[59]
Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc Le, and Ed Chi. 2023. https://arxiv.org/abs/2205.10625 Least-to-most prompting enables complex reasoning in large language models . Preprint, arXiv:2205.10625
work page internal anchor Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.