Recognition: 2 theorem links
· Lean TheoremDiscovering Ordinary Differential Equations with LLM-Based Qualitative and Quantitative Evaluation
Pith reviewed 2026-05-11 00:59 UTC · model grok-4.3
The pith
DoLQ recovers true ordinary differential equations from data more successfully by using an LLM to check both numerical fit and physical plausibility.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
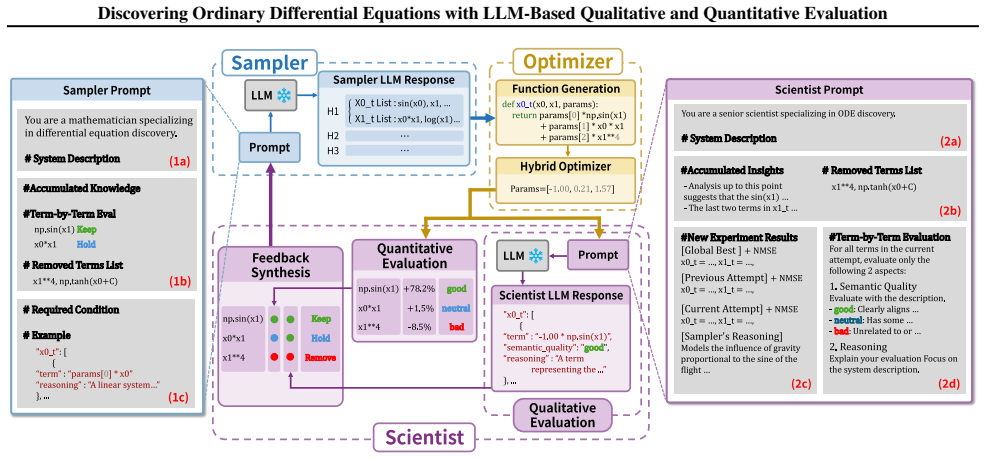
DoLQ employs a multi-agent architecture: a Sampler Agent proposes dynamic system candidates, a Parameter Optimizer refines equations for accuracy, and a Scientist Agent leverages an LLM to conduct both qualitative and quantitative evaluations and synthesize their results to iteratively guide the search. Experiments on multi-dimensional ordinary differential equation benchmarks demonstrate that DoLQ achieves superior performance compared to existing methods, not only attaining higher success rates but also more accurately recovering the correct symbolic terms of ground truth equations.
What carries the argument
The Scientist Agent, which uses an LLM to evaluate physical plausibility and domain knowledge alongside quantitative accuracy, then synthesizes the two judgments to direct the next round of candidate proposals.
If this is right
- Higher success rates on multi-dimensional ODE benchmarks than quantitative-only methods.
- More accurate recovery of the exact symbolic terms present in the ground-truth equations.
- Incorporation of domain knowledge to favor physically plausible equations even when multiple forms fit the data numerically.
- Iterative refinement of the equation set through combined qualitative and quantitative feedback.
Where Pith is reading between the lines
- The same multi-agent pattern could be tested on partial differential equations or discrete dynamical systems where qualitative constraints are also important.
- Performance may degrade if the underlying LLM lacks relevant scientific knowledge or changes between runs, pointing to a need for prompt stabilization or ensemble evaluation.
- This hybrid setup suggests a broader route for scientific machine learning in which language-model reasoning enforces consistency with known laws while data fitting supplies the coefficients.
Load-bearing premise
The LLM Scientist Agent can reliably judge physical plausibility and domain knowledge without hallucinations, training-data biases, or inconsistent judgments across repeated runs.
What would settle it
Running the Scientist Agent multiple times on identical candidate equations and checking whether its qualitative plausibility scores and term selections remain stable, or presenting a data-fitting but physically invalid equation and verifying that the agent consistently rejects it.
Figures















read the original abstract
Discovering governing differential equations from observational data is a fundamental challenge in scientific machine learning. Existing symbolic regression approaches rely primarily on quantitative metrics; however, real-world differential equation modeling also requires incorporating domain knowledge to ensure physical plausibility. To address this gap, we propose DoLQ, a method for discovering ordinary differential equations with LLM-based qualitative and quantitative evaluation. DoLQ employs a multi-agent architecture: a Sampler Agent proposes dynamic system candidates, a Parameter Optimizer refines equations for accuracy, and a Scientist Agent leverages an LLM to conduct both qualitative and quantitative evaluations and synthesize their results to iteratively guide the search. Experiments on multi-dimensional ordinary differential equation benchmarks demonstrate that DoLQ achieves superior performance compared to existing methods, not only attaining higher success rates but also more accurately recovering the correct symbolic terms of ground truth equations. Our code is available at https://github.com/Bon99yun/DoLQ.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DoLQ, a multi-agent architecture for ODE discovery from data consisting of a Sampler Agent for candidate generation, a Parameter Optimizer for fitting, and an LLM-powered Scientist Agent that performs qualitative evaluation of physical plausibility/domain knowledge alongside quantitative metrics to iteratively steer the search. Experiments on multi-dimensional ODE benchmarks are reported to show higher success rates and more accurate recovery of ground-truth symbolic terms than prior methods, with code released at https://github.com/Bon99yun/DoLQ.
Significance. If the performance gains hold under rigorous controls, the work would be significant for scientific machine learning by showing how LLM-based qualitative assessment can be integrated into symbolic regression pipelines to improve physical plausibility of discovered ODEs. The open-source code is a clear strength for reproducibility.
major comments (3)
- [Method] Method section (Scientist Agent description): the qualitative evaluation procedure supplies no prompt templates, temperature settings, consistency metrics across stochastic calls, or human-expert agreement studies; because the iterative guidance and claimed gains rest on these LLM judgments being stable and unbiased, this omission is load-bearing for the superiority claim over quantitative-only baselines.
- [Experiments] Experiments section: the headline results on success rates and symbolic-term recovery do not report the number of independent trials per benchmark, statistical significance tests, exact baseline implementations, or explicit handling of LLM stochasticity; without these, the gap between claim and verifiable evidence remains moderate.
- [Results] Results/discussion: the advantage attributed to the multi-agent design with LLM qualitative synthesis could arise from benchmark-specific LLM behavior rather than the architecture itself, given the absence of bias controls or ablation isolating the Scientist Agent's contribution.
minor comments (2)
- The abstract refers to 'multi-dimensional ordinary differential equation benchmarks' without enumerating the specific systems or providing a table of their dimensions and ground-truth forms.
- [Method] Notation for the combined qualitative-quantitative score synthesized by the Scientist Agent is introduced without an explicit equation or pseudocode step.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We appreciate the emphasis on reproducibility, statistical rigor, and isolating the contributions of our multi-agent design. Below we respond point-by-point to the major comments and indicate the revisions we will incorporate.
read point-by-point responses
-
Referee: [Method] Method section (Scientist Agent description): the qualitative evaluation procedure supplies no prompt templates, temperature settings, consistency metrics across stochastic calls, or human-expert agreement studies; because the iterative guidance and claimed gains rest on these LLM judgments being stable and unbiased, this omission is load-bearing for the superiority claim over quantitative-only baselines.
Authors: We agree that full transparency on the Scientist Agent is essential. In the revised manuscript we will add the complete prompt templates (both for qualitative physical-plausibility assessment and for synthesizing quantitative/qualitative scores), state the temperature (0.7) and other generation parameters, and report consistency metrics obtained by repeating each LLM call three times with different seeds and measuring agreement on the final recommendation. We did not conduct a formal human-expert agreement study in the original work; we will therefore add an explicit limitations paragraph acknowledging this gap and noting that LLM judgments may carry domain-specific biases. These changes directly address the load-bearing concern by allowing readers to reproduce and scrutinize the qualitative component. revision: partial
-
Referee: [Experiments] Experiments section: the headline results on success rates and symbolic-term recovery do not report the number of independent trials per benchmark, statistical significance tests, exact baseline implementations, or explicit handling of LLM stochasticity; without these, the gap between claim and verifiable evidence remains moderate.
Authors: We accept this criticism. The revised Experiments section will explicitly state that all reported figures are means over five independent trials per benchmark, include statistical significance tests (paired t-tests and Wilcoxon signed-rank tests with p-values) comparing DoLQ against each baseline, provide the precise code versions and hyper-parameters used for every baseline (with links to our re-implementations), and describe our handling of LLM stochasticity via fixed random seeds plus reporting of standard deviations across runs. These additions will close the gap between claims and verifiable evidence. revision: yes
-
Referee: [Results] Results/discussion: the advantage attributed to the multi-agent design with LLM qualitative synthesis could arise from benchmark-specific LLM behavior rather than the architecture itself, given the absence of bias controls or ablation isolating the Scientist Agent's contribution.
Authors: We recognize the need to isolate the Scientist Agent's contribution. In the revision we will add a dedicated ablation study that runs the full DoLQ pipeline against an otherwise identical quantitative-only variant (i.e., Sampler + Parameter Optimizer without the LLM qualitative synthesis step). We will also expand the benchmark suite and include a short discussion of potential LLM biases together with controls (e.g., temperature sweeps and prompt-variation checks). These new results will allow readers to assess whether the observed gains are attributable to the multi-agent architecture rather than benchmark-specific LLM behavior. revision: yes
Circularity Check
No circularity: empirical multi-agent method with external LLM judgments and benchmark validation
full rationale
The paper describes an algorithmic framework (Sampler, Optimizer, Scientist Agent) that uses an LLM for qualitative evaluation of physical plausibility and combines it with quantitative metrics to guide iterative search for ODEs. Performance is assessed via success rates and symbolic recovery on external multi-dimensional ODE benchmarks, with no mathematical derivation chain, fitted parameters renamed as predictions, or self-citations that bear the central claim. The LLM judgments are treated as an independent external input rather than derived from the method's own outputs, and the architecture does not reduce any claimed result to a quantity defined in terms of its own fitted values or prior self-referential theorems. This is a standard empirical proposal whose validity rests on experimental outcomes outside the paper's internal definitions.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DoLQ employs a multi-agent architecture: a Sampler Agent proposes dynamic system candidates, a Parameter Optimizer refines equations for accuracy, and a Scientist Agent leverages an LLM to conduct both qualitative and quantitative evaluations
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
terms are classified into three categories: good (terms whose removal significantly increases error...), neutral..., and bad...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Abhimanyu Das, Weihao Kong, Rajat Sen, and Yichen Zhou
URL https://proceedings.mlr.press/ v139/biggio21a.html. Brunton, S. L., Proctor, J. L., and Kutz, J. N. Discovering governing equations from data by sparse identification of nonlinear dynamical systems.Proceedings of the National Academy of Sciences, 113(15):3932– 3937, 2016. doi: 10.1073/pnas.1517384113. URL https://www.pnas.org/doi/abs/10.1073/ pnas.151...
-
[2]
URL http://arxiv.org/abs/2305. 01582. arXiv:2305.01582 [astro-ph, physics:physics]. Cranmer, M., Greydanus, S., Hoyer, S., Battaglia, P., Spergel, D., and Ho, S. Lagrangian neural networks. InICLR 2020 Workshop on Integration of Deep Neural Models and Differential Equations, 2019. URLhttps: //openreview.net/forum?id=iE8tFa4Nq. Czarnecki, W. M., Osindero, ...
work page internal anchor Pith review arXiv 2020
-
[3]
cc/paper_files/paper/2017/file/ 758a06618c69880a6cee5314ee42d52f- Paper.pdf
URL https://proceedings.neurips. cc/paper_files/paper/2017/file/ 758a06618c69880a6cee5314ee42d52f- Paper.pdf. d’Ascoli, S. et al. Odeformer: Symbolic regression of dynamical systems with transformers. InPro- ceedings of the 12th International Conference on Learning Representations (ICLR), Vienna, Austria,
2017
-
[4]
ICLR 2024
URL https://openreview.net/forum? id=TzoHLiGVMo. ICLR 2024. Du, M., Chen, Y ., Wang, Z., Nie, L., and Zhang, D. Large language models for automatic equation discovery of nonlinear dynamics.Physics of Fluids, 36(9):097121, 09
2024
-
[5]
ISSN 1070-6631. doi: 10.1063/5.0224297. URL https://doi.org/10.1063/5.0224297. Dupont, E., Doucet, A., and Teh, Y . W. Augmented neural odes. InAdvances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 9 Discovering Ordinary Differential Equations with LLM-Based Qualitative and Quantitative Evaluation
-
[6]
cc/paper_files/paper/2019/file/ 21be9a4bd4f81549a9d1d241981cec3c- Paper.pdf
URL https://proceedings.neurips. cc/paper_files/paper/2019/file/ 21be9a4bd4f81549a9d1d241981cec3c- Paper.pdf. Fletcher, R.Practical methods of optimization. John Wiley & Sons, 2013. Gao, E.-H. et al. Probabilistic grammars for modeling dy- namical systems from coarse, noisy, and partial data.Re- search Square, 2023. Grayeli, A., Sehgal, A., Costilla-Reyes...
-
[7]
Proceedings of the National Academy of Sciences120(33) (2023) https://doi.org/10.1073/pnas
URL https://proceedings.neurips. cc/paper_files/paper/2019/file/ 26cd8ecadce0d4efd6cc8a8725cbd1f8- Paper.pdf. Guo, Z., Wang, S., Tian, Y ., Yang, J., Yu, H., Na, X., Kov´acs, L., Li, L., Ioannou, P. A., and Wang, F.- Y . Sr-llm: An incremental symbolic regression frame- work driven by llm-based retrieval-augmented gener- ation.Proceedings of the National ...
-
[8]
Kamienny, P.-A., d’Ascoli, S., Lample, G., and Charton, F
URL https://openreview.net/forum? id=Wic0OgYsgy. Kamienny, P.-A., d’Ascoli, S., Lample, G., and Charton, F. End-to-end symbolic regression with transform- ers. In Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., and Oh, A. (eds.),Advances in Neural Information Processing Systems, vol- ume 35, pp. 10269–10281. Curran Associates, Inc.,
-
[9]
cc/paper_files/paper/2022/file/ 42eb37cdbefd7abae0835f4b67548c39- Paper-Conference.pdf
URL https://proceedings.neurips. cc/paper_files/paper/2022/file/ 42eb37cdbefd7abae0835f4b67548c39- Paper-Conference.pdf. Karniadakis, G. E., Kevrekidis, I. G., Lu, L., et al. Physics- informed machine learning.Nature Reviews Physics, 3: 422–440, 2021. Koza, J. R.Genetic Programming: On the Programming of Computers by Means of Natural Selection. MIT Press,...
2022
-
[10]
URL https://www.sciencedirect.com/ science/article/pii/S0021999122009019
doi: https://doi.org/10.1016/j.jcp.2022.111838. URL https://www.sciencedirect.com/ science/article/pii/S0021999122009019. Lu, C., Lu, C., Lange, R. T., Foerster, J., Clune, J., and Ha, D. The ai scientist: Towards fully automated open-ended sci- entific discovery, 2024. URL https://arxiv.org/ abs/2408.06292. Matsubara, Y ., Chiba, N., Igarashi, R., and Us...
-
[11]
Merler, M., Haitsiukevich, K., Dainese, N., and Martti- nen, P
URL https://openreview.net/forum? id=KZSEgJGPxu. Merler, M., Haitsiukevich, K., Dainese, N., and Martti- nen, P. In-context symbolic regression: Leveraging large language models for function discovery. In Fu, X. and Fleisig, E. (eds.),Proceedings of the 62nd An- nual Meeting of the Association for Computational Lin- guistics (Volume 4: Student Research Wo...
2024
-
[12]
URL https: //aclanthology.org/2024.acl-srw.49/
doi: 10.18653/v1/2024.acl-srw.49. URL https: //aclanthology.org/2024.acl-srw.49/. Mundhenk, T., Landajuela, M., Glatt, R., Santiago, C. P., faissol, D., and Petersen, B. K. Symbolic regression via deep reinforcement learning enhanced genetic programming seeding. In Ranzato, M., Beygelzimer, 10 Discovering Ordinary Differential Equations with LLM-Based Qua...
-
[13]
cc/paper_files/paper/2021/file/ d073bb8d0c47f317dd39de9c9f004e9d- Paper.pdf
URL https://proceedings.neurips. cc/paper_files/paper/2021/file/ d073bb8d0c47f317dd39de9c9f004e9d- Paper.pdf. Oliveira, L. O. V ., Martins, J. F. B., Miranda, L. F., and Pappa, G. L. Analysing symbolic regression benchmarks under a meta-learning approach. InProceedings of the Genetic and Evolutionary Computation Conference Com- panion, pp. 1342–1349, 2018...
2021
-
[14]
URL https: //doi.org/10.1007/s10994-024-06522-1
doi: 10.1007/s10994-024-06522-1. URL https: //doi.org/10.1007/s10994-024-06522-1. Park, D., Moon, H., and Ryu, S. A self-correcting multi- agent llm framework for language-based physics sim- ulation and explanation.npj Artificial Intelligence, 2 (1):10, 2026. ISSN 3005-1460. doi: 10.1038/s44387- 025-00057-z. URL https://doi.org/10.1038/ s44387-025-00057-z...
-
[15]
Rubanova, Y ., Chen, R
URL https://www.sciencedirect.com/ science/article/pii/S0021999118307125. Rubanova, Y ., Chen, R. T. Q., and Duvenaud, D. K. Latent ordinary differential equations for irregularly-sampled time series. InAdvances in Neural Information Pro- cessing Systems, volume 32. Curran Associates, Inc.,
-
[16]
URL https://proceedings.neurips. cc/paper_files/paper/2019/file/ 42a6845a557bef704ad8ac9cb4461d43- Paper.pdf. Rudin, C. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead.Nature machine intelligence, 1(5):206– 215, 2019. Schmidt, M. and Lipson, H. Distilling free-form natural laws from experime...
-
[17]
AI Feynman: A physics-inspired method for symbolic regression.Science Advances, 6(16):eaay2631, 2020
URL https://proceedings.neurips. cc/paper_files/paper/2023/file/ 8ffb4e3118280a66b192b6f06e0e2596- Paper-Conference.pdf. Shojaee, P., Meidani, K., Gupta, S., Farimani, A. B., and Reddy, C. K. LLM-SR: Scientific equation discovery via programming with large language models. InThe Thir- teenth International Conference on Learning Represen- tations, 2025. UR...
-
[18]
+ (0.0004499464651382155∗x2) + (0.0002873146658744879∗x3) + (3.203979516768474e−05∗x0∗x1) ˙x2 (−(−8.313688998942643e−05)∗sin(x1)) + (0.00012926385963329574∗ −0.0002110727122192323∗x3∗x0 2 ∗sin(x1)) + (−0.00012926385963329574∗ 0.05∗x0 2 ∗cos(x1)) + (−0.00012926385963329574∗1.5157577205870516∗ (−0.0002110727122192323∗x3) 2 ∗x0 2 ∗cos(x1))+(−1.0∗exp(−((x3−1....
-
[20]
-- This system is 2-dimensional -- Variables x2 and above do not exist
Target System Context: Input variables are x0, x1. -- This system is 2-dimensional -- Variables x2 and above do not exist
-
[21]
x0", "np.sin(x0)
Term Format: Propose terms WITHOUT coefficients. The system will automatically attach trainable parameters. -- Correct: "x0", "np.sin(x0)", "x0 *x1" -- Incorrect: "params[0] *x0", "C *x0", "0.5 *x0"
-
[22]
np.sin(2 *x0)
Term Complexity: You MAY use internal constants if they have physical meaning (e.g., frequency, phase). -- Example: "np.sin(2 *x0)" is allowed and encouraged if the factor 2 is significant. -- Note: The system will still attach an outer trainable parameter (e.g., params[0] *np.sin(2*x0))
-
[23]
9.81 *x0
Symbolic Constants: Do NOT use symbolic constants like ’g’, ’k’, ’m’. Use numerical values. -- Correct: "9.81 *x0" (if g=9.81 is known), "np.pi *x0" -- Incorrect: "g *x0" (will cause NameError)
-
[25]
x0", "x1
Reasoning required: When proposing each term, provide a physical/mathematical reasoning based on the system description (desc). [Example (2D System)] x0 t: ["x0", "x1"] x1 t: ["x0", "np.sin(x1)"] Figure 16.Initial prompt to the Sampler agent at iteration 1, where accumulated knowledge, term-level evaluation, and removed-term history are empty at initializ...
-
[26]
You can use: import numpy as np
-
[27]
- This system is 4-dimensional - Variables x4 and above do not exist
Target System Context: Input variables are x0, x1, x2, x3. - This system is 4-dimensional - Variables x4 and above do not exist
-
[28]
x0", "np.sin(x0)
Term Format: Propose terms WITHOUT coefficients. The system will automatically attach trainable parameters. - Correct: "x0", "np.sin(x0)", "x0 *x1" - Incorrect: "params[0] *x0", "C *x0", "0.5 *x0"
-
[29]
np.sin(2 *x0)
Term Complexity: You MAY use internal constants if they have physical meaning (e.g., frequency, phase). - Example: "np.sin(2 *x0)" is allowed and encouraged if the factor 2 is significant. - Note: The system will still attach an outer trainable parameter (e.g., params[0] *np.sin(2*x0))
-
[30]
9.81 *x0
Symbolic Constants: Do NOT use symbolic constants like ’g’, ’k’, ’m’. Use numerical values. - Correct: "9.81 *x0" (if g=9.81 is known), "np.pi *x0" - Incorrect: "g *x0" (will cause NameError)
-
[31]
Structural modifications are required
No duplicates: Equations identical to previous attempts are forbidden. Structural modifications are required
-
[32]
x0", "x1 *x2
Reasoning required: When proposing each term, provide a physical/mathematical reasoning based on the system description (desc). [Example (4D System)] x0 t: ["x0", "x1 *x2", "x3"] x1 t: ["x0", "np.sin(x1)"] x2 t: ["x0 *x1"] x3 t: ["-9.81", "x0"] Figure 12.The Sampler Prompt. The labeled sections(1a)-(1c)correspond to the Sampler components in Figure 2:(1a)...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.