Recognition: no theorem link
SparseRL-Sync: Lossless Weight Synchronization with ~100x Less Communication
Pith reviewed 2026-05-11 01:20 UTC · model grok-4.3
The pith
Sparse synchronization sends only changed weight indices and values to cut RL communication volume by about 100 times while reconstructing full weights exactly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In mainstream large-model RL training the locations where parameters actually change are highly sparse at the element level, often 99 percent or more. SparseRL-Sync replaces full-weight transfers with a lossless sparse update payload of indices and values that can be exactly reconstructed on the inference side, preserving 100 percent fidelity. Under a simplified cost model this reduces the per-update communication volume from S to approximately S/X, yielding about a 100x reduction in transmitted data with 99 percent sparsity, and bucketing further cuts launch and control-plane overhead.
What carries the argument
The lossless sparse update payload of parameter indices paired with their new values, sent in place of dense weights and grouped via bucketing to reduce overhead.
If this is right
- Per-update communication volume falls from full size S to roughly S/X when sparsity reaches 99 percent.
- Launch and control-plane overhead shrinks because payloads are smaller and can be bucketed.
- Scalability improves in bandwidth-limited, cross-datacenter, or highly asynchronous RL settings.
- Policy fidelity stays identical to full-weight synchronization, so training quality is unaffected.
- End-to-end throughput rises when weight synchronization previously dominated the timeline.
Where Pith is reading between the lines
- The same sparse-payload approach could reduce communication in other distributed training workloads if their update patterns exhibit comparable element-wise sparsity.
- Variable-bandwidth environments such as online RL or heterogeneous clusters would see the largest relative gains in tail latency.
- Combining the index-value format with further encoding of the index list itself might yield additional savings beyond the basic 100x factor.
Load-bearing premise
The element-level locations of actual parameter changes remain highly sparse, around 99 percent or more, consistently across training steps and model scales.
What would settle it
Measure the fraction of parameters whose values differ by more than a small numerical threshold between successive policy updates in a production-scale RL run; if the average sparsity falls below roughly 90 percent the claimed reduction factor would not hold.
Figures


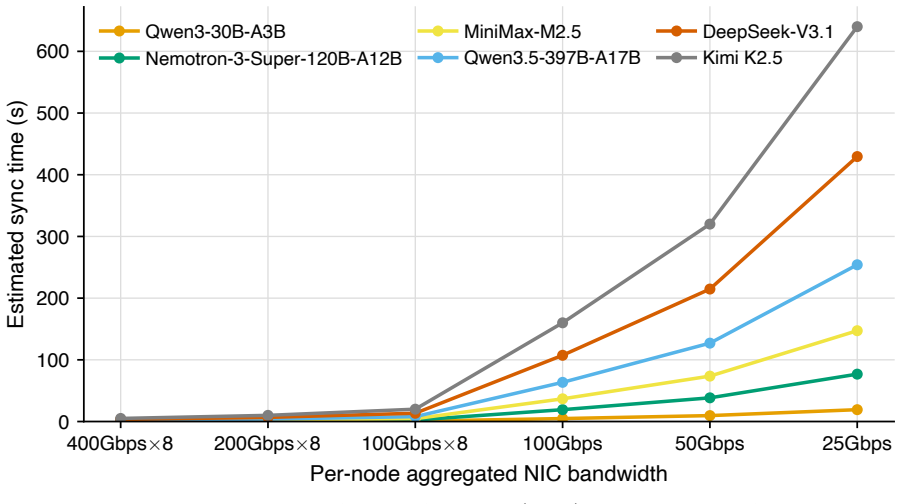
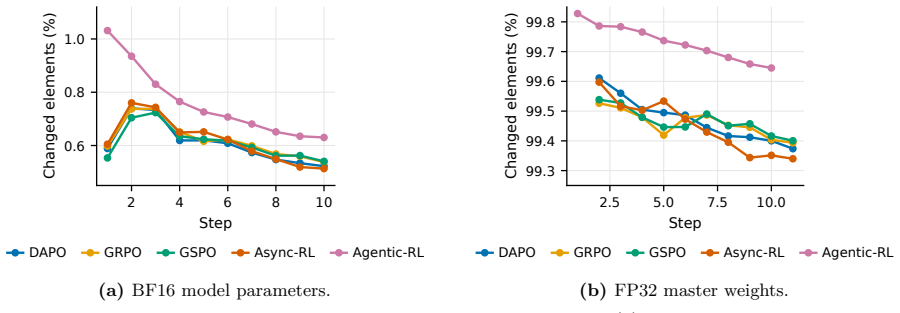






read the original abstract
In large-scale reinforcement learning (RL) systems with decoupled Trainer-Rollout execution, the Trainer must regularly synchronize policy weights to the Rollout side to limit policy staleness. When inter-node bandwidth is abundant, such synchronization is usually only a small fraction of end-to-end cost. As model size grows, however, the communication demand rises rapidly. In bandwidth-constrained or network-variable deployments -- for example, cross-datacenter or cross-cluster settings, heterogeneous resource pools, and online RL -- weight synchronization can become a dominant bottleneck for throughput and tail latency. We observe that, in mainstream large-model RL training, the locations where parameters actually change are highly sparse at the element level (often 99%+ sparsity). Building on this observation, we propose and implement SparseRL-Sync, which replaces full-weight transfers with a lossless sparse update payload (indices and values) that can be exactly reconstructed on the inference side, thereby preserving 100% fidelity. Under a simplified cost model, sparse synchronization reduces the per-update communication volume from S to approximately S/X; with 99% sparsity (X ~ 100), this yields about a 100x reduction in transmitted data. Combined with appropriate bucketing, SparseRL-Sync also reduces launch and control-plane overhead, significantly improving scalability and end-to-end efficiency in bandwidth-limited and highly asynchronous RL settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in large-scale RL with decoupled Trainer-Rollout execution, parameter updates exhibit high element-level sparsity (often 99%+). SparseRL-Sync replaces full weight transfers with a lossless sparse payload of indices and values that can be exactly reconstructed, preserving 100% fidelity. Under a simplified cost model, this reduces per-update communication volume from S to approximately S/X, yielding ~100x savings at 99% sparsity (X~100); bucketing further reduces launch and control-plane overhead in bandwidth-constrained or asynchronous settings.
Significance. If the sparsity observation proves consistent across steps and scales and sparse handling overhead remains low, the approach could meaningfully improve throughput and scalability for RL training in cross-datacenter, heterogeneous, or online settings by addressing communication bottlenecks without fidelity loss. The lossless reconstruction property is a clear strength.
major comments (2)
- [Abstract] Abstract: The central quantitative claim that sparse synchronization reduces volume from S to S/X (~100x at 99% sparsity) relies on a simplified cost model that sets index transmission cost to zero. With standard 32-bit indices and 32-bit float values, each changed element costs 8 bytes; at 1% density the transmitted volume is 0.01*(8/4)=0.02 of dense size, for only a 50x reduction. The S/X approximation is therefore overstated unless a specific low-overhead indexing scheme (e.g., bitmap or delta-encoded) is defined and analyzed.
- [Abstract] Abstract: No experimental measurements, sparsity statistics across training steps or model scales, overhead benchmarks, or end-to-end throughput results are supplied to support the 99%+ sparsity observation or to validate that reconstruction preserves fidelity at scale. This leaves the empirical premise of the ~100x claim unverified.
minor comments (2)
- The description of bucketing and its interaction with sparse payloads to reduce control-plane overhead would benefit from a concrete example or pseudocode.
- Notation for the cost model (S, X) should be defined explicitly when first introduced.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. The two major comments highlight important aspects of our presentation that require clarification and qualification. We address each point below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central quantitative claim that sparse synchronization reduces volume from S to S/X (~100x at 99% sparsity) relies on a simplified cost model that sets index transmission cost to zero. With standard 32-bit indices and 32-bit float values, each changed element costs 8 bytes; at 1% density the transmitted volume is 0.01*(8/4)=0.02 of dense size, for only a 50x reduction. The S/X approximation is therefore overstated unless a specific low-overhead indexing scheme (e.g., bitmap or delta-encoded) is defined and analyzed.
Authors: We agree that the abstract employs a simplified cost model that focuses on the value payload and treats index overhead as secondary. The manuscript describes the payload as indices plus values but does not specify or analyze a particular index encoding. We will revise the abstract and add a short paragraph in the main text to explicitly state the assumptions of the model, provide the more accurate 32-bit index + 32-bit value calculation the referee notes, and discuss practical low-overhead schemes (compressed bitmaps, run-length encoding, or delta indexing) that can substantially reduce index cost at high sparsity. This will qualify the ~100x figure as an upper-bound under the simplified model while showing how closer-to-ideal savings remain achievable. revision: partial
-
Referee: [Abstract] Abstract: No experimental measurements, sparsity statistics across training steps or model scales, overhead benchmarks, or end-to-end throughput results are supplied to support the 99%+ sparsity observation or to validate that reconstruction preserves fidelity at scale. This leaves the empirical premise of the ~100x claim unverified.
Authors: The sparsity observation is drawn from our internal large-scale RL training runs, and the lossless reconstruction follows directly from transmitting exact indices and values. However, the current manuscript presents these as motivating observations without accompanying statistics, overhead measurements, or end-to-end results. We will revise the text to (1) qualify the 99%+ figure as an observed range rather than a universal claim, (2) add a brief discussion of the source of the observation with illustrative (non-proprietary) examples, and (3) explicitly note that comprehensive benchmarks are left for future work. We cannot introduce new large-scale experiments in this revision cycle. revision: partial
- Absence of quantitative sparsity statistics, overhead benchmarks, and end-to-end throughput measurements to support the empirical claims.
Circularity Check
No circularity: central claim follows from external empirical sparsity observation
full rationale
The paper states an empirical observation of 99%+ element-level sparsity in parameter updates during large-model RL training as an external fact, then applies a simplified cost model to conclude that sparse synchronization reduces volume from S to approximately S/X (with X~100 yielding ~100x reduction). This scaling is a direct arithmetic consequence of the input sparsity level rather than any self-referential derivation, fitted parameter, or self-citation chain. No equations, uniqueness theorems, or ansatzes are introduced that reduce the result to the paper's own outputs by construction. The derivation remains self-contained against the stated observation and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- sparsity factor X
axioms (1)
- domain assumption Parameter updates exhibit high element-level sparsity (99%+) in mainstream large-model RL training
Reference graph
Works this paper leans on
-
[3]
Advances in Neural Information Processing Systems , volume =
Training language models to follow instructions with human feedback , author =. Advances in Neural Information Processing Systems , volume =
- [4]
-
[5]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Zhihong and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Song, Junxiao and Bi, Xiao and others , year =. 2402.03300 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Yu and others , year =
-
[7]
Reasoning-burden of long chain-of-thought RL fine-tuning , author =. 2025 , note =
work page 2025
-
[8]
Kazemnejad, Amirhossein and others , year =
-
[9]
Gao and others , year =
-
[10]
Zheng and others , year =
-
[11]
Le Roux, Nicolas and others , year =
-
[12]
Tapered importance weights for off-policy
Arnal and others , year =. Tapered importance weights for off-policy
-
[13]
Wang and others , year =
-
[14]
Tang and others , year =
-
[15]
Nan and others , year =
-
[16]
2024 , howpublished =
work page 2024
- [17]
-
[18]
Seide, Frank and Fu, Hao and Droppo, Jasha and Li, Gang and Yu, Dong , booktitle =. 1-bit stochastic gradient descent and its application to data-parallel distributed training of speech
-
[19]
Wen, Wei and Xu, Cong and Yan, Feng and Wu, Chunpeng and Wang, Yandan and Chen, Yiran and Li, Hai , booktitle =
-
[20]
Sparse Communication for Distributed Gradient Descent , author =. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
work page 2017
-
[21]
International Conference on Learning Representations (ICLR) , year =
Deep Gradient Compression: Reducing the Communication Bandwidth for Distributed Training , author =. International Conference on Learning Representations (ICLR) , year =
-
[22]
Vogels, Thijs and Karimireddy, Sai Praneeth and Jaggi, Martin , booktitle =
-
[23]
Collet, Yann and Kucherawy, Murray , year =
-
[24]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Shoeybi, Mohammad and Patwary, Mostofa and Puri, Raul and LeGresley, Patrick and Casper, Jared and Catanzaro, Bryan , year =. 1909.08053 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[25]
Zhao, Yanli and Gu, Andrew and Varma, Rohan and Luo, Liang and Huang, Chien-Chin and Xu, Min and Wright, Less and Shojanazeri, Hamid and Ott, Myle and Shleifer, Sam and Desmaison, Alban and Balioglu, Can and Damania, Pritam and Nguyen, Bernard and Chauhan, Geeta and Hao, Yuchen and Mathews, Ajit and Li, Shen , booktitle =. 2023 , eprint =
work page 2023
-
[26]
2026 , howpublished =
work page 2026
-
[27]
Sparse communication for distributed gradient descent
Alham Fikri Aji and Kenneth Heafield. Sparse communication for distributed gradient descent. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2017
work page 2017
-
[28]
AReaL : Towards fully asynchronous reinforcement learning for large language models, 2024 a
Anonymous . AReaL : Towards fully asynchronous reinforcement learning for large language models, 2024 a . TODO: confirm citation key and arXiv id
work page 2024
-
[29]
ROLL : Heterogeneous reinforcement learning for large models, 2024 b
Anonymous . ROLL : Heterogeneous reinforcement learning for large models, 2024 b . TODO: confirm citation key and arXiv id
work page 2024
-
[30]
AWex : Asynchronous weight exchange for large-model RL training
Ant Group / inclusionAI . AWex : Asynchronous weight exchange for large-model RL training. GitHub repository, 2024. URL https://github.com/inclusionAI/asystem-awex
work page 2024
-
[31]
Composer2: Multi-cluster RL training at C ursor
Cursor . Composer2: Multi-cluster RL training at C ursor. Technical report, 2024. TODO: replace with the canonical URL once published
work page 2024
-
[32]
SAPO : Soft asymmetric policy optimization, 2025
Gao et al. SAPO : Soft asymmetric policy optimization, 2025. TODO: confirm citation; sigmoid-based soft gating
work page 2025
-
[33]
VinePPO : Unlocking RL potential for llm reasoning through refined credit assignment, 2024
Amirhossein Kazemnejad et al. VinePPO : Unlocking RL potential for llm reasoning through refined credit assignment, 2024. TODO: confirm citation; cited in info.md as Kazemnejad et al., 2024
work page 2024
-
[34]
TOPR : Tapered off-policy REINFORCE for stable off-policy learning, 2025
Nicolas Le Roux et al. TOPR : Tapered off-policy REINFORCE for stable off-policy learning, 2025. TODO: confirm citation
work page 2025
-
[35]
Yujun Lin, Song Han, Huizi Mao, Yu Wang, and William J. Dally. Deep gradient compression: Reducing the communication bandwidth for distributed training. In International Conference on Learning Representations (ICLR), 2018
work page 2018
-
[36]
Erfan Miahi and Eugene Belilovsky. Understanding and exploiting weight update sparsity for communication-efficient distributed RL , 2026. URL https://arxiv.org/abs/2602.03839
-
[37]
Moonshot AI . Kimi checkpoint engine. GitHub repository, 2024. URL https://github.com/MoonshotAI/checkpoint-engine
work page 2024
-
[38]
NGRPO : Negative-aware group relative policy optimization, 2025
Nan et al. NGRPO : Negative-aware group relative policy optimization, 2025. TODO: confirm citation
work page 2025
-
[39]
Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35, 2022
work page 2022
-
[40]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms, 2017. URL https://arxiv.org/abs/1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[41]
Helix : An RL training framework
Scitix . Helix : An RL training framework. GitHub repository, 2026. URL https://github.com/scitix/helix. Repository to be released; placeholder URL
work page 2026
-
[42]
Frank Seide, Hao Fu, Jasha Droppo, Gang Li, and Dong Yu. 1-bit stochastic gradient descent and its application to data-parallel distributed training of speech DNNs . In Fifteenth Annual Conference of the International Speech Communication Association (INTERSPEECH), 2014
work page 2014
-
[43]
DeepSeekMath : Pushing the limits of mathematical reasoning in open language models, 2024
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, et al. DeepSeekMath : Pushing the limits of mathematical reasoning in open language models, 2024. Introduces Group Relative Policy Optimization (GRPO)
work page 2024
-
[44]
A3PO : Adaptive advantage shaping for policy optimization, 2025
Tang et al. A3PO : Adaptive advantage shaping for policy optimization, 2025. TODO: confirm citation
work page 2025
-
[45]
slime : an open-source framework for large-model reinforcement learning
THU-DCST . slime : an open-source framework for large-model reinforcement learning. GitHub repository, 2024. URL https://github.com/THU-DCST/slime. TODO: confirm canonical citation and version commit
work page 2024
-
[46]
PowerSGD : Practical low-rank gradient compression for distributed optimization
Thijs Vogels, Sai Praneeth Karimireddy, and Martin Jaggi. PowerSGD : Practical low-rank gradient compression for distributed optimization. In Advances in Neural Information Processing Systems, 2019
work page 2019
-
[47]
ASPO : Asymmetric importance-ratio correction for policy optimization, 2025
Wang et al. ASPO : Asymmetric importance-ratio correction for policy optimization, 2025. TODO: confirm citation
work page 2025
-
[48]
TernGrad : Ternary gradients to reduce communication in distributed deep learning
Wei Wen, Cong Xu, Feng Yan, Chunpeng Wu, Yandan Wang, Yiran Chen, and Hai Li. TernGrad : Ternary gradients to reduce communication in distributed deep learning. In Advances in Neural Information Processing Systems, 2017
work page 2017
-
[49]
DAPO : An open-source LLM reinforcement learning system at scale, 2025
Yu et al. DAPO : An open-source LLM reinforcement learning system at scale, 2025. TODO: confirm full author list and arXiv id
work page 2025
-
[50]
GSPO : Sequence-level group sequence policy optimization, 2025
Zheng et al. GSPO : Sequence-level group sequence policy optimization, 2025. TODO: confirm citation
work page 2025
-
[51]
arXiv preprint arXiv:2511.08567 , year=
Hanqing Zhu, Zhenyu Zhang, Hanxian Huang, DiJia Su, Zechun Liu, Jiawei Zhao, Igor Fedorov, Hamed Pirsiavash, Zhizhou Sha, Jinwon Lee, David Z. Pan, Zhangyang Wang, Yuandong Tian, and Kai Sheng Tai. The path not taken: RLVR provably learns off the principals, 2025. URL https://arxiv.org/abs/2511.08567
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.