Recognition: no theorem link
Rethinking Importance Sampling in LLM Policy Optimization: A Cumulative Token Perspective
Pith reviewed 2026-05-11 01:14 UTC · model grok-4.3
The pith
The cumulative token importance sampling ratio supplies unbiased prefix corrections with strictly lower variance than full-sequence ratios under token-level policy gradients.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under the token-level policy-gradient formulation, the cumulative token IS ratio—the product of per-token importance sampling ratios up to position t—provides an unbiased prefix correction for each token-level gradient term and has strictly lower variance than the full sequence ratio. CTPO implements this ratio together with log-space clip bounds that scale proportionally to sqrt(t), yielding more uniform regularization across token positions and improved performance on mathematical reasoning tasks.
What carries the argument
The cumulative token IS ratio, defined as the running product of per-token importance sampling ratios from sequence start to the current position t, which supplies prefix corrections for token-level gradients.
If this is right
- Off-policy updates become feasible at the token level without the bias of simple token ratios or the variance explosion of full-sequence products.
- Position-adaptive clipping maintains comparable regularization strength at every token index rather than over- or under-clipping later positions.
- The method delivers higher average accuracy on challenging mathematical reasoning benchmarks than GRPO and GSPO across multiple model sizes.
- Training stability improves because the importance weight no longer grows multiplicatively with full sequence length.
Where Pith is reading between the lines
- The same cumulative-ratio construction could be applied to other autoregressive sequence models trained with reinforcement learning beyond language models.
- If the variance reduction holds in practice, it may permit larger batch sizes or learning rates without additional gradient clipping.
- The approach suggests examining whether other sequential RL settings with long trajectories benefit from prefix-product corrections instead of full-trajectory weights.
Load-bearing premise
The token-level policy-gradient formulation accurately captures the LLM post-training objective, and the sqrt(t)-scaled clipping does not introduce new bias or instability.
What would settle it
An experiment that computes gradient variance on held-out trajectories using both cumulative and full-sequence ratios while keeping the policy and data fixed; the cumulative ratio should show measurably lower variance without degrading final task performance.
Figures
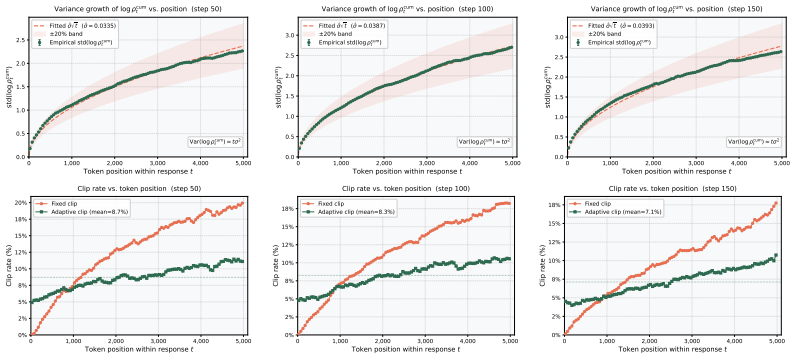
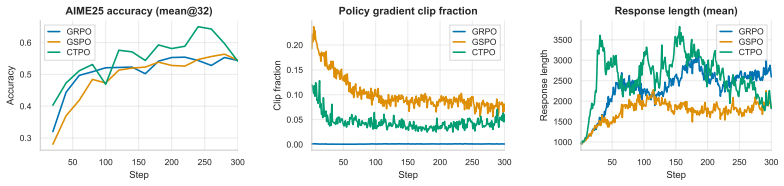
read the original abstract
Reinforcement learning, including reinforcement learning with verifiable rewards (RLVR), has emerged as a powerful approach for LLM post-training. Central to these approaches is the design of the importance sampling (IS) ratio used in off-policy policy-gradient estimation. Existing methods face a fundamental bias-variance dilemma: token-level IS ratios, as adopted by PPO (Schulman et al., 2017) and GRPO (Shao et al., 2024), introduce bias by ignoring prefix state distribution mismatch; full sequence ratios provide exact trajectory-level correction but suffer from high variance due to the multiplicative accumulation of per-token ratios, while GSPO (Zheng et al., 2025) improves numerical stability via length normalization at the cost of deviating from the exact full-sequence IS correction. In this work, we identify the cumulative token IS ratio, the product of per-token ratios up to position $t$, as a theoretically principled solution to this dilemma. We prove that, under the token-level policy-gradient formulation, this ratio provides an unbiased prefix correction for each token-level gradient term and has strictly lower variance than the full sequence ratio. Building on this insight, we propose CTPO (Cumulative Token Policy Optimization), which combines the cumulative token IS ratio with position-adaptive clipping that scales log-space clip bounds according to the natural $\sqrt{t}$ growth of the cumulative log-ratio. This yields more consistent regularization across token positions. We implement and evaluate CTPO in the tool-integrated reasoning setting on several challenging mathematical reasoning benchmarks, achieving the best average performance across both model scales compared with strong GRPO and GSPO baselines. Code will be available at https://github.com/horizon-llm/CTPO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript identifies a bias-variance dilemma in importance sampling ratios for off-policy policy-gradient estimation in LLM post-training. It claims that the cumulative token IS ratio (product of per-token ratios up to position t) provides an unbiased prefix correction for each token-level gradient term and strictly lower variance than the full-sequence ratio, under the token-level policy-gradient formulation. The authors propose CTPO, which combines this ratio with position-adaptive clipping scaled by sqrt(t) growth of the cumulative log-ratio, and report that it achieves the best average performance on tool-integrated mathematical reasoning benchmarks relative to GRPO and GSPO baselines.
Significance. If the theoretical result holds under the stated formulation and the empirical gains are reproducible, the work could offer a principled middle path between biased token-level ratios and high-variance sequence-level ratios, improving stability in LLM reinforcement post-training. The position-adaptive clipping addresses a concrete practical issue in long trajectories. The evaluation on challenging math benchmarks provides initial evidence of utility, though quantitative variance measurements and ablations would strengthen the assessment.
major comments (3)
- [Abstract] Abstract: the central claim asserts a proof that the cumulative token IS ratio is unbiased and has strictly lower variance than the full sequence ratio under the token-level policy-gradient formulation, yet no derivation, explicit gradient expressions, variance formulas, or list of assumptions (e.g., on state distributions or return structure) is supplied. This is load-bearing for the entire contribution.
- [Abstract] Abstract: the unbiasedness and variance results are derived only for the token-level policy-gradient formulation, but standard RLVR/math-reasoning objectives use sequence-level rewards received after the full trajectory. The manuscript does not show whether the per-token prefix correction remains unbiased when the advantage is computed over the entire sequence, which directly affects applicability to the reported experiments.
- [CTPO] CTPO proposal: the position-adaptive clipping with sqrt(t) scaling is presented as yielding consistent regularization, but no analysis or ablation demonstrates that this scaling preserves unbiasedness or does not introduce instability; without such evidence the component remains heuristic and load-bearing for the claimed performance gains.
minor comments (2)
- The abstract states that CTPO achieves the best average performance but supplies neither the specific benchmark names, accuracy numbers, nor variance measurements; adding these quantitative details would allow readers to gauge the magnitude of improvement.
- Notation for the cumulative token IS ratio and the adaptive clip bounds should be defined with an equation early in the text to improve readability before the proof is invoked.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help strengthen the theoretical and empirical aspects of the work. We address each major comment below and will revise the manuscript to incorporate clarifications, derivations, and additional analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim asserts a proof that the cumulative token IS ratio is unbiased and has strictly lower variance than the full sequence ratio under the token-level policy-gradient formulation, yet no derivation, explicit gradient expressions, variance formulas, or list of assumptions (e.g., on state distributions or return structure) is supplied. This is load-bearing for the entire contribution.
Authors: We agree that the proof is central and should be presented more explicitly for clarity. In the revised manuscript, we will move the full derivation of unbiasedness and the variance comparison into the main text (expanding Section 3), including explicit token-level gradient expressions, the variance formulas under the token-level formulation, and a clear list of assumptions regarding state distributions and return structure. This will make the theoretical claims self-contained without relying solely on the appendix. revision: yes
-
Referee: [Abstract] Abstract: the unbiasedness and variance results are derived only for the token-level policy-gradient formulation, but standard RLVR/math-reasoning objectives use sequence-level rewards received after the full trajectory. The manuscript does not show whether the per-token prefix correction remains unbiased when the advantage is computed over the entire sequence, which directly affects applicability to the reported experiments.
Authors: This point correctly identifies a gap in bridging the token-level theory to the sequence-level reward setting used in the experiments. While the cumulative token IS ratio provides prefix correction for the state distribution up to position t, we will add a dedicated subsection discussing its application with sequence-level advantages. We will show that the per-token gradient terms remain unbiased under the prefix correction even when the advantage is the full-trajectory return (as the IS ratio corrects the visitation up to t independently of the return structure). We will also include a note on limitations and empirical variance measurements on the math benchmarks to support applicability. revision: partial
-
Referee: [CTPO] CTPO proposal: the position-adaptive clipping with sqrt(t) scaling is presented as yielding consistent regularization, but no analysis or ablation demonstrates that this scaling preserves unbiasedness or does not introduce instability; without such evidence the component remains heuristic and load-bearing for the claimed performance gains.
Authors: We acknowledge that the sqrt(t) scaling for clipping bounds is a practical design choice motivated by the growth of the cumulative log-ratio and would benefit from further justification. In the revision, we will add an ablation study evaluating alternative scalings (constant, linear in t, and sqrt(t)) on both performance and training stability metrics. We will also include a short analysis showing that the scaling preserves the unbiasedness of the IS ratio (as clipping is applied after ratio computation) while reducing position-dependent variance in the effective regularization strength, supported by the new empirical results. revision: yes
Circularity Check
No circularity: proof is self-contained under explicit token-level assumption
full rationale
The paper's core derivation is a mathematical proof establishing unbiasedness and variance reduction for the cumulative token IS ratio, conditioned explicitly on the token-level policy-gradient formulation. This follows from standard importance-sampling identities applied to per-token terms and does not reduce to any fitted parameter, self-citation chain, or redefinition of the target quantity. Cited prior methods (GRPO, GSPO) supply context for the bias-variance dilemma but are not invoked as load-bearing uniqueness theorems or ansatzes. The position-adaptive clipping is introduced as a practical heuristic derived from the observed sqrt(t) scaling of cumulative log-ratios, without circular dependence on the result itself. The derivation therefore remains independent of its outputs and is self-contained within the stated modeling assumptions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Token-level policy-gradient formulation holds for the LLM optimization setting
Reference graph
Works this paper leans on
-
[1]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Training a helpful and harmless assistant with reinforcement learning from human feedback , author=. arXiv preprint arXiv:2204.05862 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Learning to reason under off-policy guidance , author=. arXiv preprint arXiv:2504.14945 , year=
-
[8]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Dapo: An open-source llm reinforcement learning system at scale , author=. arXiv preprint arXiv:2503.14476 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Human-level control through deep reinforcement learning , author=. nature , volume=. 2015 , publisher=
work page 2015
-
[10]
arXiv preprint arXiv:2505.18573 , year=
Enhancing Efficiency and Exploration in Reinforcement Learning for LLMs , author=. arXiv preprint arXiv:2505.18573 , year=
-
[11]
Optimizing Chain-of-Thought Reasoners via Gradient Variance Minimization in Rejection Sampling and RL , author=. arXiv preprint arXiv:2505.02391 , year=
-
[12]
Depth-Breadth Synergy in RLVR: Unlocking LLM Reasoning Gains with Adaptive Exploration
Depth-Breadth Synergy in RLVR: Unlocking LLM Reasoning Gains with Adaptive Exploration , author=. arXiv preprint arXiv:2508.13755 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Improving Data Efficiency for LLM Reinforcement Fine-tuning Through Difficulty-targeted Online Data Selection and Rollout Replay , author=. arXiv preprint arXiv:2506.05316 , year=
-
[14]
arXiv preprint arXiv:2507.07451 , year=
RLEP: Reinforcement Learning with Experience Replay for LLM Reasoning , author=. arXiv preprint arXiv:2507.07451 , year=
-
[15]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[16]
Advances in Neural Information Processing Systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
KTO: Model Alignment as Prospect Theoretic Optimization
Kto: Model alignment as prospect theoretic optimization , author=. arXiv preprint arXiv:2402.01306 , year=
work page internal anchor Pith review arXiv
-
[18]
Orpo: Monolithic preference optimization without reference model , author=. arXiv preprint arXiv:2403.07691 , year=
-
[19]
Advances in Neural Information Processing Systems , volume=
Simpo: Simple preference optimization with a reference-free reward , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
Rlhf workflow: From reward modeling to online rlhf.arXiv preprint arXiv:2405.07863,
Rlhf workflow: From reward modeling to online rlhf , author=. arXiv preprint arXiv:2405.07863 , year=
-
[21]
arXiv preprint arXiv:2405.21046 , year=
Exploratory preference optimization: Harnessing implicit q*-approximation for sample-efficient rlhf , author=. arXiv preprint arXiv:2405.21046 , year=
-
[22]
International Conference on Artificial Intelligence and Statistics , pages=
A general theoretical paradigm to understand learning from human preferences , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2024 , organization=
work page 2024
-
[23]
Nash learning from human feedback , author=. arXiv preprint arXiv:2312.00886 , volume=
-
[24]
arXiv preprint arXiv:2405.00675 , year=
Self-play preference optimization for language model alignment , author=. arXiv preprint arXiv:2405.00675 , year=
-
[25]
Advances in Neural Information Processing Systems , volume=
Online iterative reinforcement learning from human feedback with general preference model , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
arXiv preprint arXiv:2407.00617 , year=
Iterative nash policy optimization: Aligning llms with general preferences via no-regret learning , author=. arXiv preprint arXiv:2407.00617 , year=
-
[27]
Improving llm general preference alignment via optimistic online mirror descent
Improving LLM general preference alignment via optimistic online mirror descent , author=. arXiv preprint arXiv:2502.16852 , year=
-
[28]
Openai o1 system card , author=. arXiv preprint arXiv:2412.16720 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Group Sequence Policy Optimization
Group sequence policy optimization , author=. arXiv preprint arXiv:2507.18071 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Understanding R1-Zero-Like Training: A Critical Perspective
Understanding r1-zero-like training: A critical perspective , author=. arXiv preprint arXiv:2503.20783 , year=
work page internal anchor Pith review arXiv
-
[31]
Reinforcement learning: An introduction , author=. 1998 , publisher=
work page 1998
-
[32]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Kimi k1. 5: Scaling reinforcement learning with llms , author=. arXiv preprint arXiv:2501.12599 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
First Conference on Language Modeling , year=
Gpqa: A graduate-level google-proof q&a benchmark , author=. First Conference on Language Modeling , year=
-
[34]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Measuring Mathematical Problem Solving With the MATH Dataset
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Proceedings of the Twentieth European Conference on Computer Systems , pages=
Hybridflow: A flexible and efficient rlhf framework , author=. Proceedings of the Twentieth European Conference on Computer Systems , pages=
-
[37]
Advances in neural information processing systems , volume=
Solving quantitative reasoning problems with language models , author=. Advances in neural information processing systems , volume=
-
[38]
Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems , author=. arXiv preprint arXiv:2402.14008 , year=
work page internal anchor Pith review arXiv
-
[39]
Qwen2 technical report , author=. arXiv preprint arXiv:2407.10671 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [40]
-
[41]
Eligibility traces for off-policy policy evaluation , author=
-
[42]
Journal of Machine Learning Research , volume=
Variance reduction techniques for gradient estimates in reinforcement learning , author=. Journal of Machine Learning Research , volume=
-
[43]
International conference on machine learning , pages=
Doubly robust off-policy value evaluation for reinforcement learning , author=. International conference on machine learning , pages=. 2016 , organization=
work page 2016
- [44]
-
[45]
Soft adaptive policy optimization , author=. arXiv preprint arXiv:2511.20347 , year=
-
[46]
Simpletir: End-to-end reinforcement learning for multi-turn tool-integrated reasoning , author=. arXiv preprint arXiv:2509.02479 , year=
-
[47]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
DeepScaleR: Surpassing O1-Preview with a 1.5B Model by Scaling RL , author=
-
[49]
Seallms 3: Open foundation and chat multilingual large language models for southeast asian languages
Improving sampling efficiency in rlvr through adaptive rollout and response reuse , author=. arXiv preprint arXiv:2509.25808 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.