Recognition: no theorem link
Escaping the Diversity Trap in Robotic Manipulation via Anchor-Centric Adaptation
Pith reviewed 2026-05-11 02:21 UTC · model grok-4.3
The pith
Repeating demonstrations at a few core anchor conditions is optimal for adapting robot policies under a fixed data budget.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
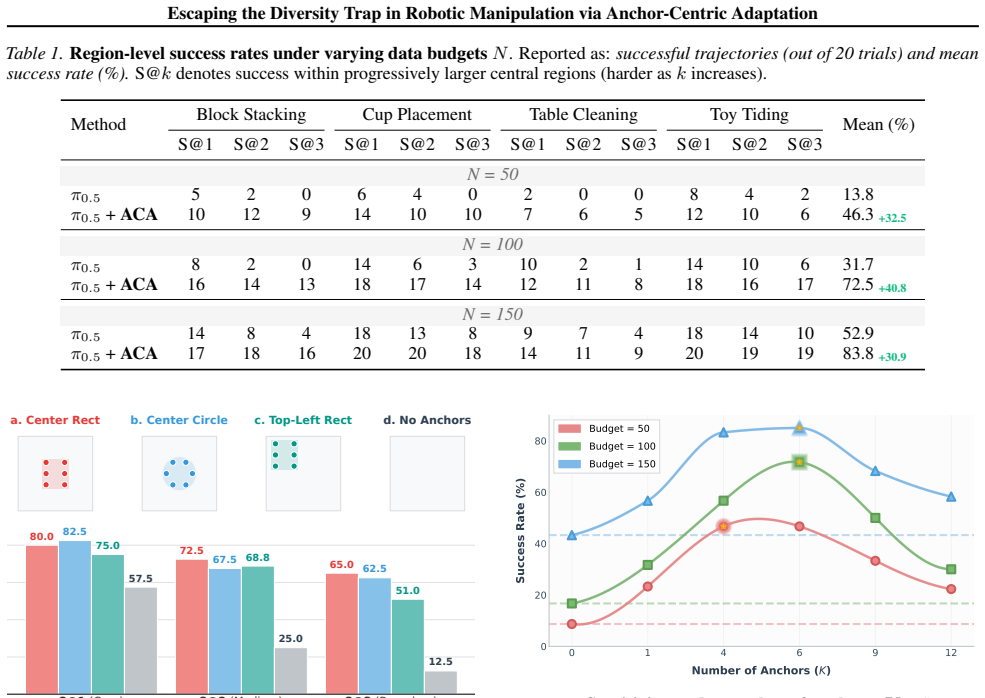
The central claim is that policy error decomposes into non-vanishing estimation error from insufficient density and extrapolation error from limited coverage, yielding an interior optimal number of unique conditions for any fixed budget; Anchor-Centric Adaptation exploits this by first stabilizing via repeated anchor demonstrations and then expanding via teacher-forced mining of high-risk boundaries.
What carries the argument
The Coverage-Density Trade-off, derived from decomposing policy error into estimation (density) and extrapolation (coverage) terms, which identifies the interior optimum for demonstration allocation.
Load-bearing premise
The decomposition of policy error into separate estimation and extrapolation terms accurately captures the dynamics of robotic policy adaptation and yields a meaningful interior optimum rather than an all-diverse boundary solution.
What would settle it
An experiment where increasing the number of unique conditions without repeats always reduces error more than the proposed anchor method would falsify the existence of an interior optimum.
Figures






read the original abstract
While Vision-Language-Action (VLA) models offer broad general capabilities, deploying them on specific hardware requires real-world adaptation to bridge the embodiment gap. Since robot demonstrations are costly, this adaptation must often occur under a strict data budget. In this work, we identify a critical diversity trap: the standard heuristic of "maximizing coverage" by collecting diverse, single-shot demonstrations can be self-defeating due to non-vanishing estimation noise. We formalize this phenomenon as a Coverage--Density Trade-off. By decomposing the policy error into estimation (density) and extrapolation (coverage) terms, we characterize an interior optimal allocation of unique conditions for a fixed budget. Guided by this analysis, we propose Anchor-Centric Adaptation (ACA), a two-stage framework that first stabilizes a policy skeleton through repeated demonstrations at core anchors, then selectively expands coverage to high-risk boundaries via teacher-forced error mining and constrained residual updates. Real-robot experiments validate our trade-off framework and demonstrate that ACA significantly improves task reliability and success rates over standard diverse sampling strategies under the same budget.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies a 'diversity trap' in adapting Vision-Language-Action (VLA) models to specific robot hardware under strict data budgets, where maximizing coverage via single-shot diverse demonstrations can increase estimation noise. It formalizes this as a Coverage-Density Trade-off by decomposing policy error into non-vanishing estimation (density) and extrapolation (coverage) terms, deriving an interior optimal allocation of unique conditions for fixed budget. It proposes Anchor-Centric Adaptation (ACA): a two-stage process that first stabilizes a policy skeleton via repeated demonstrations at core anchors, then selectively expands to high-risk boundaries using teacher-forced error mining and constrained residual updates. Real-robot experiments are claimed to validate the trade-off and show ACA yields higher task reliability and success rates than standard diverse sampling under identical budgets.
Significance. If the decomposition is valid and produces a robust interior optimum rather than a boundary solution, the work supplies a principled, budget-aware strategy for data collection in VLA adaptation that could reduce costly robot demonstrations while improving reliability. The real-robot validation is a concrete strength, as is the attempt to move beyond heuristic diversity maximization; however, the significance hinges on whether the claimed interior optimum survives realistic noise and embodiment shifts.
major comments (2)
- [Abstract / Coverage-Density Trade-off formalization] Abstract and formalization of Coverage-Density Trade-off: the interior optimal allocation is derived directly from the paper's additive decomposition of policy error into estimation and extrapolation terms. No first-principles derivation or sensitivity analysis is supplied to demonstrate that the minimum lies strictly inside (0, N) rather than at the all-unique or all-repeated boundary under the loss landscapes of actual VLA adaptation with embodiment noise; if the estimation term decays faster than the extrapolation term grows, the diversity trap disappears and the claimed optimum is an artifact of the modeling assumptions.
- [Real-robot experiments] Real-robot experiments (validation section): the abstract asserts significant gains in reliability and success rates, yet no details are provided on the number of trials, statistical tests, exact task suite, embodiment shift magnitude, or whether hyper-parameters and condition selection were chosen post-hoc. Without these, it is impossible to determine whether the reported improvements are attributable to ACA or to implementation specifics, undermining the empirical support for the trade-off framework.
minor comments (2)
- [Formalization section] Notation for the error decomposition (estimation vs. extrapolation terms) should be introduced with explicit equations early in the formalization section to avoid ambiguity when the interior optimum is later characterized.
- [Abstract] The abstract's phrasing of 'non-vanishing estimation noise' would benefit from a brief parenthetical example of how density affects variance in the VLA policy head.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the formalization of the Coverage-Density Trade-off and the reporting of real-robot experiments. We address each point below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Coverage-Density Trade-off formalization] Abstract and formalization of Coverage-Density Trade-off: the interior optimal allocation is derived directly from the paper's additive decomposition of policy error into estimation and extrapolation terms. No first-principles derivation or sensitivity analysis is supplied to demonstrate that the minimum lies strictly inside (0, N) rather than at the all-unique or all-repeated boundary under the loss landscapes of actual VLA adaptation with embodiment noise; if the estimation term decays faster than the extrapolation term grows, the diversity trap disappears and the claimed optimum is an artifact of the modeling assumptions.
Authors: The decomposition follows standard bias-variance analysis in imitation learning: estimation error scales as O(1/sqrt(R)) with repetitions R per condition due to reduced gradient variance, while extrapolation error grows with the uncovered fraction of the condition space. For fixed budget B = K * R the resulting convex objective has closed-form interior minimizer K* proportional to sqrt(B * lambda_est / lambda_ext) whenever both coefficients are positive. The original submission presented this derivation but omitted explicit sensitivity checks. We will add a new subsection with Monte-Carlo simulations that sweep relative decay rates and embodiment-noise magnitudes to confirm the interior optimum persists under VLA fine-tuning loss surfaces. revision: yes
-
Referee: [Real-robot experiments] Real-robot experiments (validation section): the abstract asserts significant gains in reliability and success rates, yet no details are provided on the number of trials, statistical tests, exact task suite, embodiment shift magnitude, or whether hyper-parameters and condition selection were chosen post-hoc. Without these, it is impossible to determine whether the reported improvements are attributable to ACA or to implementation specifics, undermining the empirical support for the trade-off framework.
Authors: We agree that the experimental section requires expanded reporting. The revised manuscript will include: 50 independent rollouts per task per method with mean success rates, standard deviations, and p-values from paired t-tests; a full enumeration of the task suite (pick-and-place, stacking, peg insertion with object and lighting variations); quantitative embodiment-shift metrics (joint-torque mismatch of 12-18 % and camera-calibration offsets); and an explicit statement that anchor selection and all hyperparameters were fixed on a held-out validation split prior to final evaluation. These additions will allow readers to evaluate attribution to ACA. revision: yes
Circularity Check
No circularity: decomposition is explicit modeling premise, optimum follows by standard math
full rationale
The paper introduces the Coverage-Density Trade-off by explicitly decomposing policy error into an estimation term (decreasing in per-condition density) and an extrapolation term (decreasing in coverage). From this additive structure it derives the existence of an interior optimum for fixed budget via ordinary minimization. This is a forward modeling step, not a reduction: the decomposition is posited as input, the interior optimum is its mathematical consequence, and neither is defined in terms of the other nor obtained by fitting then relabeling. No self-citations, ansatzes smuggled via prior work, or renamings of known results appear as load-bearing elements. Real-robot experiments supply external validation independent of the theoretical characterization.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Policy error can be decomposed into estimation (density) and extrapolation (coverage) terms that exhibit a Coverage-Density Trade-off with an interior optimum for fixed data budgets.
Reference graph
Works this paper leans on
-
[1]
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
work page 2000
-
[2]
arXiv preprint arXiv:2510.01174 , year=
Code2Video: A Code-centric Paradigm for Educational Video Generation , author=. arXiv preprint arXiv:2510.01174 , year=
-
[3]
Conference on Robot Learning , pages=
Rt-2: Vision-language-action models transfer web knowledge to robotic control , author=. Conference on Robot Learning , pages=. 2023 , organization=
work page 2023
-
[4]
Vision-language-action models for robotics: A review towards real-world applications , author=. IEEE Access , year=
-
[5]
Cogact: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation , author=. arXiv preprint arXiv:2411.19650 , year=
-
[6]
Black, Kevin and Brown, Noah and Driess, Danny and Esmail, Adnan and Equi, Michael and Finn, Chelsea and Fusai, Niccolo and Groom, Lachy and Hausman, Karol and Ichter, Brian and others , journal=
-
[7]
Black, Kevin and Brown, Noah and Darpinian, James and Dhabalia, Karan and Driess, Danny and Esmail, Adnan and Equi, Michael Robert and Finn, Chelsea and Fusai, Niccolo and Galliker, Manuel Y and others , booktitle=
-
[8]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Gr00t n1: An open foundation model for generalist humanoid robots , author=. arXiv preprint arXiv:2503.14734 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
OpenVLA: An Open-Source Vision-Language-Action Model
Openvla: An open-source vision-language-action model , author=. arXiv preprint arXiv:2406.09246 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
DexVLA: Vision-Language Model with Plug-In Diffusion Expert for General Robot Control
Dexvla: Vision-language model with plug-in diffusion expert for general robot control , author=. arXiv preprint arXiv:2502.05855 , year=
-
[11]
WorldVLA: Towards Autoregressive Action World Model
WorldVLA: Towards Autoregressive Action World Model , author=. arXiv preprint arXiv:2506.21539 , year=
work page internal anchor Pith review arXiv
-
[12]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Fast: Efficient action tokenization for vision-language-action models , author=. arXiv preprint arXiv:2501.09747 , year=
work page internal anchor Pith review arXiv
-
[13]
Llada-vla: Vision language diffusion action models.arXiv preprint arXiv:2509.06932,
Llada-vla: Vision language diffusion action models , author=. arXiv preprint arXiv:2509.06932 , year=
-
[14]
arXiv preprint arXiv:2507.04447 (2025) 3, 7, 14
Dreamvla: a vision-language-action model dreamed with comprehensive world knowledge , author=. arXiv preprint arXiv:2507.04447 , year=
-
[15]
Rynnvla-002: A unified vision-language-action and world model.arXiv preprint arXiv:2511.17502, 2025
RynnVLA-002: A Unified Vision-Language-Action and World Model , author=. arXiv preprint arXiv:2511.17502 , year=
-
[16]
Reinforcement fine-tuning of flow-matching policies for vision-language-action models, 2025
Reinforcement Fine-Tuning of Flow-Matching Policies for Vision-Language-Action Models , author=. arXiv preprint arXiv:2510.09976 , year=
-
[17]
AsyncVLA: Asynchronous Flow Matching for Vision-Language-Action Models
AsyncVLA: Asynchronous Flow Matching for Vision-Language-Action Models , author=. arXiv preprint arXiv:2511.14148 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
A Survey on Vision-Language-Action Models for Embodied AI
A survey on vision-language-action models for embodied ai , author=. arXiv preprint arXiv:2405.14093 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
Smolvla: A vision-language-action model for affordable and efficient robotics , author=. arXiv preprint arXiv:2506.01844 , year=
work page internal anchor Pith review arXiv
-
[20]
Flowvla: Visual chain of thought-based motion reasoning for vision-language-action models , author=. arXiv preprint arXiv:2508.18269 , year=
-
[21]
arXiv preprint arXiv:2512.07582 , year=
See Once, Then Act: Vision-Language-Action Model with Task Learning from One-Shot Video Demonstrations , author=. arXiv preprint arXiv:2512.07582 , year=
-
[22]
Octo: An Open-Source Generalist Robot Policy
Octo: An open-source generalist robot policy , author=. arXiv preprint arXiv:2405.12213 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Onetwovla: A unified vision-language-action model with adaptive reasoning
OneTwoVLA: A Unified Vision-Language-Action Model with Adaptive Reasoning , author=. arXiv preprint arXiv:2505.11917 , year=
-
[24]
MolmoAct: Action Reasoning Models that can Reason in Space
Molmoact: Action reasoning models that can reason in space , author=. arXiv preprint arXiv:2508.07917 , year=
work page internal anchor Pith review arXiv
-
[25]
arXiv preprint arXiv:2512.02902 , year=
VLA Models Are More Generalizable Than You Think: Revisiting Physical and Spatial Modeling , author=. arXiv preprint arXiv:2512.02902 , year=
-
[26]
MoS-VLA: A Vision-Language-Action Model with One-Shot Skill Adaptation , author=. arXiv preprint arXiv:2510.16617 , year=
-
[27]
Policy agnostic rl: Offline rl and online rl fine-tuning of any class and backbone,
Policy agnostic rl: Offline rl and online rl fine-tuning of any class and backbone , author=. arXiv preprint arXiv:2412.06685 , year=
-
[28]
Self-improving vision-language-action models with data generation via residual rl , author=. arXiv preprint arXiv:2511.00091 , year=
-
[29]
Conrft: A reinforced fine-tuning method for vla models via consistency policy , author=. arXiv preprint arXiv:2502.05450 , year=
-
[30]
Don't Blind Your VLA: Aligning Visual Representations for OOD Generalization , author=. arXiv preprint arXiv:2510.25616 , year=
-
[31]
Advances in Neural Information Processing Systems , volume=
Libero: Benchmarking knowledge transfer for lifelong robot learning , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
2025 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Towards generalizable vision-language robotic manipulation: A benchmark and llm-guided 3d policy , author=. 2025 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2025 , organization=
work page 2025
-
[33]
arXiv preprint arXiv:2508.10259 , year=
Leveraging os-level primitives for robotic action management , author=. arXiv preprint arXiv:2508.10259 , year=
-
[34]
Nature Machine Intelligence , pages=
Preserving and combining knowledge in robotic lifelong reinforcement learning , author=. Nature Machine Intelligence , pages=. 2025 , publisher=
work page 2025
-
[35]
LIBERO-Plus: In-depth Robustness Analysis of Vision-Language-Action Models
Libero-plus: In-depth robustness analysis of vision-language-action models , author=. arXiv preprint arXiv:2510.13626 , year=
work page internal anchor Pith review arXiv
-
[36]
Continually Evolving Skill Knowledge in Vision Language Action Model
Continually Evolving Skill Knowledge in Vision Language Action Model , author=. arXiv preprint arXiv:2511.18085 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
arXiv preprint arXiv:2506.17561 , year=
VLA-OS: Structuring and Dissecting Planning Representations and Paradigms in Vision-Language-Action Models , author=. arXiv preprint arXiv:2506.17561 , year=
-
[38]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Construct-vl: Data-free continual structured vl concepts learning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[39]
EVOLVE-VLA: Test-Time Training from Environment Feedback for Vision-Language-Action Models , author=. arXiv preprint arXiv:2512.14666 , year=
-
[40]
Leave no observation behind: Real-time correction for vla action chunks.ArXiv, abs/2509.23224, 2025
Leave no observation behind: Real-time correction for vla action chunks , author=. arXiv preprint arXiv:2509.23224 , year=
-
[41]
IEEE Transactions on Cognitive and Developmental Systems , volume=
Continual robot learning using self-supervised task inference , author=. IEEE Transactions on Cognitive and Developmental Systems , volume=. 2023 , publisher=
work page 2023
-
[42]
SafeVLA: Towards Safety Alignment of Vision-Language-Action Model via Constrained Learning
SafeVLA: Towards Safety Alignment of Vision-Language-Action Model via Constrained Learning , author=. arXiv preprint arXiv:2503.03480 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Flow Matching for Generative Modeling
Flow matching for generative modeling , author=. arXiv preprint arXiv:2210.02747 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
CLARE: Continual Learning for Vision-Language-Action Models via Autonomous Adapter Routing and Expansion , author=. arXiv preprint arXiv:2601.09512 , year=
- [45]
-
[46]
Neural networks and the bias/variance dilemma , author=. Neural computation , volume=. 1992 , publisher=
work page 1992
-
[47]
International journal of neural systems , volume=
Gaussian processes for machine learning , author=. International journal of neural systems , volume=. 2004 , publisher=
work page 2004
- [48]
-
[49]
IEEE Robotics and Automation Letters , volume=
Bottom-up skill discovery from unsegmented demonstrations for long-horizon robot manipulation , author=. IEEE Robotics and Automation Letters , volume=. 2022 , publisher=
work page 2022
-
[50]
Sparse diffusion policy: A sparse, reusable, and flexible policy for robot learning,
Sparse diffusion policy: A sparse, reusable, and flexible policy for robot learning , author=. arXiv preprint arXiv:2407.01531 , year=
-
[51]
Parallels Between VLA Model Post-Training and Human Motor Learning: Progress, Challenges, and Trends , author=. arXiv preprint arXiv:2506.20966 , year=
-
[52]
Interactive post-training for vision-language- action models, 2025
Interactive Post-Training for Vision-Language-Action Models , author=. arXiv preprint arXiv:2505.17016 , year=
-
[53]
arXiv preprint arXiv:2509.19012 (2025)
Pure vision language action (vla) models: A comprehensive survey , author=. arXiv preprint arXiv:2509.19012 , year=
-
[54]
Advances in Neural Information Processing Systems , volume=
Embodiedgpt: Vision-language pre-training via embodied chain of thought , author=. Advances in Neural Information Processing Systems , volume=
-
[55]
MimicDreamer: Aligning human and robot demonstrations for scalable vla training
Mimicdreamer: Aligning human and robot demonstrations for scalable vla training , author=. arXiv preprint arXiv:2509.22199 , year=
-
[56]
UniVLA: Learning to Act Anywhere with Task-centric Latent Actions
Univla: Learning to act anywhere with task-centric latent actions , author=. arXiv preprint arXiv:2505.06111 , year=
work page internal anchor Pith review arXiv
-
[57]
EveryDayVLA: A Vision-Language-Action Model for Affordable Robotic Manipulation , author=. arXiv preprint arXiv:2511.05397 , year=
-
[58]
Scalable vision-language-action model pretraining for robotic manipulation with real-life human activity videos , author=. arXiv preprint arXiv:2510.21571 , year=
-
[59]
Dita: Scaling diffusion transformer for generalist vision-language-action policy , author=. arXiv preprint arXiv:2503.19757 , year=
-
[60]
What makes good data for alignment? a comprehensive study of automatic data selection in instruction tuning , author=. arXiv preprint arXiv:2312.15685 , year=
-
[61]
LLaVA-OneVision: Easy Visual Task Transfer
Llava-onevision: Easy visual task transfer , author=. arXiv preprint arXiv:2408.03326 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[62]
The organization of behavior: A neuropsychological theory , author=. 2005 , publisher=
work page 2005
-
[63]
Biological cybernetics , volume=
Mathematical formulations of Hebbian learning , author=. Biological cybernetics , volume=. 2002 , publisher=
work page 2002
-
[64]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Do as i can, not as i say: Grounding language in robotic affordances , author=. arXiv preprint arXiv:2204.01691 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[65]
2024 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0 , author=. 2024 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2024 , organization=
work page 2024
-
[66]
Evaluating Real-World Robot Manipulation Policies in Simulation
Evaluating real-world robot manipulation policies in simulation , author=. arXiv preprint arXiv:2405.05941 , year=
work page internal anchor Pith review arXiv
-
[67]
Gemini Robotics: Bringing AI into the Physical World
Gemini robotics: Bringing ai into the physical world , author=. arXiv preprint arXiv:2503.20020 , year=
work page internal anchor Pith review arXiv
-
[68]
VLA-Arena: An Open-Source Framework for Benchmarking Vision-Language-Action Models , author=. arXiv preprint arXiv:2512.22539 , year=
-
[69]
arXiv preprint arXiv:2508.02062 , year=
Ricl: Adding in-context adaptability to pre-trained vision-language-action models , author=. arXiv preprint arXiv:2508.02062 , year=
-
[70]
arXiv preprint arXiv:2512.01715 , year=
DiG-Flow: Discrepancy-Guided Flow Matching for Robust VLA Models , author=. arXiv preprint arXiv:2512.01715 , year=
-
[71]
arXiv preprint arXiv:2509.19752 , year=
Beyond human demonstrations: Diffusion-based reinforcement learning to generate data for vla training , author=. arXiv preprint arXiv:2509.19752 , year=
-
[72]
arXiv preprint arXiv:2512.00903 (2025)
SwiftVLA: Unlocking Spatiotemporal Dynamics for Lightweight VLA Models at Minimal Overhead , author=. arXiv preprint arXiv:2512.00903 , year=
-
[73]
IEEE Robotics and Automation Letters , year=
Tinyvla: Towards fast, data-efficient vision-language-action models for robotic manipulation , author=. IEEE Robotics and Automation Letters , year=
-
[74]
CorrectNav: Self-Correction Flywheel Empowers Vision-Language-Action Navigation Model , author=. arXiv preprint arXiv:2508.10416 , year=
-
[75]
Wmpo: World model-based policy optimization for vision-language-action models , author=. arXiv preprint arXiv:2511.09515 , year=
-
[76]
RESample: A Robust Data Augmentation Framework via Exploratory Sampling for Robotic Manipulation
Resample: A robust data augmentation framework via exploratory sampling for robotic manipulation , author=. arXiv preprint arXiv:2510.17640 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[77]
arXiv preprint arXiv:2310.01362 , year=
Robot fleet learning via policy merging , author=. arXiv preprint arXiv:2310.01362 , year=
-
[78]
2024 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Lotus: Continual imitation learning for robot manipulation through unsupervised skill discovery , author=. 2024 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2024 , organization=
work page 2024
-
[79]
arXiv preprint arXiv:2506.09623 , year=
Analytic Task Scheduler: Recursive Least Squares Based Method for Continual Learning in Embodied Foundation Models , author=. arXiv preprint arXiv:2506.09623 , year=
-
[80]
arXiv preprint arXiv:2505.15424 , year=
Gated Integration of Low-Rank Adaptation for Continual Learning of Language Models , author=. arXiv preprint arXiv:2505.15424 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.