Recognition: 2 theorem links
· Lean TheoremConvex Optimization with Nested Evolving Feasible Sets
Pith reviewed 2026-05-11 02:06 UTC · model grok-4.3
The pith
An algorithm called Frugal achieves zero regret and O(log T) movement cost for strongly convex losses over nested shrinking feasible sets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the CONES framework, where the objective remains fixed but feasible sets evolve as a nested sequence S1 ⊇ S2 ⊇ ⋯ ⊇ ST, the Frugal algorithm ensures zero regret against the hindsight optimum while bounding total movement by O(log T) when the loss is strongly convex or α-sharp, and this bound is tight because any online algorithm with o(T) regret requires Ω(log T) movement.
What carries the argument
The Frugal algorithm, which performs selective updates only when needed to maintain zero regret against the hindsight benchmark while exploiting the nested structure to limit total displacement.
If this is right
- For general convex losses, any polynomial trade-off between regret and movement cost is achievable via the lazy algorithm.
- Zero regret is attainable with only O(log T) movement under strong convexity or α-sharpness.
- The Ω(log T) movement lower bound applies to any algorithm with o(T) regret in both the strongly convex and α-sharp cases.
- The framework extends nested convex body chasing to include a fixed optimization objective.
Where Pith is reading between the lines
- Applications with tightening constraints over time, such as resource allocation, may require only logarithmic adjustments when losses are strongly convex.
- Similar lazy-update ideas could apply to online convex optimization with time-varying but nested constraints.
- Empirical tests on specific nested geometries like shrinking balls or polytopes would confirm the logarithmic movement bound in practice.
Load-bearing premise
The feasible sets form a nested sequence of convex bodies and the algorithm receives sufficient information such as gradients to perform the required updates at each step.
What would settle it
A concrete sequence of nested convex sets and strongly convex loss where Frugal incurs positive regret or super-logarithmic movement, or an algorithm that achieves o(T) regret with movement o(log T).
Figures



read the original abstract
Convex Optimization with Nested Evolving Feasible Sets (CONES)} is considered where the objective function $f$ remains fixed but the feasible region evolves over time as a nested sequence $S_1 \supseteq S_2 \supseteq \cdots \supseteq S_T$. The goal of an online algorithm is to simultaneously minimize the regret with respect to hindsight static optimal benchmark and the total movement cost while ensuring feasibility at all times. CONES is an optimization-oriented generalization of the well-known nested convex body chasing problem. When the loss function is convex, we propose a lazy-algorithm and show that it achieves $O(T^{1-\beta}), O(T^\beta)$ simultaneous regret and movement cost for any $\beta \in (0,1]$, over a time horizon of $T$. When the loss function is strongly convex or $\alpha$-sharp, we propose an algorithm Frugal that simultaneously achieves zero regret and a movement cost of $O(\log T)$. To complement this, we show that any online algorithm with $o(T)$ regret has a movement cost of $\Omega(\log{T})$ for both cases, proving optimality of Frugal.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the CONES problem: online convex optimization where the loss function f is fixed but the feasible sets form a nested sequence S1 ⊇ S2 ⊇ ⋯ ⊇ ST of convex bodies. The objective is to minimize both regret against the hindsight optimum in the intersection and total movement cost while remaining feasible at every step. For general convex losses the authors give a lazy algorithm attaining the regret-movement trade-off O(T^{1-β}) and O(T^β) for any β ∈ (0,1]. For strongly convex or α-sharp losses they give the Frugal algorithm that simultaneously achieves bounded (zero) regret and O(log T) movement; they also prove that any algorithm with o(T) regret must incur Ω(log T) movement, establishing optimality.
Significance. If the derivations are correct, the work supplies the first optimal algorithms for this natural generalization of nested convex body chasing to the fixed-objective setting. The zero-regret / O(log T) movement result under strong convexity or sharpness, together with the matching lower bound, is a clean and useful contribution. The algorithms rely only on standard convexity, oracle access, and the nested structure, so the results are immediately applicable to dynamic resource allocation and online learning with monotonically tightening constraints.
minor comments (4)
- [Abstract] Abstract: the phrase 'zero regret' is used without qualification. It would be clearer to state explicitly that the regret is bounded by a constant independent of T (as opposed to the conventional sublinear regret).
- [Abstract] Abstract and §1: the lower bound is stated for any algorithm with o(T) regret. Clarify whether the Ω(log T) movement lower bound holds for every sublinear regret or only for regret o(T) with a specific rate; a short remark on the precise statement would avoid ambiguity.
- [Introduction] The manuscript would benefit from an explicit comparison paragraph (perhaps in §1 or §2) that contrasts CONES with both standard online convex optimization (no evolving sets) and the pure nested convex body chasing problem, highlighting where the fixed objective changes the analysis.
- Notation: the movement cost is referred to as 'total movement cost' in the abstract and 'movement cost' later; adopt a single consistent term and define it formally once (e.g., sum of distances between consecutive decisions).
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The referee's description accurately reflects the CONES problem, our lazy algorithm for the convex case, and the Frugal algorithm with matching lower bound for strongly convex and sharp losses. We appreciate the recognition of the results' applicability to dynamic resource allocation and online learning with tightening constraints.
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper defines the CONES problem with nested convex sets and fixed convex loss, then constructs explicit algorithms (lazy for general convex, Frugal for strongly convex/α-sharp) whose regret and movement bounds are derived directly from convexity, strong convexity, and the nested structure via standard potential-function or oracle-based analysis. The matching lower bound follows from an information-theoretic adversarial construction on set shrinkage that forces movements for any low-regret algorithm. No equation reduces to a fitted parameter renamed as a prediction, no self-citation is load-bearing for the central claims, and no ansatz or uniqueness result is smuggled in; all steps rest on the stated assumptions and standard convex optimization tools without self-referential closure.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoesIf F_{t-1} + f(ˆx_t) ≤ t·v_t then x_t ← ˆx_t (lazy) else x_t ← x^*_{near,t} (jump); phases defined by jump times with recurrence t_{k+1} > t_k (1 + μ δ_k / (2G + L δ_k))
-
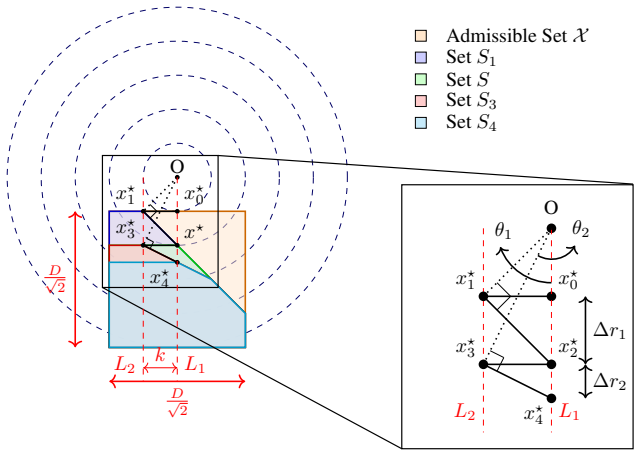
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearM_FRUGAL(T) = O(log T) with zero regret under strong convexity or α-sharpness; matching Ω(log T) lower bound
Reference graph
Works this paper leans on
-
[1]
Optimal algorithms for online convex optimization with multi-point bandit feedback
Alekh Agarwal, Ofer Dekel, and Lin Xiao. Optimal algorithms for online convex optimization with multi-point bandit feedback. InConference on Learning Theory (COLT), pages 28–40, 2010
work page 2010
-
[2]
C. J. Argue, S ´ebastien Bubeck, Michael B. Cohen, Anupam Gupta, and Yin Tat Lee. A nearly-linear bound for chasing nested convex bodies, 2018
work page 2018
-
[3]
C. J. Argue, Anupam Gupta, Ziye Tang, and Guru Guruganesh. Chasing convex bodies with linear competitive ratio.J. ACM, 68(5), August 2021
work page 2021
-
[4]
Dimension-free bounds for chasing convex functions
CJ Argue, Anupam Gupta, and Guru Guruganesh. Dimension-free bounds for chasing convex functions. InConference on Learning Theory, pages 219–241. PMLR, 2020
work page 2020
-
[5]
Argue, Anupam Gupta, and Guru Guruganesh
C.J. Argue, Anupam Gupta, and Guru Guruganesh. Dimension-free bounds for chasing convex functions. In Jacob Aber- nethy and Shivani Agarwal, editors,Proceedings of Thirty Third Conference on Learning Theory, volume 125 ofProceed- ings of Machine Learning Research, pages 219–241. PMLR, 09–12 Jul 2020
work page 2020
-
[6]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional AI: Harmlessness from AI feedback.arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
Nested convex bodies are chaseable, 2017
Nikhil Bansal, Martin B ¨ohm, Marek Eli ´aˇs, Grigorios Koumoutsos, and Seeun William Umboh. Nested convex bodies are chaseable, 2017
work page 2017
-
[8]
A 2-competitive algorithm for online convex optimization with switching costs
Nikhil Bansal, Anupam Gupta, Ravishankar Krishnaswamy, Kirk Pruhs, Kevin Schewior, and Cliff Stein. A 2-competitive algorithm for online convex optimization with switching costs. InApproximation, Randomization, and Combinatorial Optimization. Algorithms and Techniques (APPROX/RANDOM 2015), pages 96–109. Schloss Dagstuhl–Leibniz-Zentrum f¨ur Informatik, 2015
work page 2015
- [9]
-
[10]
Princeton University Press, 2009
Aharon Ben-Tal, Laurent El Ghaoui, and Arkadi Nemirovski.Robust Optimization. Princeton University Press, 2009
work page 2009
-
[11]
Fr ´ed´eric Bonnans and Alexander Shapiro.Perturbation Analysis of Optimization Problems
J. Fr ´ed´eric Bonnans and Alexander Shapiro.Perturbation Analysis of Optimization Problems. Springer Series in Operations Research. Springer Science & Business Media, New York, 2000
work page 2000
-
[12]
Convex optimization: Algorithms and complexity, 2015
S ´ebastien Bubeck. Convex optimization: Algorithms and complexity, 2015
work page 2015
-
[13]
Chasing nested convex bodies nearly optimally, 2021
S ´ebastien Bubeck, Bo’az Klartag, Yin Tat Lee, Yuanzhi Li, and Mark Sellke. Chasing nested convex bodies nearly optimally, 2021
work page 2021
-
[14]
Smoothed online convex optimization in high dimensions via online balanced descent
Niangjun Chen, Gautam Goel, and Adam Wierman. Smoothed online convex optimization in high dimensions via online balanced descent. InConference On Learning Theory, pages 1574–1594. PMLR, 2018
work page 2018
-
[15]
Mung Chiang, Steven H Low, Robert Calderbank, and John C Doyle. Layering as optimization decomposition: A mathe- matical theory of network architectures.Proceedings of the IEEE, 95(1):255–312, 2007
work page 2007
-
[16]
Support-vector networks.Machine Learning, 20(3):273–297, 1995
Corinna Cortes and Vladimir Vapnik. Support-vector networks.Machine Learning, 20(3):273–297, 1995
work page 1995
-
[17]
Safe RLHF: Safe Reinforcement Learning from Human Feedback
Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Nanhai Xu, Mickel Liu, Yizhou Wang, and Yaodong Yang. Safe RLHF: Safe reinforcement learning from human feedback.arXiv preprint arXiv:2310.12773, 2023
work page internal anchor Pith review arXiv 2023
-
[18]
Academic Press, New York, NY , 1983
Anthony V Fiacco.Introduction to Sensitivity and Stability Analysis in Nonlinear Programming, volume 165 ofMathemat- ics in Science and Engineering. Academic Press, New York, NY , 1983
work page 1983
-
[19]
Online convex optimization in the bandit setting: gradient descent without a gradient
Abraham D Flaxman, Adam Tauman Kalai, and H Brendan McMahan. Online convex optimization in the bandit setting: gradient descent without a gradient. InProceedings of the Sixteenth Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), pages 385–394, 2005. 9
work page 2005
-
[20]
An algorithm for quadratic programming.Naval Research Logistics Quarterly, 3(1- 2):95–110, 1956
Marguerite Frank and Philip Wolfe. An algorithm for quadratic programming.Naval Research Logistics Quarterly, 3(1- 2):95–110, 1956
work page 1956
-
[21]
On convex body chasing.Discrete & Computational Geometry, 9(3):293–321, 1993
Joel Friedman and Nathan Linial. On convex body chasing.Discrete & Computational Geometry, 9(3):293–321, 1993
work page 1993
-
[22]
Gautam Goel, Yiheng Lin, Haoyuan Sun, and Adam Wierman. Beyond online balanced descent: An optimal algorithm for smoothed online optimization.Advances in Neural Information Processing Systems, 32, 2019
work page 2019
-
[23]
Hengquan Guo, Xin Liu, Honghao Wei, and Lei Ying. Online convex optimization with hard constraints: Towards the best of two worlds and beyond.Advances in Neural Information Processing Systems, 35:36426–36439, 2022
work page 2022
-
[24]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models.International Conference on Learning Representations (ICLR), 2022
work page 2022
-
[25]
Martin Jaggi. Revisiting frank-wolfe: Projection-free sparse convex optimization.International Conference on Machine Learning (ICML), pages 427–435, 2013
work page 2013
-
[26]
Frank P Kelly, Aman K Maulloo, and David K H Tan. Rate control for communication networks: shadow prices, propor- tional fairness and stability.Journal of the Operational Research Society, 49(3):237–252, 1998
work page 1998
-
[27]
Overcoming catastrophic forgetting in neural networks
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sciences, 114(13):3521–3526, 2017
work page 2017
-
[28]
Cautious regret minimization: Online optimization with long-term budget constraints
Nikolaos Liakopoulos, Apostolos Destounis, Georgios Paschos, Thrasyvoulos Spyropoulos, and Panayotis Mertikopoulos. Cautious regret minimization: Online optimization with long-term budget constraints. InInternational Conference on Machine Learning, pages 3944–3952. PMLR, 2019
work page 2019
-
[29]
Paolo Manselli and Carlo Pucci. Maximum length of steepest descent curves for quasi-convex functions.Geometriae Dedicata, 38(2):211–227, 1991
work page 1991
-
[30]
Constrained model predictive control: Stability and optimality.Automatica, 36(6):789–814, 2000
David Q Mayne, James B Rawlings, Christopher V Rao, and Pierre OM Scokaert. Constrained model predictive control: Stability and optimality.Automatica, 36(6):789–814, 2000
work page 2000
-
[31]
arXiv preprint arXiv:1702.04783 , year=
Michael J Neely and Hao Yu. Online convex optimization with time-varying constraints.arXiv preprint arXiv:1702.04783, 2017
-
[32]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agar- wal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. InAdvances in Neural Information Processing Systems, volume 35, pages 27730–27744, 2022
work page 2022
-
[33]
Bernhard Sch ¨olkopf and Alexander J. Smola.Learning with Kernels. MIT Press, 2002
work page 2002
-
[34]
Trust region policy optimization
John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimization. In ICML, 2015
work page 2015
-
[35]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[36]
Springer International Publishing, Cham, 2023
Mark Sellke.Chasing Convex Bodies Optimally, pages 313–335. Springer International Publishing, Cham, 2023
work page 2023
-
[37]
Andrea Simonetto, Emiliano Dall’Anese, Santiago Paternain, Geert Leus, and Georgios B Giannakis. Time-varying convex optimization: Time-structured algorithms and applications.Proceedings of the IEEE, 108(11):2032–2048, 2020
work page 2032
-
[38]
Optimal algorithms for online convex optimization with adversarial constraints
Abhishek Sinha and Rahul Vaze. Optimal algorithms for online convex optimization with adversarial constraints. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
work page 2024
-
[39]
Abhishek Sinha and Rahul Vaze. Beyond $\tilde{O}(\sqrt{T})$ constraint violation for online convex optimization with adversarial constraints. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, NeurIPS 2025, 2025
work page 2025
-
[40]
Safety-aware algorithms for adversarial contextual bandit
Wen Sun, Debadeepta Dey, and Ashish Kapoor. Safety-aware algorithms for adversarial contextual bandit. InInternational Conference on Machine Learning, pages 3280–3288. PMLR, 2017. 10
work page 2017
-
[41]
Rahul Vaze and Abhishek Sinha. $o(\sqrt{T})$ static regret and instance dependent constraint violation for constrained online convex optimization. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, NeurIPS 2025, 2025
work page 2025
-
[42]
arXiv preprint arXiv:2306.00149 , year=
Xinlei Yi, Xiuxian Li, Tao Yang, Lihua Xie, Yiguang Hong, Tianyou Chai, and Karl H Johansson. Distributed online convex optimization with adversarial constraints: Reduced cumulative constraint violation bounds under slater’s condition.arXiv preprint arXiv:2306.00149, 2023
-
[43]
Hao Yu, Michael Neely, and Xiaohan Wei. Online convex optimization with stochastic constraints.Advances in Neural Information Processing Systems, 30, 2017
work page 2017
-
[44]
Lijun Zhang, Wei Jiang, Shiyin Lu, and Tianbao Yang. Revisiting smoothed online learning.Advances in Neural Informa- tion Processing Systems, 34:13599–13612, 2021
work page 2021
-
[45]
Fine-Tuning Language Models from Human Preferences
Daniel M Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. Fine-tuning language models from human preferences.arXiv preprint arXiv:1909.08593, 2019. 10 Motivating Applications for CONES To motivate CONES, consider a company operating under regulatory oversight, such as an airline or a medic...
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[46]
16 15 Proof of Theorem 3 Proof.Letfbeµ-strongly convex
Substituting∆r i = k2 ri−1 gives k2 T /2+1X i=1 1 ri−1 > D√ 2 .(10) Sincer i−1 is nondecreasing ini, we have 1 ri−1 ≤ 1 r0 ,∀i≤ T 2 + 1.Hence, PT /2+1 i=1 1 ri−1 ≤ T /2+1 r0 .Plugging this into (10), we get thekthat satisfies (9) as k2 · T /2 + 1 r0 > D√ 2 =⇒k > vuut D√ 2 r0 T 2 + 1.(11) Finally, plugging this into (8), we haveM G(T)≥kT > T r D√ 2 r0 T 2 ...
-
[47]
Note that the contours of the function are squares centered at the origin with their sides parallel to the co- ordinate axes. Fixinga≥D/2 √ 2ensures that the sides ofXthat are parallel to the x-axis have the same function value (The side on the top will havef(p, q) = max(|p|, a) =aand the one on the bottom will havef(p, q) = max(|p|, a+D/ √
-
[48]
=a+D/ √ 2). The desired set of minimizers{x ∗ t }for this construction ofS t’s are defined as: x∗ t = (p∗ t , q∗ t ) = ( (−D/2 √ 2,−a− Pt i=1 k/2t−1)iftis odd, (+D/2 √ 2,−a− Pt i=1 k/2t−1)iftis even. (40) The idea is to make the greedy algorithmGoscillate between the vertical sides ofX, while incrementally moving down in the vertical direction. Note that ...
-
[49]
When the first condition is true, i.e., ˜∆Φt ≤ − 1 2 ∥xt−1 −x t∥
˜∆Φt =∥x t −y t∥ − ∥xt−1 −y t∥ ≤ − 1 2 ∥xt−1 −x t∥,or 2.∥y t −x t∥ ≥ 1 4 ∥xt−1 −x t∥. When the first condition is true, i.e., ˜∆Φt ≤ − 1 2 ∥xt−1 −x t∥. Note that cLinG(t) =∥x t −x t−1∥and hence cLinG(t) + 2· ˜∆Φt ≤ ∥x t −x t−1∥ − ∥xt −x t−1∥, = 0≤ 12 α ·(f t(yt)−v t). When the second condition is true i.e.,∥y t −x t∥ ≥ 1 4 ∥xt−1 −x t∥. Sincex t =x ⋆ t for...
-
[50]
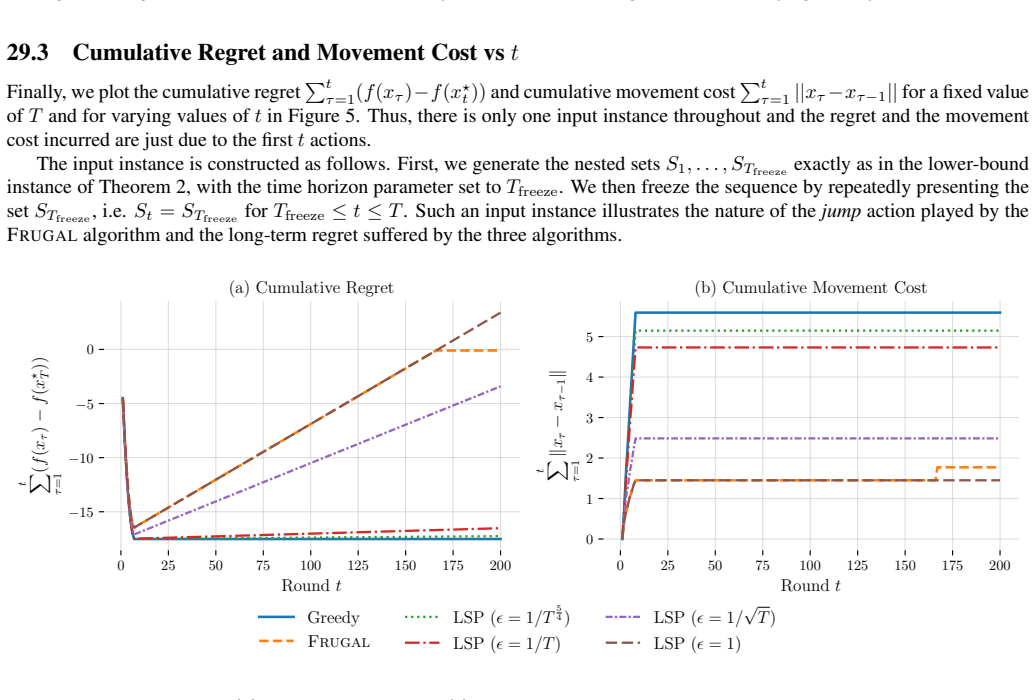
The value ofTwill be chosen later for the different simulations
We fixr 0 = 1,D= 4andk= vuut D√ 2 r0 T 2 + 1 throughout, as in (11). The value ofTwill be chosen later for the different simulations. 29.1 Trajectory visualization −1 0 x −4 −3 −2 −1 0 y x⋆ 0x⋆ 1 x⋆ 2x⋆ 3 x⋆ 4x⋆ 5 x⋆ 6x⋆ 7 x1 = −k (a) Input Instance −1 0 x −4 −3 −2 −1 0 y t = 0 (b) Greedy −1 0 x −4 −3 −2 −1 0 y t = 0 (c) Frugal −1 0 x −4 −3 −2 −1 0 y t = ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.