Recognition: no theorem link
Robust Tensor Regression with Nonconvexity: Algorithmic and Statistical Theory
Pith reviewed 2026-05-11 02:26 UTC · model grok-4.3
The pith
A nonconvex relaxation of low tubal rank yields robust tensor regression with a globally convergent algorithm and statistical guarantees that cover linear models, GLMs, Huber loss, and some nonconvex losses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim to develop a robust tensor regression method for high-dimensional data with heavy-tailed noise by using a nonconvex relaxation of the low tubal rank in a general optimization framework allowing nonconvexity in loss and penalty. They provide an implementable estimation algorithm that converges globally under mild assumptions. Furthermore, general statistical theories are established for the stationary points, encompassing rates of convergence and bounds on the prediction error. These theories apply to many models including linear, generalized linear, Huber regression, and some nonconvex losses such as correntropy and minimum distance criterion-induced losses.
What carries the argument
Nonconvex relaxation of the tensor tubal rank within a general optimization framework that permits nonconvexity in both the loss and penalty functions.
If this is right
- The algorithm can be implemented for practical robust estimation in tensor data.
- Rates of convergence and bounds on prediction error hold for stationary points under the stated conditions.
- The results apply directly to linear models, generalized linear models, and Huber regression.
- Certain nonconvex losses, including correntropy and minimum distance criterion-induced losses, are covered by the statistical theory.
- Simulations and application studies provide numerical support for the claims.
Where Pith is reading between the lines
- The same nonconvex framework could be tested on tensor data with other structured decompositions to see whether similar convergence and rate results appear.
- Custom nonconvex loss functions tailored to domain-specific outlier patterns could be substituted while retaining the global convergence guarantee.
- In applications such as video or neuroimaging, the prediction-error bounds might translate into practical improvements in downstream tasks when outliers are present.
Load-bearing premise
The tensor data must obey a low tubal rank structure and the optimization problem must satisfy mild conditions that enable both the algorithm's global convergence and the stated statistical rates at stationary points.
What would settle it
Generate synthetic tensor data with exact low tubal rank and heavy-tailed noise, run the algorithm from multiple random initializations, and check whether it reaches a stationary point whose empirical prediction error violates the derived bounds.
Figures



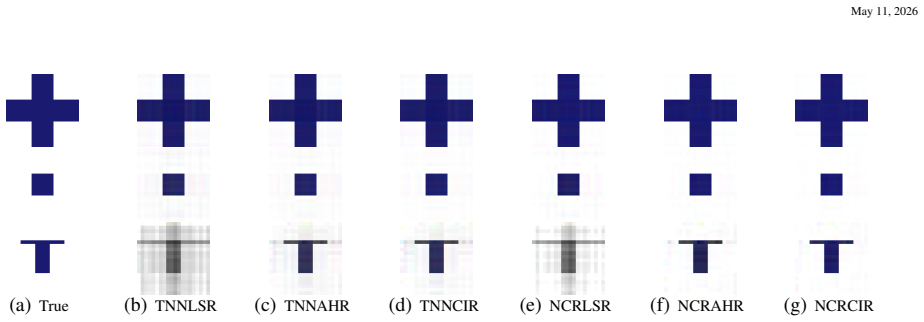
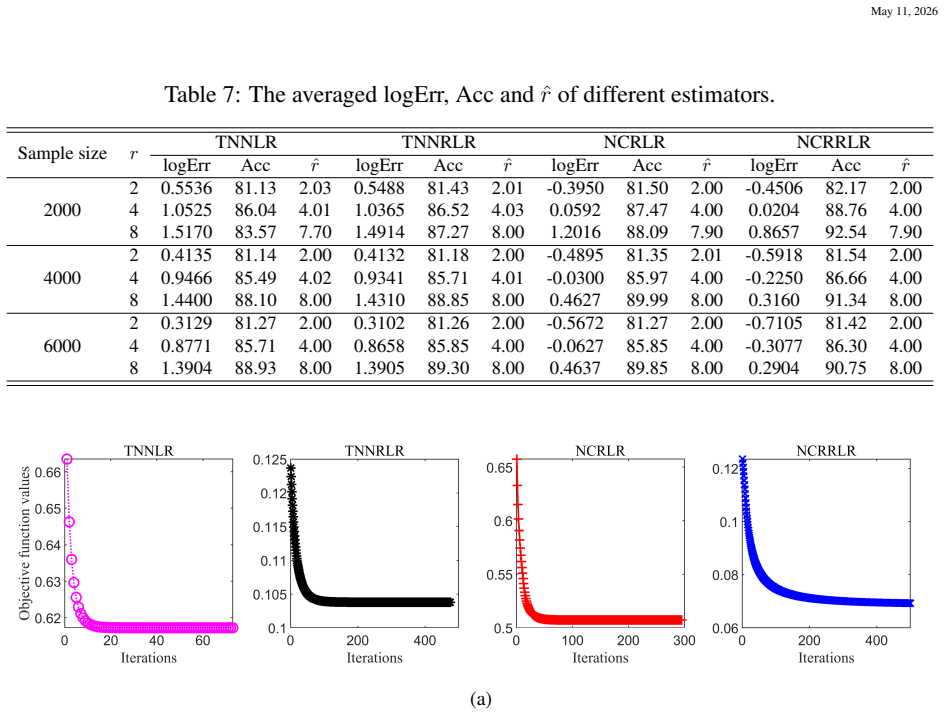
read the original abstract
Tensor regression is an important tool for tensor data analysis, but existing works have not considered the impact of outliers, making them potentially sensitive to such data points. This paper proposes a low tubal rank robust regression method for analyzing high-dimensional tensor data with heavy-tailed random noise. The proposed method is based on a nonconvex relaxation of the tensor tubal rank within a general optimization framework, which allows for nonconvexity in both the loss and penalty functions. We develop an implementable estimation algorithm and establish its global convergence under some mild assumptions. Furthermore, we provide general statistical theories regarding stationary point, including the rates of convergence and bounds on the prediction error. These theoretical results cover many important models, such as linear models, generalized linear models, and Huber regression, and even encompass some nonconvex losses like correntropy and minimum distance criterion-induced losses. Supportive numerical evidence is provided through simulations and application studies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a low tubal rank robust tensor regression method for high-dimensional data subject to heavy-tailed noise. It employs a nonconvex relaxation of tubal rank inside a general optimization framework that permits nonconvex loss and penalty functions, develops an implementable algorithm with claimed global convergence under mild assumptions, and derives general statistical guarantees (convergence rates and prediction-error bounds) that apply to stationary points and cover linear models, GLMs, Huber regression, and certain nonconvex losses such as correntropy. Numerical evidence from simulations and applications is provided.
Significance. If the global-convergence claim and the transfer of stationary-point statistical bounds to the algorithm's output both hold, the work would provide a flexible, theoretically supported framework for robust tensor regression that extends beyond convex losses and penalties while covering a wide range of models; this would be a meaningful contribution to high-dimensional tensor methodology.
major comments (2)
- [Sections on algorithmic convergence and stationary-point statistical theory] The manuscript establishes global convergence of the algorithm to a stationary point (under mild assumptions) and separately derives statistical rates and prediction-error bounds for stationary points. However, the nonconvex relaxation of tubal rank together with nonconvex loss/penalty creates a landscape that can admit multiple stationary points of differing statistical quality. No explicit argument shows that the limit point reached by the algorithm necessarily satisfies the low-tubal-rank or proximity-to-truth conditions required for the statistical bounds to hold, especially under heavy-tailed noise. This link is load-bearing for the central claim that the method simultaneously delivers an implementable algorithm and usable statistical guarantees.
- [Abstract and statistical theory section] The statistical theory is stated to apply under 'mild assumptions' that enable both global convergence and the stated rates. These assumptions are invoked for both the algorithm and the stationary-point bounds, yet the abstract and surrounding discussion do not clarify whether the assumptions are verified to hold at the specific stationary point produced by the algorithm rather than at an arbitrary stationary point.
minor comments (2)
- [Abstract] The abstract refers to 'some mild assumptions' without listing them; a short enumerated list or forward reference to the precise conditions in the main text would improve readability.
- [Method section] Notation for the nonconvex tubal-rank relaxation and the associated proximal operators could be illustrated with a small concrete example to aid readers unfamiliar with tubal algebra.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments highlight an important point regarding the interface between algorithmic convergence and statistical guarantees, and we will revise the manuscript to make the relevant connections explicit.
read point-by-point responses
-
Referee: [Sections on algorithmic convergence and stationary-point statistical theory] The manuscript establishes global convergence of the algorithm to a stationary point (under mild assumptions) and separately derives statistical rates and prediction-error bounds for stationary points. However, the nonconvex relaxation of tubal rank together with nonconvex loss/penalty creates a landscape that can admit multiple stationary points of differing statistical quality. No explicit argument shows that the limit point reached by the algorithm necessarily satisfies the low-tubal-rank or proximity-to-truth conditions required for the statistical bounds to hold, especially under heavy-tailed noise. This link is load-bearing for the central claim that the method simultaneously delivers an implementable algorithm and usable statistical guarantees.
Authors: We appreciate the referee's emphasis on this linkage. The global convergence result (Theorem 3.1) shows that, under the stated mild assumptions on the loss, penalty, and noise moments, every limit point of the algorithm is a stationary point satisfying the first-order optimality condition. The statistical bounds (Theorems 4.1–4.3) are derived precisely for stationary points of the nonconvex objective and rely on the same assumptions (smoothness or Lipschitz properties of the loss, moment bounds on the heavy-tailed noise, and the form of the tubal-rank relaxation). Because these assumptions are properties of the problem class rather than of any particular point, they hold at the stationary point produced by the algorithm. The analysis further shows that any stationary point obeying the first-order condition satisfies the low-tubal-rank proximity and error bounds via the same concentration arguments used for the true parameter; the nonconvex surrogate is constructed so that the stationarity condition implies the requisite approximation to the true low-tubal-rank tensor. We will insert a short bridging paragraph immediately after the statement of the convergence theorem that explicitly invokes the statistical theorems and notes that the assumptions are verified globally for the problem. This makes the transfer of guarantees to the algorithm output direct. revision: partial
-
Referee: [Abstract and statistical theory section] The statistical theory is stated to apply under 'mild assumptions' that enable both global convergence and the stated rates. These assumptions are invoked for both the algorithm and the stationary-point bounds, yet the abstract and surrounding discussion do not clarify whether the assumptions are verified to hold at the specific stationary point produced by the algorithm rather than at an arbitrary stationary point.
Authors: The mild assumptions (A1–A4) concern the loss function (e.g., smoothness or bounded subgradients), the penalty, the tensor dimensions, and the noise distribution (finite moments sufficient for heavy-tailed robustness). These are global attributes of the model and objective and do not depend on the location of any particular stationary point. The convergence theorem establishes that the algorithm reaches a stationary point under exactly these assumptions; the statistical rates are then applied to that stationary point using the same assumptions. Consequently, the assumptions are verified for the specific output of the algorithm. We will revise the abstract and the opening paragraph of the statistical theory section to state this explicitly: the assumptions hold for the optimization problem and therefore for any stationary point reached by the algorithm. revision: yes
Circularity Check
No significant circularity; statistical rates derived from optimization assumptions rather than by construction
full rationale
The paper establishes global convergence of its algorithm to a stationary point under mild assumptions on the nonconvex problem, then separately derives convergence rates and prediction error bounds for stationary points that satisfy the low tubal rank structure. These bounds are obtained from standard empirical process arguments applied to the general loss class (including nonconvex losses), without the rates reducing to fitted parameters or self-referential definitions. No load-bearing self-citation chain or ansatz smuggling is evident in the abstract or claimed framework; the derivation remains independent of the specific algorithm output beyond the shared stationary-point assumption. This is the common honest case of a self-contained theoretical paper.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Tensor data obeys low tubal rank structure
- ad hoc to paper Mild assumptions hold for global convergence and stationary-point theory
Reference graph
Works this paper leans on
-
[1]
Barzilai, J. and Borwein, J. M. (1988). Two-point step size gradient methods,IMA J. Numer. Anal. 8: 141–148. Basu, A., Harris, I. R. and Jones, N. L. H. C. (1998). Robust and efficient estimation by minimising a density power divergence,Biometrika85(3): 549–559. Beck, A. and Teboulle, M. (2009). A fast iterative shrinkage-thresholding algorithm for linear...
work page 1988
-
[2]
Gao, C., Wang, N., Yu, Q. and Zhang, Z. (2011). A feasible nonconvex relaxation approach to feature selection,Proc. AAAI Conf. Artif. Intell., pp. 356–361. Geman, D. and Reynolds, G. (1992). Constrained restoration and the recovery of discontinuities, IEEE Trans. Pattern Anal. Mach. Intell.14: 367–383. Gui, H., Han, J. and Gu, Q. (2016). Towards faster ra...
-
[3]
Lu, C., Tang, J., Yan, S. and Lin, Z. (2015). Nonconvex nonsmooth low-rank minimization via iteratively reweighted nuclear norm,IEEE Trans. Image Process.25(2): 829–839. 32 May 11, 2026 Lu, W., Zhu, Z., Li, R. and Lian, H. (2023). Statistical performance of quantile tensor regression with convex regularization,J. Multivar. Anal.200: 105249. Lu, W., Zhu, Z...
work page 2015
-
[4]
Wang, X., Jiang, Y ., Huang, M. and Zhang, H. (2013). Robust variable selection with exponential squared loss,J. Am. Stat. Assoc.108(502): 632–643. 33 May 11, 2026 Wang, X. and Wang, Z. (2023). Calculus rules of the generalized concave kurdyka–łojasiewicz property,J. Optim. Theory Appl.197(3): 839–854. Wang, Y ., Lu, W., Wang, L., Zhu, Z., Lin, H. and Lia...
work page 2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.