Recognition: no theorem link
Is the Future Compatible? Diagnosing Dynamic Consistency in World Action Models
Pith reviewed 2026-05-11 02:27 UTC · model grok-4.3
The pith
Action-state consistency diagnoses whether World Action Models produce futures that match their own actions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
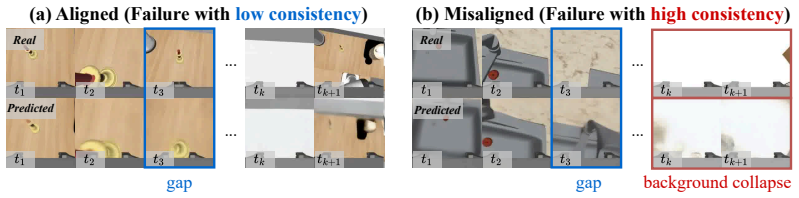
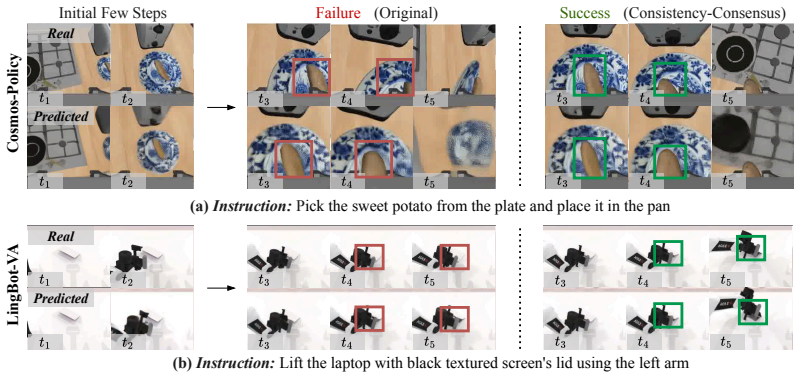
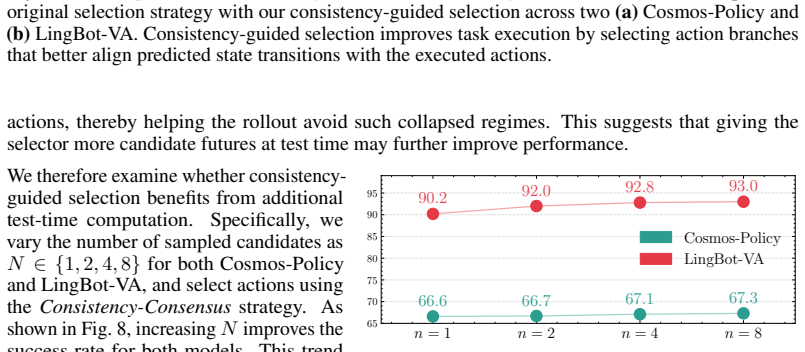
Action-state consistency, the alignment between predicted actions and induced state transitions, systematically separates successful and failed rollouts in representative joint-prediction and inverse-dynamics World Action Models and follows trends similar to learned value estimates. Background collapse, where low-dynamics trajectories become deceptively consistent, forms an important boundary condition. A value-free consensus strategy that ranks candidate rollouts by agreement among predicted futures improves success rates on RoboCasa and RoboTwin 2.0 without further training or reward modeling.
What carries the argument
Action-state consistency: the alignment between a model's predicted action sequence and the state transitions that result when those actions are applied to the model's own predicted observations.
If this is right
- Action-state consistency provides a diagnostic for WAM reliability that goes beyond visual plausibility of predicted observations.
- Consistency scores can be used for test-time ranking of imagined futures without any learned value function or external reward.
- Background collapse limits the diagnostic on trajectories dominated by static elements.
- The consensus ranking strategy raises task success on the tested robot environments.
Where Pith is reading between the lines
- Internal agreement among multiple predicted futures may serve as a general proxy for plan quality in other model-based settings where ground-truth rewards are absent.
- The same consistency measure could be applied to evaluate predictive models outside robotics, such as in video prediction or simulation.
- If consistency generalizes, it could reduce reliance on reward modeling during planning by substituting model-internal signals.
Load-bearing premise
Action-state consistency acts as a general, independent signal of rollout quality that extends beyond the specific models and tasks examined, with background collapse as the main exception.
What would settle it
A new model or task suite in which high-consistency rollouts fail at the same rate as low-consistency ones, or in which the consensus selection method produces no gain in success rate.
Figures













read the original abstract
World Action Models (WAMs) enable decision-making through imagined rollouts by predicting future observations and actions. However, the reliability of these imagined futures remains under-examined: is a generated future merely visually plausible, or is it dynamically compatible with the action sequence it claims to model? In this work, we identify action-state consistency, the alignment between predicted actions and induced state transitions, as a missing reliability axis for WAMs. Through a systematic study across representative joint-prediction and inverse-dynamics models, we find that action-state consistency systematically separates successful and failed rollouts across many tasks and follows similar success-failure trends as learned value estimates. These results suggest that consistency captures decision-relevant structure beyond visual realism. We further identify background collapse as an important boundary condition, where low-dynamics failed trajectories can become deceptively consistent because static futures are easier to predict. Building on these findings, we introduce a value-free consensus strategy for test-time selection, which ranks candidate rollouts by agreement among predicted futures. This strategy improves success rates on RoboCasa and RoboTwin 2.0 without additional training or reward modeling. Taken together, our findings establish action-state consistency as both a diagnostic tool for evaluating WAM reliability and a practical signal for value-free planning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that action-state consistency (alignment between predicted actions and induced state transitions) is a missing reliability axis for World Action Models (WAMs). It reports that this metric systematically separates successful from failed rollouts across joint-prediction and inverse-dynamics models, tracks trends similar to learned value estimates, identifies background collapse as a key boundary condition for low-dynamics failures, and introduces a value-free consensus strategy that ranks candidate rollouts by agreement among predicted futures, yielding improved success rates on RoboCasa and RoboTwin 2.0 without training or rewards.
Significance. If the empirical findings hold, the work supplies a concrete diagnostic for dynamic compatibility in WAMs beyond visual plausibility and a practical, reward-free test-time selection method. This could strengthen model-based planning in robotics by surfacing an independent signal of rollout quality, provided the consistency metric and consensus procedure generalize beyond the tested models and tasks.
major comments (2)
- [Abstract] Abstract: the claim that action-state consistency 'systematically separates successful and failed rollouts' and that the consensus strategy 'improves success rates' rests on assertions whose support cannot be verified, as the text supplies no experimental details, controls, statistical tests, ablation results, or quantitative metrics.
- [Results] The results on the consensus strategy: while background collapse is flagged as a boundary condition, the manuscript provides no evidence that mutual agreement among predicted futures avoids or corrects for shared model biases (e.g., all models collapsing to static backgrounds because they are easier to predict); without such a demonstration the reported gains on RoboCasa and RoboTwin 2.0 may reflect benchmark-specific artifacts rather than a reliable proxy for dynamic compatibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, clarifying the support in the full manuscript while acknowledging areas for potential expansion.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that action-state consistency 'systematically separates successful and failed rollouts' and that the consensus strategy 'improves success rates' rests on assertions whose support cannot be verified, as the text supplies no experimental details, controls, statistical tests, ablation results, or quantitative metrics.
Authors: Abstracts are constrained by length and conventionally omit detailed experimental protocols. The full manuscript reports quantitative results across joint-prediction and inverse-dynamics models on multiple tasks, including consistency score distributions that separate successful from failed rollouts, correlation trends with learned value estimates, ablation studies on model variants, and concrete success-rate gains (with statistical reporting) from the consensus selector on RoboCasa and RoboTwin 2.0. We are prepared to incorporate selected quantitative highlights into the abstract in revision. revision: partial
-
Referee: [Results] The results on the consensus strategy: while background collapse is flagged as a boundary condition, the manuscript provides no evidence that mutual agreement among predicted futures avoids or corrects for shared model biases (e.g., all models collapsing to static backgrounds because they are easier to predict); without such a demonstration the reported gains on RoboCasa and RoboTwin 2.0 may reflect benchmark-specific artifacts rather than a reliable proxy for dynamic compatibility.
Authors: We agree that explicit verification against shared biases is desirable. Our evaluation already spans architecturally distinct model families (joint-prediction and inverse-dynamics), and the consensus procedure selects among multiple predicted futures per rollout. Background collapse is explicitly identified as a low-dynamics failure mode in which high consistency can occur for static predictions. The observed improvements on two independent benchmarks provide empirical support that the agreement signal is useful, yet we lack a controlled experiment that isolates correction of common collapse biases. We can expand the discussion of this limitation and, if space permits, add targeted analysis in revision. revision: partial
Circularity Check
No significant circularity; empirical diagnostics and test-time consensus are independent of fitted inputs.
full rationale
The paper defines action-state consistency explicitly as alignment between a model's predicted actions and the state transitions those actions induce, then reports an empirical study showing this metric separates successful versus failed rollouts across joint-prediction and inverse-dynamics models on multiple tasks. The value-free consensus strategy is introduced as a post-hoc ranking of candidate rollouts by mutual agreement among their predicted futures, without reference to learned value functions, rewards, or model-specific normalizations that would make the ranking tautological. No equations, self-citations, or uniqueness theorems are presented that reduce either the diagnostic separation or the consensus improvement to a re-expression of the input data or prior author results. The reported gains on RoboCasa and RoboTwin 2.0 are therefore external to the definitions themselves and rest on benchmark evaluation rather than construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption World Action Models enable decision-making through imagined rollouts by predicting future observations and actions
- domain assumption Action-state consistency can be measured as the alignment between predicted actions and induced state transitions
invented entities (2)
-
action-state consistency
no independent evidence
-
background collapse
no independent evidence
Reference graph
Works this paper leans on
-
[1]
World Simulation with Video Foundation Models for Physical AI
Arslan Ali, Junjie Bai, Maciej Bala, Yogesh Balaji, Aaron Blakeman, Tiffany Cai, Jiaxin Cao, Tianshi Cao, Elizabeth Cha, Yu-Wei Chao, et al. World simulation with video foundation models for physical ai.arXiv preprint arXiv:2511.00062, 2025
work page internal anchor Pith review arXiv 2025
-
[2]
Zechen Bai, Chen Gao, and Mike Zheng Shou. Evolve-vla: Test-time training from environment feedback for vision-language-action models.arXiv preprint arXiv:2512.14666, 2025
-
[3]
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mido Assran, and Nicolas Ballas. Revisiting feature prediction for learning visual representations from video.Transactions on Machine Learning Research, 2024
work page 2024
-
[4]
Motus: A unified latent action world model
Hongzhe Bi, Hengkai Tan, Shenghao Xie, Zeyuan Wang, Shuhe Huang, Haitian Liu, Ruowen Zhao, Yao Feng, Chendong Xiang, Yinze Rong, et al. Motus: A unified latent action world model. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026
work page 2026
-
[5]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, Yusuf Aytar, Sarah Maria Elisabeth Bechtle, Feryal Behbahani, Stephanie C.Y . Chan, Nicolas Heess, Lucy Gonzalez, Simon Osindero, Sherjil Ozair, Scott Reed, Jingwei Zhang, Konrad Zolna, Jeff Clune, Nando...
work page 2024
-
[8]
WorldVLA: Towards Autoregressive Action World Model
Jun Cen, Chaohui Yu, Hangjie Yuan, Yuming Jiang, Siteng Huang, Jiayan Guo, Xin Li, Yibing Song, Hao Luo, Fan Wang, et al. Worldvla: Towards autoregressive action world model.arXiv preprint arXiv:2506.21539, 2025
work page internal anchor Pith review arXiv 2025
-
[9]
Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Zixuan Li, Qiwei Liang, Xianliang Lin, Yiheng Ge, Zhenyu Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025
work page internal anchor Pith review arXiv 2025
-
[10]
Mingtong Dai, Lingbo Liu, Yongjie Bai, Yang Liu, Zhouxia Wang, Rui Su, Chunjie Chen, Liang Lin, and Xinyu Wu. Rover: Robot reward model as test-time verifier for vision-language-action model.arXiv preprint arXiv:2510.10975, 2025
-
[11]
Wenkai Guo, Guanxing Lu, Haoyuan Deng, Zhenyu Wu, Yansong Tang, and Ziwei Wang. Vla-reasoner: Empowering vision-language-action models with reasoning via online monte carlo tree search.arXiv preprint arXiv:2509.22643, 2025
-
[12]
David Ha and Jürgen Schmidhuber. World models. InConference on Neural Information Processing Systems, 2018
work page 2018
-
[13]
Dream to control: Learning behaviors by latent imagination
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination. InInternational Conference on Learning Representations, 2020
work page 2020
-
[14]
Mastering atari with discrete world models
Danijar Hafner, Timothy P Lillicrap, Mohammad Norouzi, and Jimmy Ba. Mastering atari with discrete world models. InInternational Conference on Learning Representations, 2021
work page 2021
-
[15]
Mastering diverse control tasks through world models.Nature, 640(8059):647–653, 2025
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse control tasks through world models.Nature, 640(8059):647–653, 2025
work page 2025
-
[16]
A dual process vla: Efficient robotic manipulation leveraging vlm.arXiv preprint arXiv:2410.15549,
ByungOk Han, Jaehong Kim, and Jinhyeok Jang. A dual process vla: Efficient robotic manipulation leveraging vlm.arXiv preprint arXiv:2410.15549, 2024
-
[17]
Safedreamer: Safe reinforcement learning with world models
Weidong Huang, Jiaming Ji, Chunhe Xia, Borong Zhang, and Yaodong Yang. Safedreamer: Safe reinforcement learning with world models. InInternational Conference on Learning Representations, 2024
work page 2024
-
[18]
$\pi^{*}_{0.6}$: a VLA That Learns From Experience
Physical Intelligence, Ali Amin, Raichelle Aniceto, Ashwin Balakrishna, Kevin Black, Ken Conley, Grace Connors, James Darpinian, Karan Dhabalia, Jared DiCarlo, et al. π∗ 0.6: a vla that learns from experience. arXiv preprint arXiv:2511.14759, 2025. 10
work page Pith review arXiv 2025
-
[19]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. π0.5: a vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Suhyeok Jang, Dongyoung Kim, Changyeon Kim, Youngsuk Kim, and Jinwoo Shin. Verifier-free test-time sampling for vision language action models.arXiv preprint arXiv:2510.05681, 2025
-
[21]
Openvla: An open-source vision-language- action model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan P Foster, Pannag R Sanketi, Quan Vuong, et al. Openvla: An open-source vision-language- action model. InConference on Robot Learning, pages 2679–2713, 2025
work page 2025
-
[22]
Cosmos policy: Fine-tuning video models for visuomotor control and planning
Moo Jin Kim, Yihuai Gao, Tsung-Yi Lin, Yen-Chen Lin, Yunhao Ge, Grace Lam, Percy Liang, Shuran Song, Ming-Yu Liu, Chelsea Finn, and Jinwei Gu. Cosmos policy: Fine-tuning video models for visuomotor control and planning. InInternational Conference on Learning Representations, 2026
work page 2026
-
[23]
Jacky Kwok, Xilun Zhang, Mengdi Xu, Yuejiang Liu, Azalia Mirhoseini, Chelsea Finn, and Marco Pavone. Scaling verification can be more effective than scaling policy learning for vision-language-action alignment. arXiv preprint arXiv:2602.12281, 2026
-
[24]
Robotic world model: A neural network simulator for robust policy optimization in robotics
Chenhao Li, Andreas Krause, and Marco Hutter. Robotic world model: A neural network simulator for robust policy optimization in robotics. InConference on Neural Information Processing Systems Workshop on Embodied World Models for Decision Making, 2025
work page 2025
-
[25]
Causal world modeling for robot control
Lin Li, Qihang Zhang, Yiming Luo, Shuai Yang, Ruilin Wang, Fei Han, Mingrui Yu, Zelin Gao, Nan Xue, Xing Zhu, et al. Causal world modeling for robot control. InRobotics: Science and Systems, 2026
work page 2026
-
[26]
Shuang Li, Yihuai Gao, Dorsa Sadigh, and Shuran Song. Unified video action model.arXiv preprint arXiv:2503.00200, 2025
work page internal anchor Pith review arXiv 2025
-
[27]
Video generators are robot policies.arXiv preprint arXiv:2508.00795, 2025
Junbang Liang, Pavel Tokmakov, Ruoshi Liu, Sruthi Sudhakar, Paarth Shah, Rares Ambrus, and Carl V ondrick. Video generators are robot policies.arXiv preprint arXiv:2508.00795, 2025
-
[28]
Lucas Maes, Quentin Le Lidec, Damien Scieur, Yann LeCun, and Randall Balestriero. Leworldmodel: Stable end-to-end joint-embedding predictive architecture from pixels.arXiv preprint arXiv:2603.19312, 2026
-
[29]
Robocasa: Large-scale simulation of everyday tasks for generalist robots
Soroush Nasiriany, Abhiram Maddukuri, Lance Zhang, Adeet Parikh, Aaron Lo, Abhishek Joshi, Ajay Mandlekar, and Yuke Zhu. Robocasa: Large-scale simulation of everyday tasks for generalist robots. In Robotics: Science and Systems, 2024
work page 2024
-
[30]
Video generation models as world simulators
OpenAI. Video generation models as world simulators. Technical report, OpenAI, 2024. URL https: //openai.com/index/video-generation-models-as-world-simulators/
work page 2024
-
[31]
WorldSimBench: Towards video generation models as world simulators
Yiran Qin, Zhelun Shi, Jiwen Yu, Xijun Wang, Enshen Zhou, Lijun Li, Zhenfei Yin, Xihui Liu, Lu Sheng, Jing Shao, Lei Bai, and Ruimao Zhang. WorldSimBench: Towards video generation models as world simulators. InInternational Conference on Machine Learning, volume 267, pages 50338–50362, 2025
work page 2025
-
[32]
Roboscape: Physics- informed embodied world model
Yu Shang, Xin Zhang, Yinzhou Tang, Lei Jin, Chen Gao, Wei Wu, and Yong Li. Roboscape: Physics- informed embodied world model. InConference on Neural Information Processing Systems, 2026
work page 2026
-
[33]
Advancing open-source world models,
Robbyant Team, Zelin Gao, Qiuyu Wang, Yanhong Zeng, Jiapeng Zhu, Ka Leong Cheng, Yixuan Li, Hanlin Wang, Yinghao Xu, Shuailei Ma, et al. Advancing open-source world models.arXiv preprint arXiv:2601.20540, 2026
-
[34]
Yalcin Tur, Jalal Naghiyev, Haoquan Fang, Wei-Chuan Tsai, Jiafei Duan, Dieter Fox, and Ranjay Krishna. Recurrent-depth vla: Implicit test-time compute scaling of vision-language-action models via latent iterative reasoning.arXiv preprint arXiv:2602.07845, 2026
-
[35]
Yan Wang, Wenjie Luo, Junjie Bai, Yulong Cao, Tong Che, Ke Chen, Yuxiao Chen, Jenna Diamond, Yifan Ding, Wenhao Ding, et al. Alpamayo-r1: Bridging reasoning and action prediction for generalizable autonomous driving in the long tail.arXiv preprint arXiv:2511.00088, 2025
-
[36]
RLVR-world: Training world models with reinforcement learning
Jialong Wu, Shaofeng Yin, Ningya Feng, and Mingsheng Long. RLVR-world: Training world models with reinforcement learning. InConference on Neural Information Processing Systems, 2025
work page 2025
-
[37]
Daydreamer: World models for physical robot learning
Philipp Wu, Alejandro Escontrela, Danijar Hafner, Pieter Abbeel, and Ken Goldberg. Daydreamer: World models for physical robot learning. InConference on Robot Learning, pages 2226–2240, 2023. 11
work page 2023
-
[38]
Gigaworld-policy: An efficient action- centered world–action model, 2026
Angen Ye, Boyuan Wang, Chaojun Ni, Guan Huang, Guosheng Zhao, Hao Li, Hengtao Li, Jie Li, Jindi Lv, Jingyu Liu, et al. Gigaworld-policy: An efficient action-centered world–action model.arXiv preprint arXiv:2603.17240, 2026
-
[39]
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan Xiang, et al. World action models are zero-shot policies.International Conference on Learning Representation Workshop of the 2nd Workshop on World Models: Understanding, Modelling and Scaling, 2026
work page 2026
-
[40]
Fast-WAM: Do World Action Models Need Test-time Future Imagination?
Tianyuan Yuan, Zibin Dong, Yicheng Liu, and Hang Zhao. Fast-wam: Do world action models need test-time future imagination?arXiv preprint arXiv:2603.16666, 2026
work page internal anchor Pith review arXiv 2026
-
[41]
Jiahan Zhang, Muqing Jiang, Nanru Dai, TaiMing Lu, Arda Uzunoglu, Shunchi Zhang, Yana Wei, Jiahao Wang, Vishal M. Patel, Paul Pu Liang, Daniel Khashabi, Cheng Peng, Rama Chellappa, Tianmin Shu, Alan Yuille, Yilun Du, and Jieneng Chen. World-in-world: World models in a closed-loop world. In International Conference on Learning Representations, 2026
work page 2026
-
[42]
arXiv preprint arXiv:2512.06628 , year=
Ruicheng Zhang, Mingyang Zhang, Jun Zhou, Zhangrui Guo, Xiaofan Liu, Zunnan Xu, Zhizhou Zhong, Puxin Yan, Haocheng Luo, and Xiu Li. Mind-v: Hierarchical video generation for long-horizon robotic manipulation with rl-based physical alignment.arXiv preprint arXiv:2512.06628, 2025
-
[43]
X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
Jinliang Zheng, Jianxiong Li, Zhihao Wang, Dongxiu Liu, Xirui Kang, Yuchun Feng, Yinan Zheng, Jiayin Zou, Yilun Chen, Jia Zeng, et al. X-vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model.arXiv preprint arXiv:2510.10274, 2025
work page internal anchor Pith review arXiv 2025
-
[44]
Flare: Robot learning with implicit world modeling
Ruijie Zheng, Jing Wang, Scott Reed, Johan Bjorck, Yu Fang, Fengyuan Hu, Joel Jang, Kaushil Kundalia, Zongyu Lin, Loïc Magne, Avnish Narayan, You Liang Tan, Guanzhi Wang, Qi Wang, Jiannan Xiang, Yinzhen Xu, Seonghyeon Ye, Jan Kautz, Furong Huang, Yuke Zhu, and Linxi Fan. Flare: Robot learning with implicit world modeling. InConference on Robot Learning, v...
work page 2025
-
[45]
Unified World Models: Coupling Video and Action Diffusion for Pretraining on Large Robotic Datasets
Chuning Zhu, Raymond Yu, Siyuan Feng, Benjamin Burchfiel, Paarth Shah, and Abhishek Gupta. Unified world models: Coupling video and action diffusion for pretraining on large robotic datasets.arXiv preprint arXiv:2504.02792, 2025
work page internal anchor Pith review arXiv 2025
-
[46]
RT-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. RT-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183, 2023. 12 Appendix Content A Implementation Details 14 B Related Work 14 C Per-Task Analysis 15 C.1...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.