Recognition: 2 theorem links
· Lean TheoremMind the Gap: Geometrically Accurate Generative Reconstruction from Disjoint Views
Pith reviewed 2026-05-11 02:10 UTC · model grok-4.3
The pith
A new framework enables accurate 3D reconstruction from completely non-overlapping camera views by synthesizing bridging perspectives.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
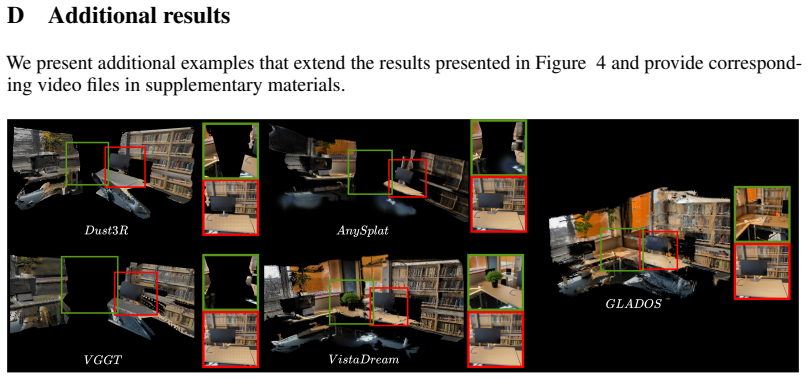
The paper establishes that existing state-of-the-art reconstruction and generative methods fail on zero-overlap inputs by yielding disconnected surfaces or semantically inconsistent shapes. GLADOS solves the problem through a three-stage process in which foundation models create intermediate perspectives to link the disjoint views, a global alignment step creates a coarse geometric scaffold that absorbs contradictions from the generated images, and iterative expansion plus consistency optimization fills gaps and unifies the final model.
What carries the argument
The GLADOS three-stage pipeline of generative bridging to connect inputs, robust coarse reconstruction via global alignment that absorbs local errors, and iterative context expansion with consistency optimization.
If this is right
- 3D modeling becomes feasible in distributed settings such as robot swarms or crowdsourced collections where overlapping views cannot be obtained.
- The modular design permits any improved generative model, reconstruction algorithm, or inpainting technique to be substituted into the pipeline.
- New dataset and metrics allow direct measurement of reconstruction quality specifically under zero-overlap conditions.
- Standard methods are shown to produce disconnected geometries or incoherent semantics when inputs lack any shared content.
Where Pith is reading between the lines
- The bridging approach could extend to other sparse-view problems such as completing large scenes from scattered observations taken at different times.
- Stronger generative models might eventually reduce the need for the alignment stage, leading to simpler end-to-end pipelines.
- Real-world validation on data with varying lighting or camera types would test how well the error-absorption mechanism holds outside controlled benchmarks.
Load-bearing premise
That the geometric errors created when foundation models synthesize intermediate views can be corrected by later global alignment and consistency steps instead of producing unresolvable contradictions.
What would settle it
Apply GLADOS and baseline methods to a set of real images captured by separate robots with no overlap and check whether the output forms one connected, semantically consistent 3D model while baselines produce disconnected or incoherent results.
Figures








read the original abstract
3D vision systems are fundamentally constrained by their reliance on visual overlap: reconstruction methods require it for geometric alignment, while generative models use it to enforce multi-view consistency. This limitation is particularly acute in real-world scenarios such as distributed swarm robotics or crowd-sourced data collection, where capturing overlapping perspectives, both in terms of spatial and appearance overlap, is often impossible. We introduce Generative Reconstruction from Disjoint Views as a new paradigm, establish a comprehensive dataset, and propose specialized evaluation metrics for zero-overlap scenarios. Our benchmarking demonstrates that existing state-of-the-art methods fail catastrophically on this task, producing disconnected geometries or semantically incoherent reconstructions. To address these limitations, we propose GLADOS, a general, modular framework that operates through three stages: (1) Generative Bridging, where foundation models synthesize intermediate perspectives to connect disjoint inputs; (2) Robust Coarse 3D Reconstruction, that establish coarse geometric scaffold via global alignment which absorbs local contradictions from generative process; and (3) Iterative Context Expansion and Consistency Optimization to fill missing regions and unify the reconstruction. As an architectureagnostic framework, GLADOS enables seamless integration of future advances in generation, reconstruction, and inpainting. The source code is available at: https://github.com/gwilczynski95/GLADOS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that 3D vision systems are limited by reliance on visual overlap for both reconstruction and generative consistency, introduces Generative Reconstruction from Disjoint Views as a new paradigm for zero-overlap scenarios (e.g., swarm robotics), establishes a dataset and specialized metrics, demonstrates catastrophic failure of existing SOTA methods, and proposes the GLADOS framework with three stages: (1) generative bridging via foundation models to synthesize intermediates, (2) robust coarse 3D reconstruction via global alignment to absorb local contradictions, and (3) iterative context expansion and consistency optimization to unify the output. The framework is presented as modular and architecture-agnostic, with source code released.
Significance. If the central claims hold, the work would meaningfully expand 3D reconstruction to practical non-overlapping capture settings and provide a reusable benchmark via the new dataset and metrics. The release of source code is a clear strength for reproducibility, and the modular design allows future integration of improved generative or reconstruction components. However, the absence of quantitative bounds on error propagation from generative bridging reduces the immediate impact.
major comments (3)
- Abstract and GLADOS framework description: the central claim that global alignment in stage (2) absorbs local geometric contradictions from generative bridging (stage 1) without creating irresolvable inconsistencies (e.g., contradictory depths or object placements) is load-bearing but unsupported by any quantitative error bounds, tolerance thresholds, or failure-mode analysis for the zero-overlap regime; if absorption fails, stage (3) has no viable scaffold.
- Iterative Context Expansion and Consistency Optimization stage: the optimization is described only at a high level with no equations, algorithmic pseudocode, or convergence criteria, making it impossible to verify how it enforces geometric accuracy or resolves contradictions introduced by foundation-model synthesis.
- Benchmarking claims in Abstract: the assertion that SOTA methods 'fail catastrophically' (producing disconnected geometries or incoherent reconstructions) is used to motivate the new paradigm but lacks any cited quantitative results, specific metrics (e.g., Chamfer distance, IoU), or ablation tables in the provided description, weakening the justification for GLADOS.
minor comments (2)
- Abstract: the GLADOS acronym is introduced without expansion on first use.
- The manuscript would benefit from a dedicated related-work subsection contrasting GLADOS with prior multi-view generative reconstruction methods that assume partial overlap.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas where the presentation can be strengthened, particularly around quantitative support and clarity in the abstract and framework description. We address each major comment below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: Abstract and GLADOS framework description: the central claim that global alignment in stage (2) absorbs local geometric contradictions from generative bridging (stage 1) without creating irresolvable inconsistencies (e.g., contradictory depths or object placements) is load-bearing but unsupported by any quantitative error bounds, tolerance thresholds, or failure-mode analysis for the zero-overlap regime; if absorption fails, stage (3) has no viable scaffold.
Authors: We agree that the abstract is high-level and does not include explicit quantitative bounds or failure-mode analysis. The full manuscript (Section 3.2) describes the robust global alignment using outlier-robust optimization that tolerates local generative inconsistencies, with empirical validation on the proposed dataset showing successful absorption in the zero-overlap setting. However, we acknowledge the value of adding formal bounds and analysis. We will revise the abstract to reference these aspects and add a new subsection with derived tolerance thresholds, error propagation analysis, and identified failure cases where stage (3) may not fully resolve issues. revision: yes
-
Referee: Iterative Context Expansion and Consistency Optimization stage: the optimization is described only at a high level with no equations, algorithmic pseudocode, or convergence criteria, making it impossible to verify how it enforces geometric accuracy or resolves contradictions introduced by foundation-model synthesis.
Authors: The full manuscript (Section 3.3) formalizes this stage with a consistency optimization objective and iterative procedure. To improve accessibility and verifiability, we will expand the framework overview in the revised manuscript to include the key equations for the geometric consistency loss, pseudocode for the iterative expansion algorithm, and convergence criteria based on stabilization of the multi-view consistency metric below a defined threshold. revision: yes
-
Referee: Benchmarking claims in Abstract: the assertion that SOTA methods 'fail catastrophically' (producing disconnected geometries or incoherent reconstructions) is used to motivate the new paradigm but lacks any cited quantitative results, specific metrics (e.g., Chamfer distance, IoU), or ablation tables in the provided description, weakening the justification for GLADOS.
Authors: The abstract summarizes results detailed in Section 4 and Table 2, where SOTA methods exhibit catastrophic failures with Chamfer distances orders of magnitude higher and IoU scores below 0.2 due to disconnected components. We will update the abstract to explicitly cite these quantitative metrics (Chamfer distance and IoU) and reference the relevant table and ablation studies to strengthen the motivation and justification. revision: yes
Circularity Check
No circularity: engineering composition of independent components
full rationale
The paper introduces GLADOS as a modular three-stage pipeline (generative bridging via foundation models, robust coarse reconstruction with global alignment, and iterative consistency optimization) without any equations, fitted parameters, or derivations that reduce claimed outputs to inputs by construction. Benchmarking of existing methods' failures and the new zero-overlap dataset/metrics are presented as empirical contributions rather than self-referential predictions. No self-citation chains or uniqueness theorems are invoked to justify core choices; the framework is explicitly architecture-agnostic and relies on external advances in generation and reconstruction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Foundation models can synthesize intermediate perspectives that preserve sufficient geometric structure for subsequent alignment despite local inaccuracies
invented entities (1)
-
GLADOS framework
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
GLADOS... three stages: (1) Generative Bridging... (2) Robust Coarse... (3) Iterative Context Expansion
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Srinivasan, Matthew Tancik, Jonathan T
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. In ECCV, 2020
work page 2020
-
[2]
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3D Gaussian Splatting for Real-Time Radiance Field Rendering.ACM Transactions on Graphics, 42(4), 2023
work page 2023
-
[3]
Dust3r: Geometric 3d vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vision made easy. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20697–20709, 2024
work page 2024
-
[4]
Lihan Jiang, Yucheng Mao, Linning Xu, Tao Lu, Kerui Ren, Yichen Jin, Xudong Xu, Mulin Yu, Jiangmiao Pang, Feng Zhao, et al. Anysplat: Feed-forward 3d gaussian splatting from unconstrained views.ACM Transactions on Graphics (TOG), 44(6):1–16, 2025
work page 2025
-
[5]
Brandon Smart, Chuanxia Zheng, Iro Laina, and Victor Adrian Prisacariu. Splatt3r: Zero-shot gaussian splatting from uncalibrated image pairs.arXiv preprint arXiv:2408.13912, 2024
-
[6]
Data-efficient decentralized visual slam
Titus Cieslewski, Siddharth Choudhary, and Davide Scaramuzza. Data-efficient decentralized visual slam. In2018 IEEE international conference on robotics and automation (ICRA), pages 2466–2473. IEEE, 2018
work page 2018
-
[7]
Chen Change Loy, Tao Xiang, and Shaogang Gong. Time-delayed correlation analysis for multi-camera activity understanding.International Journal of Computer Vision, 90(1):106–129, 2010
work page 2010
-
[8]
Reconstructing the world* in six days*(as captured by the yahoo 100 million image dataset)
Jared Heinly, Johannes L Schonberger, Enrique Dunn, and Jan-Michael Frahm. Reconstructing the world* in six days*(as captured by the yahoo 100 million image dataset). InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3287–3295, 2015
work page 2015
-
[9]
Align3r: Aligned monocular depth estimation for dynamic videos
Jiahao Lu, Tianyu Huang, Peng Li, Zhiyang Dou, Cheng Lin, Zhiming Cui, Zhen Dong, Sai-Kit Yeung, Wenping Wang, and Yuan Liu. Align3r: Aligned monocular depth estimation for dynamic videos. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22820–22830, 2025
work page 2025
-
[10]
Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass
Jianing Yang, Alexander Sax, Kevin J Liang, Mikael Henaff, Hao Tang, Ang Cao, Joyce Chai, Franziska Meier, and Matt Feiszli. Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21924–21935, 2025
work page 2025
-
[11]
Easi3r: Estimating disentangled motion from dust3r without training
Xingyu Chen, Yue Chen, Yuliang Xiu, Andreas Geiger, and Anpei Chen. Easi3r: Estimating disentangled motion from dust3r without training. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9158–9168, 2025
work page 2025
-
[12]
Vis- tadream: Sampling multiview consistent images for single-view scene reconstruction
Haiping Wang, Yuan Liu, Ziwei Liu, Wenping Wang, Zhen Dong, and Bisheng Yang. Vis- tadream: Sampling multiview consistent images for single-view scene reconstruction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 26772– 26782, 2025. 10
work page 2025
-
[13]
Jaeyoung Chung, Suyoung Lee, Hyeongjin Nam, Jaerin Lee, and Kyoung Mu Lee. Lucid- dreamer: Domain-free generation of 3d gaussian splatting scenes.IEEE Transactions on Visualization & Computer Graphics, (01):1–12, 2025
work page 2025
-
[14]
Dreamscape: 3d scene creation via gaussian splatting joint correlation modeling
Yueming Zhao, Xuening Yuan, Hongyu Yang, and Di Huang. Dreamscape: 3d scene creation via gaussian splatting joint correlation modeling. In2025 IEEE International Conference on Multimedia and Expo (ICME), pages 1–6. IEEE, 2025
work page 2025
-
[15]
Wangbo Yu, Jinbo Xing, Li Yuan, Wenbo Hu, Xiaoyu Li, Zhipeng Huang, Xiangjun Gao, Tien-Tsin Wong, Ying Shan, and Yonghong Tian. Viewcrafter: Taming video diffusion models for high-fidelity novel view synthesis.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
work page 2025
-
[16]
World-consistent video diffusion with explicit 3d modeling
Qihang Zhang, Shuangfei Zhai, Miguel Angel Bautista Martin, Kevin Miao, Alexander Toshev, Joshua Susskind, and Jiatao Gu. World-consistent video diffusion with explicit 3d modeling. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 21685–21695, 2025
work page 2025
-
[17]
Milan Erdelj, Michał Król, and Enrico Natalizio. Wireless sensor networks and multi-uav systems for natural disaster management.Computer Networks, 124:72–86, 2017
work page 2017
-
[18]
Carmine Tommaso Recchiuto and Antonio Sgorbissa. Post-disaster assessment with unmanned aerial vehicles: A survey on practical implementations and research approaches.Journal of Field Robotics, 35(4):459–490, 2018
work page 2018
-
[19]
Yulun Tian, Yun Chang, Fernando Herrera Arias, Carlos Nieto-Granda, Jonathan P How, and Luca Carlone. Kimera-multi: Robust, distributed, dense metric-semantic slam for multi-robot systems.IEEE transactions on robotics, 38(4), 2022
work page 2022
-
[20]
Pierre-Yves Lajoie, Benjamin Ramtoula, Yun Chang, Luca Carlone, and Giovanni Beltrame. Door-slam: Distributed, online, and outlier resilient slam for robotic teams.IEEE Robotics and Automation Letters, 5(2):1656–1663, 2020
work page 2020
-
[21]
Patrik Schmuck and Margarita Chli. Ccm-slam: Robust and efficient centralized collaborative monocular simultaneous localization and mapping for robotic teams.Journal of Field Robotics, 36(4):763–781, 2019
work page 2019
-
[22]
Georgios Evangelidis and Branislav Micusik. Revisiting visual-inertial structure-from-motion for odometry and slam initialization.IEEE Robotics and Automation Letters, 6(2):1415–1422, 2021
work page 2021
-
[23]
Matterport3D: Learning from RGB-D Data in Indoor Environments
Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Halber, Matthias Niessner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. Matterport3d: Learning from rgb-d data in indoor environments.arXiv preprint arXiv:1709.06158, 2017
work page Pith review arXiv 2017
-
[24]
Structure-from-motion revisited
Johannes L Schonberger and Jan-Michael Frahm. Structure-from-motion revisited. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 4104–4113, 2016
work page 2016
-
[25]
Freenerf: Improving few-shot neural rendering with free frequency regularization
Jiawei Yang, Marco Pavone, and Yue Wang. Freenerf: Improving few-shot neural rendering with free frequency regularization. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8254–8263, 2023
work page 2023
-
[26]
Text2room: Extracting textured 3d meshes from 2d text-to-image models
Lukas Höllein, Ang Cao, Andrew Owens, Justin Johnson, and Matthias Nießner. Text2room: Extracting textured 3d meshes from 2d text-to-image models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 7909–7920, 2023
work page 2023
-
[27]
Mvdream: Multi-view diffusion for 3d gen- eration.arXiv preprint arXiv:2308.16512, 2023
Yichun Shi, Peng Wang, Jianglong Ye, Mai Long, Kejie Li, and Xiao Yang. Mvdream: Multi- view diffusion for 3d generation.arXiv preprint arXiv:2308.16512, 2023
-
[28]
Building rome in a day.Communications of the ACM, 54(10):105–112, 2011
Sameer Agarwal, Yasutaka Furukawa, Noah Snavely, Ian Simon, Brian Curless, Steven M Seitz, and Richard Szeliski. Building rome in a day.Communications of the ACM, 54(10):105–112, 2011. 11
work page 2011
-
[29]
Nerf in the wild: Neural radiance fields for unconstrained photo collections
Ricardo Martin-Brualla, Noha Radwan, Mehdi SM Sajjadi, Jonathan T Barron, Alexey Doso- vitskiy, and Daniel Duckworth. Nerf in the wild: Neural radiance fields for unconstrained photo collections. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7210–7219, 2021
work page 2021
-
[30]
Transplat: Generalizable 3d gaussian splatting from sparse multi-view images with transformers
Chuanrui Zhang, Yingshuang Zou, Zhuoling Li, Minmin Yi, and Haoqian Wang. Transplat: Generalizable 3d gaussian splatting from sparse multi-view images with transformers. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 9869–9877, 2025
work page 2025
-
[31]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
work page 2025
-
[32]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. In Proceedings of the IEEE/CVF international conference on computer vision, pages 4015–4026, 2023
work page 2023
-
[33]
Nerfiller: Completing scenes via generative 3d inpainting
Ethan Weber, Aleksander Holynski, Varun Jampani, Saurabh Saxena, Noah Snavely, Abhishek Kar, and Angjoo Kanazawa. Nerfiller: Completing scenes via generative 3d inpainting. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20731–20741, 2024
work page 2024
-
[34]
Scenetok: A compressed, diffusable token space for 3d scenes.arXiv preprint arXiv:2602.18882, 2026
Mohammad Asim, Christopher Wewer, and Jan Eric Lenssen. Scenetok: A compressed, diffusable token space for 3d scenes.arXiv preprint arXiv:2602.18882, 2026
-
[35]
Latent consistency models: Synthesizing high-resolution images with few-step inference, 2023
Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, and Hang Zhao. Latent consistency models: Synthesizing high-resolution images with few-step inference, 2023
work page 2023
-
[36]
Vickie Ye, Ruilong Li, Justin Kerr, Matias Turkulainen, Brent Yi, Zhuoyang Pan, Otto Seiskari, Jianbo Ye, Jeffrey Hu, Matthew Tancik, and Angjoo Kanazawa. gsplat: An open-source library for gaussian splatting.Journal of Machine Learning Research, 26(34):1–17, 2025
work page 2025
-
[37]
Barron, Ben Mildenhall, Dor Verbin, Pratul P
Jonathan T. Barron, Ben Mildenhall, Dor Verbin, Pratul P. Srinivasan, and Peter Hedman. Mip-nerf 360: Unbounded anti-aliased neural radiance fields.CVPR, 2022
work page 2022
-
[38]
Arno Knapitsch, Jaesik Park, Qian-Yi Zhou, and Vladlen Koltun. Tanks and temples: Bench- marking large-scale scene reconstruction.ACM Transactions on Graphics (ToG), 36(4):1–13, 2017
work page 2017
-
[39]
Peter Hedman, Julien Philip, True Price, Jan-Michael Frahm, George Drettakis, and Gabriel Brostow. Deep blending for free-viewpoint image-based rendering.ACM Transactions on Graphics (ToG), 37(6):1–15, 2018
work page 2018
-
[40]
Stereo magnifica- tion: Learning view synthesis using multiplane images.ACM Trans
Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. Stereo magnifica- tion: Learning view synthesis using multiplane images.ACM Trans. Graph. (Proc. SIGGRAPH), 37, 2018
work page 2018
-
[41]
Rethinking the Inception Architecture for Computer Vision
Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision.CoRR, abs/1512.00567, 2015
work page Pith review arXiv 2015
-
[42]
Clipscore: A reference-free evaluation metric for image captioning, 2022
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation metric for image captioning, 2022
work page 2022
-
[43]
GeCo: Evaluating Geometric Consistency for Video Generation via Motion and Structure
Leslie Gu, Junhwa Hur, Charles Herrmann, Fangneng Zhan, Todd Zickler, Deqing Sun, and Hanspeter Pfister. Geco: A differentiable geometric consistency metric for video generation. arXiv preprint arXiv:2512.22274, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Met3r: Measuring multi-view consistency in generated images
Mohammad Asim, Christopher Wewer, Thomas Wimmer, Bernt Schiele, and Jan Eric Lenssen. Met3r: Measuring multi-view consistency in generated images. InIEEE/CVF Computer Vision and Pattern Recognition (CVPR), 2025. 12
work page 2025
-
[45]
Gemini 3.1 pro: A smarter model for your most complex tasks, 2026
The Gemini Team. Gemini 3.1 pro: A smarter model for your most complex tasks, 2026. Accessed: 2026-05-06
work page 2026
-
[46]
Nano banana 2: Combining pro capabilities with lightning-fast speed, 2026
Naina Raisinghani. Nano banana 2: Combining pro capabilities with lightning-fast speed, 2026. Google DeepMind blog, accessed 2026-05-06
work page 2026
-
[47]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. Qwen2-vl: Enhancing vision- language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Fooocus: Focus on prompting and generating
Lvmin Zhang and Fooocus contributors. Fooocus: Focus on prompting and generating. https: //github.com/lllyasviel/Fooocus, 2024. Accessed: 2026-05-06
work page 2024
-
[49]
Aleksei Bochkovskii, Amaël Delaunoy, Hugo Germain, Marcel Santos, Yichao Zhou, Stephan R. Richter, and Vladlen Koltun. Depth pro: Sharp monocular metric depth in less than a second. InInternational Conference on Learning Representations, 2025
work page 2025
-
[50]
High-resolution image synthesis with latent diffusion models, 2021
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models, 2021
work page 2021
-
[51]
Real-esrgan: Training real-world blind super-resolution with pure synthetic data
Xintao Wang, Liangbin Xie, Chao Dong, and Ying Shan. Real-esrgan: Training real-world blind super-resolution with pure synthetic data. InInternational Conference on Computer Vision Workshops (ICCVW). 13 A Metrics GeCo (Geometric Consistency Metric)is a differentiable, geometry-grounded metric designed to detect geometric deformation and occlusion-inconsis...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.