Recognition: 2 theorem links
· Lean TheoremRevisiting Transformer Layer Parameterization Through Causal Energy Minimization
Pith reviewed 2026-05-11 02:14 UTC · model grok-4.3
The pith
Transformer attention and MLPs can be derived as gradient steps minimizing causal conditional energies, enabling stable weight-tied variants that match standard baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Causal Energy Minimization recasts each Transformer layer as an optimization step on a conditional energy function that respects causality. Under this view, weight-tied multi-head attention emerges as a gradient update on an interaction energy, while a gated MLP with tied projections corresponds to minimization of an element-wise energy. The same lens yields additional parameterizations such as diagonal-plus-low-rank forms and lightweight preconditioners, all of which remain trainable and functionally competitive with unconstrained attention and MLP blocks in moderate-scale language modeling.
What carries the argument
Causal Energy Minimization framework that treats layer forward passes as gradient steps minimizing conditional energies while enforcing parameterization constraints and causality.
If this is right
- Weight-tied multi-head attention can replace standard attention while preserving token-mixing function.
- Gated MLPs with shared projections deliver equivalent token-wise transformations using fewer parameters.
- The energy view naturally admits recursive updates and low-rank interaction terms as valid layer designs.
- Constrained layers obtained this way train stably and match baseline perplexity in language modeling at moderate scale.
Where Pith is reading between the lines
- Viewing layers as explicit energy steps may allow hybrid architectures that alternate minimization dynamics with other update rules.
- The same perspective could be applied to discover new layer families beyond attention and feed-forward blocks.
- Making the per-layer energy explicit might improve interpretability of how information is mixed or transformed across tokens.
Load-bearing premise
That energy-based recasting of attention and MLPs produces parameterizations that remain functionally equivalent to the originals and retain their training stability and expressivity at scale.
What would settle it
If CEM-derived layers with tied weights show substantially higher perplexity or training instability than matched-parameter standard Transformers on controlled language-modeling benchmarks at the 100M scale.
Figures




read the original abstract
Transformer blocks typically combine multi-head attention (MHA) for token mixing with gated MLPs for token-wise feature transformation, yet many choices in their parameterization remain largely empirical. We introduce Causal Energy Minimization (CEM), a framework that recasts Transformer layers as optimization steps on conditional energy functions while explicitly accounting for layer parameterization. Extending prior energy-based interpretations of attention, CEM shows that weight-tied MHA can be derived as a gradient update on an interaction energy, and that a gated MLP with shared up/down projections can be viewed through an element-wise energy. This perspective identifies a design space for Transformer layers that includes within-layer weight sharing, diagonal-plus-low-rank interactions, lightweight preconditioners, and recursive updates. We evaluate CEM-derived layers in language-modeling experiments at the moderate hundred-million-parameter scale. Despite their constrained parameterizations, these layers train stably and can match corresponding Transformer baselines. Overall, our results suggest that CEM provides a useful lens for understanding Transformer layer parameterization, connecting Transformer architectures to energy-based models and motivating further exploration of energy-guided layer designs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Causal Energy Minimization (CEM), a framework that recasts Transformer layers as optimization steps on conditional energy functions. It derives weight-tied multi-head attention as a gradient update on an interaction energy and a gated MLP with shared up/down projections via an element-wise energy. This yields a design space of constrained parameterizations (weight sharing, diagonal-plus-low-rank interactions, lightweight preconditioners, recursive updates) that the authors evaluate in language-modeling experiments at the ~100M-parameter scale, where the layers train stably and match standard Transformer baselines.
Significance. If the derivations are exact (rather than specially constructed reparameterizations) and the moderate-scale results are robust, the work provides a principled energy-based lens for understanding and designing Transformer layers, explicitly connecting them to energy-based models. The explicit accounting for parameterization choices and the demonstration of stable training under weight-tying and sharing constraints are strengths that could motivate more efficient architectures.
major comments (2)
- [§3] §3 (derivation of weight-tied MHA): The central claim that standard scaled dot-product attention arises precisely as a gradient step on a conditional interaction energy requires explicit clarification of the energy functional form, any auxiliary variables or log-partition approximations, and the exact step-size assumptions. If the construction is tailored to recover softmax(QK^T/sqrt(d))V, the derivation risks circularity and the resulting weight-tied variant may not be functionally equivalent to unconstrained MHA, undermining the subsequent design-space claims.
- [§5] §5 (language-modeling experiments): The statement that CEM-derived layers 'can match corresponding Transformer baselines' at the hundred-million-parameter scale is load-bearing for the empirical validation, yet the manuscript provides insufficient detail on baseline implementations, number of random seeds, error bars, hyperparameter search protocol, and data-exclusion rules. Without these, it is impossible to determine whether performance parity reflects genuine equivalence or post-hoc tuning within the constrained parameterization.
minor comments (2)
- [§2] Notation for the conditional energy functions and interaction terms should be introduced with explicit definitions and dimensions in the first appearance to improve readability for readers unfamiliar with energy-based interpretations of attention.
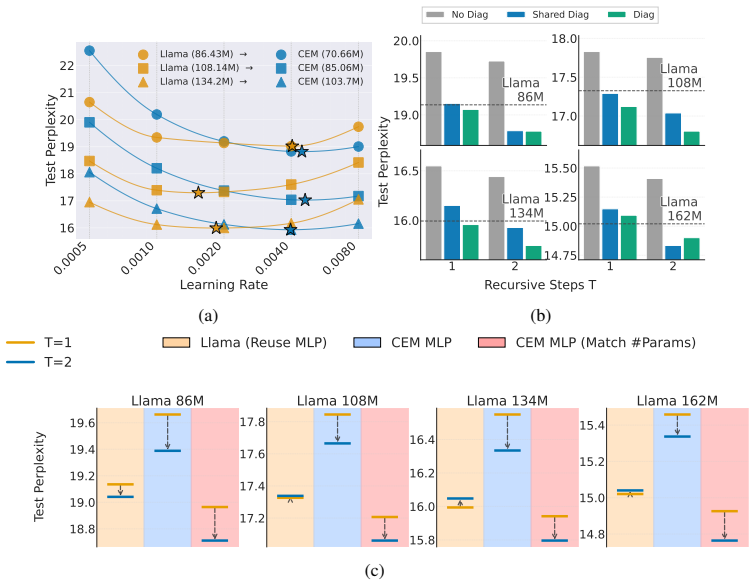
- [§5] Figure captions and axis labels in the experimental plots would benefit from stating the exact model sizes, training tokens, and evaluation metric (e.g., perplexity on which split) to allow direct comparison with prior work.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment below and will revise the paper to incorporate clarifications and additional details where needed.
read point-by-point responses
-
Referee: [§3] §3 (derivation of weight-tied MHA): The central claim that standard scaled dot-product attention arises precisely as a gradient step on a conditional interaction energy requires explicit clarification of the energy functional form, any auxiliary variables or log-partition approximations, and the exact step-size assumptions. If the construction is tailored to recover softmax(QK^T/sqrt(d))V, the derivation risks circularity and the resulting weight-tied variant may not be functionally equivalent to unconstrained MHA, undermining the subsequent design-space claims.
Authors: We appreciate the request for greater precision. The derivation starts from an explicitly defined conditional interaction energy E(Q,K,V) = −(QK^T / √d) V (with appropriate masking for causality), where the gradient with respect to V, taken with unit step size and softmax normalization arising from the log-sum-exp structure, recovers the standard scaled dot-product attention output. No auxiliary variables are used beyond the standard Q/K/V projections, and the construction extends prior energy-based interpretations of attention rather than being reverse-engineered to match it. We will revise §3 to state the energy functional form verbatim, list the step-size assumption (η = 1), and provide a compact derivation sketch. The weight-tied variant is a constrained parameterization by design; our subsequent experiments demonstrate that this constraint remains stable and competitive, which supports rather than undermines the broader design-space claims. revision: yes
-
Referee: [§5] §5 (language-modeling experiments): The statement that CEM-derived layers 'can match corresponding Transformer baselines' at the hundred-million-parameter scale is load-bearing for the empirical validation, yet the manuscript provides insufficient detail on baseline implementations, number of random seeds, error bars, hyperparameter search protocol, and data-exclusion rules. Without these, it is impossible to determine whether performance parity reflects genuine equivalence or post-hoc tuning within the constrained parameterization.
Authors: We agree that the current experimental description is insufficient for assessing robustness. In the revised manuscript we will expand §5 with: (i) exact baseline architecture and hyperparameter specifications matching the CEM variants, (ii) training curves and final metrics averaged over three independent random seeds together with standard deviations, (iii) the hyperparameter search ranges and selection procedure applied uniformly to both baselines and CEM models, and (iv) explicit data-preprocessing and validation-set exclusion rules. These additions will allow readers to evaluate whether the observed parity is reproducible and not the result of selective tuning. revision: yes
Circularity Check
No circularity identified; derivation presented as extension of prior energy-based views with independent experimental validation
full rationale
The paper introduces CEM as a framework that recasts layers as optimization steps on conditional energies, deriving weight-tied MHA and gated MLPs from gradient updates on interaction and element-wise energies. This is framed as extending existing energy-based interpretations of attention rather than redefining components to match inputs by construction. No self-citation load-bearing steps, fitted predictions, or ansatzes smuggled via prior author work are evident in the abstract or description. Experiments at 100M scale showing stable training and baseline-matching performance provide external falsifiability outside any fitted parameterization. The derivation chain appears self-contained against the stated assumptions, with no quoted reduction of outputs to inputs by definition.
Axiom & Free-Parameter Ledger
free parameters (1)
- interaction energy scales
axioms (1)
- domain assumption Transformer layers can be recast as optimization steps on conditional energy functions
invented entities (1)
-
Causal Energy Minimization framework
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearweight-tied MHA can be derived as a gradient update on an interaction energy... gated MLP with shared up/down projections can be viewed through an element-wise energy
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearCausal Energy Minimization (CEM), a framework that recasts Transformer layers as optimization steps on conditional energy functions
Reference graph
Works this paper leans on
-
[1]
Gqa: Training generalized multi-query transformer models from multi-head checkpoints
Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebron, and Sumit Sanghai. Gqa: Training generalized multi-query transformer models from multi-head checkpoints. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 4895–4901,
work page 2023
-
[2]
Relaxed recursive transformers: Effective parameter sharing with layer-wise LoRA
Sangmin Bae, Adam Fisch, Hrayr Harutyunyan, Ziwei Ji, Seungyeon Kim, and Tal Schuster. Relaxed recursive transformers: Effective parameter sharing with layer-wise lora.ArXiv, abs/2410.20672,
-
[3]
On the Opportunities and Risks of Foundation Models
Rishi Bommasani, Drew A. Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S. Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, Erik Brynjolfsson, S. Buch, Dallas Card, Rodrigo Castellon, Niladri S. Chatterji, Annie S. Chen, Kathleen A. Creel, Jared Davis, Dora Demszky, Chris Donahue, Moussa Koulako Bala Doumbouya, Esin Du...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
URL https://doi.org/10.1137/23M1587610
doi: 10.1137/23M1587610. URL https://doi.org/10.1137/23M1587610. Kyunghyun Cho, Bart Van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using rnn encoder–decoder for statistical machine translation. InConference on Empirical Methods in Natural Language Processing,
-
[5]
NRGPT: An Energy-based Alternative for GPT
URL https: //openreview.net/forum?id=HyzdRiR9Y7. Nima Dehmamy, Benjamin Hoover, Bishwajit Saha, Leo Kozachkov, Jean-Jacques Slotine, and Dmitry Krotov. Nrgpt: An energy-based alternative for gpt.arXiv preprint arXiv:2512.16762,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Improved Contrastive Divergence Training of Energy Based Models.arXiv:2012.01316 [cs], June 2021
Yilun Du, Shuang Li, Joshua Tenenbaum, and Igor Mordatch. Improved contrastive divergence training of energy based models.arXiv preprint arXiv:2012.01316,
-
[7]
Energy-based trans- formers are scalable learners and thinkers.arXiv preprint arXiv:2507.02092, 2025
Alexi Gladstone, Ganesh Nanduru, Md Mofijul Islam, Peixuan Han, Hyeonjeong Ha, Aman Chadha, Yilun Du, Heng Ji, Jundong Li, and Tariq Iqbal. Energy-based transformers are scalable learners and thinkers.arXiv preprint arXiv:2507.02092,
-
[8]
Training Large Language Models to Reason in a Continuous Latent Space
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. Training large language models to reason in a continuous latent space.arXiv preprint arXiv:2412.06769,
work page internal anchor Pith review arXiv
-
[9]
LoRA: Low-Rank Adaptation of Large Language Models
J. Edward Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models.ArXiv, abs/2106.09685,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Neural machine translation in linear time.arXiv:1610.10099,
Nal Kalchbrenner, Lasse Espeholt, Karen Simonyan, Aaron van den Oord, Alex Graves, and Koray Kavukcuoglu. Neural machine translation in linear time.arXiv preprint arXiv:1610.10099,
-
[11]
Kimi Linear: An Expressive, Efficient Attention Architecture
Yu Kimi Team, Zhang, Zongyu Lin, Xingcheng Yao, Jiaxi Hu, Fanqing Meng, Chengyin Liu, Xin Men, Songlin Yang, Zhiyuan Li, et al. Kimi linear: An expressive, efficient attention architecture. arXiv preprint arXiv:2510.26692,
work page internal anchor Pith review arXiv
-
[12]
URLhttps://arxiv.org/abs/2501.19393. Ofir Press, Noah A. Smith, and Mike Lewis. Train short, test long: Attention with linear biases enables input length extrapolation. InInternational Conference on Learning Representations (ICLR),
-
[13]
Aditya Ravuri and Neil D Lawrence. Transformers as unrolled inference in probabilistic laplacian eigenmaps: An interpretation and potential improvements.arXiv preprint arXiv:2507.21040,
-
[14]
Fast Transformer Decoding: One Write-Head is All You Need
Noam Shazeer. Fast transformer decoding: One write-head is all you need. InarXiv preprint arXiv:1911.02150,
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[15]
GLU Variants Improve Transformer
Noam Shazeer. Glu variants improve transformer.arXiv preprint arXiv:2002.05202,
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[17]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
URLhttps://arxiv.org/abs/2408.03314. Preprint; ICLR 2025 version on OpenReview. David R. So, Wojciech Ma’nke, Hanxiao Liu, Zihang Dai, Noam Shazeer, and Quoc V . Le. Primer: Searching for efficient transformers for language modeling.ArXiv, abs/2109.08668,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Think silently, think fast: Dynamic latent compression of llm reasoning chains
Wenhui Tan, Jiaze Li, Jianzhong Ju, Zhenbo Luo, Jian Luan, and Ruihua Song. Think silently, think fast: Dynamic latent compression of llm reasoning chains.ArXiv, abs/2505.16552,
-
[19]
Probabilistic transformer: A probabilistic dependency model for contextual word representation
Haoyi Wu and Kewei Tu. Probabilistic transformer: A probabilistic dependency model for contextual word representation. InFindings of the Association for Computational Linguistics: ACL 2023, pages 7613–7636,
work page 2023
-
[20]
Looped transformers are better at learning learning algorithms.arXiv preprint arXiv:2311.12424,
Liu Yang, Kangwook Lee, Robert Nowak, and Dimitris Papailiopoulos. Looped transformers are better at learning learning algorithms.ArXiv, abs/2311.12424,
-
[22]
URLhttps://arxiv.org/abs/2409.14026. 13 A Background A.1 Equivalence between concatenation and summation in attention In Section 2.1, we write the multi-head attention update in the form MHA(h1:i) = KX k=1 W O⊤ k iX j=1 softmaxj 1√Dh (kk j′)⊤qk i i j′=1 vk j ! , where each head k contributes an output vector that is multiplied by a head-specific block W O...
-
[23]
Element-wise energy.The element-wise energy leading to gated MLPs has a less direct connection
introduce novel Hopfield layers and evaluate them on associative-memory benchmarks, our framework treats standard Transformer layers themselves as energy-based updates, and we demonstrate that this perspective leads to principled extensions and improvements for text modeling tasks. Element-wise energy.The element-wise energy leading to gated MLPs has a le...
work page 2023
-
[24]
Table 2: Training hyperparameters for CEM models and Llama baselines
We follow Chinchilla-optimal compute allocation [Hoffmann et al., 2022] for determining the number of training tokens for each model size. Table 2: Training hyperparameters for CEM models and Llama baselines. Hyperparameter CEM models Llama baseline Optimizer AdamW Learning rate 0.002 β1 0.9 β2 0.95 ϵ1e-9 Weight decay 0.1 Gradient clipping 1.0 LR schedule...
work page 2022
-
[25]
The code is not yet publicly available but will be released upon publication
All experiments use the SlimPajama dataset (Section D.2) and were conducted on 8× NVIDIA A100 GPUs. The code is not yet publicly available but will be released upon publication. 18 Table 3: Model size, compute, and RMSE (mean ± std) on synthetic data sampled from Gaussian processes with 10 input dimensions. Here the latent state dimension is set equal to ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.