Recognition: no theorem link
LithoBench: Benchmarking Large Multimodal Models for Remote-Sensing Lithology Interpretation
Pith reviewed 2026-05-11 01:57 UTC · model grok-4.3
The pith
Large multimodal models show clear weaknesses in interpreting rock types from remote sensing data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
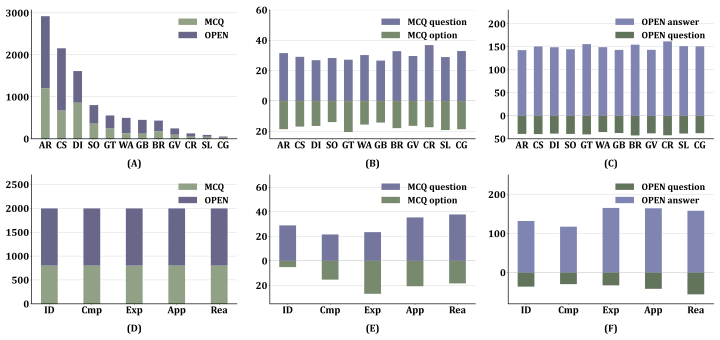
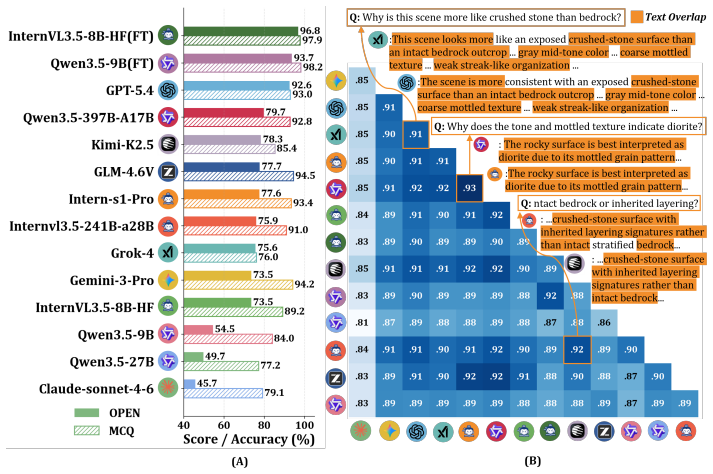
LithoBench is a benchmark with 10,000 expert-annotated instances in 12 lithological categories, structured into 4,000 multiple-choice and 6,000 open-ended tasks across five levels: Identification and Description, Comparative Analysis, Mechanism Explanation, Practical Application, and Comprehensive Reasoning. Evaluations of multiple large vision-language models indicate substantial limitations in geological semantic understanding, with particularly poor performance on higher-order tasks.
What carries the argument
LithoBench, the multi-level benchmark dataset and evaluation pipeline that organizes tasks by increasing cognitive demands to assess geological knowledge in AI models.
If this is right
- Reliable automated support for geological surveys and mineral exploration would require models to handle higher-order explanation and reasoning.
- Development of future large multimodal models should focus on embedding domain-specific geological knowledge.
- The expert-in-the-loop pipeline used to build the benchmark offers a method to create more reliable evaluations in other knowledge-intensive fields.
Where Pith is reading between the lines
- The structure of five cognitive levels could serve as a model for designing tests in other specialized image-interpretation domains such as medical or ecological analysis.
- Models that improve on LithoBench might enable practical tools that assist field geologists with initial interpretations from imagery.
- Gaps shown here suggest that general-purpose multimodal training alone is insufficient for tasks requiring precise scientific inference.
Load-bearing premise
The expert-annotated tasks at the five cognitive levels accurately reflect the knowledge and reasoning required for actual remote-sensing lithology interpretation in the field.
What would settle it
An experiment where a large vision-language model achieves high scores on the higher cognitive levels of LithoBench and then demonstrates accurate lithology interpretation on a new set of unlabeled remote sensing images validated by independent experts.
Figures


















read the original abstract
Remote sensing lithology interpretation is fundamental to geological surveys, mineral exploration, and regional geological mapping. Unlike general land-cover recognition, lithology interpretation is a knowledge-intensive task that requires experts to infer rock types from various features, e.g., subtle visual, spectral, textural, geomorphological, and contextual cues, making reliable automated interpretation highly challenging. Geological knowledge-guided large multimodal models offer new opportunities, yet their evaluation remains constrained by the lack of benchmarks that capture lithological annotations, multi-level geological semantics, and expert-informed assessment. Here, we propose LithoBench, a multi-level benchmark for evaluating geological semantic understanding in remote sensing lithology interpretation. LithoBench contains 10,000 expert-annotated interpretation instances across 12 representative lithological categories, including 4,000 multiple-choice and 6,000 open-ended tasks organized into five cognitive levels: Identification and Description, Comparative Analysis, Mechanism Explanation, Practical Application, and Comprehensive Reasoning. We further develop an expert-in-the-loop, knowledge-grounded semi-automated construction pipeline, coupling multi sub-processes, e.g., structured geological image descriptions, to enhance geological validity and evaluation reliability. Experiments with multiple large vision-language models eveal substantial limitations in geological semantic understanding, particularly on higher-order explanation, application, and reasoning tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LithoBench, a benchmark of 10,000 expert-annotated remote-sensing instances across 12 lithological categories. It comprises 4,000 multiple-choice and 6,000 open-ended tasks organized into five cognitive levels (Identification and Description, Comparative Analysis, Mechanism Explanation, Practical Application, Comprehensive Reasoning). An expert-in-the-loop, knowledge-grounded semi-automated pipeline is described for construction, and experiments on multiple large vision-language models are reported to reveal substantial limitations in geological semantic understanding, especially on higher-order explanation, application, and reasoning tasks.
Significance. If the ground-truth annotations are shown to be reliable, this benchmark would fill an important gap by providing the first multi-level, domain-specific evaluation resource for multimodal models on knowledge-intensive geological remote-sensing tasks. The empirical findings could usefully guide development of models better suited to applications such as mineral exploration and regional mapping, where subtle visual, spectral, and contextual cues must be integrated with expert geological knowledge.
major comments (2)
- [construction pipeline description] The description of the expert-in-the-loop, knowledge-grounded semi-automated construction pipeline (Abstract and associated methods section) provides no quantitative validation: no inter-annotator agreement scores, no fraction of the 10,000 instances that received full expert review, and no error analysis on geological semantics. This is load-bearing for the central claim, because the reported model deficiencies on the 6,000 open-ended tasks at cognitive levels 3–5 rest on the assumption that these annotations constitute reliable ground truth; without such metrics, annotation noise could inflate apparent limitations.
- [dataset construction] No justification or external reference is given for the choice of the 12 lithological categories or the precise definitions of the five cognitive levels (Abstract and dataset section). Because the strongest claim is that model performance on this benchmark reveals general limitations in geological semantic understanding, the lack of grounding in established geological standards or expert consensus undermines the generalization argument beyond the specific 10k instances.
minor comments (3)
- [Abstract] Abstract contains a typo: 'eveal' should read 'reveal'.
- [Introduction] The manuscript would benefit from explicit comparison to prior remote-sensing and geological-image benchmarks to clarify the incremental contribution of the five-level cognitive taxonomy.
- [Experiments] Performance tables should report statistical significance or confidence intervals when claiming 'substantial limitations' across models.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments, which highlight important aspects of benchmark reliability and grounding. We address each major comment below and will revise the manuscript to strengthen these elements.
read point-by-point responses
-
Referee: The description of the expert-in-the-loop, knowledge-grounded semi-automated construction pipeline (Abstract and associated methods section) provides no quantitative validation: no inter-annotator agreement scores, no fraction of the 10,000 instances that received full expert review, and no error analysis on geological semantics. This is load-bearing for the central claim, because the reported model deficiencies on the 6,000 open-ended tasks at cognitive levels 3–5 rest on the assumption that these annotations constitute reliable ground truth; without such metrics, annotation noise could inflate apparent limitations.
Authors: We agree that quantitative validation metrics are necessary to substantiate the reliability of the ground-truth annotations. The current manuscript describes the expert-in-the-loop process at a high level but does not report inter-annotator agreement, the exact fraction of instances receiving full expert review, or a dedicated error analysis. In the revised version, we will add these details to the Methods section: inter-annotator agreement scores (Cohen's kappa) on a randomly sampled subset of 500 instances reviewed by two independent geologists; the proportion of the 10,000 instances that underwent full expert review (beyond automated filtering); and a qualitative error analysis of semantic inconsistencies in geological descriptions. This will directly address concerns about annotation noise affecting the evaluation of higher-order cognitive tasks. revision: yes
-
Referee: No justification or external reference is given for the choice of the 12 lithological categories or the precise definitions of the five cognitive levels (Abstract and dataset section). Because the strongest claim is that model performance on this benchmark reveals general limitations in geological semantic understanding, the lack of grounding in established geological standards or expert consensus undermines the generalization argument beyond the specific 10k instances.
Authors: We acknowledge that explicit justification and external references would better support the generalization of our findings. The 12 categories were chosen to represent the most common lithologies encountered in remote-sensing surveys (e.g., granite, basalt, limestone, sandstone, and metamorphic equivalents), drawing from standard geological classifications. The five cognitive levels adapt established frameworks from educational psychology (Bloom's taxonomy) to geological interpretation. In the revision, we will expand the Dataset section with citations to USGS and IUGS lithological standards, prior remote-sensing geology literature, and domain-specific cognitive taxonomies used in other scientific benchmarks. This will clarify the rationale and strengthen the claim that the observed limitations reflect broader challenges in geological semantic understanding. revision: yes
Circularity Check
No circularity: benchmark construction and direct empirical evaluation
full rationale
The paper creates LithoBench (10,000 expert-annotated instances across five cognitive levels) and reports model performance on it. No equations, fitted parameters, or predictions are defined; the central results are measured accuracies on held-out tasks. The semi-automated annotation pipeline is a construction method, not a derivation that reduces outputs to inputs by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatzes appear in the provided text. The work is self-contained empirical benchmarking.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert annotations and the five-level cognitive taxonomy accurately reflect the knowledge required for reliable remote-sensing lithology interpretation.
Reference graph
Works this paper leans on
-
[1]
Addison Wesley Longman, Inc., 2001
Lorin W Anderson and David R Krathwohl.A taxonomy for learning, teaching, and assessing: A revision of Bloom’s taxonomy of educational objectives: complete edition. Addison Wesley Longman, Inc., 2001
work page 2001
-
[2]
Anthropic. Claude Sonnet 4.6 System Card. https://www.anthropic.com/ claude-sonnet-4-6-system-card, 2026. Accessed: 2026-04-23
work page 2026
-
[3]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Xiaodao Chen, Yupeng Liu, Wei Han, Xiongwei Zheng, Sheng Wang, Jun Wang, and Lizhe Wang. A vision-language foundation model-based multi-modal retrieval-augmented generation framework for remote sensing lithological recognition.ISPRS Journal of Photogrammetry and Remote Sensing, pages 328–340, 2025
work page 2025
-
[6]
Yansi Chen, Yunchen Wang, Feng Zhang, Yulong Dong, Zhihong Song, and Genyuan Liu. Remote sensing for lithology mapping in vegetation-covered regions: Methods, challenges, and opportunities.Minerals, (9):1153, 2023
work page 2023
-
[7]
Leandro Estefano Christovam, GG Pessoa, MH Shimabukuro, and MLBT Galo. Land use and land cover classification using hyperspectral imagery: Evaluating the performance of spectral angle mapper, support vector machine and random forest.The international archives of the photogrammetry, remote sensing and spatial information sciences, pages 1841–1847, 2019
work page 2019
-
[8]
Instructblip: Towards general-purpose vision-language models with instruction tuning
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale N Fung, and Steven Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning. InNeurIPS, pages 49250–49267, 2023
work page 2023
-
[9]
Ronghao Fu, Haoran Liu, Weijie Zhang, Zhiwen Lin, Xiao Yang, Peng Zhang, and Bo Yang. Omniearth: A benchmark for evaluating vision-language models in geospatial tasks.arXiv preprint arXiv:2603.09471, 2026
-
[10]
Sobhi M Ghoneim, Zakaria Hamimi, Kamal Abdelrahman, Mohamed A Khalifa, Mohamed Shabban, and Ashraf S Abdelmaksoud. Machine learning and remote sensing-based lithological mapping of the duwi shear-belt area, central eastern desert, egypt.Scientific Reports, (1):17010, 2024
work page 2024
-
[11]
Google DeepMind. Gemini 3 pro model card. https://storage.googleapis.com/ deepmind-media/Model-Cards/Gemini-3-Pro-Model-Card.pdf , 2025. Accessed: 2026-04-23
work page 2025
-
[12]
Soufiane Hajaj, Abderrazak El Harti, Amin Beiranvand Pour, Amine Jellouli, Zakaria Adiri, and Mazlan Hashim. A review on hyperspectral imagery application for lithological mapping and mineral prospecting: Machine learning techniques and future prospects.Remote Sensing Applications: Society and Environment, page 101218, 2024. 10
work page 2024
-
[13]
Wei Han, Lizhe Wang, Yuewei Wang, Jun Li, Jining Yan, and Yinghui Shao. A novel framework for leveraging geological environment big data to assess sustainable development goals.The Innovation Geoscience, page 100122, 2025
work page 2025
-
[14]
Wei Han, Xiaohan Zhang, Yi Wang, Lizhe Wang, Xiaohui Huang, Jun Li, Sheng Wang, Weitao Chen, Xianju Li, Ruyi Feng, et al. A survey of machine learning and deep learning in remote sensing of geological environment: Challenges, advances, and opportunities.ISPRS Journal of Photogrammetry and Remote Sensing, pages 87–113, 2023
work page 2023
-
[15]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. InICLR, page 3, 2022
work page 2022
-
[16]
Yuan Hu, Jianlong Yuan, Congcong Wen, Xiaonan Lu, Yu Liu, and Xiang Li. Rsgpt: A remote sensing vision language model and benchmark.ISPRS Journal of Photogrammetry and Remote Sensing, pages 272–286, 2025
work page 2025
-
[17]
Yusong Hu, Runmin Ma, Yue Fan, Jinxin Shi, Zongsheng Cao, Yuhao Zhou, Jiakang Yuan, Shuaiyu Zhang, Shiyang Feng, Xiangchao Yan, et al. Flowsearch: Advancing deep research with dynamic structured knowledge flow.arXiv preprint arXiv:2510.08521, 2025
-
[18]
Hyrank hyperspectral satellite dataset i (version v001).Zenodo, Apr, 2018
K Karantzalos, Christina Karakizi, Zacharias Kandylakis, and Georgia Antoniou. Hyrank hyperspectral satellite dataset i (version v001).Zenodo, Apr, 2018
work page 2018
-
[19]
Prometheus: Inducing fine-grained evaluation capability in language models
Seungone Kim, Jamin Shin, Yejin Cho, Joel Jang, Shayne Longpre, Hwaran Lee, Sangdoo Yun, Seongjin Shin, Sungdong Kim, James Thorne, et al. Prometheus: Inducing fine-grained evaluation capability in language models. InICLR, 2023
work page 2023
-
[20]
Geochat: Grounded large vision-language model for remote sensing
Kartik Kuckreja, Muhammad Shahzad Danish, Muzammal Naseer, Abhijit Das, Salman Khan, and Fahad Shahbaz Khan. Geochat: Grounded large vision-language model for remote sensing. InCVPR, pages 27831–27840, 2024
work page 2024
-
[21]
Geo-bench: Toward foundation models for earth monitoring
Alexandre Lacoste, Nils Lehmann, Pau Rodriguez, Evan Sherwin, Hannah Kerner, Björn Lütjens, Jeremy Irvin, David Dao, Hamed Alemohammad, Alexandre Drouin, et al. Geo-bench: Toward foundation models for earth monitoring. InNeurIPS, pages 51080–51093, 2023
work page 2023
-
[22]
Retrieval-augmented generation for knowledge-intensive nlp tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. In33, pages 9459–9474, 2020
work page 2020
-
[23]
Seed-bench: Benchmarking multimodal large language models
Bohao Li, Yuying Ge, Yixiao Ge, Guangzhi Wang, Rui Wang, Ruimao Zhang, and Ying Shan. Seed-bench: Benchmarking multimodal large language models. InCVPR, pages 13299–13308, 2024
work page 2024
-
[24]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language- image pre-training with frozen image encoders and large language models. InICML, pages 19730–19742, 2023
work page 2023
-
[25]
Vrsbench: A versatile vision-language bench- mark dataset for remote sensing image understanding
Xiang Li, Jian Ding, and Mohamed Elhoseiny. Vrsbench: A versatile vision-language bench- mark dataset for remote sensing image understanding. InNeurIPS, pages 3229–3242, 2024
work page 2024
-
[26]
Rouge: A package for automatic evaluation of summaries
Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. InText summarization branches out, pages 74–81, 2004
work page 2004
-
[27]
Nan Lin, Jiawei Fu, Ranzhe Jiang, Genjun Li, and Qian Yang. Lithological classification by hyperspectral images based on a two-layer xgboost model, combined with a greedy algorithm. Remote Sensing, (15):3764, 2023
work page 2023
-
[28]
Visual instruction tuning.NeurIPS
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.NeurIPS
-
[29]
Huize Liu, Ke Wu, Honggen Xu, and Ying Xu. Lithology classification using tasi thermal infrared hyperspectral data with convolutional neural networks.Remote Sensing, (16):3117, 2021. 11
work page 2021
-
[30]
G-eval: Nlg evaluation using gpt-4 with better human alignment
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-eval: Nlg evaluation using gpt-4 with better human alignment. InEMNLP, pages 2511–2522, 2023
work page 2023
-
[31]
Mmbench: Is your multi-modal model an all-around player? InECCV, pages 216–233, 2024
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? InECCV, pages 216–233, 2024
work page 2024
-
[32]
Valerio Marsocci, Yuru Jia, Georges Le Bellier, David Kerekes, Liang Zeng, Sebastian Hafner, Sebastian Gerard, Eric Brune, Ritu Yadav, Ali Shibli, et al. Pangaea: A global and inclusive benchmark for geospatial foundation models.arXiv preprint arXiv:2412.04204, 2024
- [33]
-
[34]
OpenAI. Introducing gpt-5.4. https://openai.com/index/introducing-gpt-5-4/ ,
-
[36]
Bleu: a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318, 2002
work page 2002
-
[37]
Sima Peyghambari and Yun Zhang. Hyperspectral remote sensing in lithological mapping, mineral exploration, and environmental geology: an updated review.Journal of Applied Remote Sensing, (3):031501–031501, 2021
work page 2021
-
[38]
PICABench: How far are we from physically realistic image editing?, 2025
Yuandong Pu, Le Zhuo, Songhao Han, Jinbo Xing, Kaiwen Zhu, Shuo Cao, Bin Fu, Si Liu, Hongsheng Li, Yu Qiao, et al. Picabench: How far are we from physically realistic image editing?arXiv preprint arXiv:2510.17681, 2025
-
[39]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
work page 2021
-
[40]
Ali Shebl, Dávid Abriha, Amr S Fahil, Hanna A El-Dokouny, Abdelmajeed A Elrasheed, and Árpád Csámer. Prisma hyperspectral data for lithological mapping in the egyptian eastern desert: Evaluating the support vector machine, random forest, and xg boost machine learning algorithms.Ore Geology Reviews, page 105652, 2023
work page 2023
-
[41]
Xian Sun, Peijin Wang, Zhiyuan Yan, Feng Xu, Ruiping Wang, Wenhui Diao, Jin Chen, Jihao Li, Yingchao Feng, Tao Xu, et al. Fair1m: A benchmark dataset for fine-grained object recognition in high-resolution remote sensing imagery.ISPRS Journal of Photogrammetry and Remote Sensing, pages 116–130, 2022
work page 2022
-
[42]
Samrs: Scaling-up remote sensing segmentation dataset with segment anything model
Di Wang, Jing Zhang, Bo Du, Minqiang Xu, Lin Liu, Dacheng Tao, and Liangpei Zhang. Samrs: Scaling-up remote sensing segmentation dataset with segment anything model. InNeurIPS, pages 8815–8827, 2023
work page 2023
-
[43]
Junjue Wang, Zhuo Zheng, Zihang Chen, Ailong Ma, and Yanfei Zhong. Earthvqa: Towards queryable earth via relational reasoning-based remote sensing visual question answering. In AAAI, number 6, pages 5481–5489, 2024
work page 2024
-
[44]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
W. Wang et al. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
xAI. Grok 4 Model Card. https://data.x.ai/2025-08-20-grok-4-model-card.pdf ,
work page 2025
-
[46]
Accessed: 2026-04-23
work page 2026
-
[47]
Openearthmap: A benchmark dataset for global high-resolution land cover mapping
Junshi Xia, Naoto Yokoya, Bruno Adriano, and Clifford Broni-Bediako. Openearthmap: A benchmark dataset for global high-resolution land cover mapping. InWACV, pages 6254–6264, 2023. 12
work page 2023
-
[48]
C- pack: Packed resources for general chinese embeddings
Shitao Xiao, Zheng Liu, Peitian Zhang, Niklas Muennighoff, Defu Lian, and Jian-Yun Nie. C- pack: Packed resources for general chinese embeddings. InProceedings of the 47th international ACM SIGIR conference on research and development in information retrieval, pages 641–649, 2024
work page 2024
-
[49]
Assessment of worldview-3 data for lithological mapping.Remote Sensing, (11):1132, 2017
Bei Ye, Shufang Tian, Jia Ge, and Yaqin Sun. Assessment of worldview-3 data for lithological mapping.Remote Sensing, (11):1132, 2017
work page 2017
-
[50]
MM-Vet: Evaluating Large Multimodal Models for Integrated Capabilities
Weihao Yu, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng Liu, Xinchao Wang, and Lijuan Wang. Mm-vet: Evaluating large multimodal models for integrated capabilities. arXiv preprint arXiv:2308.02490, 2023
work page internal anchor Pith review arXiv 2023
-
[51]
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. InCVPR, pages 9556–9567, 2024
work page 2024
- [52]
-
[53]
Yang Zhan, Zhitong Xiong, and Yuan Yuan. Skyeyegpt: Unifying remote sensing vision- language tasks via instruction tuning with large language model.ISPRS Journal of Photogram- metry and Remote Sensing, pages 64–77, 2025
work page 2025
-
[54]
Wei Zhang, Miaoxin Cai, Tong Zhang, Yin Zhuang, and Xuerui Mao. Earthgpt: A universal multimodal large language model for multisensor image comprehension in remote sensing domain.IEEE Transactions on Geoscience and Remote Sensing, pages 1–20, 2024
work page 2024
-
[55]
Large multimodal models evaluation: a survey
Zicheng Zhang, Junying Wang, Farong Wen, Yijin Guo, Xiangyu Zhao, Xinyu Fang, Shengyuan Ding, Ziheng Jia, Jiahao Xiao, Ye Shen, et al. Large multimodal models evaluation: a survey. Science China Information Sciences, (12):221301, 2025
work page 2025
-
[56]
Xiangyu Zhao, Wanghan Xu, Bo Liu, Yuhao Zhou, Fenghua Ling, Ben Fei, Xiaoyu Yue, Lei Bai, Wenlong Zhang, and Xiao-Ming Wu. Msearth: A benchmark for multimodal scientific comprehension of earth science.arXiv e-prints, pages arXiv–2505, 2025
work page 2025
-
[57]
Judging llm-as-a-judge with mt-bench and chatbot arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena. InNeurIPS, pages 46595–46623, 2023
work page 2023
-
[58]
Rsvlm- qa: A benchmark dataset for remote sensing vision language model-based question answering
Xing Zi, Jinghao Xiao, Yunxiao Shi, Xian Tao, Jun Li, Ali Braytee, and Mukesh Prasad. Rsvlm- qa: A benchmark dataset for remote sensing vision language model-based question answering. InACM MM, pages 12905–12911, 2025
work page 2025
-
[59]
Intern-s1-pro: Scientific multimodal foundation model at trillion scale, 2026
Yicheng Zou, Dongsheng Zhu, Lin Zhu, Tong Zhu, Yunhua Zhou, Peiheng Zhou, Xinyu Zhou, Dongzhan Zhou, Zhiwang Zhou, Yuhao Zhou, et al. Intern-s1-pro: Scientific multimodal foundation model at trillion scale.arXiv preprint arXiv:2603.25040, 2026. 13 NeurIPS Paper Checklist 1.Claims Question: Do the main claims made in the abstract and introduction accuratel...
-
[60]
You are STRICTLY FORBIDDEN from using <think> tags
DO NOT output any internal thinking processes, planning, or reasoning. You are STRICTLY FORBIDDEN from using <think> tags
-
[61]
DO NOT output any conversational text, greetings, or explanations before or after the JSON
-
[62]
Output ONLY a valid, parsable JSON object matching the exact structure below. Required JSON Structure: { "Tone_Color": { "Brightness": {"value": "Dark/Medium/Bright", "evidence": "..."}, "Hue_Bias": {"value": "Gray/Yellow−brown/Red−brown/Blue−gray", "evidence": "..."}, "Contrast": {"value": "...", "evidence": "..."} }, "Texture": { "Granularity": {"value"...
-
[63]
The generated question must be about the target image only
-
[64]
Any internally provided reference images may be used only as hidden support for distractor design, comparative reasoning, or quality control
-
[65]
The final question, answer, and explanation must be written exactly as a single−image benchmark item
-
[66]
The final wording must read naturally as if the user is seeing only one standalone target image
-
[67]
Never mention image layout, image positions, panel structure, or multi−image composition in any form
- [68]
-
[69]
Do not say or imply that multiple images were provided
-
[70]
Do not explicitly mention any hidden support images even when using them internally
-
[71]
You may draw inspiration from any of the provided question prototypes, or combine ideas from multiple prototypes
-
[72]
Do not copy any prototype verbatim
-
[73]
Keep the question professional and geologically meaningful
-
[74]
Keep the answer consistent with the target image evidence and any internally used support information, while referring only to the target image in the final wording
-
[75]
Output strictly valid JSON only. No markdown. No extra text. Generate exactly 1 English single−choice multiple−choice question. Requirements:
-
[76]
Provide exactly 4 options labeled A/B/C/D
-
[77]
There must be exactly 1 correct answer
-
[78]
The question should be {mcq_focus} rather than a purely superficial lookup
-
[79]
Distractors must be plausible, domain−relevant, and challenging
-
[80]
Use retrieved professional knowledge when available to improve correctness and professionalism, but do not copy it mechanically
-
[81]
Do not leak the correct answer in the question stem. Output JSON: { "question": "...", "options": [ {"key": "A", "text": "..."}, {"key": "B", "text": "..."}, {"key": "C", "text": "..."}, {"key": "D", "text": "..."} ], "answer_key": "A", "answer_text": "...", "explanation": "..." } Figure 11: Prompt template for generating multiple-choice questions across ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.