Recognition: 2 theorem links
· Lean TheoremNot All Tokens Learn Alike: Attention Entropy Reveals Heterogeneous Signals in RL Reasoning
Pith reviewed 2026-05-11 02:26 UTC · model grok-4.3
The pith
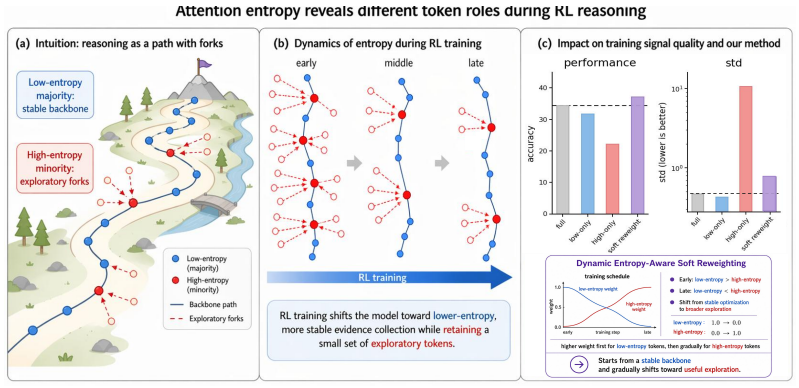
Attention entropy distinguishes stable anchor tokens from volatile explorer tokens during RL reasoning post-training
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
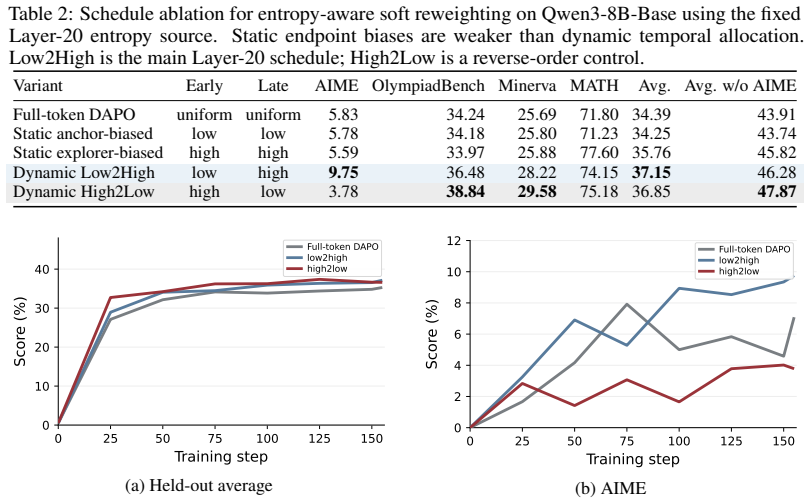
Token-level RL objectives are sparsely estimable with random subsets, but entropy-structured analysis reveals that low-attention-entropy anchor tokens produce stable gradients aligned with full-token updates while high-attention-entropy explorer tokens induce larger yet more volatile gradients; dynamic entropy-aware soft-reweighting then improves held-out average performance from 34.39 to 37.40.
What carries the argument
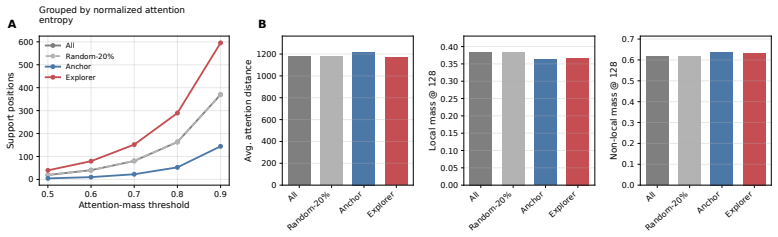
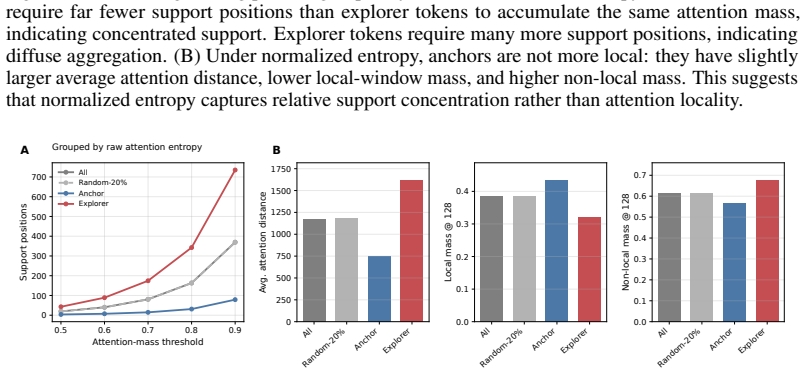
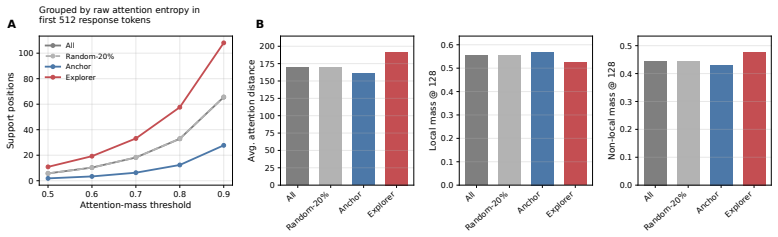
Attention entropy, which measures the concentration or diffuseness of contextual support for each response token
If this is right
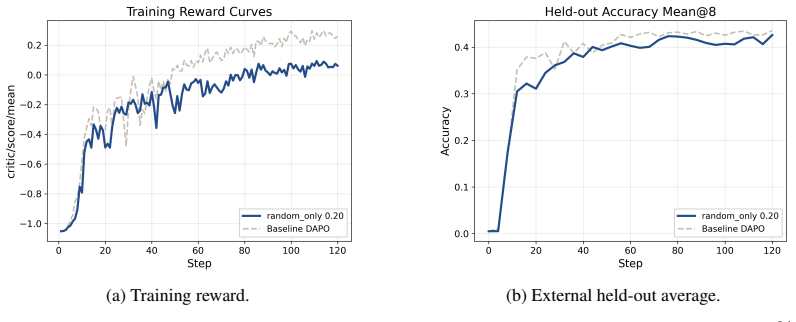
- Uniform random 20 percent token subsets preserve much of full-token held-out performance due to substantial redundancy.
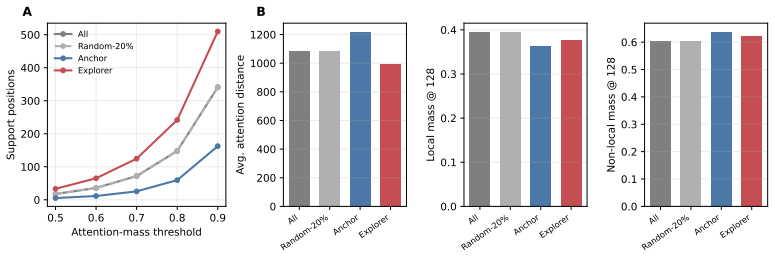
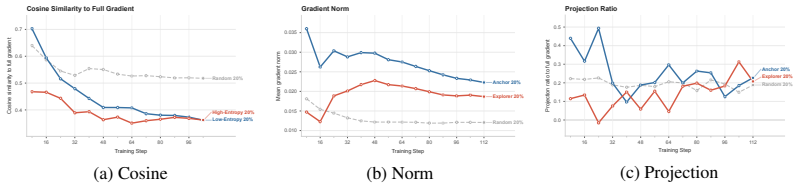
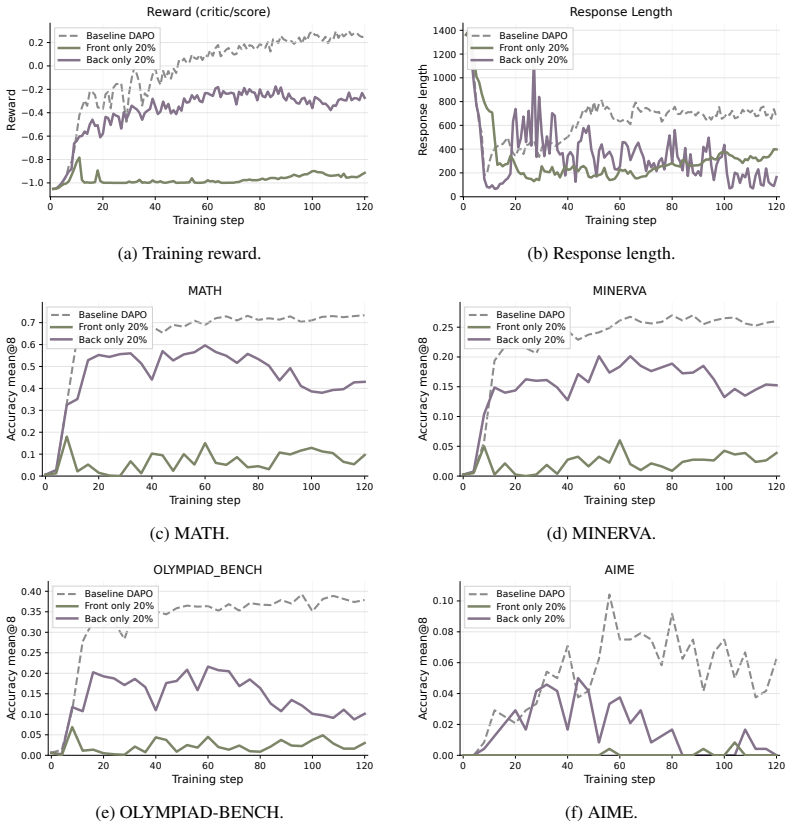
- Anchor tokens provide a stable optimization backbone but tend to plateau on harder benchmarks.
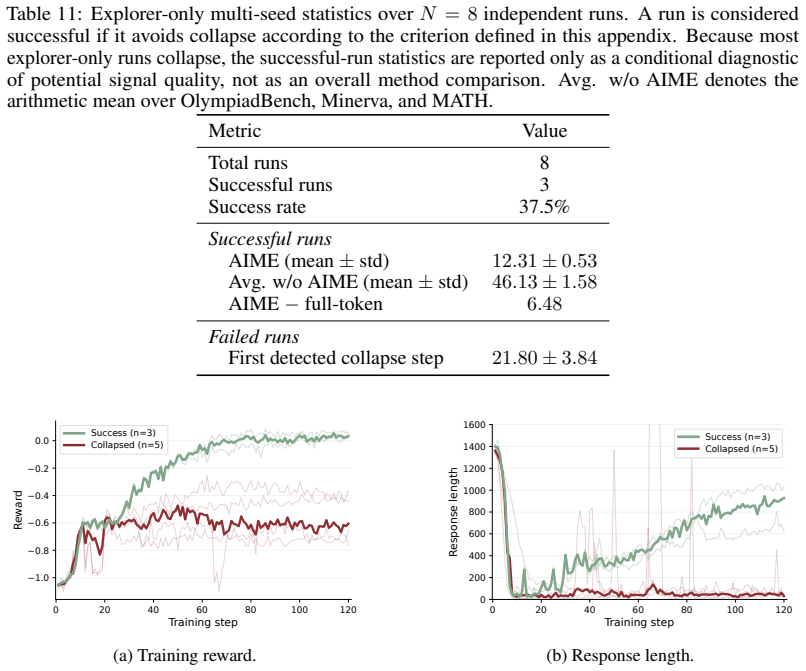
- Explorer tokens can contain useful hard-reasoning signals yet lead to unstable training on average.
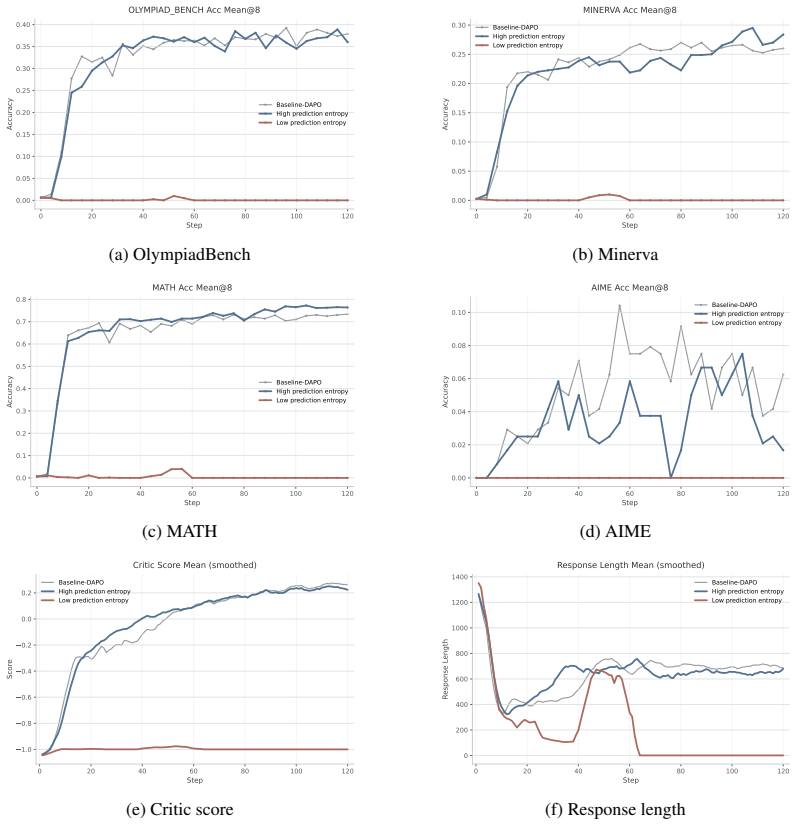
- The anchor-explorer asymmetry persists after explicit controls for token position, predictive entropy, and loss normalization.
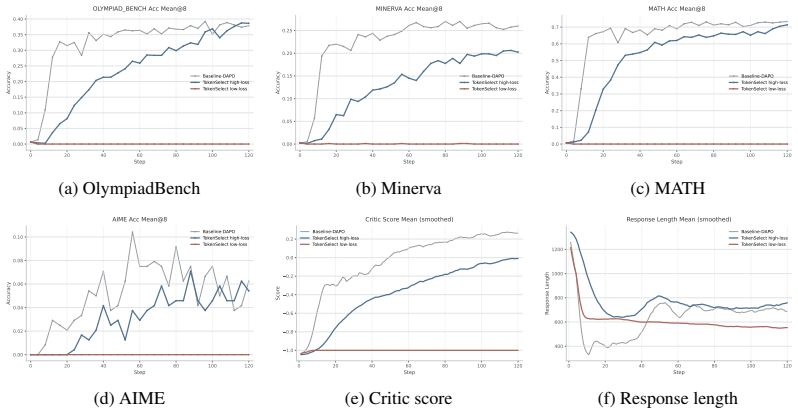
- Dynamic entropy-aware soft-reweighting improves overall held-out performance in the tested setting.
Where Pith is reading between the lines
- Training algorithms could adaptively up-weight anchors early for stability and gradually include explorers to tackle harder reasoning steps.
- The observed volatility in explorer gradients may explain inconsistent RL outcomes across runs and point to stabilization techniques.
- Similar entropy-based partitioning might apply to other token-level objectives such as supervised fine-tuning or preference optimization.
- Uniform averaging across tokens in standard RL objectives may hide useful heterogeneity that targeted reweighting can exploit.
Load-bearing premise
Attention entropy captures optimization-relevant heterogeneity in token signals independent of position, predictive entropy, and loss normalization.
What would settle it
Applying the entropy-aware soft-reweighting to a new model or benchmark and observing no performance gain, or finding that low-entropy token gradients lose alignment with full updates under additional controls.
Figures






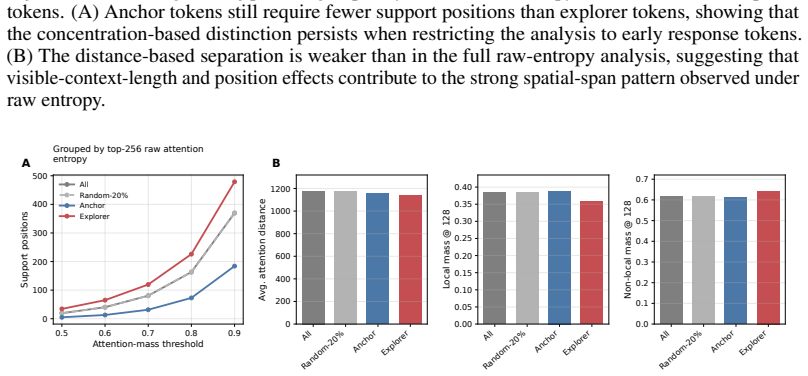

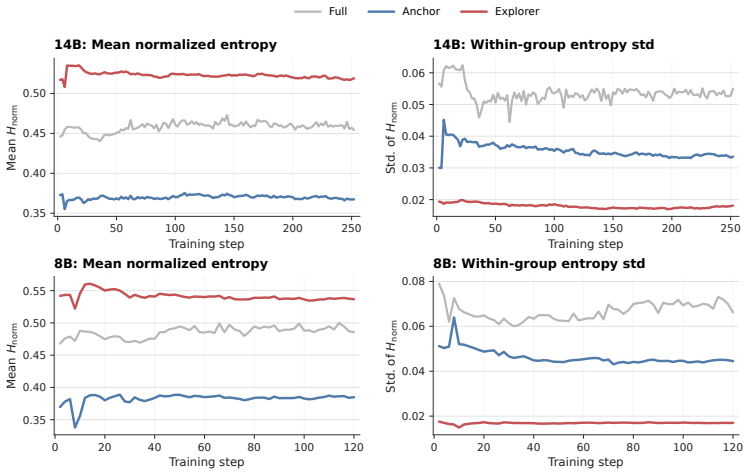

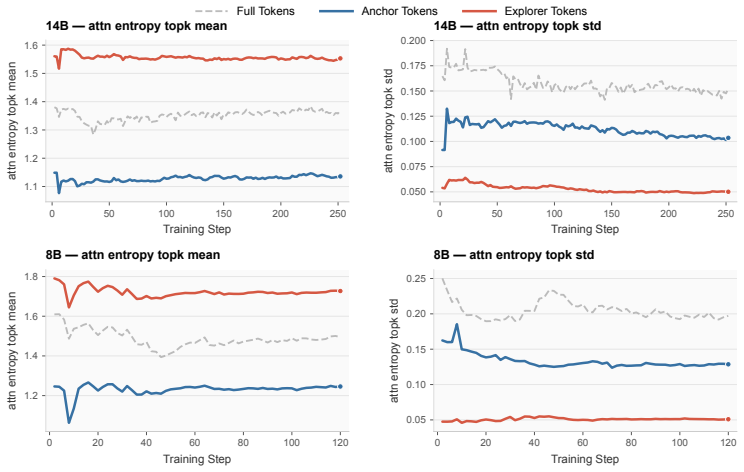



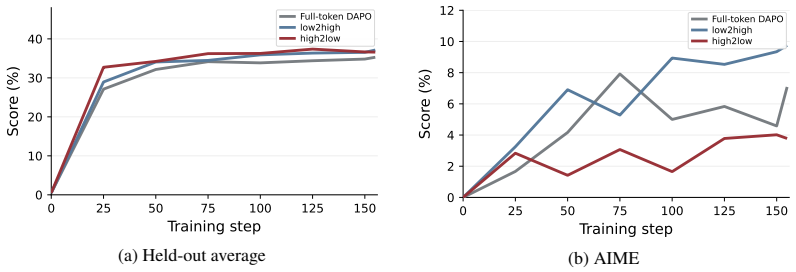
read the original abstract
Reinforcement-learning-based post-training has become a key approach for improving the reasoning ability of large language models, but its token-level learning signals remain poorly understood. This work studies their heterogeneity through attention entropy, which measures how concentrated or diffuse the contextual support is for each response token. We first show that token-level RL objectives are sparsely estimable: uniformly random 20 percent token subsets preserve much of the full-token held-out performance, suggesting substantial redundancy in token-level updates. However, entropy-structured subsets behave very differently. Low-attention-entropy tokens, which we call anchors, rely on concentrated support, produce stable gradients aligned with full-token updates, and provide a reliable optimization backbone, but tend to plateau on harder benchmarks. High-attention-entropy tokens, which we call explorers, aggregate more diffuse context and induce larger but more volatile gradients. Explorer-only training is unstable on average, though rare successful runs suggest that these tokens may contain useful hard-reasoning signals when optimization remains stable. We support this anchor-explorer spectrum with evidence-gathering analyses, entropy dynamics, gradient-geometry diagnostics, and controls showing that position, predictive entropy, and loss normalization do not explain the observed asymmetry. Finally, a dynamic entropy-aware soft-reweighting intervention improves Qwen3-8B-Base from 34.39 to 37.40 held-out average in the strongest setting. These findings suggest that attention entropy reveals optimization-relevant structure in token-level RL signals, and that uniform token averaging can obscure meaningful heterogeneity in reasoning post-training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that token-level RL objectives in LLM reasoning post-training exhibit heterogeneity captured by attention entropy: low-entropy 'anchor' tokens yield stable gradients aligned with full updates and serve as a reliable backbone, while high-entropy 'explorer' tokens produce larger but volatile gradients that may encode hard-reasoning signals. Uniform random subsets preserve performance, but entropy-structured subsets differ markedly; controls are said to rule out position, predictive entropy, and loss normalization as explanations; a dynamic entropy-aware soft-reweighting intervention raises Qwen3-8B-Base held-out average from 34.39 to 37.40.
Significance. If the central empirical claim holds after stronger isolation of attention entropy, the work would supply a concrete, actionable handle on token-level signal heterogeneity in RL reasoning training, with the reported 3-point lift indicating practical value for reweighting schemes. The sparsity finding and gradient-geometry diagnostics add diagnostic utility, though the moderate soundness and absence of replication artifacts limit immediate field impact.
major comments (2)
- [Controls] Controls section: the assertion that position, predictive entropy, and loss normalization do not explain the observed anchor/explorer asymmetry lacks the quantitative isolation metrics (e.g., partial correlations, residual gradient alignment after regression on those covariates, or matched-subset ablations) needed to support the claim; without them the attribution of both the gradient-geometry differences and the 34.39-to-37.40 gain specifically to attention entropy remains vulnerable to confounding.
- [Experimental results] Experimental results: the headline performance lift is reported as a single scalar (37.40) without run count, standard deviation, or statistical test against the 34.39 baseline, rendering it impossible to judge whether the gain is reliable or could be explained by optimization variance rather than the entropy-aware reweighting.
minor comments (3)
- [Method] The abstract and main text should explicitly define the entropy threshold used to separate anchors from explorers and state whether it is fixed or tuned per model/dataset.
- [Figures] Figure captions and axis labels for gradient-geometry diagnostics should include the exact normalization and distance metric employed so readers can reproduce the reported stability/volatility contrast.
- [Evaluation] The paper would be strengthened by reporting the exact held-out benchmarks and their weighting in the 34.39/37.40 averages.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help clarify the presentation of our results. We address each major comment below and commit to revisions that strengthen the quantitative support for our claims without altering the core findings.
read point-by-point responses
-
Referee: [Controls] Controls section: the assertion that position, predictive entropy, and loss normalization do not explain the observed anchor/explorer asymmetry lacks the quantitative isolation metrics (e.g., partial correlations, residual gradient alignment after regression on those covariates, or matched-subset ablations) needed to support the claim; without them the attribution of both the gradient-geometry differences and the 34.39-to-37.40 gain specifically to attention entropy remains vulnerable to confounding.
Authors: We acknowledge that while the manuscript reports controls indicating that position, predictive entropy, and loss normalization do not fully account for the anchor/explorer differences, these controls would be more convincing with explicit quantitative isolation. In the revision we will add (i) partial correlations between attention entropy and gradient-alignment metrics after regressing out the three covariates, and (ii) matched-subset ablations that hold position, predictive entropy, and loss normalization approximately constant while varying attention entropy. These additions will directly address the concern and provide the requested metrics. revision: yes
-
Referee: [Experimental results] Experimental results: the headline performance lift is reported as a single scalar (37.40) without run count, standard deviation, or statistical test against the 34.39 baseline, rendering it impossible to judge whether the gain is reliable or could be explained by optimization variance rather than the entropy-aware reweighting.
Authors: We agree that reporting only a single scalar value limits assessment of reliability. The revised manuscript will present the held-out average over multiple independent training runs (with the exact number stated), include standard deviations, and report a statistical comparison (e.g., paired t-test) between the entropy-aware reweighting condition and the baseline. This will allow readers to evaluate whether the observed improvement is distinguishable from optimization variance. revision: yes
Circularity Check
No significant circularity; empirical analyses and intervention stand independently.
full rationale
The paper advances its claims through observational statistics on attention entropy, gradient geometry diagnostics, explicit controls for position/predictive entropy/loss normalization, and a direct empirical performance comparison of the entropy-aware reweighting intervention. No equations, predictions, or first-principles derivations are presented that reduce by construction to fitted parameters, self-referential definitions, or self-citation chains. The anchor/explorer distinction is introduced as a descriptive label for observed entropy-based patterns and then tested via held-out metrics rather than assumed or derived tautologically. The reported 34.39-to-37.40 gain is an experimental outcome, not a statistical artifact of the measurement itself.
Axiom & Free-Parameter Ledger
free parameters (1)
- entropy threshold separating anchors from explorers
axioms (1)
- domain assumption Attention entropy measures the concentration of contextual support for each response token
invented entities (2)
-
anchor tokens
no independent evidence
-
explorer tokens
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe use Hnorm_t as the default metric... Anchor tokens: the bottom 20% by Hnorm_t ... Explorer tokens: the top 20%... dynamic entropy-aware soft-reweighting intervention improves Qwen3-8B-Base from 34.39 to 37.40
Reference graph
Works this paper leans on
-
[1]
Process Reinforcement through Implicit Rewards
Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Wendi Li, Bingxiang He, Yuchen Fan, Tianyu Yu, Qixin Xu, Weize Chen, Jiarui Yuan, Huayu Chen, Kaiyan Zhang, Xingtai Lv, Shuo Wang, Yuan Yao, Xu Han, Hao Peng, Yu Cheng, Zhiyuan Liu, Maosong Sun, Bowen Zhou, and Ning Ding. Process reinforcement through implicit rewards.arXiv preprint arXiv:2502.01456, 2025a. ...
work page internal anchor Pith review arXiv
-
[2]
Rethinking Token-Level Credit Assignment in RLVR: A Polarity-Entropy Analysis
Yuhang He, Haodong Wu, Siyi Liu, Hongyu Ge, Hange Zhou, Keyi Wu, Zhuo Zheng, Qihong Lin, Zixin Zhong, and Yongqi Zhang. Rethinking token-level credit assignment in RLVR: A polarity-entropy analysis.arXiv preprint arXiv:2604.11056,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Haoming Meng, Kexin Huang, Shaohang Wei, Chiyu Ma, Shuo Yang, Xue Wang, Guoyin Wang, Bolin Ding, and Jingren Zhou. Sparse but critical: A token-level analysis of distributional shifts in RLVR fine-tuning of LLMs.arXiv preprint arXiv:2603.22446,
-
[5]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
doi: 10.18653/v1/2024.acl-long.702
Association for Computational Linguistics. doi: 10.18653/v1/2024.acl-long.702. URL https://aclanthology.org/2024. acl-long.702/. Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. Math-shepherd: Verify and reinforce LLMs step-by-step without human annotations. In Proceedings of the 62nd Annual Meeting of t...
-
[7]
Math-shepherd: Verify and reinforce llms step-by-step without human annotations
Association for Computational Linguistics. doi: 10.18653/v1/2024.acl-long.510. URL https://aclanthology.org/2024. acl-long.510/. 10 Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shixuan Liu, Rui Lu, Kai Dang, Xionghui Chen, Jianxin Yang, Zhenru Zhang, Yuqiong Liu, An Yang, Andrew Zhao, Yang Yue, Shiji Song, Bowen Yu, Gao Huang, and Junyang Lin. Beyond the...
-
[8]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. DAPO: An open-source LLM reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Human Bias in the Face of AI: Examining Human Judgment Against Text Labeled as AI Generated
Association for Computational Linguistics. doi: 10.18653/v1/2025. acl-long.485. URLhttps://aclanthology.org/2025.acl-long.485/. Han Zhong, Zikang Shan, Guhao Feng, Wei Xiong, Xinle Cheng, Li Zhao, Di He, Jiang Bian, and Liwei Wang. DPO meets PPO: Reinforced token optimization for RLHF. InProceedings of the 42nd International Conference on Machine Learning...
-
[10]
URL https://proceedings.mlr. press/v267/. 11 A Detailed Related Work RLVR for reasoning language models.Reinforcement learning with verifiable rewards (RLVR) has recently become a central approach for improving the reasoning ability of large language models. DeepSeekMath introduced Group Relative Policy Optimization (GRPO), which removes the value model i...
work page 2024
-
[11]
+ MATH test split Prompt fieldprompt Data filtering None Prompt truncation Left truncation Maximum prompt length 1024 Maximum response length 8192 Maximum sequence length 9216 B.4 Reward function and overlong penalty We use the DAPO reward manager with a rule-based verifier. For each generated response, we extract the content inside \boxed{} and compare i...
work page 2048
-
[12]
Under the prediction-entropy 21 0 20 40 60 80 100 120 Step 0.00 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40Accuracy OLYMPIAD_BENCH Acc Mean@8 Baseline-DAPO High prediction entropy Low prediction entropy (a) OlympiadBench 0 20 40 60 80 100 120 Step 0.00 0.05 0.10 0.15 0.20 0.25 0.30Accuracy MINERVA Acc Mean@8 Baseline-DAPO High prediction entropy Low predictio...
work page 1926
-
[13]
The main observation is that the low-vs-high attention-entropy gap persists under both normalization schemes. Low-attention-entropy training remains strong and stable under both selected-token and all-token normalization. It achieves held-out performance close to full-token DAPO on the averaged validation score, maintains relatively stable response length...
work page 2000
-
[14]
The entropy-aware intervention remains effective under all three entropy-source layers, suggesting that the diagnostic is not tied to the specific Layer-20 probe used in the main mechanistic analyses. All three representative entropy sources improve over full-token DAPO on the held-out average and on every benchmark, but they expose different optimization...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.