Recognition: 2 theorem links
· Lean TheoremNoiseGate: Learning Per-Latent Timestep Schedules as Information Gating in World Action Models
Pith reviewed 2026-05-11 02:53 UTC · model grok-4.3
The pith
NoiseGate learns per-latent timestep schedules to act as information gates in joint video-action world models for robot control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
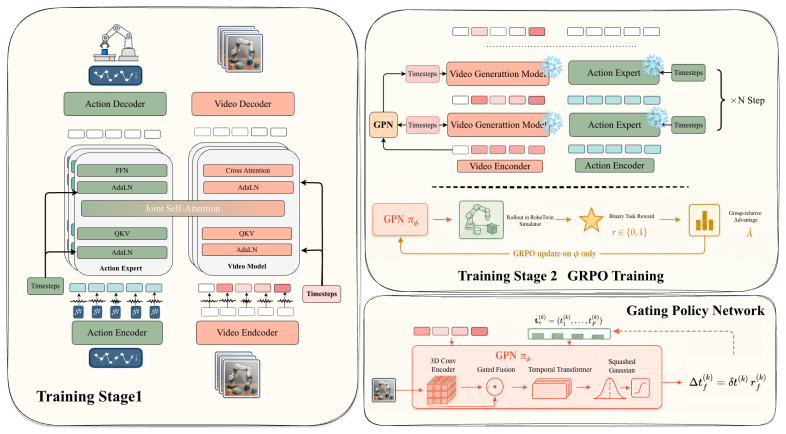
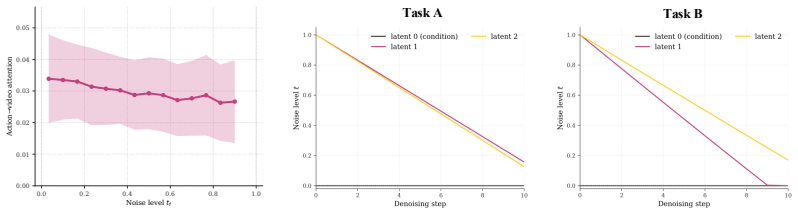
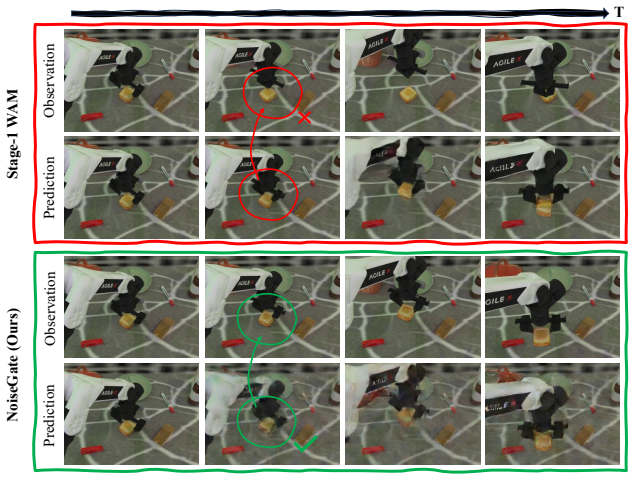
By viewing each latent frame's noise level as a controllable reliability knob rather than a fixed hyperparameter, a lightweight policy network can discover per-latent timestep schedules that modulate the Key/Value contribution of each predicted observation to the action tokens; when this policy is optimized directly on task reward, the resulting schedules improve action generation quality over any fixed shared schedule.
What carries the argument
Lightweight Gating Policy Network that outputs per-latent time increments, trained with independent per-latent timestep sampling and task-reward optimization inside a joint video-action MoT backbone.
If this is right
- Action generation can selectively ignore or trust different predicted future frames depending on the current state.
- The same backbone can be reused across tasks because the schedule policy adapts without manual retuning.
- Perception-prediction-control coupling becomes finer-grained than a single global noise level allows.
- Training stability is maintained even though the schedule is no longer a fixed hyperparameter.
Where Pith is reading between the lines
- Similar per-component gating could be applied to any generative model where different output tokens have unequal downstream value.
- The learned schedules might reveal which future observations carry the most decision-relevant information in manipulation tasks.
- Extending the approach to longer horizons or multi-agent settings would test whether the same lightweight policy remains sufficient.
- If the gating policy can be frozen after training, inference cost stays essentially unchanged from the baseline MoT.
Load-bearing premise
A small policy network optimized only on task reward can reliably discover useful per-latent noise schedules without any hand-crafted shape constraints.
What would settle it
Replace the learned per-latent schedules with either random schedules or the original shared-t schedule and measure whether task success rate on the RoboTwin random-scene suite drops by a statistically significant margin.
Figures



read the original abstract
World Action Models (WAMs) are an emerging family of policies that tie robot action generation to future-observation modeling. In this work, we focus on the joint video--action modeling paradigm, where actions and imagined future observations are co-generated along a shared denoising or flow trajectory, so that perception, prediction, and control are coupled within one generative process. Existing WAMs typically realize this paradigm with a Mixture-of-Transformers (MoT), where video and action tokens interact through shared self-attention. This architecture can in principle assign a separate timestep $t_f$ to each predicted latent frame, yet current systems collapse this degree of freedom onto a single shared scalar $t$. Under the noise-as-masking view of Diffusion Forcing, this shared schedule imposes the unjustified prior that every predicted latent is equally reliable for action generation. We instead view the per-latent schedule as a \emph{learnable information-gating policy}: by changing a latent frame's noise level, the policy modulates the reliability of its Key/Value contribution to the action tokens. We propose \textbf{NoiseGate}, which combines independent per-latent timestep sampling during backbone training, a lightweight Gating Policy Network that emits per-latent time increments during denoising, and task-reward optimization that trains the schedule policy without hand-crafted shape priors. Built on a joint video--action MoT backbone, NoiseGate delivers consistent gains on diverse RoboTwin random-scene manipulation tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces NoiseGate, a method to learn per-latent timestep schedules as an information-gating policy within joint video-action Mixture-of-Transformers (MoT) backbones for World Action Models. It combines independent per-latent timestep sampling during training, a lightweight Gating Policy Network that outputs per-latent time increments during denoising, and task-reward optimization to train the schedule policy without hand-crafted shape priors. The central empirical claim is that this yields consistent performance gains on diverse RoboTwin random-scene manipulation tasks.
Significance. If the claimed gains are robustly demonstrated, the approach could meaningfully advance generative world models for robotics by relaxing the shared-timestep assumption and allowing adaptive modulation of latent-frame reliability in action generation, potentially improving policy performance in unstructured manipulation settings.
major comments (2)
- Abstract: The claim of 'consistent gains' on RoboTwin tasks is stated without any quantitative metrics, baseline comparisons, error bars, or statistical tests, making it impossible to assess the magnitude, reliability, or reproducibility of the reported improvements.
- Method description (no numbered equations provided): The Gating Policy Network is introduced as emitting per-latent time increments, yet no explicit formulation is given for how these increments are applied to the shared denoising trajectory or how the task-reward objective is defined, leaving open whether the learned schedules provide information gating beyond what a shared-t baseline already achieves.
minor comments (2)
- The abstract introduces 'Mixture-of-Transformers (MoT)' and 'Diffusion Forcing' without citing the foundational references for these components.
- Several long sentences in the abstract could be split to improve readability and clarity of the technical contributions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and agree that targeted revisions will improve clarity and support for the claims. We will update the manuscript accordingly.
read point-by-point responses
-
Referee: Abstract: The claim of 'consistent gains' on RoboTwin tasks is stated without any quantitative metrics, baseline comparisons, error bars, or statistical tests, making it impossible to assess the magnitude, reliability, or reproducibility of the reported improvements.
Authors: We agree that the abstract would benefit from quantitative support to substantiate the 'consistent gains' claim. In the revised version, we will expand the abstract to include key metrics from the experimental results, such as average success rate improvements over shared-t baselines on RoboTwin tasks, along with references to error bars and statistical tests presented in the main results section. This will allow readers to evaluate the magnitude and reliability of the improvements directly from the abstract while maintaining its conciseness. revision: yes
-
Referee: Method description (no numbered equations provided): The Gating Policy Network is introduced as emitting per-latent time increments, yet no explicit formulation is given for how these increments are applied to the shared denoising trajectory or how the task-reward objective is defined, leaving open whether the learned schedules provide information gating beyond what a shared-t baseline already achieves.
Authors: We acknowledge that the current prose description of the Gating Policy Network and its integration lacks the precision of explicit equations, which could leave ambiguity about its distinction from a shared-t baseline. We will revise the method section to include numbered equations defining: the per-latent timestep computation (t_i = t + Δt_i where Δt_i is output by the lightweight policy network), the application of these timesteps within the joint video-action MoT denoising process, and the task-reward objective used for policy optimization. These additions will explicitly demonstrate how the per-latent modulation enables adaptive information gating that goes beyond uniform timestep assumptions, as validated by our ablation studies. revision: yes
Circularity Check
No significant circularity; empirical gains rest on added trainable components rather than definitional reduction
full rationale
The paper introduces a Gating Policy Network and task-reward optimization to learn per-latent timestep schedules on top of an existing joint video-action MoT backbone. The central claim of consistent gains on RoboTwin tasks is presented as an empirical outcome from this new architecture and training procedure. No equations, derivations, or self-citations are shown that reduce the claimed improvement to a quantity defined by the method itself or to a fitted parameter renamed as a prediction. The approach explicitly avoids hand-crafted priors and uses independent per-latent sampling, keeping the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- Gating Policy Network parameters
axioms (1)
- domain assumption Noise-as-masking view of Diffusion Forcing holds for joint video-action modeling
invented entities (1)
-
Gating Policy Network
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe instead view the per-latent schedule as a learnable information-gating policy: by changing a latent frame's noise level, the policy modulates the reliability of its Key/Value contribution to the action tokens.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclearNoiseGate, which combines independent per-latent timestep sampling during backbone training, a lightweight Gating Policy Network that emits per-latent time increments during denoising, and task-reward optimization that trains the schedule policy without hand-crafted shape priors.
Reference graph
Works this paper leans on
-
[1]
Motus: A Unified Latent Action World Model
Hongzhe Bi, Hengkai Tan, Shenghao Xie, Zeyuan Wang, Shuhe Huang, Haitian Liu, Ruowen Zhao, Yao Feng, Chendong Xiang, Yinze Rong, et al. Motus: A unified latent action world model.arXiv preprint arXiv:2512.13030, 2025
work page internal anchor Pith review arXiv 2025
-
[2]
Fast-WAM: Do World Action Models Need Test-time Future Imagination?
Tianyuan Yuan, Zibin Dong, Yicheng Liu, and Hang Zhao. Fast-wam: Do world action models need test-time future imagination?arXiv preprint arXiv:2603.16666, 2026
work page internal anchor Pith review arXiv 2026
-
[3]
World Action Models are Zero-shot Policies
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026
work page internal anchor Pith review arXiv 2026
-
[4]
Yichao Shen, Fangyun Wei, Zhiying Du, Yaobo Liang, Yan Lu, Jiaolong Yang, Nanning Zheng, and Baining Guo. Videovla: Video generators can be generalizable robot manipulators.arXiv preprint arXiv:2512.06963, 2025
-
[5]
Cosmos Policy: Fine-Tuning Video Models for Visuomotor Control and Planning
Moo Jin Kim, Yihuai Gao, Tsung-Yi Lin, Yen-Chen Lin, Yunhao Ge, Grace Lam, Percy Liang, Shuran Song, Ming-Yu Liu, Chelsea Finn, et al. Cosmos policy: Fine-tuning video models for visuomotor control and planning.arXiv preprint arXiv:2601.16163, 2026
work page internal anchor Pith review arXiv 2026
-
[6]
Rynnvla-002: A unified vision-language-action and world model.arXiv preprint arXiv:2511.17502, 2025
Jun Cen, Siteng Huang, Yuqian Yuan, Kehan Li, Hangjie Yuan, Chaohui Yu, Yuming Jiang, Jiayan Guo, Xin Li, Hao Luo, et al. Rynnvla-002: A unified vision-language-action and world model.arXiv preprint arXiv:2511.17502, 2025
-
[7]
Shuang Li, Yihuai Gao, Dorsa Sadigh, and Shuran Song. Unified video action model.arXiv preprint arXiv:2503.00200, 2025
work page internal anchor Pith review arXiv 2025
-
[8]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, T...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Boyuan Chen, Diego Martí Monsó, Yilun Du, Max Simchowitz, Russ Tedrake, and Vincent Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffusion.Advances in Neural Information Processing Systems, 37:24081–24125, 2024
work page 2024
-
[10]
arXiv preprint arXiv:2411.04996 , year =
Weixin Liang, Lili Yu, Liang Luo, Srinivasan Iyer, Ning Dong, Chunting Zhou, Gargi Ghosh, Mike Lewis, Wen-tau Yih, Luke Zettlemoyer, et al. Mixture-of-transformers: A sparse and scalable architecture for multi-modal foundation models.arXiv preprint arXiv:2411.04996, 2024
-
[11]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
work page 2025
-
[13]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
Mustafa Shukor, Dana Aubakirova, Francesco Capuano, Pepijn Kooijmans, Steven Palma, Adil Zouitine, Michel Aractingi, Caroline Pascal, Martino Russi, Andres Marafioti, et al. Smolvla: A vision-language-action model for affordable and efficient robotics.arXiv preprint arXiv:2506.01844, 2025
work page internal anchor Pith review arXiv 2025
-
[14]
Wei Li, Renshan Zhang, Rui Shao, Jie He, and Liqiang Nie. Cogvla: Cognition-aligned vision-language-action model via instruction-driven routing & sparsification.arXiv preprint arXiv:2508.21046, 2025. 10
-
[15]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. pi0.5: a vision- language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation.arXiv preprint arXiv:2410.07864, 2024
work page internal anchor Pith review arXiv 2024
-
[18]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. pi0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023
work page 2023
-
[21]
Gemini Robotics: Bringing AI into the Physical World
Gemini Robotics Team, Saminda Abeyruwan, Joshua Ainslie, Jean-Baptiste Alayrac, Montser- rat Gonzalez Arenas, Travis Armstrong, Ashwin Balakrishna, Robert Baruch, Maria Bauza, Michiel Blokzijl, et al. Gemini robotics: Bringing ai into the physical world.arXiv preprint arXiv:2503.20020, 2025
work page internal anchor Pith review arXiv 2025
-
[22]
Hao Shi, Bin Xie, Yingfei Liu, Lin Sun, Fengrong Liu, Tiancai Wang, Erjin Zhou, Haoqiang Fan, Xiangyu Zhang, and Gao Huang. Memoryvla: Perceptual-cognitive memory in vision- language-action models for robotic manipulation.arXiv preprint arXiv:2508.19236, 2025
-
[23]
GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation
Chi-Lam Cheang, Guangzeng Chen, Ya Jing, Tao Kong, Hang Li, Yifeng Li, Yuxiao Liu, Hongtao Wu, Jiafeng Xu, Yichu Yang, et al. Gr-2: A generative video-language-action model with web-scale knowledge for robot manipulation.arXiv preprint arXiv:2410.06158, 2024
work page internal anchor Pith review arXiv 2024
-
[24]
Joel Jang, Seonghyeon Ye, Zongyu Lin, Jiannan Xiang, Johan Bjorck, Yu Fang, Fengyuan Hu, Spencer Huang, Kaushil Kundalia, Yen-Chen Lin, et al. Dreamgen: Unlocking generalization in robot learning through video world models.arXiv preprint arXiv:2505.12705, 2025
-
[25]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Unleashing Large-Scale Video Generative Pre-training for Visual Robot Manipulation
Hongtao Wu, Ya Jing, Chilam Cheang, Guangzeng Chen, Jiafeng Xu, Xinghang Li, Minghuan Liu, Hang Li, and Tao Kong. Unleashing large-scale video generative pre-training for visual robot manipulation.arXiv preprint arXiv:2312.13139, 2023
work page internal anchor Pith review arXiv 2023
-
[27]
Siyuan Zhou, Yilun Du, Jiaben Chen, Yandong Li, Dit-Yan Yeung, and Chuang Gan. Ro- bodreamer: Learning compositional world models for robot imagination.arXiv preprint arXiv:2404.12377, 2024
-
[28]
Video Prediction Policy: A Generalist Robot Policy with Predictive Visual Representations
Yucheng Hu, Yanjiang Guo, Pengchao Wang, Xiaoyu Chen, Yen-Jen Wang, Jianke Zhang, Koushil Sreenath, Chaochao Lu, and Jianyu Chen. Video prediction policy: A generalist robot policy with predictive visual representations.arXiv preprint arXiv:2412.14803, 2024
work page internal anchor Pith review arXiv 2024
-
[29]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020. 11
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[30]
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models.Advances in neural information processing systems, 35:26565–26577, 2022
work page 2022
-
[31]
Schedule on the fly: Diffusion time prediction for faster and better image generation
Zilyu Ye, Zhiyang Chen, Tiancheng Li, Zemin Huang, Weijian Luo, and Guo-Jun Qi. Schedule on the fly: Diffusion time prediction for faster and better image generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 23412–23422, 2025
work page 2025
-
[32]
Hongzhi Zang, Mingjie Wei, Si Xu, Yongji Wu, Zhen Guo, Yuanqing Wang, Hao Lin, Liangzhi Shi, Yuqing Xie, Zhexuan Xu, et al. Rlinf-vla: A unified and efficient framework for vla+ rl training.arXiv preprint arXiv:2510.06710, 2025
-
[33]
Chao Yu, Yuanqing Wang, Zhen Guo, Hao Lin, Si Xu, Hongzhi Zang, Quanlu Zhang, Yongji Wu, Chunyang Zhu, Junhao Hu, et al. Rlinf: Flexible and efficient large-scale reinforcement learning via macro-to-micro flow transformation.arXiv preprint arXiv:2509.15965, 2025
-
[34]
RL-VLA$^3$: A Flexible and Asynchronous Reinforcement Learning Framework for VLA Training
Zhong Guan, Haoran Sun, Yongjian Guo, Shuai Di, Xiaodong Bai, Jing Long, Tianyun Zhao, Mingxi Luo, Chen Zhou, Yucheng Guo, et al. Rl-vla3: Reinforcement learning vla accelerating via full asynchronism.arXiv preprint arXiv:2602.05765, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
arXiv preprint arXiv:2509.09674 , year=
Haozhan Li, Yuxin Zuo, Jiale Yu, Yuhao Zhang, Zhaohui Yang, Kaiyan Zhang, Xuekai Zhu, Yuchen Zhang, Tianxing Chen, Ganqu Cui, et al. Simplevla-rl: Scaling vla training via reinforcement learning.arXiv preprint arXiv:2509.09674, 2025
-
[36]
What can rl bring to vla generalization? an empirical study.arXiv preprint, arXiv:2505.19789, 2025
Jijia Liu, Feng Gao, Bingwen Wei, Xinlei Chen, Qingmin Liao, Yi Wu, Chao Yu, and Yu Wang. What can rl bring to vla generalization? an empirical study.arXiv preprint arXiv:2505.19789, 2025
-
[37]
Flow-GRPO: Training Flow Matching Models via Online RL
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-grpo: Training flow matching models via online rl.arXiv preprint arXiv:2505.05470, 2025
work page internal anchor Pith review arXiv 2025
-
[38]
Tonghe Zhang, Chao Yu, Sichang Su, and Yu Wang. Reinflow: Fine-tuning flow matching policy with online reinforcement learning.arXiv preprint arXiv:2505.22094, 2025
-
[39]
Kang Chen, Zhihao Liu, Tonghe Zhang, Zhen Guo, Si Xu, Hao Lin, Hongzhi Zang, Quanlu Zhang, Zhaofei Yu, Guoliang Fan, et al. πrl: Online rl fine-tuning for flow-based vision- language-action models.arXiv preprint arXiv:2510.25889, 2025
-
[40]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
work page 2023
-
[41]
Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Zixuan Li, Qiwei Liang, Xianliang Lin, Yiheng Ge, Zhenyu Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025. 12 A Limitations The main limitation of the current schedu...
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.