Recognition: no theorem link
RL-VLA³: A Flexible and Asynchronous Reinforcement Learning Framework for VLA Training
Pith reviewed 2026-05-16 06:58 UTC · model grok-4.3
The pith
An asynchronous RL framework for vision-language-action models raises training throughput by up to 85 percent while keeping sample efficiency unchanged.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
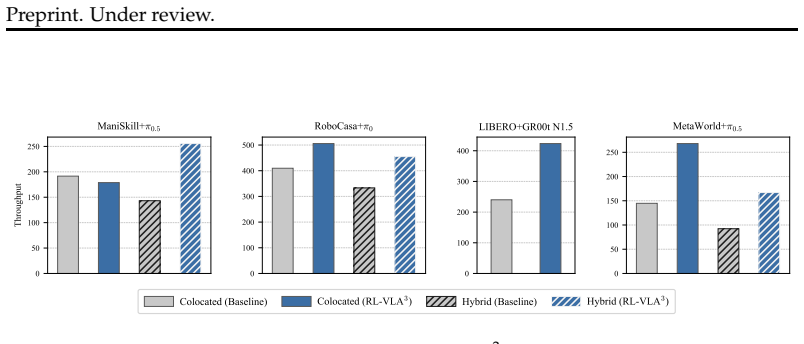
RL-VLA³ is the first fully asynchronous RL training framework tailored specifically for the system-level challenges of VLA training; it enables fine-grained asynchronous interaction between simulation, inference, and training components through dynamic batching schedulers and flexible environment sharding strategies, delivering throughput gains of up to 85.2 percent over synchronous baselines while preserving identical sample efficiency and scaling from 8 to 256 GPUs.
What carries the argument
Dynamic batching schedulers combined with flexible environment sharding strategies, which decouple simulation, inference, and training so they advance independently without waiting for full rollouts to complete.
If this is right
- Training runs finish in substantially less wall-clock time on the same hardware.
- The same final policy quality is reached with the same number of environment interactions.
- The framework works with many different simulators, VLA model sizes, and reinforcement learning algorithms.
- Distributed training scales linearly up to at least 256 GPUs without loss of correctness.
Where Pith is reading between the lines
- Hardware clusters previously limited by simulator wait times could now train larger VLA policies or run more parallel environments.
- Similar asynchronous patterns may transfer to other latency-heavy domains such as real-robot fine-tuning or long-horizon game environments.
- Developers could add priority queuing or adaptive sharding on top of the existing schedulers to further tune for specific robot tasks.
Load-bearing premise
The asynchronous design with dynamic batching and sharding introduces no hidden biases, instability, or correctness issues in the underlying RL optimization for VLA policies.
What would settle it
Train the same VLA policy on the same task and environment using both RL-VLA³ and a standard synchronous RL loop, then check whether the final policy performance and total samples required to reach that performance differ between the two runs.
Figures







read the original abstract
Reinforcement learning (RL) has emerged as a critical paradigm for post-training Vision-Language-Action (VLA) models, enabling embodied agents to adapt and improve through environmental interaction. However, existing RL frameworks for VLAs inherit synchronous design principles from traditional LLM training, treating entire rollouts as indivisible units and alternating strictly between data collection and policy optimization. This fundamentally mismatches the unique characteristics of VLA training, as physical simulators introduce highly variable, resource-intensive latencies. To address this, we introduce RL-VLA$^3$, a fully asynchronous distributed RL framework that enables fine-grained asynchronous interaction between simulation, inference, and training components through dynamic batching schedulers and flexible environment sharding strategies. Extensive experiments across diverse simulation backends, VLA architectures, and RL algorithms demonstrate that RL-VLA$^3$ achieves throughput improvements of up to 85.2\% over synchronous baselines while maintaining identical sample efficiency, with scalability validated from 8 to 256 GPUs. To our knowledge, RL-VLA$^3$ is the first fully asynchronous RL training framework tailored specifically for the system-level challenges of VLA training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RL-VLA³, a fully asynchronous distributed RL framework for Vision-Language-Action (VLA) model training. It identifies a mismatch between synchronous LLM-style training pipelines (which treat rollouts as atomic units) and the high, variable latencies of physical simulators, then proposes dynamic batching schedulers and flexible environment sharding to enable fine-grained overlap of simulation, inference, and optimization. The central empirical claim is that the framework delivers up to 85.2% higher throughput than synchronous baselines while preserving identical sample efficiency across multiple simulators, VLA architectures, and RL algorithms, with scaling demonstrated from 8 to 256 GPUs.
Significance. If the throughput and sample-efficiency claims hold under rigorous controls, RL-VLA³ would represent a practical systems advance for RL post-training of embodied VLAs, allowing substantially higher GPU utilization and larger-scale experiments without sacrificing learning dynamics. The reported cross-backend, cross-algorithm, and cross-scale validation strengthens the result relative to single-environment studies.
major comments (2)
- [§4] §4 (Experimental Results) and abstract: the claim that sample efficiency remains 'identical' across synchronous and asynchronous runs is stated without accompanying details on experimental controls, number of independent seeds, statistical equivalence tests, or how rollout lengths and environment stochasticity were matched. This information is load-bearing for the central assertion that dynamic batching and sharding introduce no hidden biases or instability in the underlying RL optimization.
- [§3.2] §3.2 (Dynamic Batching Scheduler) and §3.3 (Environment Sharding): the description of how partial rollouts are assembled into training batches and how sharding preserves correct credit assignment is high-level; a concrete walk-through or pseudocode showing that the effective batch size and gradient statistics remain unbiased relative to the synchronous case would be required to substantiate correctness.
minor comments (2)
- [Figure 3] Figure 3 and Table 1: axis labels and legend entries are too small to read at print size; throughput numbers should be accompanied by standard deviations or confidence intervals.
- [Abstract] The expansion of the superscript '³' in RL-VLA³ is never stated explicitly in the title, abstract, or introduction.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and will revise the paper to incorporate the requested clarifications and additions.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Results) and abstract: the claim that sample efficiency remains 'identical' across synchronous and asynchronous runs is stated without accompanying details on experimental controls, number of independent seeds, statistical equivalence tests, or how rollout lengths and environment stochasticity were matched. This information is load-bearing for the central assertion that dynamic batching and sharding introduce no hidden biases or instability in the underlying RL optimization.
Authors: We agree that the current presentation lacks sufficient detail to fully substantiate the 'identical' sample-efficiency claim. In the revised manuscript we will expand §4 (and the abstract where appropriate) to report: (i) the use of five independent random seeds per condition, (ii) explicit matching of rollout lengths via identical maximum episode horizons and termination criteria, (iii) control of environment stochasticity through fixed simulator seeds, and (iv) results of statistical equivalence tests (paired t-tests, p > 0.05) on cumulative reward and success rate showing no significant difference between synchronous and asynchronous runs. These additions will demonstrate that the observed throughput gains do not alter the underlying RL optimization dynamics. revision: yes
-
Referee: [§3.2] §3.2 (Dynamic Batching Scheduler) and §3.3 (Environment Sharding): the description of how partial rollouts are assembled into training batches and how sharding preserves correct credit assignment is high-level; a concrete walk-through or pseudocode showing that the effective batch size and gradient statistics remain unbiased relative to the synchronous case would be required to substantiate correctness.
Authors: We acknowledge that the algorithmic descriptions in §3.2 and §3.3 are high-level. In the revision we will add a dedicated subsection (or appendix) containing (i) complete pseudocode for the dynamic batching scheduler and environment-sharding logic, (ii) a step-by-step walk-through on a small toy batch illustrating how partial rollouts are buffered and assembled while preserving the target batch size, and (iii) a short mathematical argument showing that the expected gradient remains unbiased because each trajectory segment is processed under the correct policy version and advantage estimation uses standard GAE with proper discounting. These additions will make the unbiasedness claim explicit and verifiable. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes a new asynchronous distributed RL framework (RL-VLA³) for VLA training, with claims of throughput gains (up to 85.2%) and preserved sample efficiency supported by experiments across simulators, architectures, RL algorithms, and GPU scales (8-256). No mathematical derivations, equations, fitted parameters, or self-referential definitions appear in the abstract or high-level description. The central argument is an engineering design choice (dynamic batching and sharding for asynchrony) validated empirically against synchronous baselines, without any step that reduces by construction to its own inputs or relies on load-bearing self-citations for uniqueness.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reinforcement learning proceeds via alternating data collection and policy optimization steps
invented entities (1)
-
RL-VLA³ asynchronous framework
no independent evidence
Forward citations
Cited by 5 Pith papers
-
NoiseGate: Learning Per-Latent Timestep Schedules as Information Gating in World Action Models
NoiseGate learns per-latent timestep schedules as an information-gating policy in diffusion-based world action models, yielding consistent gains on RoboTwin manipulation tasks.
-
D-VLA: A High-Concurrency Distributed Asynchronous Reinforcement Learning Framework for Vision-Language-Action Models
D-VLA introduces plane decoupling and a swimlane asynchronous pipeline to achieve high-concurrency RL training and linear scalability for billion- to trillion-parameter vision-language-action models.
-
D-VLA: A High-Concurrency Distributed Asynchronous Reinforcement Learning Framework for Vision-Language-Action Models
D-VLA uses plane decoupling and a swimlane pipeline to deliver higher throughput and linear speedup than prior RL frameworks when training billion- and trillion-parameter VLA models on benchmarks like LIBERO.
-
Missing Old Logits in Asynchronous Agentic RL: Semantic Mismatch and Repair Methods for Off-Policy Correction
Missing old logits in async agentic RL entangle discrepancy and staleness terms in PPO off-policy correction; exact acquisition methods and revised PPO-EWMA restore decoupled updates with reported gains in speed and p...
-
Sword: Style-Robust World Models as Simulators via Dynamic Latent Bootstrapping for VLA Policy Post-Training
Sword improves world model simulators for VLA policies by disentangling visual style from dynamics and bootstrapping latents for better consistency, outperforming baselines on LIBERO in generalization and RL post-trai...
Reference graph
Works this paper leans on
-
[1]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Casta˜neda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language- action flow model for general robot control.arXiv preprint arXiv:2410.24164,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Zixuan Li, Qiwei Liang, Xianliang Lin, Yiheng Ge, Zhenyu Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation. arXiv preprint arXiv:2506.18088, 2025a. Yuhui Chen, Shuai Tian, Shugao Liu, Yingting Zhou, Haora...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
AReaL: A Large-Scale Asynchronous Reinforcement Learning System for Language Reasoning
Wei Fu, Jiaxuan Gao, Xujie Shen, Chen Zhu, Zhiyu Mei, Chuyi He, Shusheng Xu, Guo Wei, Jun Mei, Jiashu Wang, et al. Areal: A large-scale asynchronous reinforcement learning system for language reasoning.arXiv preprint arXiv:2505.24298,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Wei Gao, Yuheng Zhao, Tianyuan Wu, Shaopan Xiong, Weixun Wang, Dakai An, Lunxi Cao, Dilxat Muhtar, Zichen Liu, Haizhou Zhao, et al. Rollart: Scaling agentic rl training via disaggregated infrastructure.arXiv preprint arXiv:2512.22560,
-
[6]
Gemini Robotics Team. Gemini Robotics 1.5: Pushing the Frontier of Generalist Robots with Advanced Embodied Reasoning, Thinking, and Motion Transfer.arXiv e-prints, art. arXiv:2510.03342, October
work page internal anchor Pith review arXiv
-
[7]
doi: 10.48550/arXiv.2510.03342. Yanjiang Guo, Jianke Zhang, Xiaoyu Chen, Xiang Ji, Yen-Jen Wang, Yucheng Hu, and Jianyu Chen. Improving vision-language-action model with online reinforcement learning. In 2025 IEEE International Conference on Robotics and Automation (ICRA), pp. 15665–15672. IEEE,
work page internal anchor Pith review doi:10.48550/arxiv.2510.03342 2025
-
[8]
OpenRLHF: An Easy-to-use, Scalable and High-performance RLHF Framework
Jian Hu, Xibin Wu, Zilin Zhu, Weixun Wang, Dehao Zhang, Yu Cao, et al. Openrlhf: An easy- to-use, scalable and high-performance rlhf framework.arXiv preprint arXiv:2405.11143, 6,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
SimpleVLA-RL: Scaling VLA Training via Reinforcement Learning
10 Preprint. Under review. Haozhan Li, Yuxin Zuo, Jiale Yu, Yuhao Zhang, Zhaohui Yang, Kaiyan Zhang, Xuekai Zhu, Yuchen Zhang, Tianxing Chen, Ganqu Cui, et al. Simplevla-rl: Scaling vla training via reinforcement learning.arXiv preprint arXiv:2509.09674, 2025a. Hengtao Li, Pengxiang Ding, Runze Suo, Yihao Wang, Zirui Ge, Dongyuan Zang, Kexian Yu, Mingyang...
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
What can rl bring to vla generalization? an empirical study.arXiv preprint arXiv:2505.19789,
Jijia Liu, Feng Gao, Bingwen Wei, Xinlei Chen, Qingmin Liao, Yi Wu, Chao Yu, and Yu Wang. What can rl bring to vla generalization? an empirical study.arXiv preprint arXiv:2505.19789,
-
[13]
Guanxing Lu, Wenkai Guo, Chubin Zhang, Yuheng Zhou, Haonan Jiang, Zifeng Gao, Yan- song Tang, and Ziwei Wang. Vla-rl: Towards masterful and general robotic manipulation with scalable reinforcement learning.arXiv preprint arXiv:2505.18719,
-
[14]
A Survey on Vision-Language-Action Models for Embodied AI
Yueen Ma, Zixing Song, Yuzheng Zhuang, Jianye Hao, and Irwin King. A survey on vision-language-action models for embodied ai.arXiv preprint arXiv:2405.14093,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots
Soroush Nasiriany, Abhiram Maddukuri, Lance Zhang, Adeet Parikh, Aaron Lo, Abhishek Joshi, Ajay Mandlekar, and Yuke Zhu. Robocasa: Large-scale simulation of everyday tasks for generalist robots.arXiv preprint arXiv:2406.02523,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Laminar: A scalable asynchronous rl post-training framework.arXiv preprint arXiv:2510.12633, 2025a
Guangming Sheng, Yuxuan Tong, Borui Wan, Wang Zhang, Chaobo Jia, Xibin Wu, Yuqi Wu, Xiang Li, Chi Zhang, Yanghua Peng, et al. Laminar: A scalable asynchronous rl post-training framework.arXiv preprint arXiv:2510.12633, 2025a. Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A fl...
-
[19]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
URL https://arxiv.org/abs/ 2506.01844. Shuhan Tan, Kairan Dou, Yue Zhao, and Philipp Kr¨ahenb ¨uhl. Interactive post-training for vision-language-action models.arXiv preprint arXiv:2505.17016,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Tianhe Yu, Deirdre Quillen, Zhanpeng He, Ryan Julian, Karol Hausman, Chelsea Finn, and Sergey Levine
URL https: //arxiv.org/abs/2511.00091. Tianhe Yu, Deirdre Quillen, Zhanpeng He, Ryan Julian, Karol Hausman, Chelsea Finn, and Sergey Levine. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning. InConference on robot learning, pp. 1094–1100. PMLR,
-
[21]
Rlinf-vla: A unified and efficient framework for vla+ rl training.arXiv preprint arXiv:2510.06710,
Hongzhi Zang, Mingjie Wei, Si Xu, Yongji Wu, Zhen Guo, Yuanqing Wang, Hao Lin, Liangzhi Shi, Yuqing Xie, Zhexuan Xu, et al. Rlinf-vla: A unified and efficient framework for vla+ rl training.arXiv preprint arXiv:2510.06710,
-
[22]
Pure vision language action (vla) models: A comprehensive survey
Dapeng Zhang, Jing Sun, Chenghui Hu, Xiaoyan Wu, Zhenlong Yuan, Rui Zhou, Fei Shen, and Qingguo Zhou. Pure vision language action (vla) models: A comprehensive survey. arXiv preprint arXiv:2509.19012,
-
[23]
Yifan Zhong, Fengshuo Bai, Shaofei Cai, Xuchuan Huang, Zhang Chen, Xiaowei Zhang, Yuanfei Wang, Shaoyang Guo, Tianrui Guan, Ka Nam Lui, et al. A survey on vision-language-action models: An action tokenization perspective.arXiv preprint arXiv:2507.01925,
-
[24]
Chen Zhou, Haoran Sun, Hedan Yang, Jing Long, Junwu Xiong, Luqiao Wang, Mingxi Luo, Qiming Yang, Shuai Di, Song Wang, et al. Thousand-gpu large-scale training and optimization recipe for ai-native cloud embodied intelligence infrastructure.arXiv preprint arXiv:2603.11101,
-
[25]
All experiments in this section were conducted on a single node with 8 GPUs. We sweep Colocated versus Hybrid placement, the number of environment batches hosted per Simulator GPU, and which asynchronous features are enabled (rollout- side decoupling with dynamic batching, training-side streaming optimization, or both). Each value is an average over 5 tra...
work page 2048
-
[26]
combines very large vectorized environment counts with GPU-accelerated simulation. As shown in Table 2, we can set a very large environment batch size: up to 256 (2048/8) for colocated placement and 272 (3276/(6 ∗ 2)) for hybrid placement. Under colocated placement, it is interesting to see that the throughput of the synchronous baseline is already the be...
work page 2048
-
[27]
Therefore, we can set a larger total environment count (512 for colocated and 768 for hybrid)
is more parallelizable than LIBERO and RoboCasa. Therefore, we can set a larger total environment count (512 for colocated and 768 for hybrid). As shown in Table 5, Meta-World exhibits similar trends to LIBERO in colo- cated placement: the synchronous baseline does not benefit from splitting environments into multiple batches, but RL-VLA3 significantly im...
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.