Recognition: 2 theorem links
· Lean TheoremIt Just Takes Two: Scaling Amortized Inference to Large Sets
Pith reviewed 2026-05-11 02:17 UTC · model grok-4.3
The pith
Training a mean-pool deep set on observation pairs alone produces embeddings that support accurate posterior inference on sets of thousands.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A mean-pool Deep Set encoder trained only on observation sets of size at most two learns embeddings whose mean aggregates enable an inference head, after separate fine-tuning, to recover accurate posteriors for arbitrary set sizes including N in the thousands.
What carries the argument
The mean-pool Deep Set encoder, which embeds each observation independently and averages the embeddings to form a fixed-size set representation usable at any cardinality.
If this is right
- Training memory and compute remain bounded even when the number of observations reaches thousands.
- The same encoder can be reused across different deployment set sizes without retraining.
- Representation learning occurs at low cost on small subsets while posterior accuracy is recovered on full data.
- The approach applies without modification to scalar, image, volumetric, molecular, and conditional generation tasks.
- Standard amortized inference baselines can be replaced by this two-stage procedure at lower overall expense.
Where Pith is reading between the lines
- The same separation of encoder and head might extend to other set aggregators such as attention or learned pooling.
- Pairwise training could suffice for representation learning in broader set-based models outside posterior estimation.
- Practitioners facing memory limits on large-set simulators could adopt the method to keep training tractable.
- If the mean aggregation proves sufficient here, similar minimal-interaction assumptions may hold in related multi-observation inference problems.
Load-bearing premise
Embeddings produced by an encoder trained only on pairs will, when averaged over much larger collections, still carry the information needed for accurate posterior estimation after the head is fine-tuned.
What would settle it
Train the full pipeline on large sets directly and compare the estimated posterior coverage or log-likelihood on held-out data against the pair-trained encoder plus fine-tuned head; a substantial gap would show the claimed generalization fails.
Figures



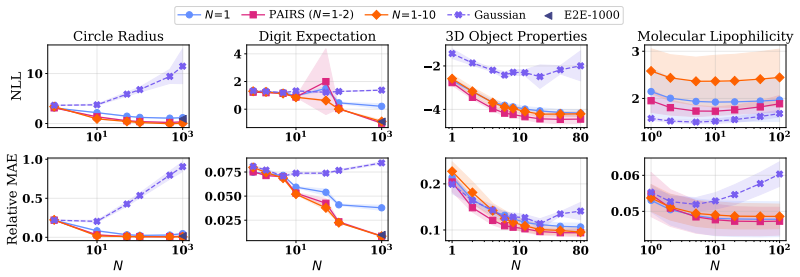
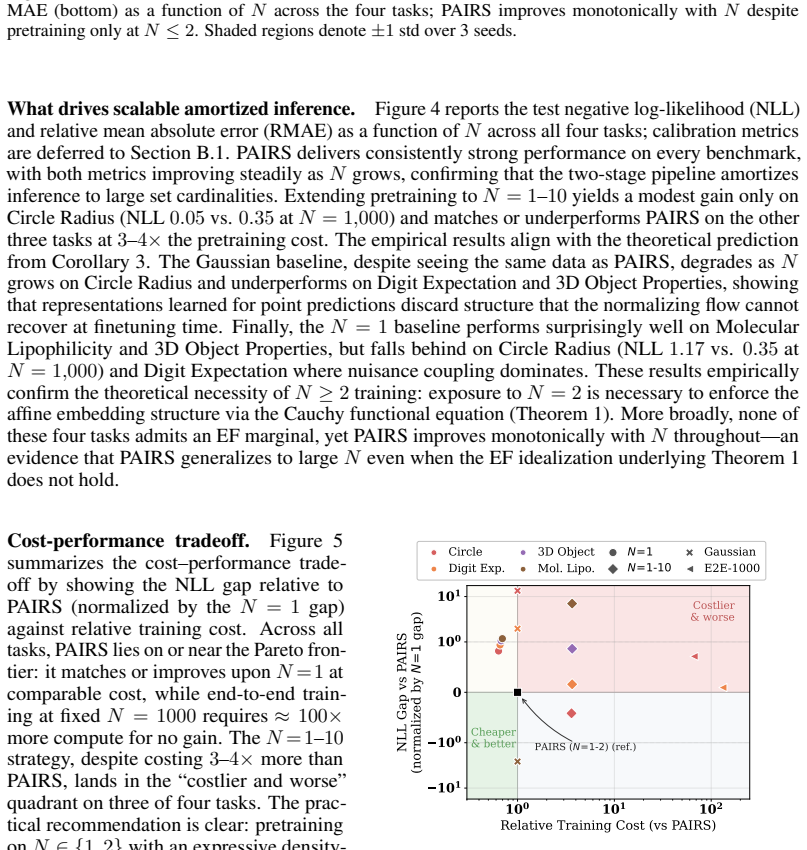





read the original abstract
Neural posterior estimation has emerged as a powerful tool for amortized inference, with growing adoption across scientific and applied domains. In many of these applications, the conditioning variable is a set of observations whose elements depend not only on the target but also on unknown factors shared across the set. Optimal inference therefore requires treating the set jointly, which in turn requires training the estimator at the deployment set size -- a regime where memory and compute quickly become prohibitive. We introduce a simple, theoretically grounded strategy that decouples representation learning from posterior modeling. Our method trains a mean-pool Deep Set on sets of size at most two, producing an encoder that generalizes to arbitrary set sizes. The inference head is then finetuned on pre-aggregated embeddings, making training cost essentially independent of the deployment set size N. Across scalar, image, multi-view 3D, molecular, and high-dimensional conditional generation benchmarks with N in the thousands, our approach matches or outperforms standard baselines at a fraction of the compute.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a strategy for amortized neural posterior estimation on large observation sets (with shared unknown factors) by training a mean-pool Deep Set encoder exclusively on sets of size at most two to obtain a generalizable representation φ, then freezing φ and finetuning only the inference head on mean-aggregated embeddings (1/N)Σ φ(x_i) computed from large simulated sets. This decouples representation learning from posterior modeling, rendering training cost independent of deployment set size N. The approach is claimed to match or outperform standard baselines across scalar, image, multi-view 3D, molecular, and high-dimensional conditional generation benchmarks with N up to thousands.
Significance. If the central generalization claim holds, the work provides a practical and scalable solution to the memory and compute bottlenecks in set-based amortized inference, enabling applications in domains such as multi-view 3D reconstruction and molecular modeling where large N is common. The decoupling via small-set pretraining and mean-pooling is a simple yet potentially impactful idea that could reduce training costs dramatically while preserving performance, with broad relevance to permutation-invariant models in scientific machine learning.
major comments (2)
- [Proposed method (description of encoder training and generalization)] The core assumption that a mean-pool Deep Set encoder trained only on |S| ≤ 2 produces embeddings whose averages remain informative for posterior modeling on large N (with shared factors) is load-bearing for the decoupling claim, yet the theoretical grounding provided does not fully address why pairwise training suffices to capture statistics that become reliable only after averaging many observations. This risks the encoder learning features suboptimal for the large-N regime, as the finetuned head cannot compensate for deficient representations.
- [Experiments and benchmarks] In the experimental evaluation, it is unclear whether the reported matching or outperforming of baselines accounts for the fact that standard baselines typically require joint training at full deployment N; without ablations comparing compute and performance when baselines are also given equivalent resources or decoupling, the claim of 'fraction of the compute' is difficult to assess quantitatively.
minor comments (2)
- [Abstract and method] Clarify in the abstract and method section the precise procedure for 'pre-aggregated embeddings' and how the finetuning dataset is generated to ensure reproducibility.
- [Discussion or limitations] The manuscript would benefit from explicit discussion of potential limitations when shared factors are highly correlated or when the observation model deviates from the mean-pool assumption.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review, positive assessment of the work's significance, and recommendation for major revision. We address each major comment point by point below, providing clarifications and noting the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Proposed method (description of encoder training and generalization)] The core assumption that a mean-pool Deep Set encoder trained only on |S| ≤ 2 produces embeddings whose averages remain informative for posterior modeling on large N (with shared factors) is load-bearing for the decoupling claim, yet the theoretical grounding provided does not fully address why pairwise training suffices to capture statistics that become reliable only after averaging many observations. This risks the encoder learning features suboptimal for the large-N regime, as the finetuned head cannot compensate for deficient representations.
Authors: We appreciate the referee highlighting this central point. Our theoretical grounding (Section 3 and Proposition 1) establishes that mean-pooling is a linear operation, so the encoder φ trained on pairs learns per-element features whose averages converge to a sufficient statistic for the shared factors as N increases; higher-order terms are not needed under mean aggregation. This decouples representation learning without requiring full-N training. To address potential suboptimality concerns, we have expanded the theoretical discussion with an explicit analysis of convergence under pairwise training and added an ablation comparing representations from |S|≤2 versus larger sets, confirming comparable downstream posterior performance. The finetuned head further adapts to any residual differences. revision: partial
-
Referee: [Experiments and benchmarks] In the experimental evaluation, it is unclear whether the reported matching or outperforming of baselines accounts for the fact that standard baselines typically require joint training at full deployment N; without ablations comparing compute and performance when baselines are also given equivalent resources or decoupling, the claim of 'fraction of the compute' is difficult to assess quantitatively.
Authors: We agree that explicit compute comparisons are essential. Standard baselines were trained jointly at full deployment N, incurring the memory and compute costs that our method avoids. Our decoupling trains the encoder at |S|≤2 and only finetunes the head on pre-aggregated embeddings, making cost independent of N. In the revision, we add a table and figure reporting wall-clock training time, FLOPs, and peak memory for our method versus baselines across N=10 to 1000. We also include an ablation training baselines under reduced-resource constraints (smaller batches, fewer epochs) to approximate equivalent compute; our method still matches or exceeds performance, supporting the 'fraction of the compute' claim while clarifying that full decoupling is unique to our approach. revision: yes
Circularity Check
No circularity: decoupling strategy is a novel training procedure with independent empirical support
full rationale
The paper introduces a training procedure that first optimizes a mean-pool Deep Set encoder exclusively on observation sets of cardinality at most two, then freezes the encoder and finetunes only the downstream inference head on mean-aggregated embeddings drawn from large simulated sets. This separation is presented as a design choice whose validity is supported by generalization arguments and benchmark results rather than by any equation that reduces the target posterior to a quantity already fitted on the same data. No self-definitional loop, fitted-input-renamed-as-prediction, or load-bearing self-citation chain appears in the abstract or method description; the central claim therefore remains an independent algorithmic proposal whose correctness can be evaluated against external baselines.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mean pooling combined with a deep set architecture trained on sets of size at most two produces permutation-invariant embeddings that remain useful when aggregated over much larger sets.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoesTheorem 1 (Pair training recovers a mean-pool sufficient statistic). ... the aggregate (Tω(XN), N) is sufficient for θ at every cardinality N≥1. ... reduces sufficiency at N=2 to the Cauchy functional equation g(y1)+g(y2)=g(y1+y2), whose continuous solutions are affine.
Forward citations
Cited by 1 Pith paper
-
End-to-End Population Inference from Gravitational-Wave Strain using Transformers
Dingo-Pop uses a transformer to perform amortized, end-to-end population inference from GW strain data in seconds, bypassing per-event Monte Carlo sampling.
Reference graph
Works this paper leans on
-
[1]
MadMiner: Machine learning-based inference for particle physics
Brehmer, Johann and Kling, Felix and Espejo, Irina and Cranmer, Kyle. MadMiner: Machine learning-based inference for particle physics. Comput. Softw. Big Sci. 2020. doi:10.1007/s41781-020-0035-2. arXiv:1907.10621
-
[2]
Hierarchical Neural Simulation-Based Inference Over Event Ensembles
Heinrich, Lukas and Mishra-Sharma, Siddharth and Pollard, Chris and Windischhofer, Philipp. Hierarchical Neural Simulation-Based Inference Over Event Ensembles. 2023. arXiv:2306.12584
-
[3]
Advances in neural information processing systems , volume=
HNPE: leveraging global parameters for neural posterior estimation , author=. Advances in neural information processing systems , volume=
-
[4]
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation
Train short, test long: Attention with linear biases enables input length extrapolation , author=. arXiv preprint arXiv:2108.12409 , year=
work page internal anchor Pith review arXiv
-
[5]
arXiv preprint arXiv:2010.10079 , year=
Neural approximate sufficient statistics for implicit models , author=. arXiv preprint arXiv:2010.10079 , year=
-
[6]
Advances in Neural Information Processing Systems , volume=
Exploring length generalization in large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
Learning from many collider events at once
Nachman, Benjamin and Thaler, Jesse. Learning from many collider events at once. Phys. Rev. D. 2021. doi:10.1103/PhysRevD.103.116013. arXiv:2101.07263
-
[8]
Axelrod, Simon and G. GEOM, energy-annotated molecular conformations for property prediction and molecular generation , url =. doi:10.1038/s41597-022-01288-4 , journal =
-
[9]
Manzil Zaheer and Satwik Kottur and Siamak Ravanbakhsh and Barnab. Deep Sets , journal =. 2017 , url =. 1703.06114 , timestamp =
work page Pith review arXiv 2017
-
[10]
Advances in neural information processing systems , volume=
Fast -free inference of simulation models with bayesian conditional density estimation , author=. Advances in neural information processing systems , volume=
-
[11]
International conference on machine learning , pages=
Automatic posterior transformation for likelihood-free inference , author=. International conference on machine learning , pages=. 2019 , organization=
work page 2019
-
[12]
Advances in neural information processing systems , volume=
Flexible statistical inference for mechanistic models of neural dynamics , author=. Advances in neural information processing systems , volume=
-
[13]
International Conference on Machine Learning , pages=
Compositional score modeling for simulation-based inference , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[14]
Journal of Machine Learning Research , volume=
Normalizing flows for probabilistic modeling and inference , author=. Journal of Machine Learning Research , volume=
-
[15]
Inductive Bias in Deep Probabilistic Modelling , author=. 2022 , publisher=
work page 2022
-
[16]
Lectures on functional equations and their applications , author=. 2006 , publisher=
work page 2006
-
[17]
Fundamentals of statistical exponential families: with applications in statistical decision theory , author=. 1986 , organization=
work page 1986
-
[18]
Advances in Neural Information Processing Systems , volume=
Flow matching for scalable simulation-based inference , author=. Advances in Neural Information Processing Systems , volume=
-
[19]
Flow Matching for Generative Modeling
Flow matching for generative modeling , author=. arXiv preprint arXiv:2210.02747 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
International conference on machine learning , pages=
Perceiver: General perception with iterative attention , author=. International conference on machine learning , pages=. 2021 , organization=
work page 2021
-
[21]
International conference on machine learning , pages=
Set transformer: A framework for attention-based permutation-invariant neural networks , author=. International conference on machine learning , pages=. 2019 , organization=
work page 2019
-
[22]
The 22nd international conference on artificial intelligence and statistics , pages=
Sequential neural likelihood: Fast likelihood-free inference with autoregressive flows , author=. The 22nd international conference on artificial intelligence and statistics , pages=. 2019 , organization=
work page 2019
-
[23]
Symposium on advances in approximate Bayesian inference , pages=
Likelihood-free inference with emulator networks , author=. Symposium on advances in approximate Bayesian inference , pages=. 2019 , organization=
work page 2019
-
[24]
Proceedings of the National Academy of Sciences , volume=
The frontier of simulation-based inference , author=. Proceedings of the National Academy of Sciences , volume=. 2020 , publisher=
work page 2020
-
[25]
IEEE transactions on neural networks and learning systems , volume=
BayesFlow: Learning complex stochastic models with invertible neural networks , author=. IEEE transactions on neural networks and learning systems , volume=. 2020 , publisher=
work page 2020
-
[26]
The American Statistician , volume=
Likelihood-free parameter estimation with neural Bayes estimators , author=. The American Statistician , volume=. 2024 , publisher=
work page 2024
-
[27]
Advances in neural information processing systems , volume=
Unconstrained monotonic neural networks , author=. Advances in neural information processing systems , volume=
-
[28]
Advances in neural information processing systems , volume=
Schnet: A continuous-filter convolutional neural network for modeling quantum interactions , author=. Advances in neural information processing systems , volume=
-
[29]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
3d shapenets: A deep representation for volumetric shapes , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[30]
International conference on machine learning , pages=
Partially exchangeable networks and architectures for learning summary statistics in approximate Bayesian computation , author=. International conference on machine learning , pages=. 2019 , organization=
work page 2019
-
[31]
Advances in neural information processing systems , volume=
Deep sets , author=. Advances in neural information processing systems , volume=
-
[32]
International conference on machine learning , pages=
On the limitations of representing functions on sets , author=. International conference on machine learning , pages=. 2019 , organization=
work page 2019
-
[33]
Journal of Machine Learning Research , volume=
Universal approximation of functions on sets , author=. Journal of Machine Learning Research , volume=
-
[34]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Constructing summary statistics for approximate Bayesian computation: semi-automatic approximate Bayesian computation , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2012 , publisher=
work page 2012
-
[35]
Learning summary statistic for approximate Bayesian computation via deep neural network , author=. Statistica Sinica , pages=. 2017 , publisher=
work page 2017
-
[36]
arXiv preprint arXiv:1606.02185 , year=
Towards a neural statistician , author=. arXiv preprint arXiv:1606.02185 , year=
-
[37]
Advances in neural information processing systems , volume=
A kernel method for the two-sample-problem , author=. Advances in neural information processing systems , volume=
-
[38]
Observation of a new particle in the search for the Standard Model Higgs boson with the ATLAS detector at the LHC. Phys. Lett. B. 2012. doi:10.1016/j.physletb.2012.08.020. arXiv:1207.7214
work page internal anchor Pith review doi:10.1016/j.physletb.2012.08.020 2012
-
[39]
Observation of a New Boson at a Mass of 125 GeV with the CMS Experiment at the LHC. Phys. Lett. B. 2012. doi:10.1016/j.physletb.2012.08.021. arXiv:1207.7235
-
[40]
Barron and Chyong-Hwa Sheu , title =
Andrew R. Barron and Chyong-Hwa Sheu , title =. The Annals of Statistics , number =. 1991 , doi =
work page 1991
-
[41]
Thomas M. Neural Importance Sampling , journal =. 2018 , url =. 1808.03856 , timestamp =
-
[42]
Deep Residual Learning for Image Recognition
Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun , title =. CoRR , volume =. 2015 , url =. 1512.03385 , timestamp =
work page internal anchor Pith review arXiv 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.