Recognition: no theorem link
End-to-End Population Inference from Gravitational-Wave Strain using Transformers
Pith reviewed 2026-05-13 01:57 UTC · model grok-4.3
The pith
Dingo-Pop uses a transformer to infer compact-binary population properties directly from gravitational-wave strain data in one second.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
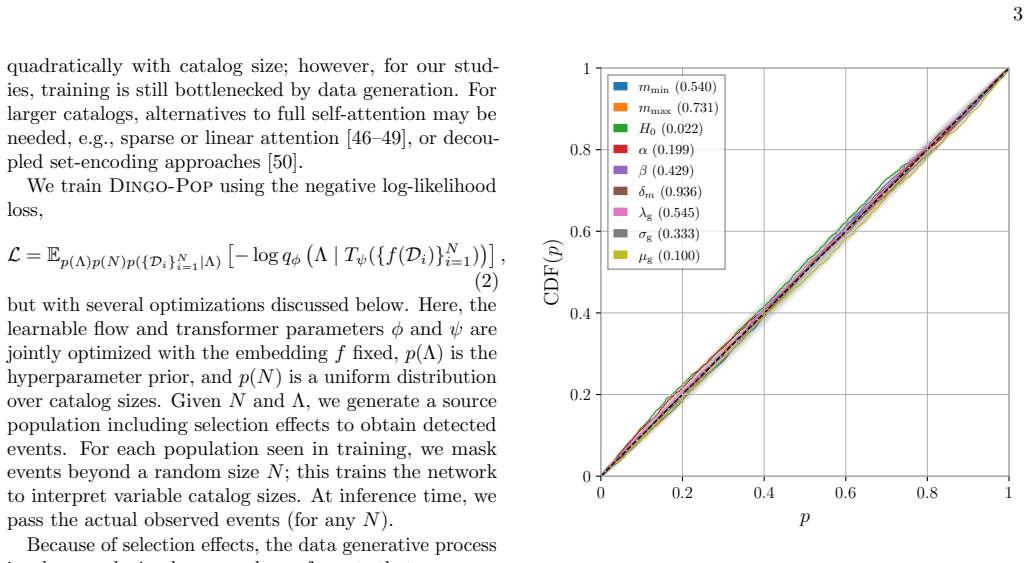
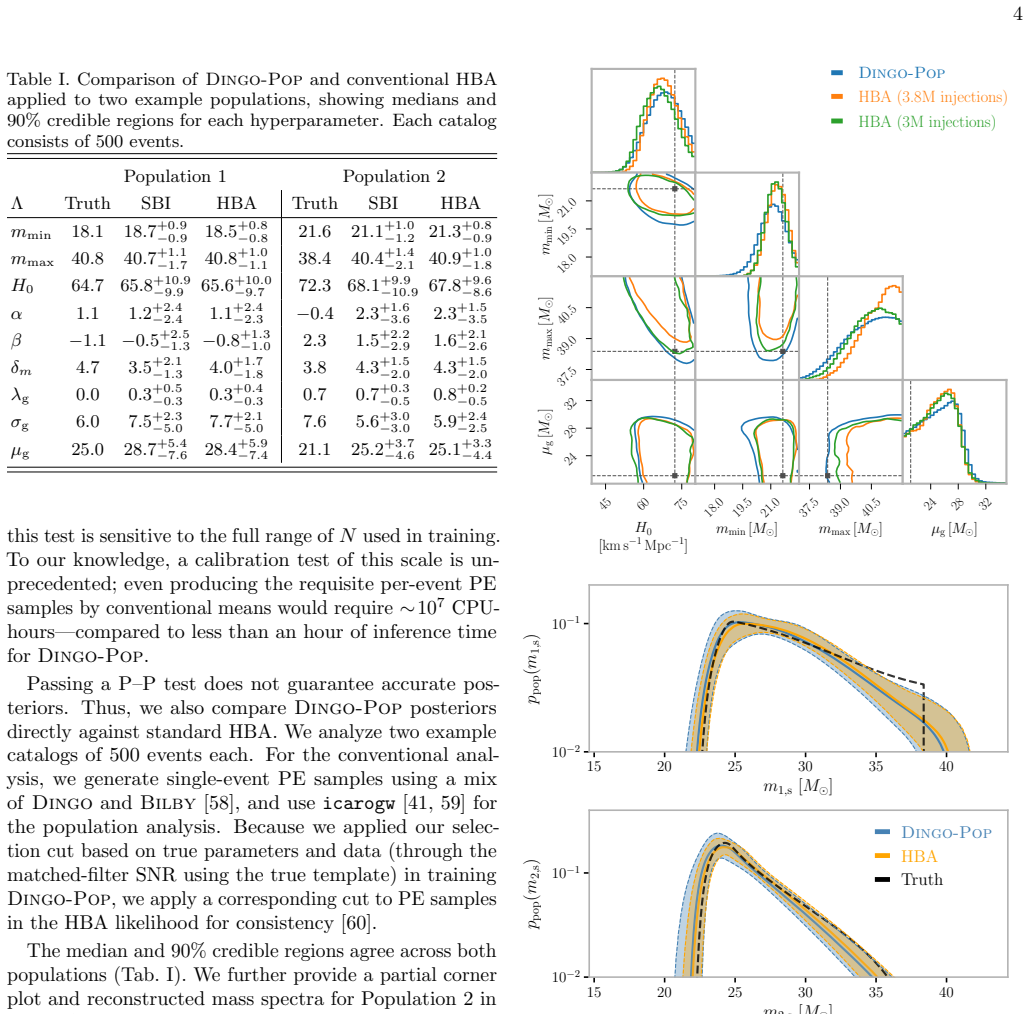
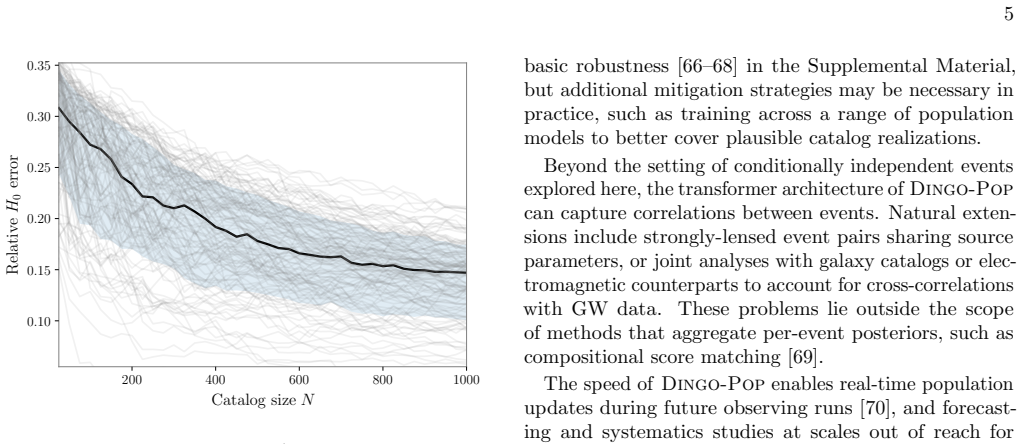
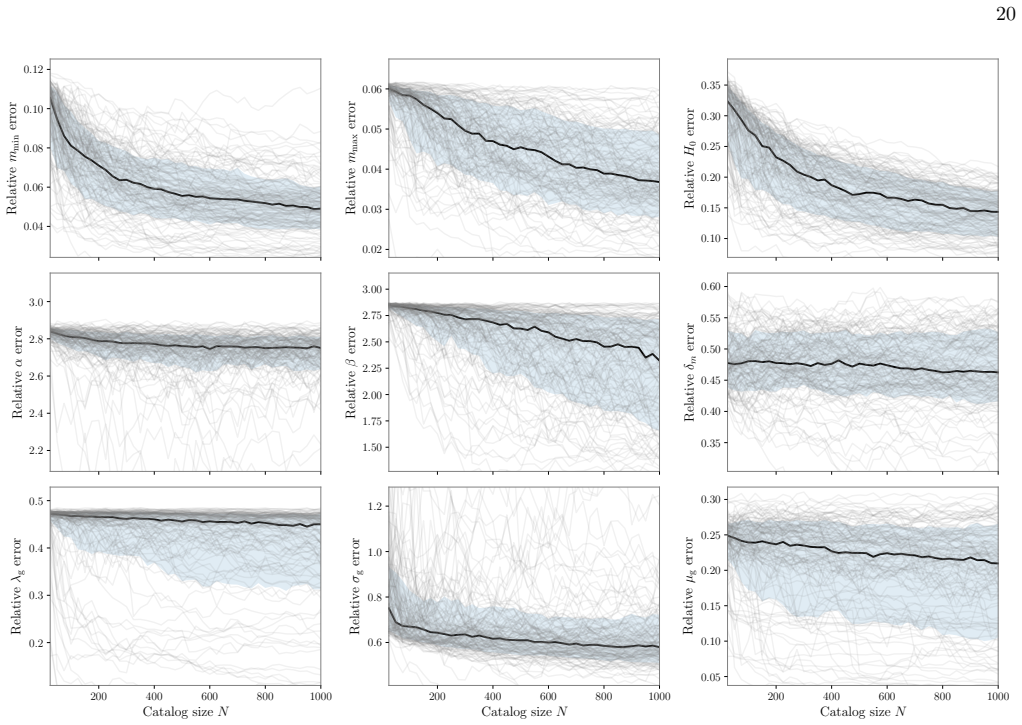
Dingo-Pop is a simulation-based inference framework that directly maps gravitational-wave strain data from catalogs of 25 to 1000 events to population posteriors using a transformer architecture. Data from each event are embedded into low-dimensional tokens and combined via the transformer trained on simulated catalogs subject to selection effects. This produces well-calibrated posteriors in about one second without per-event Monte Carlo sampling noise and matches results from traditional hierarchical Bayesian methods while supporting new classes of large-scale studies, such as examining how spectral-siren Hubble constant uncertainties scale with catalog size.
What carries the argument
A transformer network that ingests sequences of embedded gravitational-wave strain tokens from catalogs of variable size and, after training on simulations that incorporate selection effects, directly outputs population posterior distributions.
If this is right
- Population inference proceeds without Monte Carlo sampling noise from individual-event analyses.
- A single trained network handles catalogs ranging from 25 to 1000 events without retraining.
- End-to-end inference completes in approximately one second per catalog.
- Posteriors remain well-calibrated and agree with those from traditional hierarchical methods.
- New large-scale injection studies become feasible, including direct tests of how spectral-siren Hubble-constant uncertainties decrease with growing catalog size.
Where Pith is reading between the lines
- Real-time population updates could become routine once new events are detected in future observing runs.
- The method might eventually reduce reliance on detailed per-event parameter estimation when the primary goal is population inference.
- Similar token-embedding and transformer pipelines could be tested on other hierarchical inference tasks that combine noisy individual measurements into global parameters.
Load-bearing premise
A network trained only on simulated catalogs with modeled noise and selection effects will still produce accurate posteriors when applied to real gravitational-wave data whose noise properties and selection function may differ from the training distribution.
What would settle it
Apply Dingo-Pop to a set of real LIGO-Virgo strain events and compare the resulting population posterior against the posterior obtained from standard hierarchical inference on the same events; a statistically significant discrepancy in any population parameter would falsify the claim of consistency.
Figures


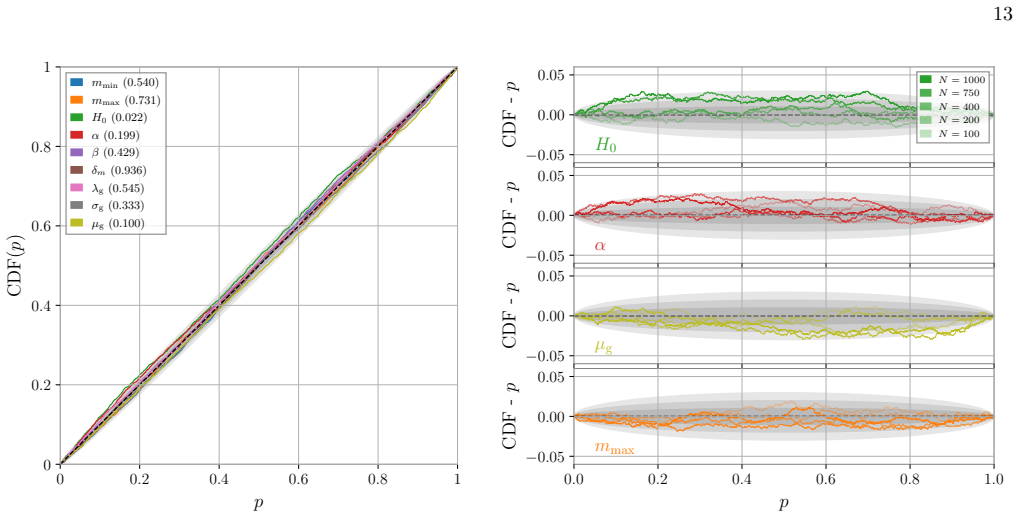
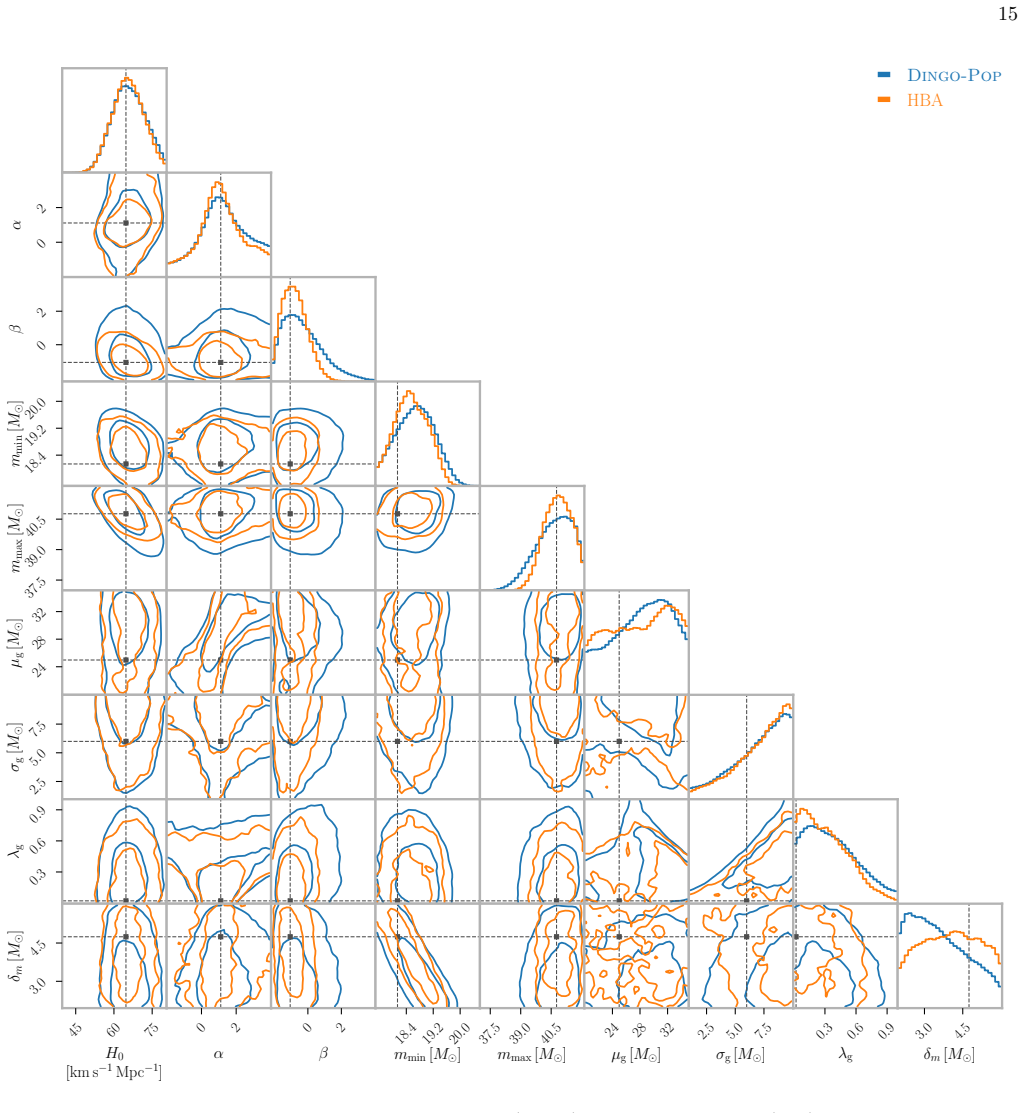
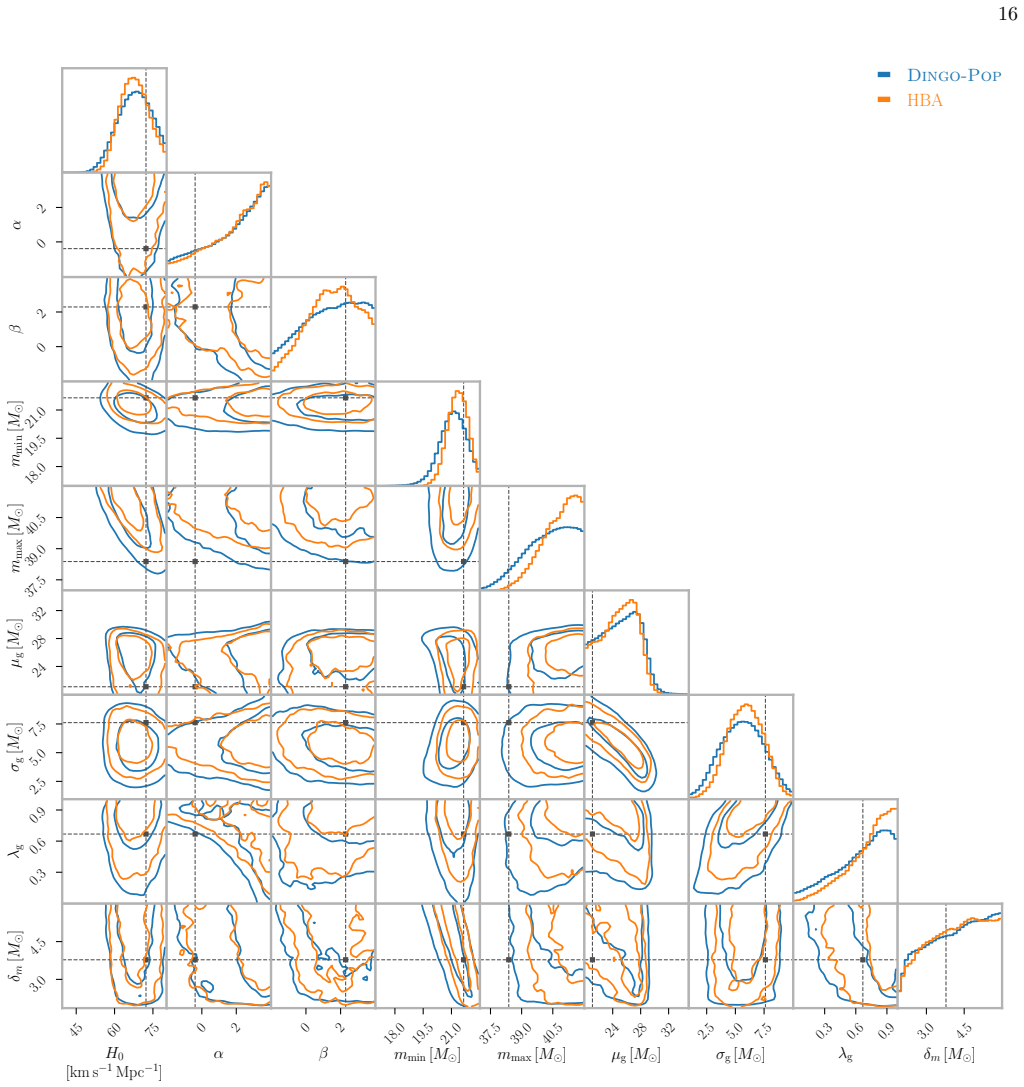


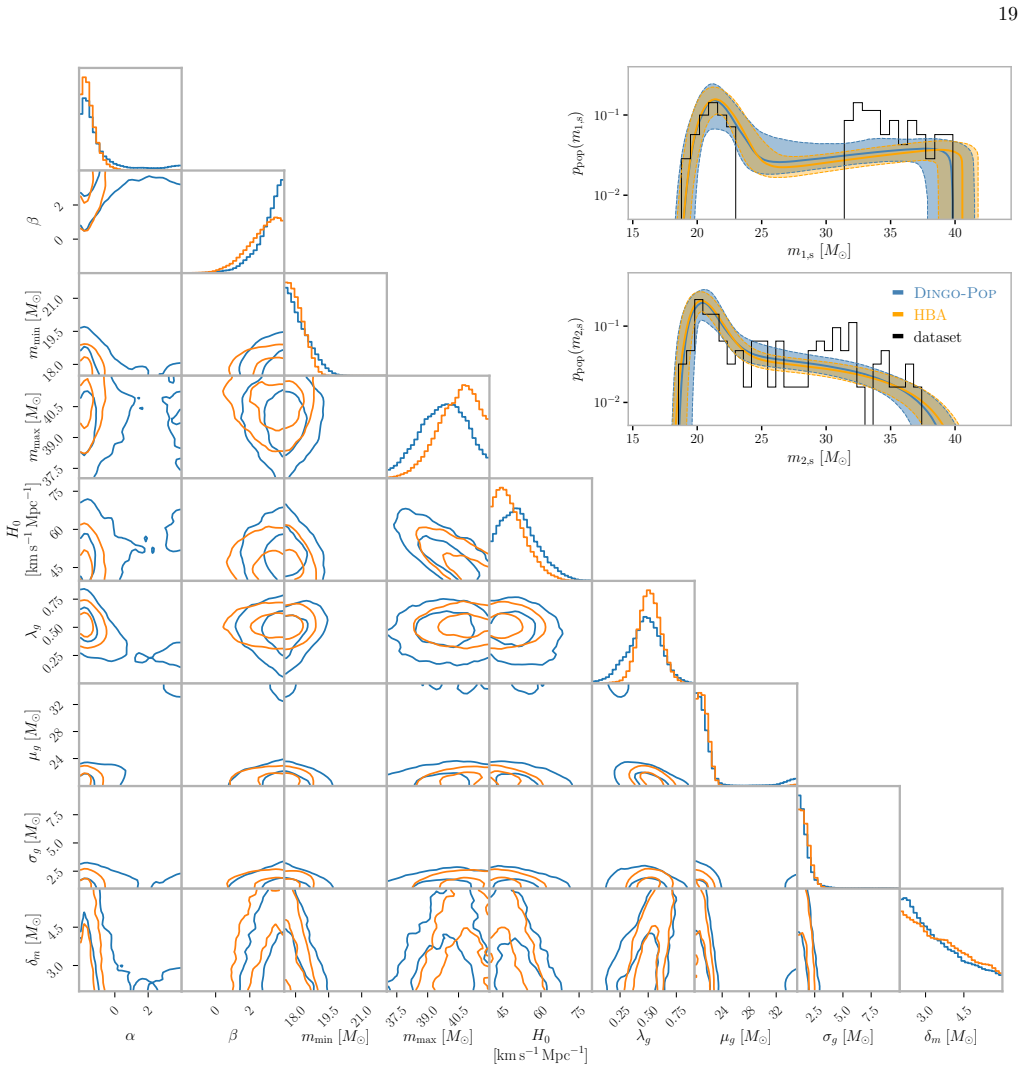
read the original abstract
The population of compact binaries encodes information about their astrophysical origins and the expansion of the universe. Hierarchical Bayesian methods infer these properties by combining single-event posteriors. As catalogs grow, however, this approach becomes computationally expensive and is subject to increasing Monte Carlo uncertainty. We introduce Dingo-Pop, a simulation-based framework that infers population posteriors directly from gravitational-wave strain data. The data for each event are embedded into low-dimensional tokens and combined using a transformer trained on simulated catalogs subject to selection effects. This enables (i) population inference without per-event Monte Carlo sampling noise, (ii) amortization across variable catalog sizes using a single network, and (iii) end-to-end inference in about one second. We train a network for catalog sizes of 25 to 1000 events, and obtain well-calibrated posteriors consistent with traditional methods. By avoiding per-event analyses that can take hours to days, Dingo-Pop enables new classes of large-scale injection studies; as an application, we examine how spectral-siren Hubble constant uncertainties change with catalog size.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Dingo-Pop, a simulation-based inference framework that uses a transformer to infer population-level posteriors for compact binary mergers directly from gravitational-wave strain data. Events are embedded as tokens and aggregated by the network, which is trained exclusively on simulated catalogs that include selection effects. The method is claimed to eliminate per-event Monte Carlo sampling noise, amortize inference across variable catalog sizes (25–1000 events) with a single network, deliver end-to-end results in ~1 s, and produce well-calibrated posteriors consistent with traditional hierarchical Bayesian analyses. An application examining spectral-siren Hubble-constant uncertainties as a function of catalog size is presented.
Significance. If the central claims hold under real-data conditions, the approach would substantially lower the computational barrier to population inference for the large catalogs expected from future observing runs, enabling previously intractable injection campaigns and rapid re-analyses. The amortization property and removal of per-event sampling noise are particularly valuable strengths.
major comments (3)
- [Abstract] Abstract: the statement that the posteriors are 'well-calibrated' and 'consistent with traditional methods' is presented without any quantitative metrics (coverage probabilities, bias or variance comparisons, KL divergences, or calibration plots). This is load-bearing for the central reliability claim.
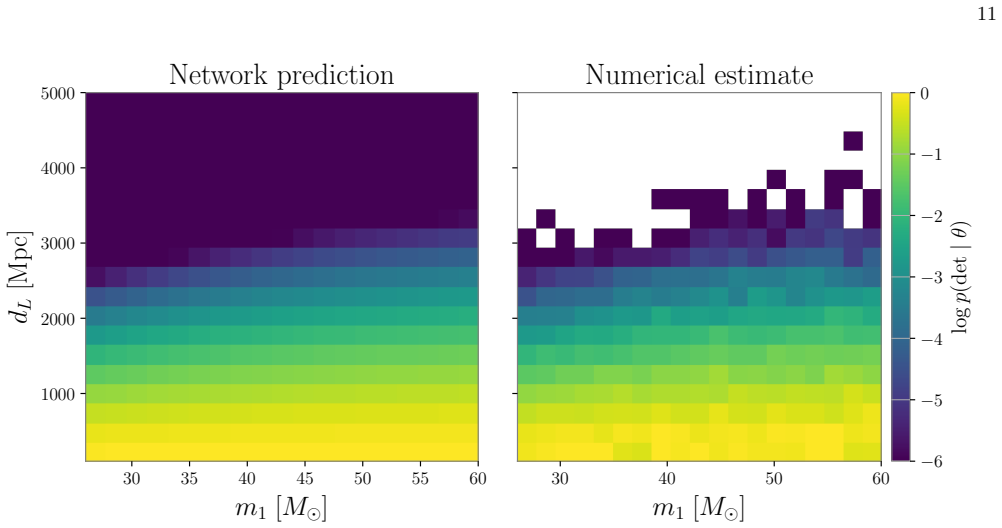
- [Abstract] Abstract: selection effects are stated to be incorporated during training, yet no description is given of the specific selection function, how it is sampled, or how the network is shown to recover unbiased population parameters when selection is present. This directly affects the validity of end-to-end inference from strain data.
- [Abstract] Abstract / method description: the network is trained exclusively on simulated catalogs; no tests for robustness to mismatches between simulated and real LIGO/Virgo noise (non-stationary glitches, calibration errors) or selection-function deviations are reported. Because the architecture produces population posteriors without intermediate per-event diagnostics, any domain shift propagates directly to the final result.
minor comments (1)
- [Abstract] The abstract would be clearer if it briefly indicated the range of population parameters (e.g., mass, spin, redshift distributions) and the transformer architecture (number of layers, attention heads, embedding dimension).
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed report. We address each major comment point by point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statement that the posteriors are 'well-calibrated' and 'consistent with traditional methods' is presented without any quantitative metrics (coverage probabilities, bias or variance comparisons, KL divergences, or calibration plots). This is load-bearing for the central reliability claim.
Authors: We agree that the abstract would benefit from explicit quantitative support for the calibration claim. The main text already contains calibration plots (showing empirical coverage probabilities for 68% and 95% intervals) and direct comparisons of posterior summaries to traditional hierarchical Bayesian results on the same simulated catalogs. To address the concern, we will revise the abstract to include a concise statement such as 'yielding well-calibrated posteriors with coverage probabilities consistent with nominal levels and in agreement with traditional methods.' revision: yes
-
Referee: [Abstract] Abstract: selection effects are stated to be incorporated during training, yet no description is given of the specific selection function, how it is sampled, or how the network is shown to recover unbiased population parameters when selection is present. This directly affects the validity of end-to-end inference from strain data.
Authors: The Methods section specifies the selection function as an SNR-threshold-based detection probability drawn from standard LIGO/Virgo sensitivity curves, with catalogs generated by sampling the population model and retaining only detectable events. Recovery of unbiased parameters under selection is shown via direct comparison of inferred hyperparameters to injected values and to conventional hierarchical analyses on identical selected catalogs. We will add a brief clause to the abstract: 'trained on simulated catalogs that incorporate selection effects via an SNR-based detection threshold.' revision: yes
-
Referee: [Abstract] Abstract / method description: the network is trained exclusively on simulated catalogs; no tests for robustness to mismatches between simulated and real LIGO/Virgo noise (non-stationary glitches, calibration errors) or selection-function deviations are reported. Because the architecture produces population posteriors without intermediate per-event diagnostics, any domain shift propagates directly to the final result.
Authors: The work is deliberately scoped to controlled simulation-based validation with realistic but stationary noise models. No explicit robustness tests against non-stationary glitches or calibration errors are included. We will add a dedicated paragraph in the Discussion section acknowledging this as a current limitation and outlining future directions such as domain-adversarial training or fine-tuning on real-data injections. revision: partial
Circularity Check
No circularity: training on independent simulations yields independent population inference
full rationale
The paper trains a transformer on simulated catalogs that embed selection effects and then applies the network to produce population posteriors from strain data. This is a standard simulation-based inference setup where the network learns a mapping from data to parameters; the output on new inputs is not forced by construction to match any fitted quantity from the target data. Validation consists of calibration checks and consistency with traditional per-event PE plus hierarchical inference, both performed on held-out simulations whose ground-truth population parameters are known independently of the network weights. No self-definitional equations, fitted-input predictions, or load-bearing self-citations appear in the derivation chain. The method therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
A. G. Abacet al.(LIGO Scientific, VIRGO, KAGRA), GWTC-4.0: Updating the Gravitational-Wave Transient Catalog with Observations from the First Part of the Fourth LIGO-Virgo-KAGRA Observing Run, (2025), arXiv:2508.18082 [gr-qc]. 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
J. Aasiet al.(LIGO Scientific), Advanced LIGO, Class. Quant. Grav.32, 074001 (2015), arXiv:1411.4547 [gr-qc]
work page internal anchor Pith review arXiv 2015
-
[4]
Advanced Virgo: a 2nd generation interferometric gravitational wave detector
F. Acerneseet al.(VIRGO), Advanced Virgo: a second- generation interferometric gravitational wave detector, Class. Quant. Grav.32, 024001 (2015), arXiv:1408.3978 [gr-qc]
work page internal anchor Pith review arXiv 2015
-
[5]
T. Akutsuet al.(KAGRA), Overview of KAGRA: Detec- tor design and construction history, PTEP2021, 05A101 (2021), arXiv:2005.05574 [physics.ins-det]
-
[6]
A. G. Abacet al.(LIGO Scientific, VIRGO, KAGRA), GWTC-4.0: Population Properties of Merging Compact Binaries, (2025), arXiv:2508.18083 [astro-ph.HE]
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Tests of General Relativity with GWTC-3
R. Abbottet al.(LIGO Scientific, VIRGO, KAGRA), Tests of General Relativity with GWTC-3, (2021), arXiv:2112.06861 [gr-qc]
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [8]
- [9]
-
[10]
R. Essick and W. Farr, Precision Requirements for Monte Carlo Sums within Hierarchical Bayesian Infer- ence, (2022), arXiv:2204.00461 [astro-ph.IM]
-
[11]
C. Talbot and J. Golomb, Growing pains: understand- ing the impact of likelihood uncertainty on hierarchical Bayesian inference for gravitational-wave astronomy, Mon. Not. Roy. Astron. Soc.526, 3495 (2023), arXiv:2304.06138 [astro-ph.IM]
-
[12]
J. Heinzel and S. Vitale, When (not) to trust Monte Carlo approximations for hierarchical Bayesian inference, (2025), arXiv:2509.07221 [astro-ph.HE]
-
[13]
M. Branchesiet al., Science with the Einstein Tele- scope: a comparison of different designs, JCAP07, 068, arXiv:2303.15923 [gr-qc]
-
[14]
Cosmic Explorer: The U.S. Contribution to Gravitational-Wave Astronomy beyond LIGO
D. Reitzeet al., Cosmic Explorer: The U.S. Contribution to Gravitational-Wave Astronomy beyond LIGO, Bull. Am. Astron. Soc.51, 035 (2019), arXiv:1907.04833 [astro- ph.IM]
work page internal anchor Pith review Pith/arXiv arXiv 2019
- [15]
-
[16]
M. Fishbach, D. E. Holz, and W. M. Farr, Does the Black Hole Merger Rate Evolve with Redshift?, Astrophys. J. Lett.863, L41 (2018), arXiv:1805.10270 [astro-ph.HE]
-
[17]
Inferring the properties of a population of compact binaries in presence of selection effects
S. Vitale, D. Gerosa, W. M. Farr, and S. R. Taylor, Infer- ring the properties of a population of compact binaries in presence of selection effects 10.1007/978-981-15-4702- 7 45-1 (2020), arXiv:2007.05579 [astro-ph.IM]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/978-981-15-4702- 2020
-
[18]
Talbotet al., Inference with finite time series: II
C. Talbotet al., Inference with finite time series: II. The window strikes back, Class. Quant. Grav.42, 235023 (2025), arXiv:2508.11091 [gr-qc]
-
[19]
R. Essicket al., Compact binary coalescence sensitivity estimates with injection campaigns during the LIGO- Virgo-KAGRA Collaborations’ fourth observing run, Phys. Rev. D112, 102001 (2025), arXiv:2508.10638 [gr-qc]
-
[20]
V. Tiwari, Estimation of the Sensitive Volume for Gravitational-wave Source Populations Using Weighted Monte Carlo Integration, Class. Quant. Grav.35, 145009 (2018), arXiv:1712.00482 [astro-ph.HE]
- [21]
- [22]
-
[23]
M. Zevin, S. S. Bavera, C. P. L. Berry, V. Kalogera, T. Fragos, P. Marchant, C. L. Rodriguez, F. Antonini, D. E. Holz, and C. Pankow, One Channel to Rule Them All? Constraining the Origins of Binary Black Holes Using Multiple Formation Pathways, Astrophys. J.910, 152 (2021), arXiv:2011.10057 [astro-ph.HE]
-
[24]
K. W. K. Wong, K. Breivik, K. Kremer, and T. Callis- ter, Joint constraints on the field-cluster mixing fraction, common envelope efficiency, and globular cluster radii from a population of binary hole mergers via deep learn- ing, Phys. Rev. D103, 083021 (2021), arXiv:2011.03564 [astro-ph.HE]
- [25]
-
[26]
S. Colloms, C. P. L. Berry, J. Veitch, and M. Zevin, Exploring the Evolution of Gravitational-wave Emitters with Efficient Emulation: Constraining the Origins of Binary Black Holes Using Normalizing Flows, Astrophys. J.988, 189 (2025), arXiv:2503.03819 [astro-ph.HE]
-
[27]
C. Plunkett, M. Mould, and S. Vitale, Constraining Pop- ulation III stellar demographics with next-generation gravitational-wave observatories, Phys. Rev. D112, 023039 (2025), arXiv:2504.18615 [gr-qc]
- [28]
-
[29]
G. Papamakarios, E. Nalisnick, D. J. Rezende, S. Mo- hamed, and B. Lakshminarayanan, Normalizing Flows for Probabilistic Modeling and Inference, J. Machine Learn- ing Res.22, 2617 (2021), arXiv:1912.02762 [stat.ML]
-
[30]
J.-M. Lueckmann, P. J. Gon¸ calves, G. Bassetto, K.¨Ocal, M. Nonnenmacher, and J. H. Macke, Flexible statistical inference for mechanistic models of neural dynamics, in Proceedings of the 31st International Conference on Neu- ral Information Processing Systems(2017) pp. 1289–1299
work page 2017
-
[31]
D. Greenberg, M. Nonnenmacher, and J. Macke, Auto- matic posterior transformation for likelihood-free infer- ence, inInternational Conference on Machine Learning (PMLR, 2019) pp. 2404–2414
work page 2019
-
[32]
K. Cranmer, J. Brehmer, and G. Louppe, The frontier of simulation-based inference, Proc. Nat. Acad. Sci.117, 30055 (2020), arXiv:1911.01429 [stat.ML]
- [33]
-
[34]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, Attention Is All You Need, arXiv e-prints , arXiv:1706.03762 (2017), arXiv:1706.03762 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[35]
PyTorch: An Imperative Style, High-Performance Deep Learning Library
A. Paszkeet al., PyTorch: An Imperative Style, High-Performance Deep Learning Library, (2019), arXiv:1912.01703 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[36]
M. Gloeckler, M. Deistler, C. Weilbach, F. Wood, and 7 J. H. Macke, All-in-one simulation-based inference, arXiv preprint arXiv:2404.09636 (2024)
-
[37]
J.-Q. Jiang, H.-L. Huang, J. He, Y.-T. Wang, and Y.-S. Piao, A fast deep-learning approach to probing primor- dial black hole populations in gravitational wave events, (2025), arXiv:2505.15530 [gr-qc]
-
[38]
C. Talbot and E. Thrane, Measuring the binary black hole mass spectrum with an astrophysically moti- vated parameterization, Astrophys. J.856, 173 (2018), arXiv:1801.02699 [astro-ph.HE]
- [39]
- [40]
-
[41]
S. Mastrogiovanni, K. Leyde, C. Karathanasis, E. Chassande-Mottin, D. A. Steer, J. Gair, A. Ghosh, R. Gray, S. Mukherjee, and S. Rinaldi, On the importance of source population models for gravitational-wave cosmol- ogy, Phys. Rev. D104, 062009 (2021), arXiv:2103.14663 [gr-qc]
- [42]
-
[43]
J. Lee, Y. Lee, J. Kim, A. Kosiorek, S. Choi, and Y. W. Teh, Set transformer: A framework for attention-based permutation-invariant neural networks, inInternational conference on machine learning(PMLR, 2019) pp. 3744– 3753
work page 2019
-
[44]
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, BERT: Pre-training of deep bidirectional transformers for language understanding, inProceedings of the 2019 Conference of the North American Chapter of the Asso- ciation for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), edited by J. Burstein, C. Doran, and T. Sol...
work page 2019
- [45]
-
[46]
A. Katharopoulos, A. Vyas, N. Pappas, and F. Fleuret, Transformers are rnns: Fast autoregressive transform- ers with linear attention, inInternational conference on machine learning(PMLR, 2020) pp. 5156–5165
work page 2020
- [47]
-
[48]
Generating Long Sequences with Sparse Transformers
R. Child, S. Gray, A. Radford, and I. Sutskever, Gen- erating long sequences with sparse transformers (2019), arXiv:1904.10509 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[49]
Longformer: The Long-Document Transformer
I. Beltagy, M. E. Peters, and A. Cohan, Long- former: The long-document transformer, arXiv preprint arXiv:2004.05150 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[50]
It Just Takes Two: Scaling Amortized Inference to Large Sets
A. Wehenkel, M. Kagan, L. Heinrich, and C. Pollard, It just takes two: Scaling amortized inference to large sets (2026), arXiv:2605.07972 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[51]
R. Abbottet al.(LIGO Scientific, Virgo,, KAGRA, VIRGO), Constraints on the Cosmic Expansion His- tory from GWTC–3, Astrophys. J.949, 76 (2023), arXiv:2111.03604 [astro-ph.CO]
-
[52]
G. Prattenet al., Computationally efficient models for the dominant and subdominant harmonic modes of precessing binary black holes, Phys. Rev. D103, 104056 (2021), arXiv:2004.06503 [gr-qc]
work page internal anchor Pith review arXiv 2021
-
[53]
A. Ramos-Buades, A. Buonanno, H. Estell´ es, M. Khalil, D. P. Mihaylov, S. Ossokine, L. Pompili, and M. Shiferaw, Next generation of accurate and efficient multipo- lar precessing-spin effective-one-body waveforms for bi- nary black holes, Phys. Rev. D108, 124037 (2023), arXiv:2303.18046 [gr-qc]
-
[54]
A. Buikemaet al.(aLIGO), Sensitivity and performance of the Advanced LIGO detectors in the third observing run, Phys. Rev. D102, 062003 (2020), arXiv:2008.01301 [astro-ph.IM]
-
[55]
M. Tseet al., Quantum-Enhanced Advanced LIGO Detec- tors in the Era of Gravitational-Wave Astronomy, Phys. Rev. Lett.123, 231107 (2019)
work page 2019
-
[56]
R. Abbottet al.(KAGRA, VIRGO, LIGO Scientific), GWTC-3: Compact Binary Coalescences Observed by LIGO and Virgo during the Second Part of the Third Observing Run, Phys. Rev. X13, 041039 (2023), arXiv:2111.03606 [gr-qc]
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [57]
-
[58]
Bilby: A user-friendly Bayesian inference library for gravitational-wave astronomy
G. Ashton, M. H¨ ubner, P. D. Lasky, C. Talbot, K. Ackley, S. Biscoveanu, Q. Chu, A. Divakarla, P. J. Easter, B. Gon- charov, and et al., BILBY: A User-friendly Bayesian In- ference Library for Gravitational-wave Astronomy, Astro- phys. J. Suppl.241, 27 (2019), arXiv:1811.02042 [astro- ph.IM]
work page internal anchor Pith review arXiv 2019
-
[59]
S. Mastrogiovanni, D. Laghi, R. Gray, G. C. Santoro, A. Ghosh, C. Karathanasis, K. Leyde, D. A. Steer, S. Per- ries, and G. Pierra, Joint population and cosmological properties inference with gravitational waves standard sirens and galaxy surveys, Phys. Rev. D108, 042002 (2023), arXiv:2305.10488 [astro-ph.CO]
-
[60]
R. Essick and M. Fishbach, Ensuring Consistency between Noise and Detection in Hierarchical Bayesian Inference, Astrophys. J.962, 169 (2024), arXiv:2310.02017 [gr-qc]
-
[61]
C. Talbot and E. Thrane, Flexible and Accurate Evalua- tion of Gravitational-wave Malmquist Bias with Machine Learning, Astrophys. J.927, 76 (2022), arXiv:2012.01317 [gr-qc]
- [62]
- [63]
-
[64]
A. Lorenzo-Medina and T. Dent, A physically modelled se- lection function for compact binary mergers in the LIGO- Virgo O3 run and beyond, Class. Quant. Grav.42, 045008 (2025), arXiv:2408.13383 [gr-qc]
- [65]
- [66]
-
[67]
M. Schmitt, P.-C. B¨ urkner, U. K¨ othe, and S. T. Radev, Detecting model misspecification in amortized bayesian in- 8 ference with neural networks, inDagm german conference on pattern recognition(Springer, 2023) pp. 541–557
work page 2023
-
[68]
A. Wehenkel, J. L. Gamella, O. Sener, J. Behrmann, G. Sapiro, J.-H. Jacobsen, and M. Cuturi, Addressing misspecification in simulation-based inference through data-driven calibration, arXiv preprint arXiv:2405.08719 (2024)
-
[69]
T. Geffner, G. Papamakarios, and A. Mnih, Composi- tional score modeling for simulation-based inference, in International Conference on Machine Learning(PMLR,
-
[70]
N. E. Wolfe, M. Mould, J. Veitch, and S. Vitale, Neural Bayesian updates to populations with grow- ing gravitational-wave catalogs, arXiv:2602.20277 [astro- ph.IM] (2026). 9 Supplemental Material PRIOR DISTRIBUTIONS TheDingo-Popframework involves two levels of prior distributions: (1) the single-event priors used to train the underlyingDingoembedding netw...
-
[71]
for population NPE. The model has four components: a tokenizer, a transformer encoder, a final feedforward network, and a normalizing flow that estimates the hyper- parameter posterior. The architectures ofDingo-Pop and its two auxiliary networks are detailed in Tab. IV. The neural networks are implemented inPyTorch[ 35], with layer normalization (rather ...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.