Recognition: no theorem link
Dooly: Configuration-Agnostic, Redundancy-Aware Profiling for LLM Inference Simulation
Pith reviewed 2026-05-11 02:37 UTC · model grok-4.3
The pith
Dooly reuses profiled LLM operation latencies across model configurations by tracing input-dimension origins in a single inference pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
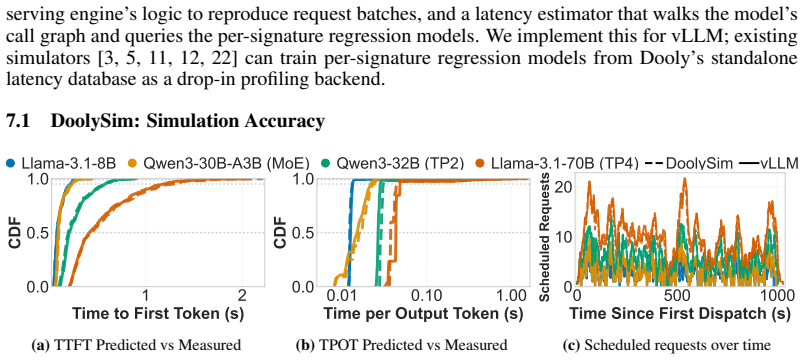
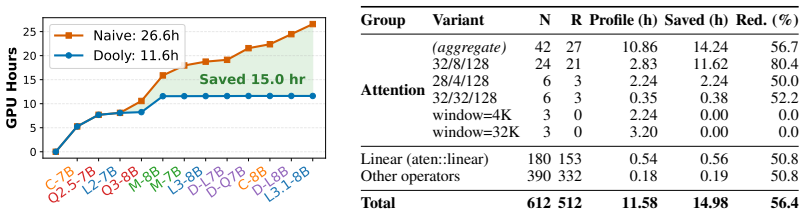
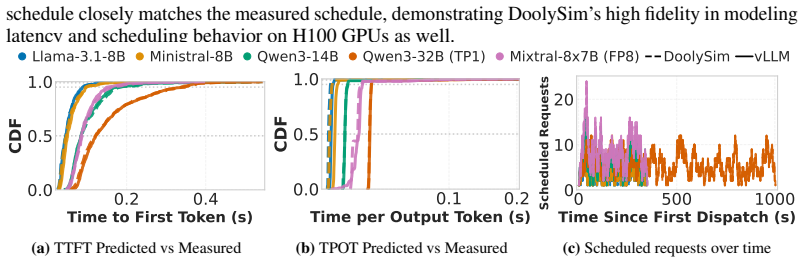
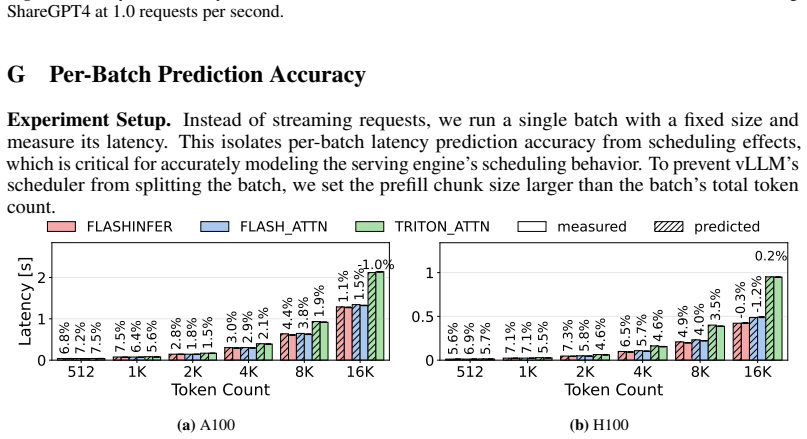
Dooly performs a single inference pass with taint propagation to label each operation's input dimensions by their origin in the model configuration or the incoming request. It selectively profiles only those operations absent from a growing latency database, reuses the serving engine's initialization for stateful operations like attention, and constructs regression models from the collected data. These models act as a drop-in replacement for the profiling component in existing simulators, delivering mean absolute percentage errors below 5% for time-to-first-token and below 8% for time-per-output-token while requiring 56.4% fewer profiling GPU-hours across diverse models, platforms, and back-
What carries the argument
Taint propagation during one inference execution to classify each input dimension's origin, enabling selective profiling and reuse of a latency database plus regression models for unprofiled cases.
If this is right
- Existing simulators can adopt the latency database without re-profiling for each new model configuration.
- Profiling effort decreases as the database accumulates data from multiple models due to shared dimensions.
- Prediction accuracy remains high across GPU platforms, attention backends, and model architectures without additional tuning.
- Stateful operations are handled automatically by reusing engine initialization code rather than custom instrumentation.
Where Pith is reading between the lines
- This reuse pattern could lower the barrier to testing many serving configurations during research and production tuning.
- Similar dimension-origin tracking might apply to profiling other neural-network inference workloads beyond transformers.
- A shared community latency database could further amortize costs across independent users.
Load-bearing premise
A single taint-labeled inference pass is enough to identify every reusable operation across arbitrary model configurations and the resulting latency database plus regression models generalize without hidden dependencies.
What would settle it
Run Dooly on a previously unseen model configuration, feed its latency database to a simulator, and compare the predicted TTFT and TPOT against direct hardware measurements; any deviation exceeding 8 percent MAPE on TPOT would falsify the claim.
Figures






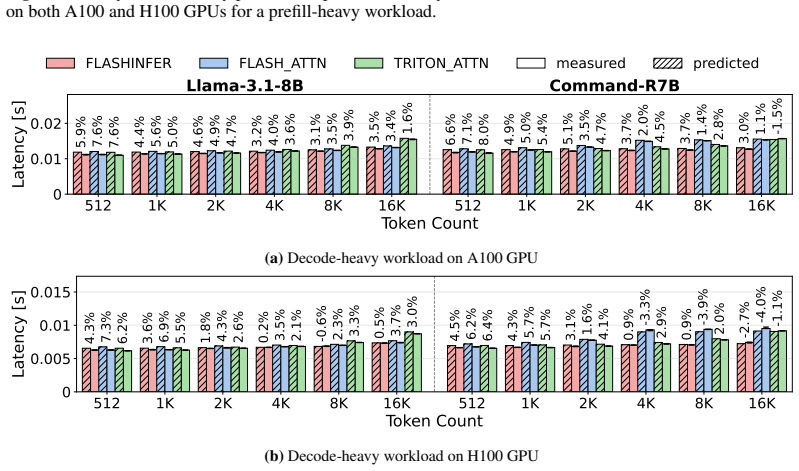



read the original abstract
Selecting the optimal LLM inference configuration requires evaluation across hardware, serving engines, attention backends, and model architectures, since no single choice performs best across all workloads. Profile-based simulators are the standard tool, yet they hardcode their operation set to a specific configuration and re-profile every operation from scratch, making exploration prohibitively expensive. This cost stems from a missing structural understanding: every input dimension of each operation is fixed by the model configuration or determined by the incoming request. Many model-configuration values (e.g., head size, layer count) recur across models, so the same operation runs in many configurations; a single sweep over the request-dependent dimensions can serve them all. We present Dooly, which exploits this structure to achieve configuration-agnostic, redundancy-aware profiling. Dooly performs a single inference pass, labels each input dimension with its origin via taint propagation, and selectively profiles only operations absent from its latency database; stateful operations such as attention are isolated by reusing the serving engine's own initialization code, eliminating manual instrumentation. It builds latency regression models based on the database, which becomes a drop-in backend for existing simulators. Across two GPU platforms, three attention backends, and diverse model architectures, Dooly achieves simulation accuracy within 5% MAPE for TTFT and 8% for TPOT while reducing profiling GPU-hours by 56.4% across 12 models compared to the existing profiling approach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Dooly, a profiling system for LLM inference simulators that performs one inference pass with taint propagation to label each operation input dimension as model-configuration-fixed or request-dependent. Only absent operations are profiled; stateful operations (e.g., attention) reuse the serving engine's own initialization code. A latency database plus regression models are then used as a drop-in backend for existing simulators. Across two GPU platforms, three attention backends, and 12 models, Dooly reports simulation accuracy within 5% MAPE for TTFT and 8% for TPOT while cutting profiling GPU-hours by 56.4% versus exhaustive per-configuration profiling.
Significance. If the taint-labeling and regression generalization hold, the work would meaningfully lower the cost of configuration exploration for LLM serving, a currently expensive step that limits both research and production tuning. The configuration-agnostic database and engine-reuse technique for stateful ops are pragmatic contributions that avoid per-model manual instrumentation.
major comments (3)
- [§3.2] §3.2 (Taint propagation): The central claim that a single inference pass with taint labeling suffices to separate reusable (config-fixed) from non-reusable (request-dependent) dimensions for every operation is load-bearing for both the 56.4% GPU-hour reduction and the reported MAPE. The manuscript does not demonstrate handling of derived or conditional dimensions (e.g., effective head size after model-specific reshape, or KV-cache sizes that mix config and runtime state). If any such case is mislabeled, the selective-profiling savings and regression predictions for unseen configurations would be invalidated.
- [§5] §5 (Evaluation and regression models): The 5% TTFT / 8% TPOT MAPE figures and the 56.4% reduction are presented without details on regression fitting procedure, feature set, data exclusion rules, train/test split, or outlier handling. This makes it impossible to assess whether the accuracy numbers are robust or result from post-hoc selection on the 12 evaluated models and three backends.
- [Table 2] Table 2 / results breakdown: The aggregate 56.4% GPU-hour saving is reported across 12 models, but no per-model or per-backend breakdown is given. Without it, it is unclear whether the savings are consistent or concentrated in a subset of architectures where many operations happen to be reusable.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from an early, explicit list of the 12 models, two platforms, and three backends to allow readers to judge the diversity claim.
- A small worked example (e.g., a 2-layer transformer) showing taint labels on a concrete operation would clarify the dimension-origin classification.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, providing clarifications where possible and committing to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Taint propagation): The central claim that a single inference pass with taint labeling suffices to separate reusable (config-fixed) from non-reusable (request-dependent) dimensions for every operation is load-bearing for both the 56.4% GPU-hour reduction and the reported MAPE. The manuscript does not demonstrate handling of derived or conditional dimensions (e.g., effective head size after model-specific reshape, or KV-cache sizes that mix config and runtime state). If any such case is mislabeled, the selective-profiling savings and regression predictions for unseen configurations would be invalidated.
Authors: We agree that explicit demonstration of derived and conditional dimension handling is necessary to fully support the central claim. Dooly’s taint propagation tracks dimension origins through the full computation graph, including reshapes, concatenations, and arithmetic used for sizes such as KV-cache (where a dimension may combine a config-fixed head size with a request-dependent sequence length, receiving a mixed label). Operations with any request-dependent component are profiled. The current §3.2 description is high-level; we will revise it to add concrete examples and pseudocode for reshape-derived head sizes and mixed KV-cache calculations, showing how labels are unioned from source dimensions. This will confirm that mislabeling does not occur for the evaluated models. revision: yes
-
Referee: [§5] §5 (Evaluation and regression models): The 5% TTFT / 8% TPOT MAPE figures and the 56.4% reduction are presented without details on regression fitting procedure, feature set, data exclusion rules, train/test split, or outlier handling. This makes it impossible to assess whether the accuracy numbers are robust or result from post-hoc selection on the 12 evaluated models and three backends.
Authors: We acknowledge that the absence of these details hinders independent assessment of robustness. The regression models use features including operation type, input/output shapes, hardware platform, and attention backend, fitted via standard regression techniques on profiled latencies. Data were collected across all 12 models and three backends with an 80/20 train/test split by configuration, outliers removed via IQR, and no post-hoc model selection. We will expand §5 with a new subsection providing the complete feature set, fitting procedure, split strategy, exclusion rules, and outlier handling. This will allow readers to verify the reported MAPE values. revision: yes
-
Referee: [Table 2] Table 2 / results breakdown: The aggregate 56.4% GPU-hour saving is reported across 12 models, but no per-model or per-backend breakdown is given. Without it, it is unclear whether the savings are consistent or concentrated in a subset of architectures where many operations happen to be reusable.
Authors: We agree that a per-model and per-backend breakdown would better demonstrate consistency of the savings. While the aggregate reflects overall benefit across diverse architectures, granular data would clarify where redundancy is highest. We will add an extended table (or new supplementary table) reporting GPU-hour savings, percentage of reusable operations, and profiled operation counts for each of the 12 models and each of the three attention backends. revision: yes
Circularity Check
No circularity in derivation chain; method is empirically grounded.
full rationale
The paper describes an empirical workflow: a single inference pass with taint propagation to label dimension origins, selective profiling of operations absent from a latency database, isolation of stateful ops via the serving engine's own code, and construction of regression models from measured data. No equations, derivations, or predictions are shown that reduce by construction to fitted parameters or self-referential definitions. Accuracy figures (5% MAPE TTFT, 8% TPOT) and the 56.4% GPU-hour reduction are presented as direct comparisons against full profiling and actual inference runs on 12 models across platforms and backends. The central claims rest on external measurements rather than self-citation chains, uniqueness theorems, or ansatzes imported from prior work, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Many model-configuration values (e.g., head size, layer count) recur across models, so the same operation runs in many configurations
Reference graph
Works this paper leans on
-
[1]
URLhttps://developer.nvidia.com/cupti
Nvidia cuda profiling tools interface, 2025. URLhttps://developer.nvidia.com/cupti
work page 2025
-
[2]
URL https://docs.pytorch.org/tutorials/ recipes/recipes/profiler_recipe.html
Pytorch profiler documentation, Jul 2026. URL https://docs.pytorch.org/tutorials/ recipes/recipes/profiler_recipe.html
work page 2026
-
[3]
Vidur: A large-scale simulation framework for llm inference, 2024
Amey Agrawal, Nitin Kedia, Jayashree Mohan, Ashish Panwar, Nipun Kwatra, Bhargav Gula- vani, Ramachandran Ramjee, and Alexey Tumanov. Vidur: A large-scale simulation framework for llm inference, 2024. URLhttps://arxiv.org/abs/2405.05465
-
[4]
Gulavani, Alexey Tumanov, and Ramachandran Ramjee
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav S. Gulavani, Alexey Tumanov, and Ramachandran Ramjee. Taming throughput-latency tradeoff in llm inference with sarathi-serve, 2024. URLhttps://arxiv.org/abs/2403.02310
-
[5]
Revati: Transparent gpu-free time-warp emulation for llm serving,
Amey Agrawal, Mayank Yadav, Sukrit Kumar, Anirudha Agrawal, Garv Ghai, Souradeep Bera, Elton Pinto, Sirish Gambhira, Mohammad Adain, Kasra Sohrab, Chus Antonanzas, and Alexey Tumanov. Revati: Transparent gpu-free time-warp emulation for llm serving, 2026. URL https://arxiv.org/abs/2601.00397
-
[6]
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. Gqa: Training generalized multi-query transformer models from multi-head checkpoints, 2023. URLhttps://arxiv.org/abs/2305.13245
work page internal anchor Pith review arXiv 2023
-
[7]
vllm v1 performance optimization, 2026
AMD. vllm v1 performance optimization, 2026. URL https://rocm.docs.amd.com/en/ latest/how-to/rocm-for-ai/inference-optimization/vllm-optimization.html
work page 2026
-
[8]
Steven Arzt, Siegfried Rasthofer, Christian Fritz, Eric Bodden, Alexandre Bartel, Jacques Klein, Yves Le Traon, Damien Octeau, and Patrick McDaniel. Flowdroid: precise context, flow, field, object-sensitive and lifecycle-aware taint analysis for android apps. InProceedings of the 35th ACM SIGPLAN Conference on Programming Language Design and Implementatio...
-
[9]
Iz Beltagy, Matthew E. Peters, and Arman Cohan. Longformer: The long-document transformer,
-
[10]
URLhttps://arxiv.org/abs/2004.05150
work page internal anchor Pith review Pith/arXiv arXiv 2004
- [11]
-
[12]
Enhanced system- level coherence for heterogeneous unified memory architectures,
Jaehong Cho, Minsu Kim, Hyunmin Choi, Guseul Heo, and Jongse Park. Llmservingsim: A hw/sw co-simulation infrastructure for llm inference serving at scale. In2024 IEEE Inter- national Symposium on Workload Characterization (IISWC), page 15–29. IEEE, Septem- ber 2024. doi: 10 .1109/iiswc63097.2024.00012. URL http://dx.doi.org/10.1109/ IISWC63097.2024.00012
-
[13]
Jaehong Cho, Hyunmin Choi, and Jongse Park. Llmservingsim2.0: A unified simulator for het- erogeneous hardware and serving techniques in llm infrastructure.IEEE Computer Architecture Letters, 24(2):361–364, July 2025. ISSN 2473-2575. doi: 10 .1109/lca.2025.3628325. URL http://dx.doi.org/10.1109/LCA.2025.3628325
-
[14]
Coherelabs/c4ai-command-r7b-12-2024
Cohere. Coherelabs/c4ai-command-r7b-12-2024. https://huggingface.co/CohereLabs/ c4ai-command-r7b-12-2024/
work page 2024
-
[15]
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
Tri Dao, Daniel Y . Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness, 2022. URL https://arxiv.org/abs/ 2205.14135
work page internal anchor Pith review arXiv 2022
-
[16]
Adapting vidur to vllm and profiling cpu overhead
duanzhaol. Adapting vidur to vllm and profiling cpu overhead. https://github.com/ microsoft/vidur/issues/51, 2025. 10
work page 2025
-
[17]
Cox, Jaeyeon Jung, Patrick McDaniel, and Anmol N
William Enck, Peter Gilbert, Seungyeop Han, Vasant Tendulkar, Byung-Gon Chun, Landon P. Cox, Jaeyeon Jung, Patrick McDaniel, and Anmol N. Sheth. Taintdroid: An information-flow tracking system for realtime privacy monitoring on smartphones.ACM Trans. Comput. Syst., 32 (2), June 2014. ISSN 0734-2071. doi: 10 .1145/2619091. URL https://doi.org/10.1145/ 2619091
work page 2014
-
[18]
Frontier: Simulating the next generation of llm inference systems, 2025
Yicheng Feng, Xin Tan, Kin Hang Sew, Yimin Jiang, Yibo Zhu, and Hong Xu. Frontier: Simulating the next generation of llm inference systems, 2025. URL https://arxiv.org/ abs/2508.03148
-
[19]
fwyc0573. How to get the profile csv of vllm instead of tensorrt-llm? https://github.com/ casys-kaist/LLMServingSim/issues/10, 2025
work page 2025
- [20]
-
[21]
hariag. Questions about simulation fidelity under vllm version differences, profiling utiliza- tion, and throughput estimation. https://github.com/microsoft/apex_plus/issues/8, 2025
work page 2025
-
[22]
Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teven...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Vijay Kandiah, Scott Peverelle, Mahmoud Khairy, Junrui Pan, Amogh Manjunath, Timothy G. Rogers, Tor M. Aamodt, and Nikos Hardavellas. Accelwattch: A power modeling framework for modern gpus. MICRO ’21, page 738–753, New York, NY , USA, 2021. Association for Computing Machinery. ISBN 9781450385572. doi: 10 .1145/3466752.3480063. URL https://doi.org/10.1145...
-
[24]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large lan- guage model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
work page 2023
-
[25]
Apex: An extensible and dynamism-aware simulator for automated parallel execution in llm serving,
Yi-Chien Lin, Woosuk Kwon, Ronald Pineda, and Fanny Nina Paravecino. Apex: An extensible and dynamism-aware simulator for automated parallel execution in llm serving, 2025. URL https://arxiv.org/abs/2411.17651
-
[26]
meta-llama/llama-3.1-8b.https://huggingface.co/meta-llama/Llama-3.1-8B
Meta. meta-llama/llama-3.1-8b.https://huggingface.co/meta-llama/Llama-3.1-8B
-
[27]
James Newsome and Dawn Song. Dynamic taint analysis for automatic detection, analysis, and signature generation of exploits on commodity software. In12th Annual Network and Distributed System Security Symposium (NDSS), San Diego, California, 2005
work page 2005
-
[28]
OpenChat. openchat_sharegpt4_dataset. https://huggingface.co/datasets/openchat/ openchat_sharegpt4_dataset
-
[29]
Pytorch: An imperative style, high-performance deep learning library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. Pytorch: An imperative style, high-perfo...
work page 2019
- [30]
-
[31]
PyTorch. GitHub - pytorch/kineto: A CPU+GPU Profiling library that provides access to timeline traces and hardware performance counters. — github.com. https://github.com/ pytorch/kineto
-
[32]
The anatomy of a triton attention kernel, 2025
Burkhard Ringlein, Jan van Lunteren, Radu Stoica, and Thomas Parnell. The anatomy of a triton attention kernel, 2025. URLhttps://arxiv.org/abs/2511.11581
-
[33]
Running problems with replica scheduler orca/sarathi
rxz 0420. Running problems with replica scheduler orca/sarathi. https://github.com/ microsoft/vidur/issues/64, 2025
work page 2025
-
[34]
samarth1612. Adding new model. https://github.com/microsoft/vidur/issues/32, 2024
work page 2024
-
[35]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc V . Le, Geoffrey E. Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of- experts layer.CoRR, abs/1701.06538, 2017. URLhttp://arxiv.org/abs/1701.06538
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[36]
Trtion.https://triton-lang.org/main/index.html, 2020
Philippe Tillet. Trtion.https://triton-lang.org/main/index.html, 2020
work page 2020
-
[37]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need, 2023. URL https://arxiv.org/abs/1706.03762
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
vLLM. Optimization and tuning, 2026. URL https://docs.vllm.ai/en/stable/ configuration/optimization/#attention-backend-selection
work page 2026
-
[39]
arXiv preprint arXiv:2501.15383 , year=
An Yang, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoyan Huang, Jiandong Jiang, Jianhong Tu, Jianwei Zhang, Jingren Zhou, Junyang Lin, Kai Dang, Kexin Yang, Le Yu, Mei Li, Minmin Sun, Qin Zhu, Rui Men, Tao He, Weijia Xu, Wenbiao Yin, Wenyuan Yu, Xiafei Qiu, Xingzhang Ren, Xinlong Yang, Yong Li, Zhiying Xu, and Zipeng Zhang. Qwen2.5-1m technical re...
-
[40]
Zihao Ye, Lequn Chen, Ruihang Lai, Wuwei Lin, Yineng Zhang, Stephanie Wang, Tianqi Chen, Baris Kasikci, Vinod Grover, Arvind Krishnamurthy, and Luis Ceze. Flashinfer: Efficient and customizable attention engine for llm inference serving, 2025. URL https://arxiv.org/ abs/2501.01005
-
[41]
SGLang: Efficient Execution of Structured Language Model Programs
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. Sglang: Efficient execution of structured language model programs, 2024. URL https://arxiv.org/abs/2312.07104
work page internal anchor Pith review arXiv 2024
-
[42]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. Distserve: Disaggregating prefill and decoding for goodput-optimized large language model serving, 2024. URLhttps://arxiv.org/abs/2401.09670. 12 A Comparison with Existing LLM Simulators Dooly RT [5] VD [3] FT [17] LS[11] AP [24] LS2 [12] Profiler Automatic Mo...
-
[43]
Error: missing context
-
[44]
Absorb: children absorbed by parent Import & Run SuccessFailure Resolved Fallback to parent Runnable Set:Attention Figure 6:Bottom-up resolution process. Sufficiency of a single trace.A natural concern is whether a single dummy-prompt trace can cover both prefill and decode call paths. Phase-dependent branching is driven entirely by token-count fields in ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.