Recognition: 2 theorem links
· Lean TheoremTool Calling is Linearly Readable and Steerable in Language Models
Pith reviewed 2026-05-11 03:04 UTC · model grok-4.3
The pith
The identity of the tool a language model chooses is linearly readable from its activations and can be switched by adding a mean difference vector.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
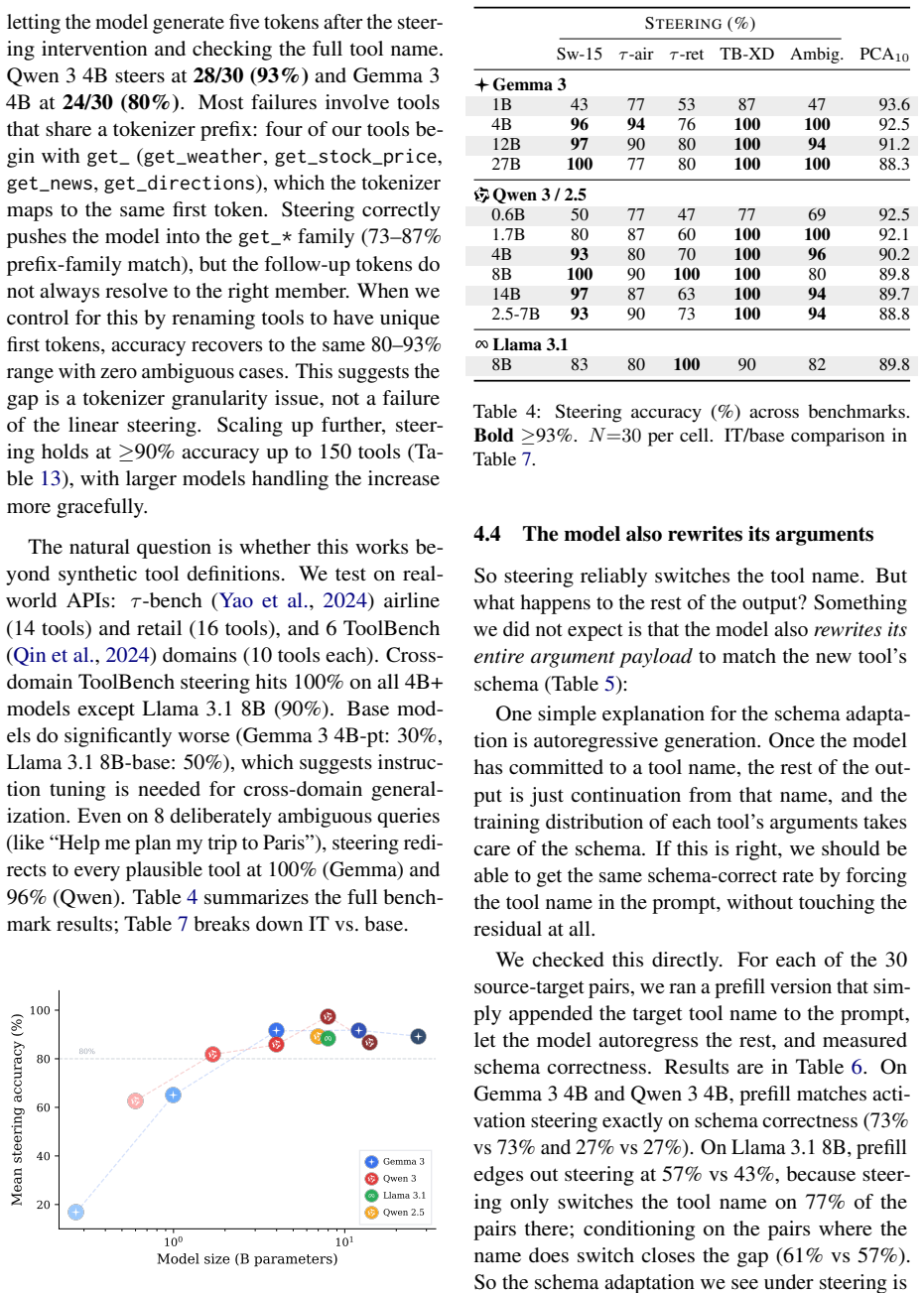
The identity of the chosen tool is linearly readable and steerable inside the model. Adding the mean-difference between two tools' average internal activations switches which tool the model selects at 77-100% accuracy on name-only single-turn prompts (93-100% at 4B+), and the JSON arguments that follow autoregressively match the new tool's schema. The causal effect concentrates along one direction, the row of the output layer that produces the target tool's first token. Activation patching localises this to a small set of mid- and late-layer attention heads, and a within-topic probe across 14 same-domain airline tools reaches 61-89% accuracy, ruling out a pure topic explanation. Even base 4B
What carries the argument
the mean-difference vector between average internal activations for each tool
Load-bearing premise
The vector difference between average activations for different tools specifically encodes tool identity rather than correlated features such as query topic or prompt syntax.
What would settle it
If adding the mean-difference vector between two tools no longer produces the new tool name and matching JSON schema at high rates on a fresh set of prompts outside the original calculation set, the linear steerability claim would fail.
Figures














read the original abstract
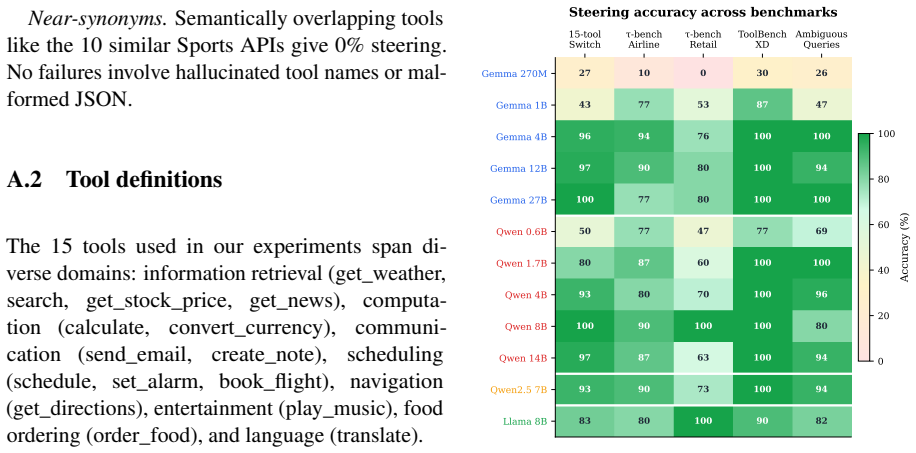
When a tool-calling agent picks the wrong tool, the failure is invisible until execution: the email gets sent, the meeting gets missed. Probing 12 instruction-tuned models across Gemma 3, Qwen 3, Qwen 2.5, and Llama 3.1 (270M to 27B), we find the identity of the chosen tool is linearly readable and steerable inside the model. Adding the mean-difference between two tools' average internal activations switches which tool the model selects at 77-100% accuracy on name-only single-turn prompts (93-100% at 4B+), and the JSON arguments that follow autoregressively match the new tool's schema, so flipping the name is enough. The same per-tool means also flag likely errors before they happen: on Gemma 3 12B and 27B, queries where the gap between the top-1 and top-2 tool is smallest produce 14-21x more wrong calls than queries with the largest gap. The causal effect concentrates along one direction, the row of the output layer that produces the target tool's first token: a unit vector along it at matched magnitude already reaches 93-100%, while what is left over leaves the choice almost untouched. Activation patching localises this to a small set of mid- and late-layer attention heads, and a within-topic probe across 14 same-domain $\tau$-bench airline tools reaches top-1 61-89% across five 4B-14B models, ruling out the reading that we are just moving the model along a topic axis. Even base models encode the right tool before they can emit it: cosine readout from the internal state recovers 69-82% on BFCL while base generation reaches only 2-10%, suggesting pretraining forms the representation and instruction tuning later wires it to the output. We measure tool identity selection and JSON schema correctness in single-turn fixed-menu settings; multi-turn agentic transfer is more fragile and is discussed in Limitations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that tool identity in language models is linearly readable and steerable via internal activations. Across 12 instruction-tuned models (Gemma 3, Qwen 3/2.5, Llama 3.1; 270M–27B), mean-difference vectors between per-tool average activations steer tool selection at 77–100% accuracy on name-only single-turn prompts (93–100% for 4B+ models), with autoregressive JSON arguments matching the new tool's schema. The effect concentrates in the output-layer row for the tool's first token (unit vector along this direction reaches 93–100% while the orthogonal residual leaves choice nearly untouched), localizes to a small set of mid- and late-layer attention heads via patching, and is not reducible to topic (within-topic probe on 14 airline tools yields 61–89% top-1 across five 4B–14B models). Base models already encode the correct tool internally (69–82% cosine readout on BFCL) despite 2–10% generation accuracy, and activation gaps predict errors (14–21× higher error rate for smallest vs. largest top-1/top-2 gaps on Gemma 3 12B/27B). All measurements are in single-turn fixed-menu settings.
Significance. If the results hold under the reported controls, the work provides concrete mechanistic evidence that tool selection is mediated by linear directions in activation space, with the output-layer decomposition and within-topic probe addressing key alternative explanations (topic/syntax confounds and post-hoc fitting). The base-model readout result is particularly notable, indicating the representation forms during pretraining and is later wired to output by instruction tuning. The error-prediction finding via activation gaps has direct practical value for reliable tool use. These elements together strengthen the central claim beyond correlational probing and could inform interpretability, safety interventions, and steering of agentic systems.
major comments (2)
- [Experiments (within-topic probe)] The within-topic probe (14 airline tools, 61–89% top-1) is load-bearing for ruling out topic as the driver; however, the manuscript should explicitly report the number of queries per tool, the exact layer(s) used for the mean vectors, and whether the same held-out set was used for both mean computation and evaluation to confirm no data leakage.
- [Results (steering experiments)] The claim that 'flipping the name is enough' for JSON schema correctness relies on autoregressive continuation; the paper should quantify schema-match rates separately from name accuracy and report whether any residual JSON errors occur even when the steered name is accepted.
minor comments (4)
- [Abstract] The abstract reports ranges (77–100%, 93–100% at 4B+) without per-model breakdowns or trial counts; adding a table with exact accuracies, model sizes, and number of prompts per condition would improve reproducibility.
- [Localization results] Activation patching localization to 'a small set of mid- and late-layer attention heads' would benefit from a figure or table listing the specific head indices and layers across models.
- [Base model analysis] The base-model readout (69–82%) vs. generation (2–10%) is a strong point; clarify whether the cosine readout uses the same mean vectors as the steered models or a separate base-model probe.
- [Throughout] Minor typographical inconsistencies in model naming (e.g., 'Gemma 3' vs. 'Gemma-3') should be standardized throughout.
Simulated Author's Rebuttal
We thank the referee for their positive assessment and recommendation for minor revision. We appreciate the constructive comments on improving the clarity and reproducibility of the within-topic probe and steering results. We address each major comment below and will update the manuscript accordingly.
read point-by-point responses
-
Referee: [Experiments (within-topic probe)] The within-topic probe (14 airline tools, 61–89% top-1) is load-bearing for ruling out topic as the driver; however, the manuscript should explicitly report the number of queries per tool, the exact layer(s) used for the mean vectors, and whether the same held-out set was used for both mean computation and evaluation to confirm no data leakage.
Authors: We agree that these experimental details are necessary for full reproducibility and to confirm the absence of data leakage. We will revise the manuscript to explicitly report the number of queries per tool in the within-topic probe, the exact layer(s) from which the mean activation vectors were computed, and confirmation that the mean vectors were derived from a separate split with evaluation performed on a held-out set with no overlap. revision: yes
-
Referee: [Results (steering experiments)] The claim that 'flipping the name is enough' for JSON schema correctness relies on autoregressive continuation; the paper should quantify schema-match rates separately from name accuracy and report whether any residual JSON errors occur even when the steered name is accepted.
Authors: We agree that separating schema-match rates from name accuracy and reporting residual errors would strengthen the steering results. We will revise the relevant Results section to include explicit quantification of schema-match rates independent of name accuracy and to report the incidence of any residual JSON errors in cases where the steered tool name is accepted. revision: yes
Circularity Check
No significant circularity
full rationale
The paper derives its claims from direct empirical measurements of internal activations across multiple models, causal steering via mean-difference vector addition on held-out single-turn prompts, within-topic controls across 14 airline tools, activation patching to localize heads, and base-model readout comparisons. None of these steps reduce to their inputs by construction: the mean vectors are computed on separate data and tested causally, the within-topic probe explicitly addresses confounds, and the output-layer decomposition is an independent verification. No self-citation chains, ansatzes, or fitted predictions masquerading as results appear in the load-bearing sections. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- per-tool mean activation vectors
axioms (1)
- domain assumption Tool identity is represented as a linear direction in the model's residual stream or attention outputs.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the identity of the chosen tool is linearly readable and steerable inside the model. Adding the mean-difference between two tools' average internal activations switches which tool the model selects
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PCA over 15 tool means fits in ∼10 directions... k90 as the smallest number of components needed to reach 90%
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Locating and Editing Factual Associations in
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , booktitle =. Locating and Editing Factual Associations in
-
[2]
Towards Automated Circuit Discovery for Mechanistic Interpretability , author =. NeurIPS , year =
-
[4]
Wang, Youjin and Zhou, Run and Fu, Rong and Cao, Shuaishuai and Zeng, Hongwei and Lu, Jiaxuan and Fan, Sicheng and Zhao, Jiaqiao and Pan, Liangming , journal =
-
[6]
Transformer Circuits Thread , year =
Circuit Tracing: Revealing Computational Graphs in Language Models , author =. Transformer Circuits Thread , year =
-
[9]
Advances in Neural Information Processing Systems , year =
Toolformer: Language Models Can Teach Themselves to Use Tools , author =. Advances in Neural Information Processing Systems , year =
-
[10]
Qin, Yujia and Liang, Shihao and Ye, Yining and Zhu, Kunlun and Yan, Lan and Lu, Yaxi and Lin, Yankai and Cong, Xin and Tang, Xiangru and Qian, Bill and others , journal =
-
[12]
Gorilla: Large Language Model Connected with Massive
Patil, Shishir G and Zhang, Tianjun and Wang, Xin and Gonzalez, Joseph E , journal =. Gorilla: Large Language Model Connected with Massive
-
[14]
Transformer Circuits Thread , year =
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , author =. Transformer Circuits Thread , year =
-
[16]
Causal Mediation Analysis for Interpreting Neural
Vig, Jesse and Gehrmann, Sebastian and Belinkov, Yonatan and Qian, Sharon and Nevo, Daniel and Sakenis, Simas and Huang, Jason and Singer, Yaron and Shieber, Stuart , journal =. Causal Mediation Analysis for Interpreting Neural
-
[17]
Interpretability in the Wild: a Circuit for Indirect Object Identification in
Wang, Kevin and Variengien, Alexandre and Conmy, Arthur and Shlegeris, Buck and Steinhardt, Jacob , journal =. Interpretability in the Wild: a Circuit for Indirect Object Identification in
-
[18]
Advances in Neural Information Processing Systems , year =
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author =. Advances in Neural Information Processing Systems , year =
-
[20]
Li, Minghao and others , journal =
-
[21]
Hao, Shibo and Liu, Tianyang and Wang, Zhen and Hu, Zhiting , journal =
-
[24]
Transformer Circuits Thread , year =
Toy Models of Superposition , author =. Transformer Circuits Thread , year =
-
[25]
Scaling Monosemanticity: Extracting Interpretable Features from
Templeton, Adly and Conerly, Tom and Marcus, Jonathan and Lindsey, Jack and Bricken, Trenton and Chen, Brian and Pearce, Adam and Citro, Craig and Ameisen, Emmanuel and Jones, Andy and others , journal =. Scaling Monosemanticity: Extracting Interpretable Features from
-
[27]
Advances in Neural Information Processing Systems , year =
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model , author =. Advances in Neural Information Processing Systems , year =
-
[28]
Representation Engineering: A Top-Down Approach to
Zou, Andy and Phan, Long and Chen, Sarah and Campbell, James and Guo, Phillip and Ren, Richard and Pan, Alexander and Yin, Xuwang and Mazeika, Mantas and Dombrowski, Ann-Kathrin and others , journal =. Representation Engineering: A Top-Down Approach to
-
[30]
Hendrycks, Dan and Mazeika, Mantas and Woodside, Thomas , journal =. An Overview of Catastrophic
-
[34]
Qwen2.5 Technical Report , author =. arXiv preprint arXiv:2412.15115 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Grattafiori, Aaron and others , journal =. The
-
[36]
Nanda, Neel and Bloom, Joseph , url =
-
[37]
Bloom, Joseph and others , url =
-
[38]
Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on
Lieberum, Tom and Raber, Senthooran and Kramar, Janos and others , journal =. Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on
-
[39]
Goodfire: Interpretability Infrastructure for
- [40]
-
[41]
Emmanuel Ameisen and 1 others. 2025. https://transformer-circuits.pub/2025/attribution-graphs/methods.html Circuit tracing: Revealing computational graphs in language models . Transformer Circuits Thread
work page 2025
-
[42]
Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Rimsky, Lee Sharkey, and 1 others. 2024. Refusal in language models is mediated by a single direction. arXiv preprint arXiv:2406.11717
work page internal anchor Pith review arXiv 2024
-
[43]
Joseph Bloom and 1 others. 2024. https://github.com/jbloomAUS/SAELens SAELens : A library for sparse autoencoder training, analysis, and interpretability
work page 2024
-
[44]
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Conerly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, and 1 others. 2023. Towards monosemanticity: Decomposing language models with dictionary learning. Transformer Circuits Thread
work page 2023
-
[45]
Arthur Conmy, Augustine Mavor-Parker, Aengus Lynch, Stefan Heimersheim, and Adri\` a Garriga-Alonso. 2023. Towards automated circuit discovery for mechanistic interpretability. In NeurIPS
work page 2023
-
[46]
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. 2023. Sparse autoencoders find highly interpretable features in language models. arXiv preprint arXiv:2309.08600
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[47]
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, and 1 others. 2022. Toy models of superposition. Transformer Circuits Thread
work page 2022
- [48]
-
[49]
Gemma Team . 2024. Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [50]
-
[51]
Aaron Grattafiori and 1 others. 2024. The Llama 3 herd of models. arXiv preprint arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
Shibo Hao, Tianyang Liu, Zhen Wang, and Zhiting Hu. 2023. ToolkenGPT : Augmenting frozen language models with massive tools via tool embeddings. Advances in Neural Information Processing Systems
work page 2023
- [53]
- [54]
-
[55]
Kenneth Li, Oam Patel, Fernanda Vi \'e gas, Hanspeter Pfister, and Martin Wattenberg. 2023 a . Inference-time intervention: Eliciting truthful answers from a language model. Advances in Neural Information Processing Systems
work page 2023
- [56]
-
[57]
Tom Lieberum, Senthooran Raber, Janos Kramar, and 1 others. 2024. Gemma scope: Open sparse autoencoders everywhere all at once on Gemma 2. arXiv preprint arXiv:2408.05147
work page internal anchor Pith review arXiv 2024
-
[58]
Johnny Lin. 2024. https://www.neuronpedia.org/ NeuronPedia : A platform for mechanistic interpretability
work page 2024
-
[59]
Samuel Marks and Max Tegmark. 2024. The geometry of truth: Emergent linear structure in large language model representations of true/false datasets. arXiv preprint arXiv:2310.06824
work page internal anchor Pith review arXiv 2024
-
[60]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. 2022. Locating and editing factual associations in GPT . In NeurIPS
work page 2022
-
[61]
Neel Nanda and Joseph Bloom. 2022. https://github.com/TransformerLensOrg/TransformerLens TransformerLens : A library for mechanistic interpretability of GPT -style language models
work page 2022
- [62]
-
[63]
Kiho Park, Yo Joong Choe, and Victor Veitch. 2024. The linear representation hypothesis and the geometry of large language models. arXiv preprint arXiv:2311.03658
work page internal anchor Pith review arXiv 2024
-
[64]
Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E Gonzalez. 2023. Gorilla: Large language model connected with massive APIs . arXiv preprint arXiv:2305.15334
work page internal anchor Pith review arXiv 2023
-
[65]
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, and 1 others. 2024. ToolLLM : Facilitating large language models to master 16000+ real-world APIs . arXiv preprint arXiv:2307.16789
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[66]
Qwen Team . 2025. Qwen3 technical report. arXiv preprint arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [67]
-
[68]
Timo Schick, Jane Dwivedi-Yu, Roberto Dess \` , Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language models can teach themselves to use tools. Advances in Neural Information Processing Systems
work page 2023
-
[69]
Adly Templeton, Tom Conerly, Jonathan Marcus, Jack Lindsey, Trenton Bricken, Brian Chen, Adam Pearce, Craig Citro, Emmanuel Ameisen, Andy Jones, and 1 others. 2024. Scaling monosemanticity: Extracting interpretable features from Claude 3 Sonnet . Transformer Circuits Thread
work page 2024
- [70]
- [71]
-
[72]
Alexander Matt Turner, Lisa Thiergart, David Udell, Gavin Leech, Ulisse Mini, and Monte Castricato. 2024. Activation addition: Steering language models without optimization. arXiv preprint arXiv:2308.10248
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [73]
-
[74]
Kevin Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. 2023. Interpretability in the wild: a circuit for indirect object identification in GPT-2 small. arXiv preprint arXiv:2211.00593
work page internal anchor Pith review arXiv 2023
- [75]
-
[76]
Fanjia Yan, Huanzhi Mao, Charlie Ji, Shishir Patil, Ion Stoica, Joseph E Gonzalez, and Hao Zhang. 2024. Berkeley function calling leaderboard. In NeurIPS
work page 2024
-
[77]
Shunyu Yao and 1 others. 2024. -bench: A benchmark for tool-agent-user interaction in real-world domains. arXiv preprint arXiv:2406.12045
work page internal anchor Pith review arXiv 2024
-
[78]
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, and 1 others. 2023. Representation engineering: A top-down approach to AI transparency. arXiv preprint arXiv:2310.01405
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.