Recognition: 2 theorem links
· Lean TheoremPenalty-Based First-Order Methods for Bilevel Optimization with Minimax and Constrained Lower-Level Problems
Pith reviewed 2026-05-11 02:36 UTC · model grok-4.3
The pith
Penalty-based first-order methods solve bilevel minimax problems to ε-KKT points in Õ(ε^{-4}) oracle complexity without strong convexity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
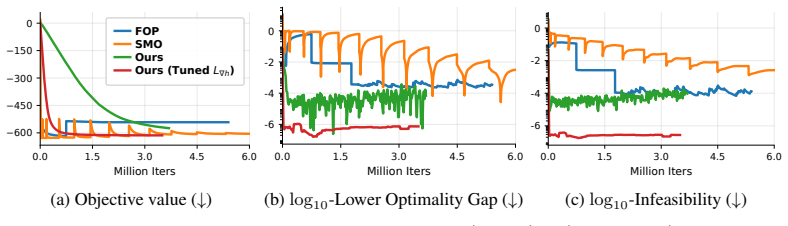
We propose penalty-based first-order methods for bilevel minimax optimization without requiring strong convexity of the lower-level problem. In the deterministic setting these methods find an ε-KKT point with Õ(ε^{-4}) oracle complexity. Bilevel problems whose lower level is convex constrained minimization are recovered as special cases through Lagrangian duality, delivering the same Õ(ε^{-4}) bound and improving on the prior Õ(ε^{-7}) result. The approach extends to the stochastic setting, where the stochastic version finds a nearly ε-KKT point with Õ(ε^{-9}) oracle complexity.
What carries the argument
Penalty reformulation of the bilevel minimax problem that converts the two-level structure into a single-level problem amenable to first-order oracles.
If this is right
- Bilevel problems whose inner level is a minimax game can now be solved by first-order methods at the same rate previously available only for strongly convex inner minimization.
- Convex constrained inner minimization problems inherit the improved Õ(ε^{-4}) complexity once rewritten via Lagrangian duality.
- The deterministic guarantee extends to a stochastic guarantee of nearly ε-KKT points at Õ(ε^{-9}) cost when only noisy oracles are available.
- The penalty framework supplies a uniform algorithmic template that covers both the minimax and the constrained-minimization special cases.
Where Pith is reading between the lines
- The same penalty technique might be applied to bilevel problems with nonconvex lower levels by replacing the duality step with an appropriate smoothing or regularization.
- Applications such as robust training or equilibrium computation could directly substitute the new inner-loop solver for existing bilevel procedures.
- The gap between the deterministic Õ(ε^{-4}) and stochastic Õ(ε^{-9}) bounds suggests room for variance-reduction techniques that could close the gap in future work.
Load-bearing premise
The penalty reformulation and the Lagrangian duality step preserve the KKT points of the original bilevel problem without introducing hidden strong-convexity or changing the first-order oracle model.
What would settle it
A concrete counter-example or numerical instance in which the proposed algorithm requires more than Õ(ε^{-4}) first-order oracle calls to reach an ε-KKT point would falsify the deterministic complexity claim.
Figures
read the original abstract
We study a class of bilevel optimization problems in which both the upper- and lower-level problems have minimax structures. This setting captures a broad range of emerging applications. Despite the extensive literature on bilevel optimization and minimax optimization separately, existing methods mainly focus on bilevel optimization with lower-level minimization problems, often under strong convexity assumptions, and are not directly applicable to the minimax lower-level setting considered here. To address this gap, we develop penalty-based first-order methods for bilevel minimax optimization without requiring strong convexity of the lower-level problem. In the deterministic setting, we establish that the proposed method finds an $\epsilon$-KKT point with $\tilde{O}(\epsilon^{-4})$ oracle complexity. We further show that bilevel problems with convex constrained lower-level minimization can be reformulated as special cases of our framework via Lagrangian duality, leading to an $\tilde{O}(\epsilon^{-4})$ complexity bound that improves upon the existing $\tilde{O}(\epsilon^{-7})$ result. Finally, we extend our approach to the stochastic setting, where only stochastic gradient oracles are available, and prove that the proposed stochastic method finds a nearly $\epsilon$-KKT point with $\tilde{O}(\epsilon^{-9})$ oracle complexity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops penalty-based first-order methods for bilevel optimization problems in which both the upper- and lower-level problems have minimax structures. It claims that the proposed deterministic method finds an ε-KKT point with Õ(ε^{-4}) oracle complexity without requiring strong convexity of the lower level. It further shows that bilevel problems with convex constrained lower-level minimization can be reformulated as special cases of the minimax framework via Lagrangian duality, yielding the same Õ(ε^{-4}) bound and improving on the prior Õ(ε^{-7}) result. The approach is extended to the stochastic setting, where the method finds a nearly ε-KKT point with Õ(ε^{-9}) oracle complexity.
Significance. If the central claims hold, the work would be significant for providing first-order methods and complexity guarantees for a broader class of bilevel problems that include minimax lower levels and constrained convex lower levels, without strong-convexity assumptions. The duality-based reformulation that improves the complexity bound for constrained cases would be a notable technical contribution, and the penalty approach addresses a gap relative to existing bilevel literature focused on minimization lower levels.
major comments (2)
- [Abstract] Abstract (duality reformulation paragraph): The claim that convex constrained lower-level minimization problems can be reformulated as special cases of the minimax framework via Lagrangian duality, preserving the Õ(ε^{-4}) complexity and the first-order oracle model, is load-bearing for the improvement over the existing Õ(ε^{-7}) result. However, exact KKT equivalence and absence of duality gap typically require an explicit constraint qualification (e.g., Slater's condition) that is not mentioned in the abstract; if the relevant theorem omits this or handles the gap only asymptotically, the complexity transfer becomes conditional on an unstated assumption.
- [Abstract] Abstract (deterministic complexity claim): The stated Õ(ε^{-4}) oracle complexity for finding an ε-KKT point relies on the penalty reformulation preserving the ε-KKT notion exactly. The manuscript should clarify in the relevant theorem whether the penalty parameter schedule introduces any hidden dependence on problem constants that would alter the stated rate or the first-order oracle model.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on our manuscript. We appreciate the opportunity to clarify the points raised and will revise the paper accordingly to improve precision and transparency.
read point-by-point responses
-
Referee: [Abstract] Abstract (duality reformulation paragraph): The claim that convex constrained lower-level minimization problems can be reformulated as special cases of the minimax framework via Lagrangian duality, preserving the Õ(ε^{-4}) complexity and the first-order oracle model, is load-bearing for the improvement over the existing Õ(ε^{-7}) result. However, exact KKT equivalence and absence of duality gap typically require an explicit constraint qualification (e.g., Slater's condition) that is not mentioned in the abstract; if the relevant theorem omits this or handles the gap only asymptotically, the complexity transfer becomes conditional on an unstated assumption.
Authors: We agree that strong duality and exact KKT equivalence between the constrained lower-level problem and its Lagrangian minimax reformulation require a constraint qualification such as Slater's condition. The full manuscript states this assumption explicitly in the section on the duality-based reformulation and derives the complexity bound under it. To eliminate any ambiguity in the abstract, we will revise the relevant paragraph to note that the reformulation and complexity transfer hold under Slater's condition (or an equivalent CQ) for the lower-level problem. revision: yes
-
Referee: [Abstract] Abstract (deterministic complexity claim): The stated Õ(ε^{-4}) oracle complexity for finding an ε-KKT point relies on the penalty reformulation preserving the ε-KKT notion exactly. The manuscript should clarify in the relevant theorem whether the penalty parameter schedule introduces any hidden dependence on problem constants that would alter the stated rate or the first-order oracle model.
Authors: The penalty parameter schedule is chosen as a function of ε only (specifically μ = Θ(ε^{-1})), with any dependence on problem constants (e.g., Lipschitz or smoothness parameters) already absorbed into the Õ notation in the standard manner for first-order complexity bounds. The analysis preserves the ε-KKT notion exactly for the penalized problem, and the oracle model remains purely first-order. We will add an explicit remark to the statement of the main deterministic theorem clarifying that the schedule introduces no additional factors that change the stated rate or oracle access model. revision: yes
Circularity Check
Minor self-citation present but central derivation independent
full rationale
The paper derives new penalty-based first-order methods and associated oracle complexities (Õ(ε^{-4}) deterministic, Õ(ε^{-9}) stochastic) via direct analysis of the proposed algorithms. The Lagrangian duality reformulation is introduced as an explicit contribution that maps constrained lower-level problems into the minimax framework, yielding the improved bound over prior Õ(ε^{-7}) results. No equation or step reduces a claimed rate to a fitted parameter or to a self-cited premise by construction. Any self-citations are peripheral and not load-bearing for the complexity claims.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The objective functions satisfy standard smoothness and Lipschitz-gradient assumptions sufficient for first-order methods to be well-defined.
- domain assumption The bilevel problems admit ε-KKT points and the penalty reformulation preserves them.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclearWe further show that bilevel problems with convex constrained lower-level minimization can be reformulated as special cases of our framework via Lagrangian duality, leading to an Õ(ε^{-4}) complexity bound
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearpenalty reformulation ... Pρ(x1,x2,y1,y2,z1,z2) := f(x1,x2,y1,y2) + ρ(˜f(x1,y1,z2) - ˜f(x1,z1,y2))
Reference graph
Works this paper leans on
-
[1]
Solving bilevel programs with the kkt-approach
Gemayqzel Bouza Allende and Georg Still. Solving bilevel programs with the kkt-approach. Mathematical programming, 138(1):309–332, 2013
work page 2013
-
[2]
Non-convex bilevel games with critical point selection maps
Michael Arbel and Julien Mairal. Non-convex bilevel games with critical point selection maps. Advances in Neural Information Processing Systems, 35:8013–8026, 2022
work page 2022
-
[3]
Aharon Ben-Tal, Dick Den Hertog, Anja De Waegenaere, Bertrand Melenberg, and Gijs Rennen. Robust solutions of optimization problems affected by uncertain probabilities.Management Science, 59(2):341–357, 2013
work page 2013
-
[4]
Bennett, Gautam Kunapuli, Jing Hu, and Jong-Shi Pang
Kristin P. Bennett, Gautam Kunapuli, Jing Hu, and Jong-Shi Pang. Bilevel optimization and machine learning. InIEEE World Congress on Computational Intelligence, pages 25–47. Springer, 2008
work page 2008
-
[5]
Henriques, Philip Torr, and Andrea Vedaldi
Luca Bertinetto, Joao F. Henriques, Philip Torr, and Andrea Vedaldi. Meta-learning with differentiable closed-form solvers. InInternational Conference on Learning Representations, 2018
work page 2018
-
[6]
Nonlinear programming.Journal of the Operational Research Society, 48 (3):334–334, 1997
Dimitri P Bertsekas. Nonlinear programming.Journal of the Operational Research Society, 48 (3):334–334, 1997
work page 1997
-
[7]
On finding small hyper-gradients in bilevel optimiza- tion: Hardness results and improved analysis
Lesi Chen, Jing Xu, and Jingzhao Zhang. On finding small hyper-gradients in bilevel optimiza- tion: Hardness results and improved analysis. InThe Thirty Seventh Annual Conference on Learning Theory, pages 947–980. PMLR, 2024
work page 2024
-
[8]
Lesi Chen, Yaohua Ma, and Jingzhao Zhang. Near-optimal nonconvex-strongly-convex bilevel optimization with fully first-order oracles.Journal of Machine Learning Research, 26(109): 1–56, 2025. URLhttp://jmlr.org/papers/v26/23-1104.html
work page 2025
-
[9]
Tianyi Chen, Yuejiao Sun, and Wotao Yin. Closing the gap: Tighter analysis of alternating stochastic gradient methods for bilevel problems.Advances in Neural Information Processing Systems, 34:25294–25307, 2021
work page 2021
-
[10]
A single-timescale method for stochastic bilevel optimization
Tianyi Chen, Yuejiao Sun, Quan Xiao, and Wotao Yin. A single-timescale method for stochastic bilevel optimization. InInternational Conference on Artificial Intelligence and Statistics, pages 2466–2488, 2022
work page 2022
-
[11]
Ziyi Chen, Bhavya Kailkhura, and Yi Zhou. A fast and convergent proximal algorithm for regularized nonconvex and nonsmooth bi-level optimization.arXiv preprint arXiv:2203.16615, 2022
-
[12]
Liam Collins, Aryan Mokhtari, and Sanjay Shakkottai. Task-robust model-agnostic meta- learning.Advances in Neural Information Processing Systems, 33:18860–18871, 2020
work page 2020
-
[13]
John C Duchi and Hongseok Namkoong. Learning models with uniform performance via distributionally robust optimization.The Annals of Statistics, 49(3):1378–1406, 2021
work page 2021
-
[14]
Pavel Dvurechensky, Andrea Ebner, Johannes Carl Schnebel, Shimrit Shtern, and Mathias Staudigl. Stochastic variance reduced extragradient methods for solving hierarchical variational inequalities.arXiv preprint arXiv:2602.13510, 2026
-
[15]
Model-agnostic meta-learning for fast adap- tation of deep networks
Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic meta-learning for fast adap- tation of deep networks. InInternational conference on machine learning, pages 1126–1135. PMLR, 2017
work page 2017
-
[16]
Bilevel programming for hyperparameter optimization and meta-learning
Luca Franceschi, Paolo Frasconi, Saverio Salzo, Riccardo Grazzi, and Massimiliano Pontil. Bilevel programming for hyperparameter optimization and meta-learning. InInternational Conference on Machine Learning, pages 1568–1577, 2018
work page 2018
-
[17]
Value function based difference-of-convex algorithm for bilevel hyperparameter selection problems
Lucy L Gao, Jane Ye, Haian Yin, Shangzhi Zeng, and Jin Zhang. Value function based difference-of-convex algorithm for bilevel hyperparameter selection problems. InInternational conference on machine learning, pages 7164–7182. PMLR, 2022. 11
work page 2022
-
[18]
Saeed Ghadimi and Mengdi Wang. Approximation methods for bilevel programming.arXiv preprint arXiv:1802.02246, 2018
-
[19]
Generative adversarial nets.Advances in neural information processing systems, 27, 2014
Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets.Advances in neural information processing systems, 27, 2014
work page 2014
-
[20]
On the iteration complexity of hypergradient computation
Riccardo Grazzi, Luca Franceschi, Massimiliano Pontil, and Saverio Salzo. On the iteration complexity of hypergradient computation. InInternational Conference on Machine Learning, pages 3748–3758, 2020
work page 2020
-
[21]
Zhishuai Guo, Quanqi Hu, Lijun Zhang, and Tianbao Yang. Randomized stochastic variance-reduced methods for multi-task stochastic bilevel optimization.arXiv preprint arXiv:2105.02266, 2021
-
[22]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
work page 2016
-
[23]
Mingyi Hong, Hoi-To Wai, Zhaoran Wang, and Zhuoran Yang. A two-timescale stochastic algorithm framework for bilevel optimization.SIAM Journal on Optimization, 33(1):147–180, 2023
work page 2023
-
[24]
Xiaoyin Hu, Nachuan Xiao, Xin Liu, and Kim-Chuan Toh. An improved unconstrained approach for bilevel optimization.SIAM Journal on Optimization, 33(4):2801–2829, 2023
work page 2023
-
[25]
arXiv preprint arXiv:2311.04520 , year=
Feihu Huang. Adaptive mirror descent bilevel optimization.arXiv preprint arXiv:2311.04520, 2023
-
[26]
arXiv preprint arXiv:2303.03944 , year=
Feihu Huang. On momentum-based gradient methods for bilevel optimization with nonconvex lower-level.arXiv preprint arXiv:2303.03944, 2023
-
[27]
Optimal hessian/jacobian-free nonconvex-pl bilevel optimization
Feihu Huang. Optimal hessian/jacobian-free nonconvex-pl bilevel optimization. InProceedings of the 41st International Conference on Machine Learning, pages 19598–19621, 2024
work page 2024
-
[28]
Feihu Huang, Junyi Li, Shangqian Gao, and Heng Huang. Enhanced bilevel optimization via bregman distance.Advances in Neural Information Processing Systems, 35:28928–28939, 2022
work page 2022
-
[29]
Bilevel optimization: Convergence analysis and enhanced design
Kaiyi Ji, Junjie Yang, and Yingbin Liang. Bilevel optimization: Convergence analysis and enhanced design. InICML, pages 4882–4892, 2021
work page 2021
-
[30]
Tenorio, Fernando Real-Rojas, Antonio G
Liuyuan Jiang, Quan Xiao, Victor M. Tenorio, Fernando Real-Rojas, Antonio G. Marques, and Tianyi Chen. A primal-dual-assisted penalty approach to bilevel optimization with coupled constraints.Advances in Neural Information Processing Systems, 37:95026–95066, 2024
work page 2024
-
[31]
Decoupling representation and classifier for long-tailed recognition
Bingyi Kang, Saining Xie, Marcus Rohrbach, Zhicheng Yan, Albert Gordo, Jiashi Feng, and Yannis Kalantidis. Decoupling representation and classifier for long-tailed recognition. In International Conference on Learning Representations (ICLR), 2020
work page 2020
-
[32]
Mohammad Khalafi and Digvijay Boob. Regularized operator extrapolation method for stochas- tic bilevel variational inequality problems.arXiv preprint arXiv:2505.09778, 2025
-
[33]
A near-optimal algorithm for stochastic bilevel optimization via double-momentum
Prashant Khanduri, Siliang Zeng, Mingyi Hong, Hoi-To Wai, Zhaoran Wang, and Zhuoran Yang. A near-optimal algorithm for stochastic bilevel optimization via double-momentum. In NeurIPS, 2021
work page 2021
-
[34]
Linearly constrained bilevel optimization: A smoothed implicit gradient approach
Prashant Khanduri, Ioannis Tsaknakis, Yihua Zhang, Jia Liu, Sijia Liu, Jiawei Zhang, and Mingyi Hong. Linearly constrained bilevel optimization: A smoothed implicit gradient approach. InInternational Conference on Machine Learning, pages 16291–16325. PMLR, 2023
work page 2023
-
[35]
Last layer re-training is sufficient for robustness to spurious correlations
Polina Kirichenko, Pavel Izmailov, and Andrew Gordon Wilson. Last layer re-training is sufficient for robustness to spurious correlations. InInternational Conference on Learning Representations (ICLR), 2023. 12
work page 2023
-
[36]
Guy Kornowski, Swati Padmanabhan, Kai Wang, Jimmy Zhang, and Suvrit Sra. First-order methods for linearly constrained bilevel optimization.Advances in neural information process- ing systems, 37
-
[37]
The first optimal algorithm for smooth minimax optimization
Dmitry Kovalev and Alexander Gasnikov. The first optimal algorithm for smooth minimax optimization. InNeurIPS, 2022
work page 2022
-
[38]
On penalty methods for nonconvex bilevel optimization and first-order stochastic approximation
Jeongyeol Kwon, Dohyun Kwon, Stephen Wright, and Robert Nowak. On penalty methods for nonconvex bilevel optimization and first-order stochastic approximation. InThe Twelfth International Conference on Learning Representations
-
[39]
A fully first-order method for stochastic bilevel optimization
Jeongyeol Kwon, Dohyun Kwon, Stephen Wright, and Robert D Nowak. A fully first-order method for stochastic bilevel optimization. InInternational Conference on Machine Learning, pages 18083–18113. PMLR, 2023
work page 2023
-
[40]
Chenliang Li, Siliang Zeng, Zeyi Liao, Jiaxiang Li, Dongyeop Kang, Alfredo Garcia, and Mingyi Hong. Learning reward and policy jointly from demonstration and preference improves alignment.arXiv preprint arXiv:2406.06874, 2024
-
[41]
A fully single loop algorithm for bilevel optimization without hessian inverse
Junyi Li, Bin Gu, and Heng Huang. A fully single loop algorithm for bilevel optimization without hessian inverse. InProceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 7426–7434, 2022
work page 2022
-
[42]
A novel approach for bilevel programs based on wolfe duality.arXiv preprint arXiv:2302.06838, 2023
Yuwei Li, Gui-Hua Lin, Jin Zhang, and Xide Zhu. A novel approach for bilevel programs based on wolfe duality.arXiv preprint arXiv:2302.06838, 2023
-
[43]
Bome! bilevel optimization made easy
Bo Liu, Mao Ye, Stephen Wright, Peter Stone, and Qiang Liu. Bome! bilevel optimization made easy. InNeurIPS, 2022
work page 2022
-
[44]
Darts: Differentiable architecture search
Hanxiao Liu, Karen Simonyan, and Yiming Yang. Darts: Differentiable architecture search. In ICLR, 2018
work page 2018
-
[45]
A value-function-based interior-point method for non-convex bi-level optimization
Risheng Liu, Xuan Liu, Xiaoming Yuan, Shangzhi Zeng, and Jin Zhang. A value-function-based interior-point method for non-convex bi-level optimization. InInternational conference on machine learning, pages 6882–6892. PMLR, 2021
work page 2021
-
[46]
Risheng Liu, Yaohua Liu, Shangzhi Zeng, and Jin Zhang. Towards gradient-based bilevel opti- mization with non-convex followers and beyond.Advances in Neural Information Processing Systems, 34:8662–8675, 2021
work page 2021
-
[47]
Risheng Liu, Pan Mu, Xiaoming Yuan, Shangzhi Zeng, and Jin Zhang. A general descent aggregation framework for gradient-based bi-level optimization.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(1):38–57, 2022
work page 2022
-
[48]
Risheng Liu, Xuan Liu, Shangzhi Zeng, Jin Zhang, and Yixuan Zhang. Value-function-based sequential minimization for bi-level optimization.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(12):15930–15948, 2023
work page 2023
-
[49]
Averaged method of multipliers for bi-level optimization without lower-level strong convexity
Risheng Liu, Yaohua Liu, Wei Yao, Shangzhi Zeng, and Jin Zhang. Averaged method of multipliers for bi-level optimization without lower-level strong convexity. InInternational Conference on Machine Learning, pages 21839–21866. PMLR, 2023
work page 2023
-
[50]
Deep learning face attributes in the wild
Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. InProceedings of the IEEE International Conference on Computer Vision (ICCV), pages 3730–3738, 2015
work page 2015
-
[51]
Zhaosong Lu and Sanyou Mei. First-order penalty methods for bilevel optimization.SIAM Journal on Optimization, 34(2):1937–1969, 2024. doi: 10.1137/23M1566753. URL https: //doi.org/10.1137/23M1566753
-
[52]
Zhaosong Lu and Sanyou Mei. A first-order augmented lagrangian method for constrained minimax optimization.Mathematical Programming, 213(1):1063–1104, September 2025. doi: 10.1007/s10107-024-02163-3. URLhttps://doi.org/10.1007/s10107-024-02163-3. 13
-
[53]
Solving bilevel optimization via sequential minimax optimization
Zhaosong Lu and Sanyou Mei. Solving bilevel optimization via sequential minimax optimization. Mathematics of Operations Research, 2026. doi: 10.1287/moor.2024.0521. URL https: //doi.org/10.1287/moor.2024.0521. Published online January 6, 2026
-
[54]
Towards deep learning models resistant to adversarial attacks
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks. InInternational Conference on Learning Representations, 2018
work page 2018
-
[55]
Arkadi Nemirovski. Prox-method with rate of convergence o(1/t) for variational inequalities with lipschitz continuous monotone operators and smooth convex-concave saddle point problems. SIAM Journal on Optimization, 15(1):229–251, 2004
work page 2004
-
[56]
Hantao Nie, Jiaxiang Li, and Zaiwen Wen. An augmented lagrangian value function method for lower-level constrained stochastic bilevel optimization.arXiv preprint arXiv:2509.24249, 2025
-
[57]
Duality approach to bilevel programs with a convex lower level
Aurélien Ouattara and Anil Aswani. Duality approach to bilevel programs with a convex lower level. In2018 Annual American Control Conference (ACC), pages 1388–1395. IEEE, 2018
work page 2018
-
[58]
Hyperparameter optimization with approximate gradient
Fabian Pedregosa. Hyperparameter optimization with approximate gradient. InICML, 2016
work page 2016
-
[59]
Meta-learning with implicit gradients.Advances in neural information processing systems, 32, 2019
Aravind Rajeswaran, Chelsea Finn, Sham M Kakade, and Sergey Levine. Meta-learning with implicit gradients.Advances in neural information processing systems, 32, 2019
work page 2019
-
[60]
Learning to reweight examples for robust deep learning
Mengye Ren, Wenyuan Zeng, Bin Yang, and Raquel Urtasun. Learning to reweight examples for robust deep learning. InInternational Conference on Machine Learning (ICML), pages 4334–4343. PMLR, 2018
work page 2018
-
[61]
Shiori Sagawa, Pang Wei Koh, Tatsunori B. Hashimoto, and Percy Liang. Distributionally robust neural networks for group shifts: On the importance of regularization for worst-case generalization. InInternational Conference on Learning Representations (ICLR), 2020
work page 2020
-
[62]
On penalty-based bilevel gradient descent method
Han Shen and Tianyi Chen. On penalty-based bilevel gradient descent method. InInternational conference on machine learning, pages 30992–31015. PMLR, 2023
work page 2023
-
[63]
On penalty-based bilevel gradient descent method
Han Shen, Quan Xiao, and Tianyi Chen. On penalty-based bilevel gradient descent method. Mathematical Programming, pages 1–51, 2025
work page 2025
-
[64]
A primal-dual ap- proach to bilevel optimization with multiple inner minima
Daouda Sow, Kaiyi Ji, Ziwei Guan, and Yingbin Liang. A primal-dual approach to bilevel optimization with multiple inner minima.arXiv preprint arXiv:2203.01123, 2022
-
[65]
An implicit gradient-type method for linearly constrained bilevel problems
Ioannis Tsaknakis, Prashant Khanduri, and Mingyi Hong. An implicit gradient-type method for linearly constrained bilevel problems. InICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 5438–5442. IEEE, 2022
work page 2022
-
[66]
C. Wah, S. Branson, P. Welinder, P. Perona, and S. Belongie. The caltech-ucsd birds-200-2011 dataset. Technical Report CNS-TR-2011-001, California Institute of Technology, 2011
work page 2011
-
[67]
Quan Xiao, Han Shen, Wotao Yin, and Tianyi Chen. Alternating implicit projected sgd and its efficient variants for equality-constrained bilevel optimization.arXiv preprint arXiv:2211.07096, 2022
-
[68]
Quan Xiao, Songtao Lu, and Tianyi Chen. An alternating optimization method for bilevel problems under the polyak-łojasiewicz condition.Advances in Neural Information Processing Systems, 36:63847–63873, 2023
work page 2023
-
[69]
Efficient gradient approximation method for constrained bilevel optimization
Siyuan Xu and Minghui Zhu. Efficient gradient approximation method for constrained bilevel optimization. InProceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 12509–12517, 2023
work page 2023
-
[70]
Provably faster algorithms for bilevel optimization
Junjie Yang, Kaiyi Ji, and Yingbin Liang. Provably faster algorithms for bilevel optimization. Advances in Neural Information Processing Systems, 34:13670–13682, 2021
work page 2021
-
[71]
Yan Yang, Bin Gao, and Ya-xiang Yuan. Bilevel reinforcement learning via the development of hyper-gradient without lower-level convexity.arXiv preprint arXiv:2405.19697, 2024. 14
-
[72]
Wei Yao, Haian Yin, Shangzhi Zeng, and Jin Zhang. Overcoming lower-level constraints in bilevel optimization: A novel approach with regularized gap functions. InThe Thirteenth International Conference on Learning Representations,
-
[73]
Wei Yao, Chengming Yu, Shangzhi Zeng, and Jin Zhang. Constrained bi-level optimization: Proximal lagrangian value function approach and hessian-free algorithm. InThe Twelfth International Conference on Learning Representations,
-
[74]
Ye, Xiaoming Yuan, Shangzhi Zeng, and Jin Zhang
Jane J. Ye, Xiaoming Yuan, Shangzhi Zeng, and Jin Zhang. Difference of convex algorithms for bilevel programs with applications in hyperparameter selection.Mathematical Programming, 198(2):1583–1616, 2023
work page 2023
-
[75]
Xuan Zhang, Necdet Serhat Aybat, and Mert Gurbuzbalaban. Sapd+: An accelerated stochastic method for nonconvex-concave minimax problems.Advances in Neural Information Processing Systems, 35:21668–21681, 2022
work page 2022
-
[76]
Xuan Zhang, Necdet Serhat Aybat, and Mert Gürbüzbalaban. Robust accelerated primal-dual methods for computing saddle points.SIAM Journal on Optimization, 34(1):1097–1130, 2024
work page 2024
-
[77]
Bolei Zhou, Àgata Lapedriza, Aditya Khosla, Aude Oliva, and Antonio Torralba. Places: A 10 million image database for scene recognition.IEEE Transactions on Pattern Analysis and Machine Intelligence, PP:1–1, 07 2017. doi: 10.1109/TPAMI.2017.2723009. 15 A Additional applications of(1) Model (1) can be potentially applied to not only many machine learning p...
-
[78]
3.pandqare proper closed convex and their proximal operators can be computed exactly
¯h(x, y) is σx-strongly convex in x and σy-strongly concave in y and L∇¯h-smooth on domp×domq. 3.pandqare proper closed convex and their proximal operators can be computed exactly. Subproblem (37) is an instance of (39) with ¯h(x, y)←h(x, y)−ϵ∥y−y 0∥2/(4Dq) +L ∇h∥x−x k∥2. (40) Additionally, when (33) satisfies Assumption C.1, (37) is an instance of (39) s...
-
[79]
is an O(ϵ)-KKT point of (1). E Proof of technical lemmas in Section 5 E.1 Proof of Lemma 5.3 Proof.Let’s consider the convex program min z1 ¯f(x1,z 1)s.t. ¯g(x1,z 1)≤0.(51) By Assumption 5.1.2, ¯f(x1,z 1) is convex in z1, ¯gi(x1,z 1) is convex in z1. By Assumption 5.1.4, Slater holds with margin G >0 . Then the strong duality holds and there exists a Lagr...
-
[80]
+λ T ¯g(x1,z ∗ 1)≤ ¯f(x1,z ∗
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.