Recognition: no theorem link
Rethinking Entropy Minimization in Test-Time Adaptation for Autoregressive Models
Pith reviewed 2026-05-12 00:45 UTC · model grok-4.3
The pith
Entropy minimization for test-time adaptation in autoregressive models decomposes into token-level policy gradient and entropy losses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
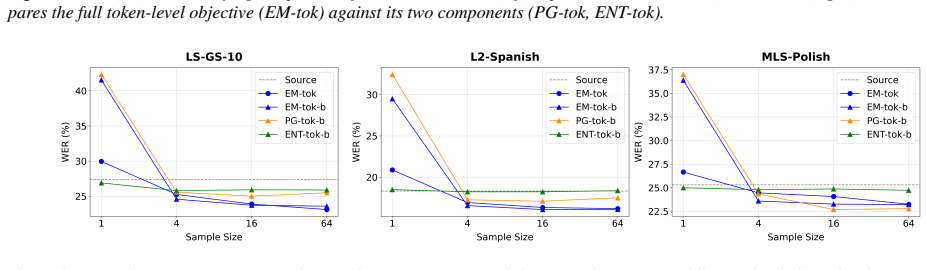
By deriving a rigorous formulation of entropy minimization tailored to autoregressive models, the exact objective naturally decomposes into a token-level policy gradient loss and a token-level entropy loss. Prior methods are reinterpreted as partial realizations of this unified formulation.
What carries the argument
The exact decomposition of the entropy minimization objective into a token-level policy gradient loss and a token-level entropy loss.
If this is right
- Previous test-time adaptation methods for autoregressive models are partial realizations of the unified entropy minimization objective.
- The full formulation can be applied to improve performance in automatic speech recognition across diverse conditions.
- Consistent gains are observed in more than 20 domains including acoustic noise, accents, and multilingual settings.
Where Pith is reading between the lines
- The token-level decomposition could be used to design more efficient adaptation algorithms for other sequence generation tasks like language modeling.
- This framework might help combine entropy minimization with other test-time techniques in a principled way.
- Similar derivations could apply to different autoregressive architectures beyond the Whisper model used in the experiments.
Load-bearing premise
The entropy minimization objective for autoregressive models admits an exact decomposition into token-level policy gradient and entropy losses without additional approximations.
What would settle it
Computing the entropy minimization objective directly on a small autoregressive model and checking if it equals the sum of the proposed token-level policy gradient loss and token-level entropy loss.
Figures



read the original abstract
Test-Time Adaptation (TTA) via entropy minimization (EM) has proven effective for classification tasks, yet its application to generative autoregressive models remains theoretically fragmented. Existing approaches typically rely on distinct heuristics, such as teacher forcing with pseudo labels or policy-gradient-based reinforcement learning, without a unified mathematical foundation. In this work, we resolve this discrepancy by deriving a rigorous formulation of EM tailored to autoregressive models. We show that the exact objective naturally decomposes into a token-level policy gradient loss and a token-level entropy loss, and we reinterpret prior methods as partial realizations of this unified formulation. Using Whisper ASR as a testbed, we demonstrate that our approach consistently improves performance across more than 20 diverse domains, including acoustic noise, accents, and multilingual settings.
Editorial analysis