Recognition: no theorem link
NeurIPS Should Require Reproducibility Standards for Frontier AI Safety Claims
Pith reviewed 2026-05-12 01:07 UTC · model grok-4.3
The pith
NeurIPS should require reproducibility standards for frontier AI safety claims, treating non-reproducibility as an evaluation-methodology failure.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
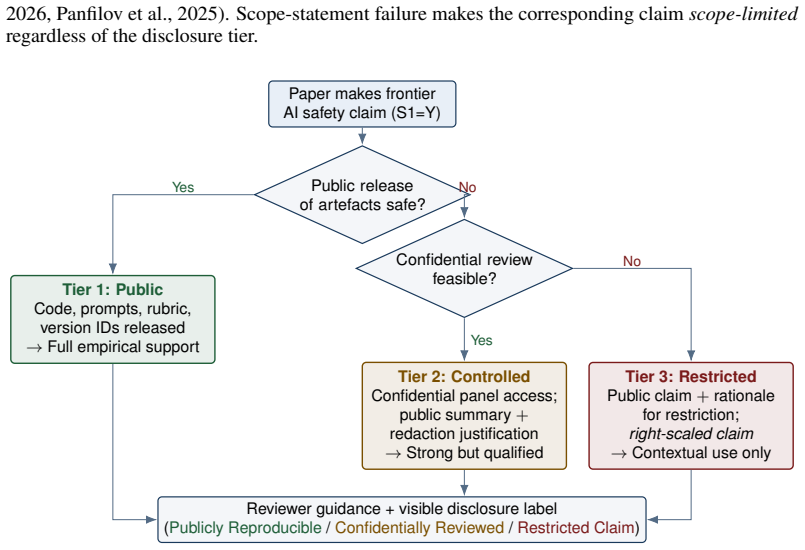
Frontier AI safety claims require reproducibility standards at NeurIPS because the most important assertions currently rest on the least accessible evidence. The paper establishes that non-reproducibility should be classified as an evaluation-methodology failure. It advances a three-tier disclosure framework distinguishing public, controlled, and claim-restricted levels, paired with mandatory claim inventories and a phased path to enforcement, so that the standards applied to the most consequential claims match those applied to the least consequential ones.
What carries the argument
The three-tier disclosure framework that distinguishes public, controlled, and claim-restricted disclosure, using a federated colloquium of qualified secure-review hosts for confidential cases.
If this is right
- Papers making safety claims would need to supply artefacts for public evaluation or grant access through controlled review.
- A mandatory claim inventory would force explicit listing of what is being asserted and its scope.
- Controlled review would cover claims whose full artefacts cannot be released publicly.
- Graduated sanctions would enforce the standards over a phased timeline.
Where Pith is reading between the lines
- The framework could be piloted on a narrow set of claims to test whether secure hosts can function without leaks or excessive delays.
- Adoption at NeurIPS might encourage similar requirements at other major AI conferences, raising baseline expectations across the field.
- Improved verifiability of safety claims could reduce reliance on developer self-assessment in governance decisions.
Load-bearing premise
A federated network of qualified secure-review hosts can be created and operated without leaking proprietary information or imposing prohibitive barriers on legitimate research.
What would settle it
An audit after policy adoption showing no measurable increase in the proportion of frontier AI safety papers at NeurIPS that supply sufficient artefacts or access for independent verification of their claims.
Figures

read the original abstract
Frontier AI safety claims - published assertions that a highly capable general-purpose model is below a threshold of concern, adequately mitigated, or suitable for release - increasingly shape model deployment, governance, and public trust. Yet the artefacts needed to evaluate them are routinely withheld, producing an evidential inversion: the most consequential claims in AI safety are often the least reproducible. This position paper argues that NeurIPS should require reproducibility standards for papers making such claims, treating non-reproducibility not as a transparency preference but as an evaluation-methodology failure. The 2026 International AI Safety Report [Bengio et al., 2026] concludes that reliable pre-deployment safety testing has become harder to conduct and that models now distinguish test from deployment contexts; the 2025 Foundation Model Transparency Index [Wan et al., 2025] reports a sector-average transparency score of 40/100 with no major developer adequately disclosing train-test overlap; contemporaneous measurement-theory work shows that attack-success-rate comparisons across systems are often founded on low-validity measurements [Chouldechova et al., 2025]. We propose a three-tier disclosure framework, distinguishing public, controlled, and claim-restricted disclosure, paired with a mandatory claim inventory, scope statements, and a phased implementation path with graduated sanctions. The framework treats secrecy and openness as endpoints of a spectrum, with controlled review (via a federated colloquium of qualified secure-review hosts) covering claims whose artefacts cannot be released publicly, and right-scaling claims whose artefacts cannot be reviewed even confidentially. The standard the community applies to its most consequential claims should be at least as high as the standard it applies to its least.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript argues that NeurIPS should mandate reproducibility standards for papers making frontier AI safety claims, treating non-reproducibility as an evaluation-methodology failure rather than a transparency preference. It cites the 2026 International AI Safety Report, the 2025 Foundation Model Transparency Index (sector-average score 40/100), and measurement-theory work on low-validity attack-success-rate comparisons to document an evidential inversion in which the most consequential claims are the least reproducible. The paper proposes a three-tier disclosure framework (public, controlled via a federated colloquium of qualified secure-review hosts, and claim-restricted), paired with a mandatory claim inventory, scope statements, and a phased implementation path with graduated sanctions.
Significance. If adopted, the standards could raise the evidential bar for high-stakes AI safety assertions that influence deployment and governance decisions, directly addressing the transparency and measurement-validity gaps documented in the cited external reports. The position draws on those reports but supplies no new empirical data or formal analysis quantifying the scale of the reproducibility problem or testing the proposed framework's effectiveness.
major comments (2)
- [three-tier disclosure framework] The controlled-disclosure tier of the three-tier framework (described after the citations to Bengio et al. 2026 and Wan et al. 2025) depends on a 'federated colloquium of qualified secure-review hosts' that can handle proprietary artifacts without leakage or prohibitive access barriers, yet the manuscript supplies no governance model, vetting criteria, security protocols, or risk analysis for realizing such a network at the required scale and expertise level. This assumption is load-bearing for the claim that non-reproducibility can be treated as an enforceable evaluation failure rather than a default for the most consequential assertions.
- [phased implementation path] The phased implementation path with graduated sanctions (outlined in the final paragraph of the abstract and corresponding section) does not specify enforcement mechanisms or fallback procedures when even confidential review is infeasible under the claim-restricted tier, leaving the central policy recommendation without a concrete path for the subset of frontier safety claims that cannot be reviewed at all.
minor comments (2)
- The term 'frontier AI safety claims' is used throughout without an explicit operational definition or scope boundaries, which could lead to inconsistent application across submissions.
- [references] The bibliography should include full details for all cited works (Bengio et al. 2026, Wan et al. 2025, Chouldechova et al. 2025) to support the position's reliance on external evidence.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review, which identifies key areas where the proposed framework requires further elaboration to be actionable. We address each major comment below and will incorporate targeted revisions to strengthen the manuscript while preserving its focus as a position paper.
read point-by-point responses
-
Referee: [three-tier disclosure framework] The controlled-disclosure tier of the three-tier framework (described after the citations to Bengio et al. 2026 and Wan et al. 2025) depends on a 'federated colloquium of qualified secure-review hosts' that can handle proprietary artifacts without leakage or prohibitive access barriers, yet the manuscript supplies no governance model, vetting criteria, security protocols, or risk analysis for realizing such a network at the required scale and expertise level. This assumption is load-bearing for the claim that non-reproducibility can be treated as an enforceable evaluation failure rather than a default for the most consequential assertions.
Authors: We agree that the manuscript introduces the federated colloquium concept at a high level without operational specifics. As a position paper, its primary aim is to establish the necessity of reproducibility standards rather than to deliver a fully engineered implementation blueprint. In revision, we will expand the relevant section to articulate high-level governance principles, including example vetting criteria (e.g., institutional accreditation with secure facilities and AI evaluation expertise), security protocols (e.g., federated secure enclaves and mandatory audit logs), and a concise risk analysis addressing leakage vectors with mitigations such as non-centralized hosting. These additions will clarify feasibility without claiming to resolve all implementation challenges, which we acknowledge require broader community and institutional collaboration. revision: partial
-
Referee: [phased implementation path] The phased implementation path with graduated sanctions (outlined in the final paragraph of the abstract and corresponding section) does not specify enforcement mechanisms or fallback procedures when even confidential review is infeasible under the claim-restricted tier, leaving the central policy recommendation without a concrete path for the subset of frontier safety claims that cannot be reviewed at all.
Authors: The referee correctly notes the absence of detailed enforcement and fallback procedures. The manuscript outlines the phased path and graduated sanctions conceptually to allow flexibility. We will revise to specify enforcement options, such as requiring a claim inventory and scope statement at submission with sanctions including rejection for non-compliance. For the claim-restricted tier where review proves infeasible, we will add explicit fallback language: authors must right-scale claims to exclude un-reviewable elements, rendering such assertions provisional and unsupported by the paper's evaluation methodology. This supplies a concrete path by tying un-reviewable claims to reduced evidential status rather than full safety conclusions. revision: partial
Circularity Check
No significant circularity detected
full rationale
This is a policy position paper with no mathematical derivations, fitted parameters, or self-referential definitions. The central argument relies on external citations to independent reports (Bengio et al. 2026, Wan et al. 2025, Chouldechova et al. 2025) and proposes an original three-tier disclosure framework as a normative recommendation. No load-bearing step reduces by construction to the paper's own inputs, self-citations, or renamed empirical patterns. The proposal is self-contained as an independent policy claim evaluated against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Reliable pre-deployment safety testing has become harder and models now distinguish test from deployment contexts.
- domain assumption Sector-average transparency is low and no major developer adequately discloses train-test overlap.
Reference graph
Works this paper leans on
-
[1]
Frontier AI regulation: Managing emerging risks to public safety.arXiv preprint arXiv:2307.03718,
Markus Anderljung, Joslyn Barnhart, Anton Korinek, et al. Frontier AI regulation: Managing emerging risks to public safety.arXiv preprint arXiv:2307.03718,
-
[2]
Claude mythos preview: Frontier red team report and project glasswing
Anthropic. Claude mythos preview: Frontier red team report and project glasswing. Technical report, Anthropic, 2026a. https://red.anthropic.com/2026/mythos-preview/; announcement at https://www.anthropic.com/glasswing. Anthropic. Responsible scaling policy (version 3.1, april 2026 update). Technical report, Anthropic, 2026b.https://www.anthropic.com/respo...
work page 2026
-
[3]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, et al. Constitutional AI: Harmlessness from AI feedback. arXiv:2212.08073,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Technical Report DSIT 2026/001, UK Department for Science, Innovation and Technology,
work page 2026
-
[5]
Rishi Bommasani, Scott Singer, et al
arXiv:2510.00075. Rishi Bommasani, Scott Singer, et al. The California report on frontier AI policy. Technical report, Joint California Policy Working Group on AI Frontier Models,
-
[6]
Feder Cooper, Markus Anderljung, Stephen Casper, Anka Reuel, Rishi Bommasani, et al
Miles Brundage, Noemi Dreksler, Aidan Homewood, Sean McGregor, Patricia Paskov, Conrad Stosz, Girish Sastry, A. Feder Cooper, Markus Anderljung, Stephen Casper, Anka Reuel, Rishi Bommasani, et al. Frontier AI auditing: Toward rigorous third-party assessment of safety and security practices at leading AI companies.arXiv preprint arXiv:2601.11699,
-
[7]
Benjamin Bucknall, Robert Trager, and Michael Osborne. Position: Ensuring mutual privacy is necessary for effective external evaluation of proprietary AI systems. arXiv:2503.01470,
-
[8]
Pavel Dolin, Weizhi Li, Gautam Dasarathy, and Visar Berisha
arXiv:2601.18076. Pavel Dolin, Weizhi Li, Gautam Dasarathy, and Visar Berisha. Statistically valid post-deployment monitoring should be standard for AI-based digital health. InNeurIPS Position Paper Track,
-
[9]
arXiv:2506.05701. European AI Office. General-purpose AI code of practice. Technical report, European Commission,
-
[10]
Regulation (EU) 2024/1689 on artificial intelligence (AI Act)
European Parliament and Council. Regulation (EU) 2024/1689 on artificial intelligence (AI Act). Technical report, Official Journal of the European Union,
work page 2024
-
[11]
ac.uk/publications/claude-mythos-future-cybersecurity
https://cetas.turing. ac.uk/publications/claude-mythos-future-cybersecurity. Aidan Homewood, Sophie Williams, Noemi Dreksler, John Lidiard, Malcolm Murray, Lennart Heim, Marta Ziosi, Seán Ó hÉigeartaigh, Michael Chen, Kevin Wei, Christoph Winter, Miles Brundage, Ben Garfinkel, and Jonas Schuett. Third-party compliance reviews for frontier AI safety framew...
-
[12]
IASEAI’26: Second annual conference of the international association for safe & ethical AI
IASEAI. IASEAI’26: Second annual conference of the international association for safe & ethical AI. Paris, 24–26 February 2026,
work page 2026
-
[13]
Delhi declaration: New delhi frontier AI impact commitments
India AI Impact Summit. Delhi declaration: New delhi frontier AI impact commitments. India AI Impact Summit, February 2026,
work page 2026
-
[14]
Responsible reporting for frontier AI development.arXiv preprint arXiv:2404.02675,
Noam Kolt, Markus Anderljung, Joslyn Barnhart, et al. Responsible reporting for frontier AI development.arXiv preprint arXiv:2404.02675,
-
[15]
STREAM (chembio): A standard for transparently reporting evaluations in AI model reports
Tegan McCaslin et al. STREAM (chembio): A standard for transparently reporting evaluations in AI model reports. arXiv:2508.09853,
-
[16]
Updates from the NeurIPS 2025 Position Paper Track
NeurIPS 2025 Position Paper Track Chairs. Updates from the NeurIPS 2025 Position Paper Track. NeurIPS Blog, June 2025,
work page 2025
-
[17]
What’s new for the Position Paper Track at NeurIPS
NeurIPS 2026 Position Paper Track Chairs. What’s new for the Position Paper Track at NeurIPS
work page 2026
-
[18]
NeurIPS Blog, March 2026,
work page 2026
- [19]
-
[20]
Strategic dishonesty can undermine AI safety evaluations of frontier LLMs
Alexander Panfilov, Evgenii Kortukov, Kristina Nikoli´c, Matthias Bethge, Sebastian Lapuschkin, Wo- jciech Samek, Ameya Prabhu, Maksym Andriushchenko, and Jonas Geiping. Strategic dishonesty can undermine AI safety evaluations of frontier LLMs. arXiv:2509.18058,
-
[21]
arXiv:2506.19882. Seoul AI Summit. Frontier AI safety commitments. Seoul AI Summit Communiqué,
-
[22]
Michelle Vaccaro, Jaeyoon Song, Abdullah Almaatouq, and Michiel A
https://www.aisi.gov.uk/blog/ our-evaluation-of-claude-mythos-previews-cyber-capabilities. Michelle Vaccaro, Jaeyoon Song, Abdullah Almaatouq, and Michiel A. Bakker. Evaluating human-AI safety: A framework for measuring harmful capability uplift. InarXiv:2603.26676,
-
[23]
The 2025 foundation model transparency index
Alexander Wan, Rishi Bommasani, Kevin Klyman, and Percy Liang. The 2025 foundation model transparency index. Technical report, Stanford CRFM,
work page 2025
-
[24]
general-purpose AI models with systemic risk
12 A Notes and Definitions Note 1.Frontier vs. AGI.The EU AI Act, UK AI Safety Framework, and NIST AI RMF organise obligations around “general-purpose AI models with systemic risk” and “frontier models”, both operationally defined categories, rather than “AGI.” Note 2.The ML Reproducibility Checklist was introduced at NeurIPS 2019 following Joelle Pineau’...
work page 2019
-
[25]
“Rigor in AI” (six-pillar framework) Identifies methodological, epistemic, normative, conceptual, reporting, and in- terpretative rigor as distinct dimensions. Present paper directly operationalises reporting rigorfor the highest-stakes claim category at NeurIPS. Pattern across the precedentsAll five address a common underlying concern: the evidence on wh...
work page 2025
-
[26]
Red-teaming generates evidence; it does not impose disclosure standards on the resulting claims
show output-based red-team evalua- tions can be defeated by strategically dishonest model behaviour. Red-teaming generates evidence; it does not impose disclosure standards on the resulting claims. Pre- submission No, comple- mentary Tiered repro- ducibility (this paper) Operates at review time at NeurIPS. Forces explicit dec- laration of what evidence su...
work page 2025
-
[27]
shows that the bottleneck is not absence of evaluation methods but absence of disclosure norms that match claim strength. A frontier lab can run a sophisticated red-team exercise, commission an external audit, and then publish a paper at NeurIPS reporting only summary statistics. Standardised benchmarks, third-party audits, and red-teaming all have valuab...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.