Recognition: no theorem link
Where Reliability Lives in Vision-Language Models: A Mechanistic Study of Attention, Hidden States, and Causal Circuits
Pith reviewed 2026-05-12 00:53 UTC · model grok-4.3
The pith
Reliability in vision-language models is legible from hidden-state geometry and late-layer circuits, not attention sharpness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In 3-7B VLMs, attention structure is a near-zero predictor of answer correctness (R_pb approximately 0), while hidden-state linear probes and layer-wise margin formation allow reliable readout, and causal ablations show late-fusion models concentrate reliability in a small set of late neurons whereas early-fusion models distribute it widely enough to tolerate loss of half the peak-layer dimension with minimal accuracy drop.
What carries the argument
The VLM Reliability Probe (VRP) pipeline that jointly measures attention-map statistics, hidden-state geometry, self-consistency, and top-k neuron ablations against a binary correctness label on POPE-style tasks.
If this is right
- Linear probes on late hidden states can serve as lightweight, training-free monitors for answer reliability.
- Early-fusion architectures absorb destruction of roughly half their peak-layer hidden dimension with at most one-point accuracy loss.
- Late-fusion models lose 8-plus points of object-identification accuracy after ablating only their top-five reliability neurons.
- Self-consistency across ten generations remains the highest-cost but strongest behavioral predictor of correctness.
Where Pith is reading between the lines
- Deployed reliability monitoring should prioritize internal hidden-state readouts over attention visualizations.
- Fusion timing in model architecture determines whether reliability is localized and therefore vulnerable to targeted internal edits.
- The same probe methodology could be applied to larger VLMs to test whether reliability localization changes with scale.
Load-bearing premise
The chosen masking thresholds, neuron counts, and linear-probe setup in the VRP pipeline isolate genuine causal reliability mechanisms rather than dataset-specific artifacts at the 3-7B scale.
What would settle it
Re-running the attention-versus-hidden-state correlation and ablation experiments on a new VLM family or non-POPE task where attention sharpness would show a strong positive correlation with correctness.
Figures





read the original abstract
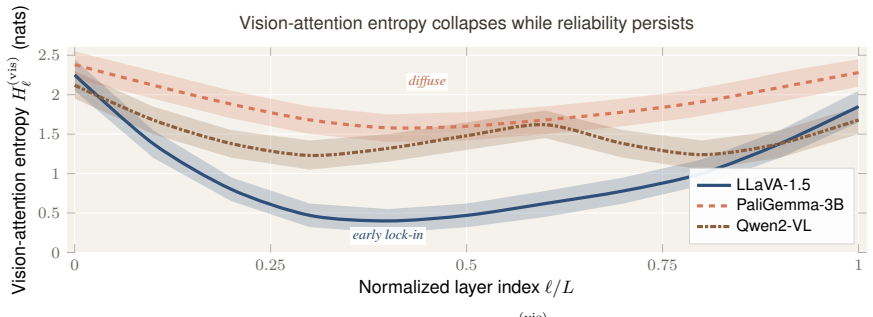
A pervasive intuition holds that vision-language models (VLMs) are most trustworthy when their attention maps look sharp: concentrated attention on the queried region should imply a confident, calibrated answer. We test this Attention-Confidence Assumption directly. We instrument three open-weight VLM families (LLaVA-1.5, PaliGemma, Qwen2-VL; 3-7B parameters) with a unified mechanistic pipeline -- the VLM Reliability Probe (VRP) -- that compares attention structure, generation dynamics, and hidden-state geometry against a single correctness label. Three results emerge. (i) Attention structure is a near-zero predictor of correctness (R_pb(C_k,y)=0.001, 95% CI [-0.034,0.036]; R_pb(H_s,y)=-0.012, [-0.047,0.024] on a pooled n=3,090 split), even though attention remains causally necessary for feature extraction (top-30% patch masking drops accuracy by 8.2-11.3 pp, p<0.001). (ii) Reliability becomes legible later in the computation: a single hidden-state linear probe reaches AUROC>0.95 on POPE for two of three families, and self-consistency at K=10 is the strongest behavioral predictor we measure at 10x inference cost (R_pb=0.43). (iii) Causal neuron-level ablations expose a sharp architectural split with direct monitor-design implications: late-fusion LLaVA concentrates reliability in a fragile late bottleneck (-8.3 pp object-identification accuracy after top-5 probe-neuron ablation), whereas early-fusion PaliGemma and Qwen2-VL distribute it widely and absorb destruction of ~50% of their peak-layer hidden dimension with <=1 pp degradation. The takeaway is narrow but consequential: in 3-7B VLMs, reliability is read more reliably off hidden-state geometry, layer-wise margin formation, and sparse late-layer circuits than off attention-map sharpness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper tests the Attention-Confidence Assumption in 3-7B VLMs (LLaVA-1.5, PaliGemma, Qwen2-VL) via the VLM Reliability Probe (VRP) pipeline. It reports near-zero point-biserial correlations between attention structure and correctness (R_pb(C_k,y)=0.001), high AUROC (>0.95) for hidden-state linear probes on POPE-style tasks, strong self-consistency prediction at K=10, and an architectural split where late-fusion LLaVA shows fragile late-layer bottlenecks under neuron ablation while early-fusion models are more robust.
Significance. If the results hold, the work supplies a concrete mechanistic counterexample to the widespread use of attention-map sharpness as a reliability signal in VLMs. The multi-family comparison, causal ablations, and layer-wise geometry measurements offer a reusable template for locating reliability mechanisms. The negative result on attention and the positive results on hidden-state probes are directly actionable for monitor design.
major comments (1)
- [VRP Pipeline / Methods] VRP Pipeline section: The pipeline fixes three load-bearing thresholds (top-30% patch masking to demonstrate necessity, top-5 probe neurons for ablation, K=10 for self-consistency) with no sensitivity analysis or justification. Because the central claim—that hidden-state geometry and late circuits are superior to attention—rests on the magnitude and statistical significance of the accuracy drops (8.2-11.3 pp) and the architectural fragility split (-8.3 pp for LLaVA), different cutoffs could materially change the reported effect sizes and the conclusion that reliability is concentrated versus distributed.
minor comments (3)
- [Abstract] Abstract: the pooled n=3,090 and exact POPE variant should be stated explicitly rather than left as 'POPE-style'.
- [Results] Results tables: ensure all R_pb and AUROC entries include the full 95% CI and the exact probe training protocol (train/test split, regularization).
- [Notation / §3] Notation: define C_k and H_s on first use and clarify whether they are computed on the same samples used for the linear probes.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the VRP pipeline. We address the concern about fixed thresholds and lack of sensitivity analysis below, and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [VRP Pipeline / Methods] VRP Pipeline section: The pipeline fixes three load-bearing thresholds (top-30% patch masking to demonstrate necessity, top-5 probe neurons for ablation, K=10 for self-consistency) with no sensitivity analysis or justification. Because the central claim—that hidden-state geometry and late circuits are superior to attention—rests on the magnitude and statistical significance of the accuracy drops (8.2-11.3 pp) and the architectural fragility split (-8.3 pp for LLaVA), different cutoffs could materially change the reported effect sizes and the conclusion that reliability is concentrated versus distributed.
Authors: We agree that sensitivity analysis is necessary to substantiate the robustness of our findings. In the revised manuscript, we will include additional experiments varying the top patch masking percentage (20-40%), the number of ablated probe neurons (top-3 to top-7), and the self-consistency sample size K (5-15). We will report the resulting accuracy drops, probe AUROCs, and architectural split metrics across these ranges, along with statistical significance. This will demonstrate that the key conclusions—near-zero attention correlation, high hidden-state predictability, and the late-fusion bottleneck—hold across reasonable threshold variations. We will also add justification for the original choices based on preliminary explorations. revision: yes
Circularity Check
No circularity: empirical measurements and interventions are self-contained
full rationale
The paper conducts a mechanistic empirical study by instrumenting VLMs with the VRP pipeline, computing direct correlations (R_pb between attention/hidden states and correctness labels), AUROC from linear probes, and accuracy drops from targeted ablations (top-30% masking, top-5 neuron removal). No equations, derivations, or self-citations reduce any reported predictor or 'prediction' to quantities defined by the same fitted parameters or inputs by construction. Methodological thresholds and POPE-style evaluation are external choices applied to model behavior, not self-referential loops. The derivation chain consists of independent measurements against held-out correctness labels, remaining self-contained.
Axiom & Free-Parameter Ledger
free parameters (3)
- K=10 =
10
- top-30% patch masking =
30
- top-5 probe-neuron ablation =
5
axioms (3)
- domain assumption Linear probes on hidden states extract reliability signals
- domain assumption Targeted neuron and patch ablations reveal causal contributions to reliability
- standard math Point-biserial correlation validly measures predictive strength of attention structure
Reference graph
Works this paper leans on
-
[1]
Flamingo: A visual language model for few-shot learning
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: A visual language model for few-shot learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[2]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Nora Belrose, Zach Furman, Logan Smith, Danny Halawi, Igor Ostrovsky, Lev McKinney, Stella Biderman, and Jacob Steinhardt. Eliciting latent predictions from transformers with the tuned lens.arXiv preprint arXiv:2303.08112, 2023
work page internal anchor Pith review arXiv 2023
-
[3]
PaliGemma: A versatile 3B VLM for transfer
Lucas Beyer, Andreas Steiner, André Susano Pinto, Alexander Kolesnikov, Xiao Wang, Daniel Salz, Maxim Neumann, Ibrahim Alabdul- mohsin, Michael Tschannen, Emanuele Bugliarello, et al. PaliGemma: A versatile 3B vision–language model for transfer.arXiv preprint arXiv:2407.07726, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Discovering latent knowledge in language models without supervision
Collin Burns, Haotian Ye, Dan Klein, and Jacob Steinhardt. Discovering latent knowledge in language models without supervision. In International Conference on Learning Representations (ICLR), 2023
work page 2023
-
[5]
Generic attention-model explainability for interpreting bi-modal and encoder–decoder transformers
Hila Chefer, Shir Gur, and Lior Wolf. Generic attention-model explainability for interpreting bi-modal and encoder–decoder transformers. In IEEE/CVF International Conference on Computer Vision (ICCV), 2021
work page 2021
-
[6]
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junnan Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven C. H. Hoi. InstructBLIP: Towards general-purpose vision–language models with instruction tuning. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[7]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, Yunsheng Wu, and Rongrong Ji. MME: A comprehensive evaluation benchmark for multimodal large language models.arXiv preprint arXiv:2306.13394, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Causal abstractions of neural networks
Atticus Geiger, Hanson Lu, Thomas Icard, and Christopher Potts. Causal abstractions of neural networks. InAdvances in Neural Information Processing Systems (NeurIPS), 2021. 11
work page 2021
-
[9]
Transformer feed-forward layers are key-value memories
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer feed-forward layers are key-value memories. InConference on Empirical Methods in Natural Language Processing (EMNLP), 2021
work page 2021
-
[10]
Transformer feed-forward layers build predictions by promoting concepts in the vocabulary space
Mor Geva, Avi Caciularu, Kevin Ro Wang, and Yoav Goldberg. Transformer feed-forward layers build predictions by promoting concepts in the vocabulary space. InConference on Empirical Methods in Natural Language Processing (EMNLP), 2022
work page 2022
-
[11]
Making the V in VQA matter: Elevating the role of image understanding in visual question answering
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the V in VQA matter: Elevating the role of image understanding in visual question answering. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017
work page 2017
-
[12]
Sarthak Jain and Byron C. Wallace. Attention is not explanation. InConference of the North American Chapter of the Association for Computational Linguistics (NAACL), 2019
work page 2019
-
[13]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation. InInternational Conference on Learning Representations (ICLR), 2023
work page 2023
-
[15]
SEED-Bench: Benchmarking Multimodal LLMs with Generative Comprehension
Bohao Li, Rui Wang, Guangzhi Wang, Yuying Ge, Yixiao Ge, and Ying Shan. SEED-Bench: Benchmarking multimodal LLMs with generative comprehension.arXiv preprint arXiv:2307.16125, 2023
work page internal anchor Pith review arXiv 2023
-
[16]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven C. H. Hoi. BLIP: Bootstrapping language-image pre-training for unified vision–language understanding and generation. InInternational Conference on Machine Learning (ICML), 2022
work page 2022
-
[17]
Evaluating object hallucination in large vision–language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision–language models. InConference on Empirical Methods in Natural Language Processing (EMNLP), 2023
work page 2023
-
[18]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[19]
Yuxuan Liu, Zhengyang Chen, Renqiu Wang, and Wayne Xin Zhao. Seeing but not believing: Vision–language models can attend correctly yet reason incorrectly.arXiv preprint arXiv:2510.17771, 2025
-
[20]
Understanding the language prior of LVLMs by contrasting chain-of-embedding
Liwei Long, Changdae Oh, Sungbin Park, and Sangdoo Li. Understanding the language prior of LVLMs by contrasting chain-of-embedding. arXiv preprint arXiv:2509.23050, 2025
-
[21]
Samuel Marks and Max Tegmark. The geometry of truth: Emergent linear structure in large language model representations of true/false datasets. InConference on Language Modeling (COLM), 2024
work page 2024
-
[22]
Interpreting GPT: The logit lens
Nostalgebraist. Interpreting GPT: The logit lens. LessWrong post, 2020
work page 2020
-
[23]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning (ICML), 2021
work page 2021
-
[24]
Object hallucination in image captioning
Anna Rohrbach, Lisa Anne Hendricks, Kaylee Burns, Trevor Darrell, and Kate Saenko. Object hallucination in image captioning. InConference on Empirical Methods in Natural Language Processing (EMNLP), 2018
work page 2018
-
[25]
Sofia Serrano and Noah A. Smith. Is attention interpretable? InAnnual Meeting of the Association for Computational Linguistics (ACL), 2019
work page 2019
-
[26]
Towards VQA models that can read
Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards VQA models that can read. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019
work page 2019
-
[27]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-VL: Enhancing vision–language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Self-consistency improves chain of thought reasoning in language models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InInternational Conference on Learning Representations (ICLR), 2023
work page 2023
-
[29]
Attention is not not explanation
Sarah Wiegreffe and Yuval Pinter. Attention is not not explanation. InConference on Empirical Methods in Natural Language Processing (EMNLP), 2019
work page 2019
-
[30]
MM-Vet: Evaluating Large Multimodal Models for Integrated Capabilities
Weihao Yu, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng Liu, Xinchao Wang, and Lijuan Wang. MM-Vet: Evaluating large multimodal models for integrated capabilities.arXiv preprint arXiv:2308.02490, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Lifeng Zhou, Wenjie Fu, Yujian Chen, Wei Liu, Zhe Lin, Shuicheng Yan, and Wei Chen. LLaV A-Bench: A benchmark for visual instruction following.arXiv preprint arXiv:2308.13692, 2023. Appendix A Detailed Experimental Setup Models and hooks.We instrument LLaV A-1.5-7B (32 layers, CLIP ViT-L/14, Vicuna-7B), PaliGemma-3B (18 layers, SigLIP, Gemma-2B), and Qwen...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.