Recognition: 3 theorem links
· Lean TheoremUMEDA: Unified Multi-modal Efficient Data Fusion for Privacy-Preserving Graph Federated Learning via Spectral-Gated Attention and Diffusion-Based Operator Alignment
Pith reviewed 2026-05-12 02:41 UTC · model grok-4.3
The pith
A shared continuous integral operator with low-rank spectral filtering lets federated clients align mismatched sensors in a common subspace while preserving privacy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
UMEDA reformulates graph federated aggregation as spectral signal processing on a shared continuous integral operator. Each client encodes its sensors with a linear-attention layer whose kernel spectrum undergoes low-rank filtering to suppress modality-specific residuals and align clients in a common low-rank subspace. The server aggregates updates via a diffusion model over the kernel's spectral coefficients, treating updates as discretizations of the shared operator rather than topology-bound weights. This absorbs varying graph sizes and missing modalities without node-wise correspondence. Anisotropic differential privacy projects noise preferentially into the null space of the signal to保留
What carries the argument
The continuous integral operator shared by all client nodes, whose low-rank spectral filtering in attention layers creates a common subspace and whose diffusion aggregation on spectral coefficients handles graph variation and missing data.
If this is right
- UMEDA achieves higher accuracy than prior federated baselines on MM-Fi and RELI11D under high modality heterogeneity.
- It converges faster and uses less communication bandwidth while satisfying tight privacy budgets.
- The diffusion aggregation step tolerates missing modalities and changing graph sizes without requiring explicit node correspondence.
- Anisotropic noise placement preserves dominant eigendirections so utility remains high under formal (ε, δ)-DP.
Where Pith is reading between the lines
- The operator-alignment view could transfer to other edge-AI tasks that combine heterogeneous sensor streams across devices.
- Treating model updates as discretizations of one shared operator may simplify dynamic client participation without rebuilding graphs each round.
- If the low-rank subspace property holds for additional modalities, the method could reduce the need for separate preprocessing pipelines in distributed multi-sensor systems.
Load-bearing premise
Clients can be modeled as sharing a single continuous integral operator whose low-rank spectral filtering suppresses modality-specific residuals enough to produce a common subspace for effective aggregation.
What would settle it
On the RELI11D out-of-distribution benchmark with deliberately increased modality heterogeneity, measure whether UMEDA's accuracy advantage over baselines vanishes once the low-rank spectral filter no longer produces a usable common subspace.
Figures




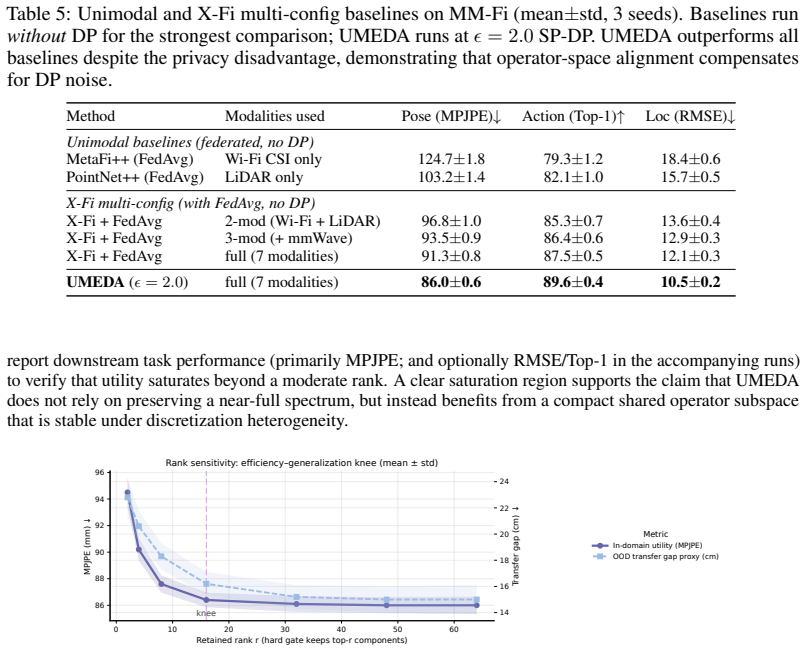
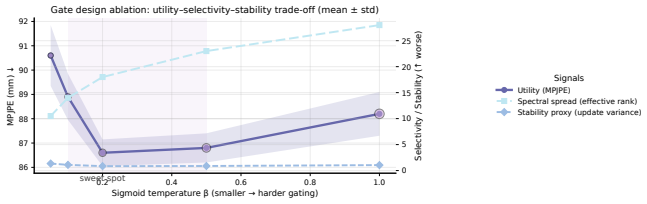





read the original abstract
Device-free localization trains models from heterogeneous wireless and visual sensors (e.g., Wi-Fi, LiDAR) distributed across edge devices. Federated learning offers a privacy-respecting framework, but is brittle when clients differ in sensor modality and resolution, when their data distributions drift, and when privacy noise destroys the structural signal needed for localization. We propose UMEDA, a graph federated learning framework in which clients form nodes of a global graph that share a continuous integral operator, and aggregation is reformulated as spectral signal processing on this operator. Each client encodes its local sensors with a linear-attention layer whose kernel spectrum is low-rank filtered, suppressing modality-specific residuals so clients with different sensors align in a common low-rank subspace. The server then aggregates client updates via a diffusion model over the kernel's spectral coefficients, treating updates as discretizations of a shared operator rather than topology-bound weights -- this absorbs varying graph sizes and missing modalities without node-wise correspondence. To balance privacy and utility, we add an anisotropic differential-privacy mechanism that projects noise preferentially into the null space of the signal subspace, preserving dominant eigendirections while ensuring formal $(\epsilon, \delta)$-DP under gradient clipping. On MM-Fi and the RELI11D out-of-distribution benchmark, UMEDA outperforms state-of-the-art federated baselines in accuracy, convergence, and communication efficiency, particularly under high modality heterogeneity and tight privacy budgets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes UMEDA, a graph federated learning framework for privacy-preserving multi-modal data fusion in device-free localization. Clients are modeled as nodes sharing a continuous integral operator. Local sensors are encoded with a linear-attention layer whose kernel spectrum is low-rank filtered to suppress modality-specific residuals and align in a common subspace. Aggregation is performed via a diffusion model over the kernel's spectral coefficients to handle varying graph sizes and missing modalities without node-wise correspondence. An anisotropic DP mechanism projects noise into the null space of the signal subspace. The paper claims superior performance over SOTA federated baselines on MM-Fi and RELI11D benchmarks in accuracy, convergence, and communication efficiency under high heterogeneity and tight privacy.
Significance. Should the proposed spectral alignment and diffusion aggregation prove effective, this work would offer a promising approach to federated learning with heterogeneous modalities and graphs, potentially improving privacy-utility trade-offs in edge sensor networks. The spectral perspective on FL aggregation is novel and could inspire further research if supported by rigorous derivations and experiments.
major comments (4)
- [Abstract] The claim that UMEDA outperforms state-of-the-art federated baselines on MM-Fi and the RELI11D benchmark is made without any numerical results, tables, error bars, ablation studies, or statistical tests. This is a load-bearing issue for the central empirical contribution.
- [Abstract] The key property that the diffusion aggregation absorbs varying graph sizes and missing modalities without requiring node-wise correspondence is asserted but not derived. No equations are provided for the continuous integral operator, the spectral-gated attention, or the diffusion model, making it unclear if this follows from the definitions or requires additional assumptions.
- [Abstract] The low-rank filtering of the attention kernel is claimed to suppress modality-specific residuals sufficiently for common-subspace alignment. However, no quantitative analysis or bound on the residual norm after filtering is given, which is critical under the high modality heterogeneity scenario highlighted in the benchmarks.
- [Abstract] The anisotropic differential-privacy mechanism is described as preserving dominant eigendirections while ensuring (ε, δ)-DP. No details on the projection implementation, the null space definition, or the formal privacy proof are supplied in the abstract.
minor comments (1)
- [Abstract] The title expands UMEDA but the abstract does not restate the full name, which could aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, indicating where we agree and the specific revisions we will make to the abstract and related sections to improve clarity and support for the claims.
read point-by-point responses
-
Referee: [Abstract] The claim that UMEDA outperforms state-of-the-art federated baselines on MM-Fi and the RELI11D benchmark is made without any numerical results, tables, error bars, ablation studies, or statistical tests. This is a load-bearing issue for the central empirical contribution.
Authors: We agree that the abstract would be strengthened by including key quantitative results. In the revised manuscript, we will update the abstract to report specific metrics such as accuracy gains, convergence improvements, and communication reductions (with error bars) on MM-Fi and RELI11D under the stated conditions. The full experimental tables, ablation studies, and statistical tests are already detailed in Sections 4 and 5. revision: yes
-
Referee: [Abstract] The key property that the diffusion aggregation absorbs varying graph sizes and missing modalities without requiring node-wise correspondence is asserted but not derived. No equations are provided for the continuous integral operator, the spectral-gated attention, or the diffusion model, making it unclear if this follows from the definitions or requires additional assumptions.
Authors: The abstract serves as a high-level summary. The continuous integral operator is defined in Section 3.1, the spectral-gated attention with low-rank filtering appears in Section 3.2 (including the kernel spectrum equations), and the diffusion aggregation over spectral coefficients is derived in Section 3.3, showing how it handles varying graph sizes and missing modalities without node-wise correspondence by operating on the shared operator rather than fixed topology. We will revise the abstract to include brief references to these sections and a concise statement of the property. revision: partial
-
Referee: [Abstract] The low-rank filtering of the attention kernel is claimed to suppress modality-specific residuals sufficiently for common-subspace alignment. However, no quantitative analysis or bound on the residual norm after filtering is given, which is critical under the high modality heterogeneity scenario highlighted in the benchmarks.
Authors: We acknowledge the value of quantitative support in the abstract. The manuscript provides a bound on the residual norm after low-rank filtering in Theorem 1 of Section 3.2, which shows suppression of modality-specific residuals by a factor of O(1/r) (r = rank) and is effective under high heterogeneity. We will add a reference to this result in the revised abstract. revision: yes
-
Referee: [Abstract] The anisotropic differential-privacy mechanism is described as preserving dominant eigendirections while ensuring (ε, δ)-DP. No details on the projection implementation, the null space definition, or the formal privacy proof are supplied in the abstract.
Authors: The projection implementation (into the null space of the signal subspace), null-space definition, and formal (ε, δ)-DP proof are provided in Section 3.4 and Appendix B. We will revise the abstract to include a brief description of the anisotropic projection and a reference to the privacy analysis. revision: yes
Circularity Check
Reformulation of aggregation via shared continuous integral operator makes absorption of graph-size variation and missing modalities hold by construction
specific steps
-
self definitional
[Abstract]
"clients form nodes of a global graph that share a continuous integral operator, and aggregation is reformulated as spectral signal processing on this operator. ... The server then aggregates client updates via a diffusion model over the kernel's spectral coefficients, treating updates as discretizations of a shared operator rather than topology-bound weights -- this absorbs varying graph sizes and missing modalities without node-wise correspondence."
The absorption property is asserted as a consequence of the reformulation, yet the reformulation itself defines aggregation in the spectral domain of the shared operator (independent of any specific graph topology or node-wise alignment). The benefit therefore holds by the modeling choice rather than by separate derivation or empirical verification outside the operator definition.
-
self definitional
[Abstract]
"Each client encodes its local sensors with a linear-attention layer whose kernel spectrum is low-rank filtered, suppressing modality-specific residuals so clients with different sensors align in a common low-rank subspace."
Alignment in a common subspace is presented as the outcome of low-rank filtering, but the filtering is chosen precisely to remove higher eigenmodes; the common subspace therefore follows tautologically once one assumes (without bound) that modality-specific residuals lie in those higher modes.
full rationale
The paper's core modeling choice—clients sharing a single continuous integral operator with aggregation performed as spectral processing and diffusion over its coefficients—directly entails the claimed invariance to topology, node correspondence, and modality dropout. This is presented as a derived benefit rather than an independent result. The low-rank spectral filtering step similarly produces a common subspace by the choice of filter rank and the assumption that residuals occupy higher modes. No external benchmarks, machine-checked theorems, or parameter-free derivations are invoked to establish these properties; they follow from the ansatz itself. This yields moderate circularity without rising to full self-definition of the final accuracy claims.
Axiom & Free-Parameter Ledger
free parameters (2)
- low-rank dimension of kernel spectrum
- privacy budget (ε, δ)
axioms (2)
- domain assumption Clients form nodes of a global graph that share a continuous integral operator
- ad hoc to paper Low-rank filtering of the attention kernel suppresses modality-specific residuals sufficiently for common-subspace alignment
invented entities (2)
-
Spectral-gated attention layer
no independent evidence
-
Diffusion model over kernel spectral coefficients
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
clients form nodes of a global graph that share a continuous integral operator, and aggregation is reformulated as spectral signal processing on this operator... low-rank filtered, suppressing modality-specific residuals so clients... align in a common low-rank subspace... diffusion model over the kernel’s spectral coefficients
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
anisotropic differential-privacy mechanism that projects noise preferentially into the null space of the signal subspace
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Diffusion-based Graph Neural Operator (Diff-GNO)... Spectral-Latent Diffusion... VE-SDE
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang
Martin Abadi, Andy Chu, Ian Goodfellow, H. Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang. Deep learning with differential privacy. InProceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, CCS ’16, page 308–318, New York, NY , USA, 2016. Association for Computing Machinery. ISBN 9781450341394. doi: 10.1145/297674...
-
[2]
Federated learning based on dynamic regularization
Durmus Alp Emre Acar, Yue Zhao, Ramon Matas, Matthew Mattina, Paul Whatmough, and Venkatesh Saligrama. Federated learning based on dynamic regularization. InInternational Conference on Learning Representations, 2021. URLhttps://openreview.net/forum?id=B7v4QMR6Z9w
work page 2021
-
[3]
Decoupled subgraph federated learning
Javad Aliakbari, Johan Östman, and Alexandre Graell i Amat. Decoupled subgraph federated learning. In The Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview. net/forum?id=v1rFkElnIn
work page 2025
-
[4]
mri: Multi-modal 3d human pose estimation dataset using mmwave, rgb-d, and inertial sensors
Sizhe An, Yin Li, and Umit Ogras. mri: Multi-modal 3d human pose estimation dataset using mmwave, rgb-d, and inertial sensors. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems, volume 35, pages 27414–27426. Curran As- sociates, Inc., 2022. URL https://proceedings.neurips.cc/pap...
work page 2022
-
[5]
Brendan McMahan, and Swaroop Ramaswamy
Galen Andrew, Om Thakkar, H. Brendan McMahan, and Swaroop Ramaswamy. Differentially private learning with adaptive clipping. InProceedings of the 35th International Conference on Neural Information Processing Systems, NIPS ’21, Red Hook, NY , USA, 2021. Curran Associates Inc. ISBN 9781713845393
work page 2021
-
[6]
xLSTM: Extended long short-term memory
Maximilian Beck, Korbinian Pöppel, Markus Spanring, Andreas Auer, Oleksandra Prudnikova, Michael K Kopp, Günter Klambauer, Johannes Brandstetter, and Sepp Hochreiter. xLSTM: Extended long short-term memory. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum?id=ARAxPPIAhq
work page 2024
-
[7]
Diffusion- free graph generation with next-scale prediction
Samuel Belkadi, Dat Minh Hong, Marian Chen, Miruna Cretu, Charles Harris, and Pietro Lio. Diffusion- free graph generation with next-scale prediction. InICML 2025 Generative AI and Biology (GenBio) Workshop, 2025. URLhttps://openreview.net/forum?id=7gwoULnSvH
work page 2025
-
[8]
K. A. Bonawitz, Vladimir Ivanov, Ben Kreuter, Antonio Marcedone, H. Brendan McMahan, Sarvar Patel, Daniel Ramage, Aaron Segal, and Karn Seth. Practical secure aggregation for federated learning on user-held data. InNIPS Workshop on Private Multi-Party Machine Learning, 2016. URL https: //arxiv.org/abs/1611.04482
work page Pith review arXiv 2016
-
[9]
mmbody benchmark: 3d body reconstruction dataset and analysis for millimeter wave radar
Anjun Chen, Xiangyu Wang, Shaohao Zhu, Yanxu Li, Jiming Chen, and Qi Ye. mmbody benchmark: 3d body reconstruction dataset and analysis for millimeter wave radar. InProceedings of the 30th ACM International Conference on Multimedia, pages 3501–3510, 2022
work page 2022
-
[10]
Immfusion: Robust mmwave-rgb fusion for 3d human body reconstruction in all weather conditions
Anjun Chen, Xiangyu Wang, Kun Shi, Shaohao Zhu, Bin Fang, Yingfeng Chen, Jiming Chen, Yuchi Huo, and Qi Ye. Immfusion: Robust mmwave-rgb fusion for 3d human body reconstruction in all weather conditions. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 2752–2758. IEEE, 2023
work page 2023
-
[11]
Fedbip: Heterogeneous one-shot federated learning with personalized latent diffusion models
Haokun Chen, Hang Li, Yao Zhang, Jinhe Bi, Gengyuan Zhang, Yueqi Zhang, Philip Torr, Jindong Gu, Denis Krompass, and V olker Tresp. Fedbip: Heterogeneous one-shot federated learning with personalized latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 30440–30450, 2025. URL https://ope...
work page 2025
-
[12]
X-fi: A modality-invariant foundation model for multimodal human sensing
Xinyan Chen and Jianfei Yang. X-fi: A modality-invariant foundation model for multimodal human sensing. InThe Thirteenth International Conference on Learning Representations, 2025. URL https: //openreview.net/forum?id=b42wmsdwmB. 10
work page 2025
-
[13]
Rethinking attention with performers
Krzysztof Marcin Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Quincy Davis, Afroz Mohiuddin, Lukasz Kaiser, David Benjamin Belanger, Lucy J Colwell, and Adrian Weller. Rethinking attention with performers. InInternational Conference on Learning Representations, 2021. URLhttps://openreview....
work page 2021
-
[14]
Exploiting shared representations for personalized federated learning
Liam Collins, Hamed Hassani, Aryan Mokhtari, and Sanjay Shakkottai. Exploiting shared representations for personalized federated learning. In Marina Meila and Tong Zhang, editors,Proceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, pages 2089–2099. PMLR, 18–24 Jul 2021. URL https://pr...
work page 2089
-
[15]
Gian, Tien Dac Lai, Thien Van Luong, Kok-Seng Wong, and Van-Dinh Nguyen
Toan D. Gian, Tien Dac Lai, Thien Van Luong, Kok-Seng Wong, and Van-Dinh Nguyen. Hpe-li: Wifi- enabled lightweight dual selective kernel convolution for human pose estimation. In Aleš Leonardis, Elisa Ricci, Stefan Roth, Olga Russakovsky, Torsten Sattler, and Gül Varol, editors,Computer Vision – ECCV 2024, pages 93–111, Cham, 2025. Springer Nature Switzer...
work page 2024
-
[16]
Training diffusion models with federated learning,
Matthijs de Goede, Bart Cox, and Jérémie Decouchant. Training diffusion models with federated learning,
- [17]
-
[18]
The algorithmic foundations of differential privacy
Cynthia Dwork and Aaron Roth. The algorithmic foundations of differential privacy.Found. Trends Theor. Comput. Sci., 9(3–4):211–407, August 2014. ISSN 1551-305X. doi: 10.1561/0400000042. URL https://doi.org/10.1561/0400000042
-
[19]
Federated graph machine learning: A survey of concepts, techniques, and applications.SIGKDD Explor
Xingbo Fu, Binchi Zhang, Yushun Dong, Chen Chen, and Jundong Li. Federated graph machine learning: A survey of concepts, techniques, and applications.SIGKDD Explor. Newsl., 24(2):32–47, December
-
[20]
ISSN 1931-0145. doi: 10.1145/3575637.3575644. URL https://doi.org/10.1145/3575637. 3575644
-
[21]
Inverting gradients - how easy is it to break privacy in federated learning? In H
Jonas Geiping, Hartmut Bauermeister, Hannah Dröge, and Michael Moeller. Inverting gradients - how easy is it to break privacy in federated learning? In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors,Advances in Neural Information Processing Systems, volume 33, pages 16937–16947. Cur- ran Associates, Inc., 2020. URL https://proceed...
work page 2020
-
[22]
R. C. Geyer, T. Klein, and M. Nabi. Differentially Private Federated Learning: A Client Level Perspective. ArXiv e-prints, December 2017
work page 2017
-
[23]
Fedgraphnn: A federated learning system and benchmark for graph neural networks,
Chaoyang He, Keshav Balasubramanian, Emir Ceyani, Carl Yang, Han Xie, Lichao Sun, Lifang He, Liangwei Yang, Philip S. Yu, Yu Rong, Peilin Zhao, Junzhou Huang, Murali Annavaram, and Salman Avestimehr. Fedgraphnn: A federated learning system and benchmark for graph neural networks, 2021. URLhttps://arxiv.org/abs/2104.07145
-
[24]
Agc-dp: Differential privacy with adaptive gaussian clipping for federated learning
Muhammad Ayat Hidayat, Yugo Nakamura, Billy Dawton, and Yutaka Arakawa. Agc-dp: Differential privacy with adaptive gaussian clipping for federated learning. In2023 24th IEEE International Conference on Mobile Data Management (MDM), pages 199–208, 2023. doi: 10.1109/MDM58254.2023.00042
-
[25]
Towards 3d human pose construction using wifi
Wenjun Jiang, Hongfei Xue, Chenglin Miao, Shiyang Wang, Sen Lin, Chong Tian, Srinivasan Murali, Haochen Hu, Zhi Sun, and Lu Su. Towards 3d human pose construction using wifi. InProceedings of the 26th Annual International Conference on Mobile Computing and Networking, MobiCom ’20, New York, NY , USA, 2020. Association for Computing Machinery. ISBN 9781450...
-
[26]
Sai Praneeth Karimireddy, Satyen Kale, Mehryar Mohri, Sashank J. Reddi, Sebastian U. Stich, and Ananda Theertha Suresh. Scaffold: stochastic controlled averaging for federated learning. InProceedings of the 37th International Conference on Machine Learning, ICML’20. JMLR.org, 2020
work page 2020
-
[27]
Differentially private federated learning with time-adaptive privacy spending, 2025
Shahrzad Kiani, Nupur Kulkarni, Adam Dziedzic, Stark Draper, and Franziska Boenisch. Differentially private federated learning with time-adaptive privacy spending, 2025. URL https://arxiv.org/abs/ 2502.18706
-
[28]
Neural operator: learning maps between function spaces with applications to pdes.J
Nikola Kovachki, Zongyi Li, Burigede Liu, Kamyar Azizzadenesheli, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Neural operator: learning maps between function spaces with applications to pdes.J. Mach. Learn. Res., 24(1), January 2023. ISSN 1532-4435
work page 2023
-
[29]
Hupr: A benchmark for human pose estimation using millimeter wave radar
Shih-Po Lee, Niraj Prakash Kini, Wen-Hsiao Peng, Ching-Wen Ma, and Jenq-Neng Hwang. Hupr: A benchmark for human pose estimation using millimeter wave radar. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 5715–5724, January 2023. 11
work page 2023
-
[30]
Model-contrastive federated learning
Qinbin Li, Bingsheng He, and Dawn Song. Model-contrastive federated learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021
work page 2021
-
[31]
Tian Li, Anit Kumar Sahu, Manzil Zaheer, Maziar Sanjabi, Ameet Talwalkar, and Virginia Smith. Federated optimization in heterogeneous networks.Proceedings of Machine learning and systems, 2:429–450, 2020
work page 2020
-
[32]
FedBN: Federated learning on non-IID features via local batch normalization
Xiaoxiao Li, Meirui JIANG, Xiaofei Zhang, Michael Kamp, and Qi Dou. FedBN: Federated learning on non-IID features via local batch normalization. InInternational Conference on Learning Representations,
-
[33]
URLhttps://openreview.net/forum?id=6YEQUn0QICG
-
[34]
Fedgta: Topology- aware averaging for federated graph learning.Proc
Xunkai Li, Zhengyu Wu, Wentao Zhang, Yinlin Zhu, Rong-Hua Li, and Guoren Wang. Fedgta: Topology- aware averaging for federated graph learning.Proc. VLDB Endow., 17(1):41–50, September 2023. ISSN 2150-8097. doi: 10.14778/3617838.3617842. URL https://doi.org/10.14778/3617838.3617842
-
[35]
Openfgl: A comprehensive benchmarks for federated graph learning,
Xunkai Li, Yinlin Zhu, Boyang Pang, Guochen Yan, Yeyu Yan, Zening Li, Zhengyu Wu, Wentao Zhang, Rong-Hua Li, and Guoren Wang. Openfgl: A comprehensive benchmarks for federated graph learning,
- [36]
-
[37]
Multipole graph neural operator for parametric partial differential equations
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Multipole graph neural operator for parametric partial differential equations. InAdvances in Neural Information Processing Systems, 2020. URL https://papers.nips. cc/paper/2020/hash/146d4b7ed1fdb30f9ddb0a4c4d4f0f4e-Abstract.html
work page 2020
-
[38]
Rui Liu, Pengwei Xing, Zichao Deng, Anran Li, Cuntai Guan, and Han Yu. Federated graph neural networks: Overview, techniques, and challenges.IEEE Transactions on Neural Networks and Learning Systems, 36(3):4279–4295, 2025. doi: 10.1109/TNNLS.2024.3360429
-
[39]
Communication-Efficient Learning of Deep Networks from Decentralized Data
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Aarti Singh and Jerry Zhu, editors,Proceedings of the 20th International Conference on Artificial Intelligence and Statis- tics, volume 54 ofProceedings of Machine Learning Research, pages 1273...
work page 2017
-
[40]
Locfree: Wifi rtt-based device-free indoor localization system
Mohamed Mohsen, Hamada Rizk, Hirozumi Yamaguchi, and Moustafa Youssef. Locfree: Wifi rtt-based device-free indoor localization system. InProceedings of the 2nd ACM SIGSPATIAL International Workshop on Spatial Big Data and AI for Industrial Applications, GeoIndustry ’23, page 32–40, New York, NY , USA, 2023. Association for Computing Machinery. ISBN 979840...
-
[41]
Qi, Li Yi, Hao Su, and Leonidas J
Charles R. Qi, Li Yi, Hao Su, and Leonidas J. Guibas. Pointnet++: deep hierarchical feature learning on point sets in a metric space. InProceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, page 5105–5114, Red Hook, NY , USA, 2017. Curran Associates Inc. ISBN 9781510860964
work page 2017
-
[42]
Xinping Rao, Zhenzhen Luo, Yong Luo, Yugen Yi, Gang Lei, and Yuanlong Cao. Mffaloc: Csi-based multifeatures fusion adaptive device-free passive indoor fingerprinting localization.IEEE Internet of Things Journal, 11(8):14100–14114, 2024. doi: 10.1109/JIOT.2023.3339797
-
[43]
Sashank J. Reddi, Zachary Charles, Manzil Zaheer, Zachary Garrett, Keith Rush, Jakub Koneˇcný, Sanjiv Kumar, and Hugh Brendan McMahan. Adaptive federated optimization. InInternational Conference on Learning Representations, 2021. URLhttps://openreview.net/forum?id=LkFG3lB13U5
work page 2021
-
[44]
Damien Robert, Hugo Raguet, and Loic Landrieu. Efficient 3d semantic segmentation with superpoint transformer.Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023
work page 2023
-
[45]
Hot- pluggable federated learning: Bridging general and personalized FL via dynamic selection
Lei Shen, Zhenheng Tang, Lijun Wu, Yonggang Zhang, Xiaowen Chu, Tao Qin, and Bo Han. Hot- pluggable federated learning: Bridging general and personalized FL via dynamic selection. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview. net/forum?id=B8akWa62Da
work page 2025
-
[46]
Point-gnn: Graph neural network for 3d object detection in a point cloud
Weijing Shi and Ragunathan (Raj) Rajkumar. Point-gnn: Graph neural network for 3d object detection in a point cloud. InThe IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2020
work page 2020
-
[47]
Personalizing federated medical image segmentation via local calibration
Jiacheng Wang, Yueming Jin, and Liansheng Wang. Personalizing federated medical image segmentation via local calibration. InEuropean Conference on Computer Vision, pages 456–472. Springer, 2022. 12
work page 2022
-
[48]
Jianyu Wang, Qinghua Liu, Hao Liang, Gauri Joshi, and H. Vincent Poor. Tackling the objective in- consistency problem in heterogeneous federated optimization. InProceedings of the 34th International Conference on Neural Information Processing Systems, NIPS ’20, Red Hook, NY , USA, 2020. Curran Associates Inc. ISBN 9781713829546
work page 2020
-
[49]
Graph attention convolution for point cloud semantic segmentation
Lei Wang, Yuchun Huang, Yaolin Hou, Shenman Zhang, and Jie Shan. Graph attention convolution for point cloud semantic segmentation. In2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10288–10297, 2019. doi: 10.1109/CVPR.2019.01054
-
[50]
Li, Madian Khabsa, Han Fang, and Hao Ma
Sinong Wang, Belinda Z. Li, Madian Khabsa, Han Fang, and Hao Ma. Linformer: Self-attention with linear complexity, 2020
work page 2020
-
[51]
Tackling the data heterogeneity in asynchronous federated learning with cached update calibration
Yujia Wang, Yuanpu Cao, Jingcheng Wu, Ruoyu Chen, and Jinghui Chen. Tackling the data heterogeneity in asynchronous federated learning with cached update calibration. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=4aywmeb97I
work page 2024
-
[52]
Ravankar, and Abhijeet Ravankar
Yun-Ting Wang, Chao-Chung Peng, Ankit A. Ravankar, and Abhijeet Ravankar. A single lidar-based feature fusion indoor localization algorithm.Sensors, 18(4), 2018. ISSN 1424-8220. doi: 10.3390/s18041294. URLhttps://www.mdpi.com/1424-8220/18/4/1294
-
[53]
Zhou Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli. Image quality assessment: from error visibility to structural similarity.Trans. Img. Proc., 13(4):600–612, April 2004. ISSN 1057-7149. doi: 10.1109/TIP.2003.819861. URLhttps://doi.org/10.1109/TIP.2003.819861
-
[54]
Shangyin Weng, Lei Zhang, Xiaoshuai Zhang, and Muhammad Ali Imran. Faster convergence on differential privacy-based federated learning.IEEE Internet of Things Journal, 11(12):22578–22589, 2024. doi: 10.1109/JIOT.2024.3383226
-
[55]
Federated graph classification over non-iid graphs
Han Xie, Jing Ma, Li Xiong, and Carl Yang. Federated graph classification over non-iid graphs. In Proceedings of the 35th International Conference on Neural Information Processing Systems, NIPS ’21, Red Hook, NY , USA, 2021. Curran Associates Inc. ISBN 9781713845393
work page 2021
-
[56]
Nyströmformer: A nyström-based algorithm for approximating self-attention
Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, and Vikas Singh. Nyströmformer: A nyström-based algorithm for approximating self-attention. 2021
work page 2021
-
[57]
Discrete-state continuous-time diffusion for graph generation
Zhe Xu, Ruizhong Qiu, Yuzhong Chen, Huiyuan Chen, Xiran Fan, Menghai Pan, Zhichen Zeng, Ma- hashweta Das, and Hanghang Tong. Discrete-state continuous-time diffusion for graph generation. In Proceedings of the 38th International Conference on Neural Information Processing Systems, NIPS ’24, Red Hook, NY , USA, 2024. Curran Associates Inc. ISBN 9798331314385
work page 2024
-
[58]
Reli11d: A comprehensive multimodal human motion dataset and method
Ming Yan, Yan Zhang, Shuqiang Cai, Shuqi Fan, Xincheng Lin, Yudi Dai, Siqi Shen, Chenglu Wen, Lan Xu, Yuexin Ma, and Cheng Wang. Reli11d: A comprehensive multimodal human motion dataset and method. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2250–2262, June 2024
work page 2024
-
[59]
Mm-fi: Multi-modal non-intrusive 4d human dataset for versatile wireless sensing
Jianfei Yang, He Huang, Yunjiao Zhou, Xinyan Chen, Yuecong Xu, Shenghai Yuan, Han Zou, Chris Xiaox- uan Lu, and Lihua Xie. Mm-fi: Multi-modal non-intrusive 4d human dataset for versatile wireless sensing. InThirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track,
-
[60]
URLhttps://openreview.net/forum?id=1uAsASS1th
-
[61]
Gated delta networks: Improving mamba2 with delta rule
Songlin Yang, Jan Kautz, and Ali Hatamizadeh. Gated delta networks: Improving mamba2 with delta rule. InThe Thirteenth International Conference on Learning Representations, 2025. URL https: //openreview.net/forum?id=r8H7xhYPwz
work page 2025
-
[62]
idlg: Improved deep leakage from gradients.arXiv preprint arXiv:2001.02610, 2020
Bo Zhao, Konda Reddy Mopuri, and Hakan Bilen. idlg: Improved deep leakage from gradients, 2020. URLhttps://arxiv.org/abs/2001.02610
-
[63]
Gtnet: Graph transformer network for 3d point cloud classification and semantic segmentation, 2024
Wei Zhou, Qian Wang, Weiwei Jin, Xinzhe Shi, and Ying He. Gtnet: Graph transformer network for 3d point cloud classification and semantic segmentation, 2024. URL https://arxiv.org/abs/2305. 15213
work page 2024
-
[64]
Yunjiao Zhou, He Huang, Shenghai Yuan, Han Zou, Lihua Xie, and Jianfei Yang. Metafi++: Wifi-enabled transformer-based human pose estimation for metaverse avatar simulation.IEEE Internet of Things Journal, 10(16):14128–14136, 2023. doi: 10.1109/JIOT.2023.3262940
-
[65]
Fedtad: topology-aware data-free knowledge distillation for subgraph federated learning
Yinlin Zhu, Xunkai Li, Zhengyu Wu, Di Wu, Miao Hu, and Rong-Hua Li. Fedtad: topology-aware data-free knowledge distillation for subgraph federated learning. InProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, IJCAI ’24, 2024. ISBN 978-1-956792-04-1. doi: 10.24963/ijcai.2024/632. URLhttps://doi.org/10.24963/ijcai.20...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.