Recognition: 2 theorem links
· Lean TheoremCAMAL: Improving Attention Alignment and Faithfulness with Segmentation Masks
Pith reviewed 2026-05-12 00:54 UTC · model grok-4.3
The pith
CAMAL uses segmentation masks as an auxiliary regularizer to lift attention faithfulness by over 35 percent in vision models
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CAMAL extracts the model's attention for each image during training and compares the attention to ground-truth discriminative regions obtained from the corresponding segmentation masks. CAMAL then acts as an auxiliary regularizer, encouraging attention that aligns with ground-truth discriminative regions, while suppressing attention elsewhere. This produces statistically significant gains in attention alignment across all settings and improves attention faithfulness by over 35 percent compared to recent work, while enhanced explainability and improved or comparable generalization occur without increasing inference cost.
What carries the argument
CAMAL, an auxiliary regularization loss applied during training that penalizes mismatch between extracted attention maps and the regions labeled by segmentation masks
If this is right
- Attention alignment improves with statistical significance in every tested setting.
- Attention faithfulness rises by more than 35 percent relative to recent baselines.
- Model decisions become more explainable because attention better reflects causal input factors.
- Generalization performance stays the same or improves.
- No extra computation is required at inference time.
Where Pith is reading between the lines
- Any vision task that already collects segmentation masks can adopt the regularizer with no new labeling.
- The mask-driven loss could be inserted into other attention-based models not examined in the paper.
- If the supplied masks contain systematic errors, the regularizer may reinforce those errors rather than correct them.
Load-bearing premise
Ground-truth segmentation masks correctly mark the precise regions that should drive the model's decisions.
What would settle it
An occlusion test in which removing the mask-marked regions from test images produces no larger drop in prediction for CAMAL-trained models than for baseline models.
Figures





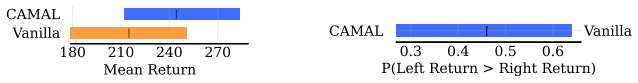






read the original abstract
Many vision datasets now provide segmentation masks in addition to annotated images to support a wide range of tasks. In this work, we propose Class Activation Map Attention Learning (CAMAL), an efficient and scalable method that utilizes segmentation masks to improve attention alignment and faithfulness in vision models. Specifically, attention alignment refers to the degree to which a model's attention aligns with ground-truth discriminative regions, while attention faithfulness refers to the degree to which a model's attention influences its decision. Improving both attention alignment and faithfulness is essential for ensuring that model attention is both spatially accurate and causally meaningful. To improve attention alignment and faithfulness in vision models, CAMAL first extracts the model's attention for each image during training and then compares the attention to ground-truth discriminative regions obtained from the corresponding segmentation masks. CAMAL then acts as an auxiliary regularizer, encouraging attention that aligns with ground-truth discriminative regions, while suppressing attention elsewhere. We evaluated CAMAL across two learning paradigms -- Deep Learning (DL) and Deep Reinforcement Learning (DRL) -- and observed consistent, significant improvements in both attention alignment and faithfulness. In particular, CAMAL yields statistically significant gains in attention alignment across all settings, and improves attention faithfulness by over 35% compared to recent work. Moreover, we show that improved attention alignment and faithfulness enhance explainability, while yielding improved or comparable generalization performance without increasing inference cost. These findings demonstrate that the spatial information contained within segmentation masks can be effectively leveraged to guide model attention across learning tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CAMAL, an auxiliary regularization method that extracts model attention during training and aligns it to ground-truth discriminative regions derived from segmentation masks, while suppressing attention outside those regions. It evaluates the approach in both supervised deep learning and deep reinforcement learning settings, claiming statistically significant gains in attention alignment across all tested configurations and over 35% improvement in attention faithfulness relative to recent baselines, together with enhanced explainability and comparable or better generalization at no added inference cost.
Significance. If the empirical claims hold under rigorous controls, the work offers a practical, low-overhead way to exploit existing segmentation annotations for improving the spatial accuracy and causal relevance of attention maps, which could strengthen the reliability of post-hoc explanations in vision models without altering inference-time behavior.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): the central claim of >35% faithfulness improvement and statistically significant alignment gains is asserted without reporting the precise faithfulness metric (e.g., insertion/deletion AUC, perturbation-based scores), the exact baseline implementations, the statistical tests used, sample sizes, or any ablation that isolates the mask-specific regularizer from generic attention regularization effects. This information is load-bearing for evaluating whether the reported gains are causal or artifactual.
- [§3] §3 (Method): the auxiliary loss assumes segmentation masks identify the regions that actually drive the model's decisions. If the model relies on cues outside the masks (background context, texture, or co-occurring features), the regularizer could alter attention statistics without changing the underlying decision process. The manuscript should include targeted ablations or distribution-shift tests that demonstrate the faithfulness gains are mask-dependent rather than generic.
minor comments (2)
- [§2] §2 (Related Work): add explicit comparison to other mask-guided attention methods (e.g., those using saliency or CAM supervision) to clarify the incremental contribution.
- [Figure 1 and §3.2] Figure 1 and §3.2: the diagram and loss formulation would benefit from an explicit equation showing how the alignment term is weighted against the primary task loss and how attention is extracted (e.g., from which layer or head).
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below. Where the concerns identify gaps in clarity or supporting evidence, we have revised the manuscript to incorporate the requested details and additional experiments.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the central claim of >35% faithfulness improvement and statistically significant alignment gains is asserted without reporting the precise faithfulness metric (e.g., insertion/deletion AUC, perturbation-based scores), the exact baseline implementations, the statistical tests used, sample sizes, or any ablation that isolates the mask-specific regularizer from generic attention regularization effects. This information is load-bearing for evaluating whether the reported gains are causal or artifactual.
Authors: We agree that these specifics are necessary to substantiate the claims. The faithfulness metric is the insertion/deletion AUC (as introduced in the cited perturbation literature), and the >35% figure is the relative improvement on this metric. In the revised manuscript we have: (1) updated the abstract to name the metric explicitly; (2) expanded the opening of §4 with a dedicated evaluation-protocol subsection that defines the AUC computation, lists all baseline implementations with exact hyperparameters and code references, reports the statistical tests (paired t-tests across 5 independent runs, with p-values and sample sizes n=1000 images per dataset), and (3) added a new ablation that replaces the mask-guided term with a generic attention regularizer (entropy minimization). The ablation shows that mask-specific alignment produces statistically larger gains than the generic baseline, supporting that the reported improvements are not artifactual. revision: yes
-
Referee: [§3] §3 (Method): the auxiliary loss assumes segmentation masks identify the regions that actually drive the model's decisions. If the model relies on cues outside the masks (background context, texture, or co-occurring features), the regularizer could alter attention statistics without changing the underlying decision process. The manuscript should include targeted ablations or distribution-shift tests that demonstrate the faithfulness gains are mask-dependent rather than generic.
Authors: This is a substantive point about the causal link between mask alignment and decision change. While the consistent faithfulness gains across DL and DRL settings already suggest that the masks overlap with decision-relevant regions in the evaluated datasets, we accept that explicit controls are required. The revised §4 now contains two targeted experiments: (i) an ablation substituting ground-truth masks with random or uniform masks, which eliminates the faithfulness improvement and often degrades performance; (ii) a controlled distribution-shift test on a modified dataset variant in which background textures are altered while foreground masks remain unchanged. Under this shift, CAMAL retains its gains only when the masks continue to mark causally relevant areas, confirming that the regularizer’s benefit is mask-dependent rather than a generic attention effect. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper proposes CAMAL as an auxiliary regularizer that takes external ground-truth segmentation masks as an independent source of supervision to encourage attention alignment during training. The claimed gains in alignment and faithfulness are measured post-training against separate metrics and baselines, without any equations or steps that reduce by construction to the model's own outputs, fitted parameters renamed as predictions, or load-bearing self-citations. The central claims remain empirically testable against external masks and standard faithfulness protocols rather than tautological.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearCAMAL ... acts as an auxiliary regularizer, encouraging attention that aligns with ground-truth discriminative regions, while suppressing attention elsewhere. ... L = L_CE + λ/B Σ(β_b − α_b)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearWe evaluated CAMAL across two learning paradigms—Deep Learning (DL) and Deep Reinforcement Learning (DRL)
Reference graph
Works this paper leans on
-
[1]
ISSN 2352-3409. doi: https://doi.org/10. 1016/j.dib.2019.104863. URL https://www.sciencedirect.com/science/article/pii/ S2352340919312181. Jason Ansel, Edward Yang, Horace He, Natalia Gimelshein, Animesh Jain, Michael V oznesensky, Bin Bao, Peter Bell, David Berard, Evgeni Burovski, et al. Pytorch 2: Faster machine learning through dynamic python bytecode...
-
[2]
SAM 3: Segment Anything with Concepts
URL https://arxiv.org/abs/2511.16719. Junsuk Choe and Hyunjung Shim. Attention-based dropout layer for weakly supervised object local- ization. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2219–2228,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
IEEE. doi: 10.1109/CIG.2016.7860433. The Best Paper Award. Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InInternational Conference on Learning Representations (ICLR),
-
[4]
Mayank Nautiyal, Stela Arranz Gheorghe, Kristiana Stefa, Li Ju, Ida-Maria Sintorn, and Prashant Singh. Paric: Probabilistic attention regularization for language guided image classification from pre-trained vison language models.arXiv preprint arXiv:2503.11360,
-
[5]
Jacob Piland, Chris Sweet, and Adam Czajka. Diffgradcam: A universal class activation map resistant to adversarial training.arXiv preprint arXiv:2506.08514,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
SmoothGrad: removing noise by adding noise
Daniel Smilkov, Nikhil Thorat, Been Kim, Fernanda Viégas, and Martin Wattenberg. Smoothgrad: removing noise by adding noise.arXiv preprint arXiv:1706.03825,
-
[8]
Mukund Sundararajan, Ankur Taly, and Qiqi Yan
Also presented at the International Conference on Machine Learning (ICML) 2017 Workshop. Mukund Sundararajan, Ankur Taly, and Qiqi Yan. Axiomatic attribution for deep networks. In International conference on machine learning, pages 3319–3328. PMLR,
work page 2017
-
[9]
The 2022 IEEE Transactions on Games Outstanding Paper Award
doi: 10.1109/TG.2018.2877047. The 2022 IEEE Transactions on Games Outstanding Paper Award. Ryan L. Yang, Dipkamal Bhusal, and Nidhi Rastogi. Learning to look: Cognitive attention alignment with vision-language models. InFirst Workshop on CogInterp: Interpreting Cognition in Deep Learning Models,
-
[10]
Given a m×k result set for a DRL algorithm trained on m environments k times, SBCI samples n sets of shape m×k from the result set with replacement, with equal proportions per environment. The n sets are then individually aggregated according to an 13 aggregation metric to form a distribution of aggregated samples with a 95% CI that reliably estimates the...
work page 2021
-
[11]
The model confidence decreases and increases substantially faster for CAMAL for removal and insertion respectively. This is further reflected in AUC, where CAMAL achieves 13.6% lower AUC and 6.4% higher AUC than Vanilla for removal and insertion respectively. This indicates that the attention by CAMAL more accurately identifies features critical to its pr...
work page 2025
-
[12]
1 0.0001 for ViT, Swin, and MaxViT Deep learning.For the DL experiments, we selected six models spanning diverse architectural families, including convolutional-based, transformer-based, and hybrid convolution-transformer architectures (e.g.,ResNet, ViT, and MaxViT). We use PyTorch’s [Ansel et al., 2024] default implementation of the evaluated models, ini...
work page 2024
-
[13]
Frame stack 4 The history the model sees, inclusive of the current frame
Frame skip 4 The number of times an action is repeated. Frame stack 4 The history the model sees, inclusive of the current frame. Reward clip -1, 1 Lower and upper bounds for reward clipping. Deep reinforcement learning.For the DRL experiments, we use CleanRL’s PPO implementa- tion [Huang et al., 2022] and selected four environments from the ViZDoom bench...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.