Recognition: 1 theorem link
· Lean TheoremSanity Checks for Long-Form Hallucination Detection
Pith reviewed 2026-05-12 01:15 UTC · model grok-4.3
The pith
Answer cues often drive hallucination detectors for reasoning traces rather than the traces themselves
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
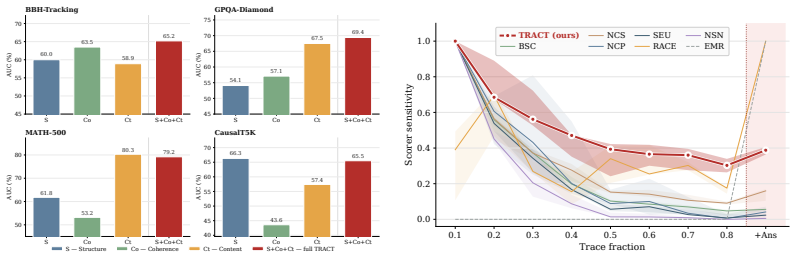
Once answer artifacts are controlled for via the Force and Remove oracle tests, effective hallucination detection does not require complex learned representations. TRACT, a lightweight scorer built on lexical trajectory features including hedging trends, step-length dynamics, and cross-response vocabulary convergence, achieves strong robustness while remaining competitive with or outperforming existing baselines on unperturbed traces. The central challenge is therefore not the absence of signal in the trace but the failure to isolate it from endpoint cues.
What carries the argument
TRACT, a lightweight scorer that aggregates lexical trajectory features such as hedging trends, step-length dynamics, and cross-response vocabulary convergence to assess reasoning validity independent of final-answer cues.
If this is right
- Detectors should be re-evaluated on their sensitivity to reasoning structure rather than final-answer information.
- Lightweight lexical-based scorers can serve as strong, interpretable baselines for long-form hallucination detection.
- The primary remaining task is to isolate genuine trace-internal signals from endpoint artifacts.
- Robust performance is achievable without complex neural representations once such artifacts are addressed.
Where Pith is reading between the lines
- Similar lexical-trajectory analysis could be tested on other long-form generation tasks where consistency across steps matters.
- These features might be combined with minimal supervision to create hybrid detectors that retain simplicity.
- Evaluation protocols for new detectors could routinely include the Force and Remove tests as standard controls.
Load-bearing premise
The Force and Remove oracle tests preserve the structure and validity of the intermediate reasoning trajectory while only altering answer-announcement cues, without introducing new structural biases or changing what counts as valid reasoning.
What would settle it
A dataset of reasoning traces where lexical patterns such as hedging and vocabulary convergence are systematically disrupted while answer cues remain fixed, with TRACT then showing a sharp performance drop relative to its results on unperturbed traces.
Figures


read the original abstract
Hallucination detection methods for large language models increasingly operate on chain-of-thought reasoning traces, yet it remains unclear whether they evaluate the reasoning itself or merely exploit surface correlates of the final answer. We introduce a controlled-invariance methodology that exposes this distinction through two oracle tests: \textsc{Force}, which replaces each response's final answer with the ground truth while preserving the reasoning trace, and \textsc{Remove}, which strips answer-announcement steps while leaving the trajectory intact. This reveals if their predictive power derives from answer-level artifacts rather than from the structure or validity of intermediate reasoning. We further show that once these artifacts are controlled for, effective detection does not necessarily require complex learned representations: TRACT, a lightweight scorer built on lexical trajectory features (hedging trends, step-length dynamics, and cross-response vocabulary convergence), achieves strong robustness while remaining competitive with or outperforming existing baselines on unperturbed traces. These findings suggest that the current central challenge in reasoning-aware hallucination detection is not the absence of signal in the trace, but the failure to isolate it from endpoint cues.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that hallucination detectors operating on long-form chain-of-thought traces often exploit surface-level answer-announcement artifacts rather than evaluating the validity or structure of intermediate reasoning. It introduces a controlled-invariance methodology with two oracle tests—Force (replacing the final answer with ground truth while preserving the trace) and Remove (stripping answer-announcement steps)—to isolate these effects. The paper further proposes TRACT, a lightweight, non-learned scorer using lexical trajectory features (hedging trends, step-length dynamics, and cross-response vocabulary convergence), and asserts that TRACT achieves strong robustness and remains competitive with or outperforms existing baselines on unperturbed traces once artifacts are controlled.
Significance. If the oracle tests successfully isolate reasoning signal without introducing new structural biases, this work offers a timely sanity-check framework that could improve evaluation practices in hallucination detection. The demonstration that a simple, interpretable, parameter-free method like TRACT can match complex learned baselines after artifact control is a constructive contribution, highlighting that the core challenge may lie in experimental design rather than representational power.
major comments (2)
- [§3] §3 (oracle test definitions): The Force oracle replaces each response's final answer with ground truth while preserving the preceding reasoning steps. However, if those steps were originally generated to support a hallucinated conclusion, the modified trace may no longer constitute coherent reasoning for the forced answer. This risks altering lexical patterns (e.g., hedging trends or step-length dynamics) that TRACT directly measures, undermining the interpretation that TRACT's performance reflects genuine reasoning signal rather than residual or newly introduced artifacts.
- [§5] §5 (results and claims): The central claim that effective detection does not require complex learned representations once artifacts are controlled rests on the assumption that Force and Remove preserve the validity and structure of the original trajectory. Without additional analysis or controls demonstrating that these oracles do not shift what counts as valid reasoning or create new exploitable lexical patterns, the robustness results for TRACT cannot be confidently attributed to isolation of reasoning signal.
minor comments (2)
- [Abstract] Abstract: states that TRACT 'achieves strong robustness' and is 'competitive with or outperforming' baselines but supplies no quantitative metrics, dataset sizes, or statistical test details. Adding these would make the high-level claims easier to evaluate at a glance.
- [§4] §4 (TRACT feature definitions): the exact computation of features such as 'hedging trends' and 'cross-response vocabulary convergence' should be formalized with equations or pseudocode to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our controlled-invariance methodology and the interpretation of TRACT's results. The comments raise valid points about potential effects of the oracles on trace coherence and feature stability. We address each major comment below with clarifications and indicate the revisions we will incorporate.
read point-by-point responses
-
Referee: [§3] §3 (oracle test definitions): The Force oracle replaces each response's final answer with ground truth while preserving the preceding reasoning steps. However, if those steps were originally generated to support a hallucinated conclusion, the modified trace may no longer constitute coherent reasoning for the forced answer. This risks altering lexical patterns (e.g., hedging trends or step-length dynamics) that TRACT directly measures, undermining the interpretation that TRACT's performance reflects genuine reasoning signal rather than residual or newly introduced artifacts.
Authors: We acknowledge that substituting the ground-truth answer in the Force oracle can produce less coherent traces when original reasoning steps were aligned with a hallucinated conclusion, which may influence lexical features such as hedging trends and step-length dynamics measured by TRACT. The oracle's design prioritizes isolating the final-answer artifact to evaluate whether detectors depend on endpoint cues rather than the trajectory itself. Empirical results show that learned baselines degrade markedly under Force, supporting artifact reliance, while TRACT's maintained performance indicates its trajectory features are relatively stable to answer changes. To strengthen the interpretation, we will revise §3 and add a dedicated analysis quantifying pre- and post-Force changes in TRACT's individual features (hedging, step dynamics, vocabulary convergence) across the dataset. revision: yes
-
Referee: [§5] §5 (results and claims): The central claim that effective detection does not require complex learned representations once artifacts are controlled rests on the assumption that Force and Remove preserve the validity and structure of the original trajectory. Without additional analysis or controls demonstrating that these oracles do not shift what counts as valid reasoning or create new exploitable lexical patterns, the robustness results for TRACT cannot be confidently attributed to isolation of reasoning signal.
Authors: We agree that confident attribution of TRACT's robustness to reasoning-signal isolation requires evidence that the oracles do not introduce new structural biases or exploitable patterns. The Remove oracle targets explicit answer announcements as surface artifacts, and Force targets the endpoint while retaining the trace; however, we recognize the need for further validation of feature stability and reasoning preservation. In the revision to §5, we will include additional controls such as feature-distribution comparisons before and after each oracle, correlation analysis between feature shifts and performance changes, and an explicit limitations discussion on oracle effects on reasoning validity. These additions will provide stronger grounding for the claim that simple lexical trajectory features suffice once artifacts are controlled. revision: yes
Circularity Check
No circularity: independent oracles and non-fitted lexical features
full rationale
The paper defines the Force and Remove oracles as explicit, independent interventions on reasoning traces (replacing final answers or stripping announcements) without reference to any detector output or fitted parameters. TRACT is constructed from explicit lexical trajectory features (hedging trends, step-length dynamics, cross-response vocabulary convergence) that are not tuned to hallucination labels. No self-citations, uniqueness theorems, or ansatzes are invoked to justify the central claims; comparisons to baselines occur on unperturbed traces as external benchmarks. The derivation chain remains self-contained against these independent definitions and evaluations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The reasoning trace's validity can be isolated from the final answer by the Force and Remove operations without confounding changes to the trace.
invented entities (1)
-
TRACT
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Jakub Binkowski, Denis Janiak, Albert Sawczyn, Bogdan Gabrys, and Tomasz Jan Kajdanow- icz
Nova Pro multimodal foundation model. Jakub Binkowski, Denis Janiak, Albert Sawczyn, Bogdan Gabrys, and Tomasz Jan Kajdanow- icz. Hallucination detection in LLMs using spectral features of attention maps. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Na...
work page 2025
-
[2]
Association for Computational Linguistics. ISBN 979-8-89176- 332-6. doi: 10.18653/v1/2025.emnlp-main.1239. URL https://aclanthology.org/2025. emnlp-main.1239/. Dylan Bouchard, Mohit Singh Chauhan, David Skarbrevik, Ho-Kyeong Ra, Viren Bajaj, and Zeya Ahmad. Uqlm: A python package for uncertainty quantification in large language models.Journal of Machine L...
-
[3]
URL http://jmlr.org/papers/v27/ 25-1557.html. Jiuhai Chen and Jonas Mueller. Quantifying uncertainty in answers from any language model and enhancing their trustworthiness.arXiv preprint arXiv:2308.16175,
-
[4]
Jeremy R. Cole, Michael J. Q. Zhang, Daniel Gillick, Julian Martin Eisenschlos, Bhuwan Dhingra, and Jacob Eisenstein. Selectively answering ambiguous questions.arXiv preprint arXiv:2305.14613,
-
[5]
Zenghao Duan, Liang Pang, Zihao Wei, Wenbin Duan, Yuxin Tian, Shicheng Xu, Jingcheng Deng, Zhiyi Yin, and Xueqi Cheng. Circular reasoning: Understanding self-reinforcing loops in large reasoning models.arXiv preprint arXiv:2601.05693,
-
[6]
Ekaterina Fadeeva, Aleksandr Rubashevskii, Artem Shelmanov, Sergey Petrakov, Haonan Li, Hamdy Mubarak, Evgenii Tsymbalov, Gleb Kuzmin, Alexander Panchenko, Timothy Baldwin, Preslav Nakov, and Maxim Panov. Fact-checking the output of large language models via token-level uncertainty quantification.arXiv preprint arXiv:2403.04696,
-
[7]
Longling Geng, Andy Ouyang, Theodore Wu, et al
doi: 10.18653/v1/2024.eacl-long.143. Longling Geng, Andy Ouyang, Theodore Wu, et al. CausalT5K: Diagnosing and informing refusal for trustworthy causal reasoning of skepticism, sycophancy, detection-correction, and rung collapse. arXiv preprint arXiv:2602.08939,
-
[8]
Mingyu Jin, Qinkai Yu, Dong Shu, Haiyan Zhao, Wenyue Hua, Yanda Meng, Yongfeng Zhang, and Mengnan Du
URL https://arxiv.org/abs/2410.22685. Mingyu Jin, Qinkai Yu, Dong Shu, Haiyan Zhao, Wenyue Hua, Yanda Meng, Yongfeng Zhang, and Mengnan Du. The impact of reasoning step length on large language models. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Findings of the Association for Computational Linguistics: ACL 2024, pages 1830–1842, Bangkok, Th...
-
[9]
doi: 10.18653/v1/2024.findings-acl.108
Association for Computational 11 Linguistics. doi: 10.18653/v1/2024.findings-acl.108. URL https://aclanthology.org/2024. findings-acl.108/. Sungmin Kang, Yavuz Faruk Bakman, Duygu Nur Yaldiz, Baturalp Buyukates, and Salman Aves- timehr. Uncertainty quantification for hallucination detection in large language models: Founda- tions, methodology, and future ...
-
[10]
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar
URLhttps://arxiv.org/abs/2405.13319. Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation.arXiv preprint arXiv:2302.09664,
-
[11]
doi: 10.1007/BF00262952. Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Felix, Jan Leike Lim, John Schulman, Ilya Sutskever, and Wojciech Zaremba. Let’s verify step by step. arXiv preprint arXiv:2305.20050,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/bf00262952
-
[12]
URLhttps://arxiv.org/abs/2305.20050. Potsawee Manakul, Adian Liusie, and Mark J. F. Gales. Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models. InProceedings of the 2023 Confer- ence on Empirical Methods in Natural Language Processing, pages 9004–9017. Association for Computational Linguistics, 2023a. doi: 10...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08896 2023
-
[13]
Hybrid Mamba-Transformer Mixture- of-Experts LLM. OpenAI. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Beyond logit lens: Contextual embeddings for robust hallucination detection & grounding in VLMs
Anirudh Phukan, Divyansh, Harshit Kumar Morj, Vaishnavi, Apoorv Saxena, and Koustava Goswami. Beyond logit lens: Contextual embeddings for robust hallucination detection & grounding in VLMs. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors,Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Lin...
work page 2025
-
[15]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Association for Computational Linguistics. ISBN 979-8-89176-189-6. doi: 10.18653/ v1/2025.naacl-long.488. URLhttps://aclanthology.org/2025.naacl-long.488/. Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks. arXiv preprint arXiv:1908.10084,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them
doi: 10.1145/3744238. 12 Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc V Le, Ed H Chi, Denny Zhou, , and Jason Wei. Challenging big-bench tasks and whether chain-of-thought can solve them.arXiv preprint arXiv:2210.09261,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1145/3744238
-
[17]
Hugo Touvron et al. Llama 3: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Changyue Wang, Weihang Su, Qingyao Ai, and Yiqun Liu
URLhttps://arxiv.org/abs/2508.15842. Changyue Wang, Weihang Su, Qingyao Ai, and Yiqun Liu. Joint evaluation of answer and reasoning consistency for hallucination detection in large reasoning models.Proceedings of the AAAI Conference on Artificial Intelligence, 40(39):33377–33385, Mar
-
[19]
doi: 10.1609/aaai.v40i39. 40624. URLhttps://ojs.aaai.org/index.php/AAAI/article/view/40624. Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems, volume 35, pages 24824–24837,
-
[20]
Junchi Yao, Shu Yang, Jianhua Xu, Lijie Hu, Mengdi Li, and Di Wang
URL https://neurips.cc. Junchi Yao, Shu Yang, Jianhua Xu, Lijie Hu, Mengdi Li, and Di Wang. Understanding the repeat curse in large language models from a feature perspective. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Findings of the Association for Computational Linguistics: ACL 2025, pages 7787–7815, Vienna,...
work page 2025
-
[21]
BERTScore: Evaluating Text Generation with BERT
Association for Computational Linguistics. ISBN 979-8-89176-256-5. doi: 10.18653/v1/2025.findings-acl.406. URLhttps://aclanthology.org/2025.findings-acl.406/. Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. Bertscore: Evaluating text generation with bert.arXiv preprint arXiv:1904.09675,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2025.findings-acl.406 2025
-
[22]
A Datasets We describe the four benchmarks used to evaluate TRACT and the other black-box scorers
URLhttps://arxiv.org/abs/2505.11741. A Datasets We describe the four benchmarks used to evaluate TRACT and the other black-box scorers. A.1 BBH-Tracking (BIG-Bench Hard) BIG-Bench Hard(BBH; Suzgun et al
-
[23]
is a benchmark of 448 four-way multiple-choice questions written by domain experts in biology, physics, and chemistry. Questions are deliberately designed to be “Google-proof”: highly skilled non-expert validators reach only 34% accuracy despite an average of over 30 minutes of unrestricted web access. Domain experts holding or pursuing PhDs in the releva...
work page 2023
-
[24]
D TRACT Pairwise Complementarity The main paper evaluates TRACT as a standalone detector. Here we ask a diagnostic question: does TRACT capture information that is complementary to existing black-box uncertainty scorers? To test this, we fuse TRACT with each baseline scorer using a 4-fold cross-validated logistic regression classifier. All fusion experime...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.