Recognition: 2 theorem links
· Lean TheoremAuto-Rubric as Reward: From Implicit Preferences to Explicit Multimodal Generative Criteria
Pith reviewed 2026-05-12 00:55 UTC · model grok-4.3
The pith
Turning a vision-language model's hidden preferences into explicit prompt-specific rubrics before any comparison produces more reliable and data-efficient rewards for multimodal generators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ARR externalizes a VLM's internalized preference knowledge as prompt-specific rubrics, translating holistic intent into independently verifiable quality dimensions before any pairwise comparison. This conversion of implicit preference structure into inspectable, interpretable constraints substantially suppresses evaluation biases including positional bias, enabling both zero-shot deployment and few-shot conditioning on minimal supervision. Rubric Policy Optimization then distills the structured evaluation into a robust binary reward that replaces opaque scalar regression with rubric-conditioned preference decisions for stable policy gradients.
What carries the argument
The Auto-Rubric as Reward process that generates explicit, prompt-specific rubrics from a VLM prior to pairwise comparison, acting as a factorized interface that converts implicit preferences into verifiable quality dimensions.
If this is right
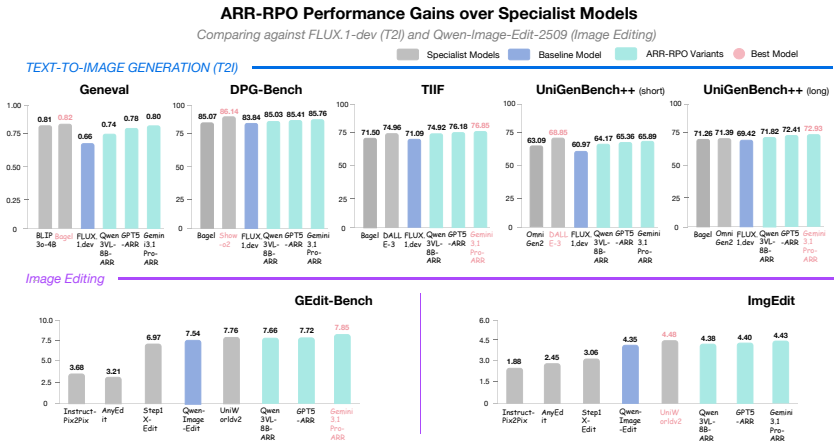
- ARR-RPO outperforms pairwise reward models and direct VLM judges on text-to-image generation and image editing benchmarks.
- The method enables zero-shot deployment without additional training and few-shot adaptation using minimal supervision.
- Explicit rubrics suppress positional bias and other evaluation artifacts that affect direct comparison methods.
- Replacing scalar regression with rubric-conditioned binary decisions stabilizes policy gradients during generative training.
Where Pith is reading between the lines
- The same externalization step could be applied to other generative tasks such as video or 3D synthesis if the underlying VLM supports those domains.
- If rubrics generated by different VLMs converge on similar criteria for the same prompts, they could serve as a shared, inspectable standard for evaluation.
- Comparing ARR rubrics against human-written rubrics on the same prompts would test whether the externalization step preserves or alters preference structure.
Load-bearing premise
A vision-language model can reliably turn its own internalized preferences into prompt-specific rubrics that remain independently verifiable and free of the evaluation biases the approach aims to remove.
What would settle it
Human raters judge that image generations selected using ARR rubrics are no better aligned with preferences than generations selected by standard pairwise reward models on the same text-to-image and image-editing benchmarks.
Figures









read the original abstract
Aligning multimodal generative models with human preferences demands reward signals that respect the compositional, multi-dimensional structure of human judgment. Prevailing RLHF approaches reduce this structure to scalar or pairwise labels, collapsing nuanced preferences into opaque parametric proxies and exposing vulnerabilities to reward hacking. While recent Rubrics-as-Reward (RaR) methods attempt to recover this structure through explicit criteria, generating rubrics that are simultaneously reliable, scalable, and data-efficient remains an open problem. We introduce Auto-Rubric as Reward (ARR), a framework that reframes reward modeling from implicit weight optimization to explicit, criteria-based decomposition. Before any pairwise comparison, ARR externalizes a VLM's internalized preference knowledge as prompt-specific rubrics, translating holistic intent into independently verifiable quality dimensions. This conversion of implicit preference structure into inspectable, interpretable constraints substantially suppresses evaluation biases including positional bias, enabling both zero-shot deployment and few-shot conditioning on minimal supervision. To extend these gains into generative training, we propose Rubric Policy Optimization (RPO), which distills ARR's structured multi-dimensional evaluation into a robust binary reward, replacing opaque scalar regression with rubric-conditioned preference decisions that stabilize policy gradients. On text-to-image generation and image editing benchmarks, ARR-RPO outperforms pairwise reward models and VLM judges, demonstrating that explicitly externalizing implicit preference knowledge into structured rubrics achieves more reliable, data-efficient multimodal alignment, revealing that the bottleneck is the absence of a factorized interface, not a deficit of knowledge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Auto-Rubric as Reward (ARR), a framework that externalizes a VLM's implicit preferences into prompt-specific, explicit rubrics before any pairwise comparison, converting holistic judgments into independently verifiable quality dimensions. It further proposes Rubric Policy Optimization (RPO) to distill these structured evaluations into a binary reward signal for generative policy training. The authors claim this approach substantially suppresses biases (e.g., positional bias), enables zero-shot and few-shot alignment, and outperforms pairwise reward models and direct VLM judges on text-to-image generation and image editing benchmarks, arguing that the alignment bottleneck is the lack of a factorized interface rather than insufficient knowledge.
Significance. If the empirical claims hold with proper validation, the work would be significant for multimodal RLHF by shifting from opaque scalar rewards to explicit, inspectable criteria, potentially mitigating reward hacking and improving data efficiency. The emphasis on pre-comparison rubric externalization offers a concrete mechanism for bias reduction that could generalize beyond current VLM judges.
major comments (2)
- [Abstract] Abstract: The central claim that ARR 'substantially suppresses evaluation biases including positional bias' and achieves benchmark outperformance is stated without any quantitative results, ablation studies, error analysis, or verification mechanism (e.g., human validation of rubric independence or inter-rubric consistency metrics). This evidence gap is load-bearing because the diagnosis that 'the bottleneck is the absence of a factorized interface' rests on the rubrics being independently verifiable and freer of the VLM's original biases.
- [Method] Method description (inferred from abstract and framework): Rubric generation is performed by the identical VLM whose preferences are being aligned, with no described external anchoring, human oversight, or post-generation consistency checks. If rubric creation inherits the same implicit weightings that produce positional or holistic biases in direct judgment, the subsequent RPO distillation cannot isolate or remove them; a concrete test (e.g., ablation comparing ARR rubrics against direct VLM scoring on bias-sensitive prompts) is required to substantiate independence.
minor comments (1)
- [Abstract] The abstract introduces several new terms (ARR, RPO) without immediate forward references to their formal definitions or pseudocode; adding a brief notation table or early equation block would improve readability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below with references to the manuscript content and indicate planned revisions where they strengthen clarity without altering the core claims or experiments.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that ARR 'substantially suppresses evaluation biases including positional bias' and achieves benchmark outperformance is stated without any quantitative results, ablation studies, error analysis, or verification mechanism (e.g., human validation of rubric independence or inter-rubric consistency metrics). This evidence gap is load-bearing because the diagnosis that 'the bottleneck is the absence of a factorized interface' rests on the rubrics being independently verifiable and freer of the VLM's original biases.
Authors: The abstract serves as a concise summary of contributions and high-level claims. Quantitative benchmark results demonstrating outperformance over pairwise reward models and direct VLM judges on text-to-image generation and image editing tasks are presented in Section 4, with specific metrics and comparisons. Ablation studies on bias suppression (including positional bias) and human validation of rubric quality, independence, and inter-rubric consistency appear in Section 5.2 and 5.3. These sections directly support the factorized-interface diagnosis. We will revise the abstract to include brief quantitative highlights and explicit cross-references to these sections. revision: partial
-
Referee: [Method] Method description (inferred from abstract and framework): Rubric generation is performed by the identical VLM whose preferences are being aligned, with no described external anchoring, human oversight, or post-generation consistency checks. If rubric creation inherits the same implicit weightings that produce positional or holistic biases in direct judgment, the subsequent RPO distillation cannot isolate or remove them; a concrete test (e.g., ablation comparing ARR rubrics against direct VLM scoring on bias-sensitive prompts) is required to substantiate independence.
Authors: The ARR design intentionally uses the same VLM to externalize its internalized preferences into explicit, prompt-specific rubrics prior to any comparison or distillation. This externalization step converts holistic judgments into independently inspectable dimensions, which the manuscript shows reduces biases (as evidenced by superior performance versus direct VLM judges and pairwise models on bias-sensitive benchmarks). The subsequent RPO step further distills these into binary rewards. While the current manuscript does not include a dedicated ablation isolating rubric generation from direct VLM scoring, the overall empirical gains on zero-shot/few-shot alignment and bias metrics substantiate the approach. We will add a clarifying paragraph in the method section on this design rationale and include the requested ablation comparing ARR rubrics to direct VLM scoring on positional-bias prompts in the revision. revision: yes
Circularity Check
No circularity: new framework with independent empirical claims
full rationale
The paper introduces ARR (externalizing VLM preferences into prompt-specific rubrics before comparison) and RPO (distilling those into binary rewards) as methodological contributions. The abstract and description frame bias suppression and improved alignment as outcomes of this explicit decomposition, validated on text-to-image and editing benchmarks. No equations, fitted parameters, or derivations are shown that reduce a claimed result to its own inputs by construction. No self-citations, uniqueness theorems, or ansatzes from prior author work are invoked to justify core steps. The central diagnosis (bottleneck is missing factorized interface) is presented as interpretive rather than proven by self-reference. This is a standard proposal of a new interface with external evaluation, scoring 0.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VLMs contain internalized preference knowledge that can be externalized into prompt-specific, independently verifiable quality dimensions before pairwise comparison.
invented entities (2)
-
Auto-Rubric as Reward (ARR) framework
no independent evidence
-
Rubric Policy Optimization (RPO)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/LogicAsFunctionalEquation.leanSatisfiesLawsOfLogic echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
ARR externalizes a VLM’s internalized preference knowledge as prompt-specific rubrics, translating holistic intent into independently verifiable quality dimensions. This conversion of implicit preference structure into inspectable, interpretable constraints substantially suppresses evaluation biases
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
reframes reward modeling from implicit weight optimization to explicit, criteria-based decomposition
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Critique-out-loud re- ward models.arXiv preprint arXiv:2408.11791, 2024
Zachary Ankner, Mansheej Paul, Brandon Cui, Jonathan D Chang, and Prithviraj Ammanabrolu. Critique-out-loud reward models.arXiv preprint arXiv:2408.11791, 2024
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Improving image generation with better captions.arXiv preprint arXiv:2310.07685, 2023
James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang, Juntang Zhuang, Joyce Lee, Yufei Guo, Wesam Manassra, Prafulla Dhariwal, Casey Chu, Yunxin Jiao, and Aditya Ramesh. Improving image generation with better captions.arXiv preprint arXiv:2310.07685, 2023
-
[4]
Training Diffusion Models with Reinforcement Learning
Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, and Sergey Levine. Training diffusion models with reinforcement learning.arXiv preprint arXiv:2305.13301, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Instructpix2pix: Learning to follow image editing instructions
Tim Brooks, Aleksander Holynski, and Alexei A Efros. Instructpix2pix: Learning to follow image editing instructions. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18392–18402, 2023
work page 2023
-
[6]
BLIP3-o: A Family of Fully Open Unified Multimodal Models-Architecture, Training and Dataset
Jiuhai Chen, Zhiyang Xu, Xichen Pan, Yushi Hu, Can Qin, Tom Goldstein, Lifu Huang, Tianyi Zhou, Saining Xie, Silvio Savarese, et al. Blip3-o: A family of fully open unified multimodal models-architecture, training and dataset.arXiv preprint arXiv:2505.09568, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
ShareGPT-4o-Image: Aligning multimodal models with GPT-4o-level image generation
Junying Chen, Zhenyang Cai, Pengcheng Chen, Shunian Chen, Ke Ji, Xidong Wang, Yunjin Yang, and Benyou Wang. Sharegpt-4o-image: Aligning multimodal models with gpt-4o-level image generation.arXiv preprint arXiv:2506.18095, 2025
-
[8]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. Janus-pro: Unified multimodal understanding and generation with data and model scaling.arXiv preprint arXiv:2501.17811, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Emerging properties in unified multimodal pretraining, 2025
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, Guang Shi, and Haoqi Fan. Emerging properties in unified multimodal pretraining, 2025
work page 2025
-
[10]
Ying Fan, Olivia Watkins, Yuqing Du, Hao Liu, Moonkyung Ryu, Craig Boutilier, Pieter Abbeel, Mohammad Ghavamzadeh, Kangwook Lee, and Kimin Lee. Dpok: Reinforcement learning for fine-tuning text-to-image diffusion models.Advances in Neural Information Processing Systems, 36:79858–79885, 2023
work page 2023
-
[11]
Dhruba Ghosh, Hannaneh Hajishirzi, and Ludwig Schmidt. Geneval: An object-focused framework for evaluating text-to-image alignment.Advances in Neural Information Processing Systems, 36:52132–52152, 2023
work page 2023
-
[12]
Google DeepMind. Gemini 3.1 Pro - Model Card. https://deepmind.google/models/ model-cards/gemini-3-1-pro/, feb 2026
work page 2026
-
[13]
Helia Hashemi, Jason Eisner, Corby Rosset, Benjamin Van Durme, and Chris Kedzie. Llm- rubric: A multidimensional, calibrated approach to automated evaluation of natural language texts. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13806–13834, 2024
work page 2024
-
[14]
Clipscore: A reference-free evaluation metric for image captioning, 2022
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation metric for image captioning, 2022
work page 2022
-
[15]
ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment
Xiwei Hu, Rui Wang, Yixiao Fang, Bin Fu, Pei Cheng, and Gang Yu. Ella: Equip diffusion models with llm for enhanced semantic alignment.arXiv preprint arXiv:2403.05135, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Yushi Hu, Reyhane Askari-Hemmat, Melissa Hall, Emily Dinan, Luke Zettlemoyer, and Marjan Ghazvininejad. Multimodal rewardbench 2: Evaluating omni reward models for interleaved text and image.arXiv preprint arXiv:2512.16899, 2025. 10
-
[17]
Au- torubric: Rubric-based generative rewards for faithful multimodal reasoning, 2026
Mengzhao Jia, Zhihan Zhang, Ignacio Cases, Zheyuan Liu, Meng Jiang, and Peng Qi. Au- torubric: Rubric-based generative rewards for faithful multimodal reasoning, 2026
work page 2026
-
[18]
Prometheus: Inducing fine-grained evaluation capability in language models
Seungone Kim, Jamin Shin, Yejin Cho, Joel Jang, Shayne Longpre, Hwaran Lee, Sangdoo Yun, Seongjin Shin, Sungdong Kim, James Thorne, et al. Prometheus: Inducing fine-grained evaluation capability in language models. InThe Twelfth International Conference on Learning Representations, 2023
work page 2023
-
[19]
Yuval Kirstain, Adam Polyak, Uriel Singer, Shahbuland Matiana, Joe Penna, and Omer Levy. Pick-a-pic: An open dataset of user preferences for text-to-image generation.Advances in neural information processing systems, 36:36652–36663, 2023
work page 2023
-
[20]
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv preprint arXiv:2506.15742, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Tony Lee, Michihiro Yasunaga, Chenlin Meng, Yifan Mai, Joon Sung Park, Agrim Gupta, Yunzhi Zhang, Deepak Narayanan, Hannah Teufel, Marco Bellagente, et al. Holistic evaluation of text-to-image models.Advances in Neural Information Processing Systems, 36:69981–70011, 2023
work page 2023
-
[22]
Hp-edit: A human- preference post-training framework for image editing, 2026
Fan Li, Chonghuinan Wang, Lina Lei, Yuping Qiu, Jiaqi Xu, Jiaxiu Jiang, Xinran Qin, Zhikai Chen, Fenglong Song, Zhixin Wang, Renjing Pei, and Wangmeng Zuo. Hp-edit: A human- preference post-training framework for image editing, 2026
work page 2026
-
[23]
Zongjian Li, Zheyuan Liu, Qihui Zhang, Bin Lin, Feize Wu, Shenghai Yuan, Zhiyuan Yan, Yang Ye, Wangbo Yu, Yuwei Niu, et al. Uniworld-v2: Reinforce image editing with diffusion negative-aware finetuning and mllm implicit feedback.arXiv preprint arXiv:2510.16888, 2025
-
[24]
Step1X-Edit: A Practical Framework for General Image Editing
Shiyu Liu, Yucheng Han, Peng Xing, Fukun Yin, Rui Wang, Wei Cheng, Jiaqi Liao, Yingming Wang, Honghao Fu, Chunrui Han, et al. Step1x-edit: A practical framework for general image editing.arXiv preprint arXiv:2504.17761, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Yixin Liu, Yue Yu, DiJia Su, Sid Wang, Xuewei Wang, Song Jiang, Bo Liu, Arman Cohan, Yuandong Tian, and Zhengxing Chen. Examining reasoning llms-as-judges in non-verifiable llm post-training.arXiv preprint arXiv:2603.12246, 2026
-
[26]
arXiv preprint arXiv:2509.23909 (2025)
Xin Luo, Jiahao Wang, Chenyuan Wu, Shitao Xiao, Xiyan Jiang, Defu Lian, Jiajun Zhang, Dong Liu, et al. Editscore: Unlocking online rl for image editing via high-fidelity reward modeling.arXiv preprint arXiv:2509.23909, 2025
-
[27]
Yiyang Ma, Xingchao Liu, Xiaokang Chen, Wen Liu, Chengyue Wu, Zhiyu Wu, Zizheng Pan, Zhenda Xie, Haowei Zhang, Xingkai Yu, et al. Janusflow: Harmonizing autoregression and rectified flow for unified multimodal understanding and generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7739–7751, 2025
work page 2025
-
[28]
Hpsv3: Towards wide-spectrum hu- man preference score
Yuhang Ma, Xiaoshi Wu, Keqiang Sun, and Hongsheng Li. Hpsv3: Towards wide-spectrum hu- man preference score. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15086–15095, 2025
work page 2025
-
[29]
Tianjun Pan, Xuan Lin, Wenyan Yang, Qianyu He, Shisong Chen, Licai Qi, Wanqing Xu, Hong- wei Feng, Bo Xu, and Yanghua Xiao. Rubriceval: A rubric-level meta-evaluation benchmark for llm judges in instruction following.arXiv preprint arXiv:2603.25133, 2026
-
[30]
Rubric is all you need: Improving llm-based code evaluation with question-specific rubrics
Aditya Pathak, Rachit Gandhi, Vaibhav Uttam, Arnav Ramamoorthy, Pratyush Ghosh, Aaryan Raj Jindal, Shreyash Verma, Aditya Mittal, Aashna Ased, Chirag Khatri, et al. Rubric is all you need: Improving llm-based code evaluation with question-specific rubrics. InProceed- ings of the 2025 ACM Conference on International Computing Education Research V . 1, page...
work page 2025
-
[31]
Sdxl: Improving latent diffusion models for high-resolution image synthesis, 2023
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis, 2023. 11
work page 2023
-
[32]
Emu edit: Precise image editing via recognition and generation tasks
Shelly Sheynin, Adam Polyak, Uriel Singer, Yuval Kirstain, Amit Zohar, Oron Ashual, Devi Parikh, and Yaniv Taigman. Emu edit: Precise image editing via recognition and generation tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8871–8879, 2024
work page 2024
-
[33]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Diffusion model alignment using direct preference optimization, 2023
Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purushwalkam, Stefano Ermon, Caiming Xiong, Shafiq Joty, and Nikhil Naik. Diffusion model alignment using direct preference optimization, 2023
work page 2023
-
[35]
Large language models are not fair evaluators
Peiyi Wang, Lei Li, Liang Chen, Zefan Cai, Dawei Zhu, Binghuai Lin, Yunbo Cao, Lingpeng Kong, Qi Liu, Tianyu Liu, et al. Large language models are not fair evaluators. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9440–9450, 2024
work page 2024
-
[36]
Emu3: Next-Token Prediction is All You Need
Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, et al. Emu3: Next-token prediction is all you need. arXiv preprint arXiv:2409.18869, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Unigenbench++: A unified semantic evaluation benchmark for text-to-image generation, 2026
Yibin Wang, Zhimin Li, Yuhang Zang, Jiazi Bu, Yujie Zhou, Yi Xin, Junjun He, Chunyu Wang, Qinglin Lu, Cheng Jin, and Jiaqi Wang. Unigenbench++: A unified semantic evaluation benchmark for text-to-image generation, 2026
work page 2026
-
[38]
Unified multimodal chain-of-thought reward model through reinforcement fine-tuning, 2025
Yibin Wang, Zhimin Li, Yuhang Zang, Chunyu Wang, Qinglin Lu, Cheng Jin, and Jiaqi Wang. Unified multimodal chain-of-thought reward model through reinforcement fine-tuning, 2025
work page 2025
-
[39]
Unified Reward Model for Multimodal Understanding and Generation
Yibin Wang, Yuhang Zang, Hao Li, Cheng Jin, and Jiaqi Wang. Unified reward model for multimodal understanding and generation.arXiv preprint arXiv:2503.05236, 2025
work page internal anchor Pith review arXiv 2025
-
[40]
Tiif-bench: How does your t2i model follow your instructions?, 2025
Xinyu Wei, Jinrui Zhang, Zeqing Wang, Hongyang Wei, Zhen Guo, and Lei Zhang. Tiif-bench: How does your t2i model follow your instructions?, 2025
work page 2025
-
[41]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
OmniGen2: Towards Instruction-Aligned Multimodal Generation
Chenyuan Wu, Pengfei Zheng, Ruiran Yan, Shitao Xiao, Xin Luo, Yueze Wang, Wanli Li, Xiyan Jiang, Yexin Liu, Junjie Zhou, et al. Omnigen2: Exploration to advanced multimodal generation.arXiv preprint arXiv:2506.18871, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
arXiv preprint arXiv:2509.26346 (2025)
Keming Wu, Sicong Jiang, Max Ku, Ping Nie, Minghao Liu, and Wenhu Chen. Editre- ward: A human-aligned reward model for instruction-guided image editing.arXiv preprint arXiv:2509.26346, 2025
-
[44]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis.arXiv preprint arXiv:2306.09341, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
Show-o2: Improved Native Unified Multimodal Models
Jinheng Xie, Zhenheng Yang, and Mike Zheng Shou. Show-o2: Improved native unified multimodal models.arXiv preprint arXiv:2506.15564, 2025
work page internal anchor Pith review arXiv 2025
-
[46]
Lipeng Xie, Sen Huang, Zhuo Zhang, Anni Zou, Yunpeng Zhai, Dingchao Ren, Kezun Zhang, Haoyuan Hu, Boyin Liu, Haoran Chen, et al. Auto-rubric: Learning from implicit weights to explicit rubrics for reward modeling.arXiv preprint arXiv:2510.17314, 2025
-
[47]
Imagereward: Learning and evaluating human preferences for text-to-image generation
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagereward: Learning and evaluating human preferences for text-to-image generation. Advances in Neural Information Processing Systems, 36:15903–15935, 2023
work page 2023
-
[48]
Seonghyeon Ye, Doyoung Kim, Sungdong Kim, Hyeonbin Hwang, Seungone Kim, Yongrae Jo, James Thorne, Juho Kim, and Minjoon Seo. Flask: Fine-grained language model evaluation based on alignment skill sets.arXiv preprint arXiv:2307.10928, 2023. 12
-
[49]
Imgedit: A unified image editing dataset and benchmark, 2025
Yang Ye, Xianyi He, Zongjian Li, Bin Lin, Shenghai Yuan, Zhiyuan Yan, Bohan Hou, and Li Yuan. Imgedit: A unified image editing dataset and benchmark, 2025
work page 2025
-
[50]
Anyedit: Mastering unified high-quality image editing for any idea, 2025
Qifan Yu, Wei Chow, Zhongqi Yue, Kaihang Pan, Yang Wu, Xiaoyang Wan, Juncheng Li, Siliang Tang, Hanwang Zhang, and Yueting Zhuang. Anyedit: Mastering unified high-quality image editing for any idea, 2025
work page 2025
-
[51]
Kai Zhang, Lingbo Mo, Wenhu Chen, Huan Sun, and Yu Su. Magicbrush: A manually annotated dataset for instruction-guided image editing.Advances in Neural Information Processing Systems, 36:31428–31449, 2023
work page 2023
-
[52]
Xiangyu Zhao, Peiyuan Zhang, Junming Lin, Tianhao Liang, Yuchen Duan, Shengyuan Ding, Changyao Tian, Yuhang Zang, Junchi Yan, and Xue Yang. Trust your critic: Robust reward modeling and reinforcement learning for faithful image editing and generation.arXiv preprint arXiv:2603.12247, 2026
-
[53]
DiffusionNFT: Online Diffusion Reinforcement with Forward Process
Kaiwen Zheng, Huayu Chen, Haotian Ye, Haoxiang Wang, Qinsheng Zhang, Kai Jiang, Hang Su, Stefano Ermon, Jun Zhu, and Ming-Yu Liu. Diffusionnft: Online diffusion reinforcement with forward process.arXiv preprint arXiv:2509.16117, 2025. 13 Appendix A Experimental Setup Details This section provides a comprehensive account of the datasets, evaluation protoco...
work page internal anchor Pith review arXiv 2025
-
[54]
Zero-shot rubric generation: ARR synthesizes rubrics on-the-fly from frozen VLMs, enabling immediate deployment in new domains without additional data collection or task-specific supervision
-
[55]
Holistic, rubric-conditioned decision interface: Rather than aggregating independently scored criteria post hoc, ARR formulates evaluation as a single rubric-conditioned judgment, where all dimensions are jointly considered in a pairwise comparison. This preserves inter- criterion dependencies and avoids inconsistencies introduced by independent scoring a...
-
[56]
Training-free reward interface: ARR operates without any parameter updates to the judge model, eliminating the computational and data overhead associated with training pointwise or pairwise reward models, while retaining strong generalization through the underlying VLM
-
[57]
rank": [rank_of_Image1, rank_of_Image2],
Data-efficient rubric induction: Across all experiments, high-quality rubrics are con- structed from as few as 100 preference pairs drawn from ShareGPT-4o-Image. This demon- strates that ARR can recover structured, task-relevant evaluation criteria with minimal supervision, achieving competitive performance with substantially lower data requirements than ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.