Recognition: no theorem link
Transformers Can Implement Preconditioned Richardson Iteration for In-Context Gaussian Kernel Regression
Pith reviewed 2026-05-12 03:02 UTC · model grok-4.3
The pith
A standard softmax-attention transformer can run preconditioned Richardson iteration to approximate in-context Gaussian kernel ridge regression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under bounded-data assumptions, a single-head transformer with O(log(1/ε)) blocks and MLP width O(√(N/ε)) implements preconditioned Richardson iteration on the kernel system and thereby produces an ε-accurate approximation to the KRR predictor for any prompt of length N. Softmax attention supplies the row-normalized Gaussian kernel operator required for the cross-token updates, while ReLU MLPs approximate the intra-token scalar operations demanded by each iteration.
What carries the argument
Preconditioned Richardson iteration on the kernel ridge regression linear system, realized by softmax attention producing the normalized Gaussian kernel matrix and ReLU MLPs performing the local scalar arithmetic of each update step.
If this is right
- The transformer depth needed for ε-accuracy scales only logarithmically with 1/ε while width scales with the square root of prompt length.
- The architecture admits a clean decomposition in which attention handles kernel-induced cross-token interactions and MLPs handle the scalar iteration arithmetic.
- Linear probing of layer activations can distinguish preconditioned Richardson from other iterative solvers by matching error-decay profiles.
- Ablation of either the attention or the MLP component breaks the alignment with the classical solver.
Where Pith is reading between the lines
- The same construction might be adapted to other positive-definite kernels or to other stationary iterative solvers whose updates can be expressed with matrix-vector products and local scalar operations.
- If the bounded-data assumption can be relaxed to sub-Gaussian tails, the same transformer could serve as a provable in-context learner for a wider class of nonparametric regression problems.
- One could test the mechanism by inserting explicit iteration counters or residual connections that mimic the preconditioner and measuring whether convergence speed improves as predicted.
Load-bearing premise
The data points and kernel evaluations remain bounded in a way that lets the approximation error of the transformer layers be controlled uniformly across all prompts of length N.
What would settle it
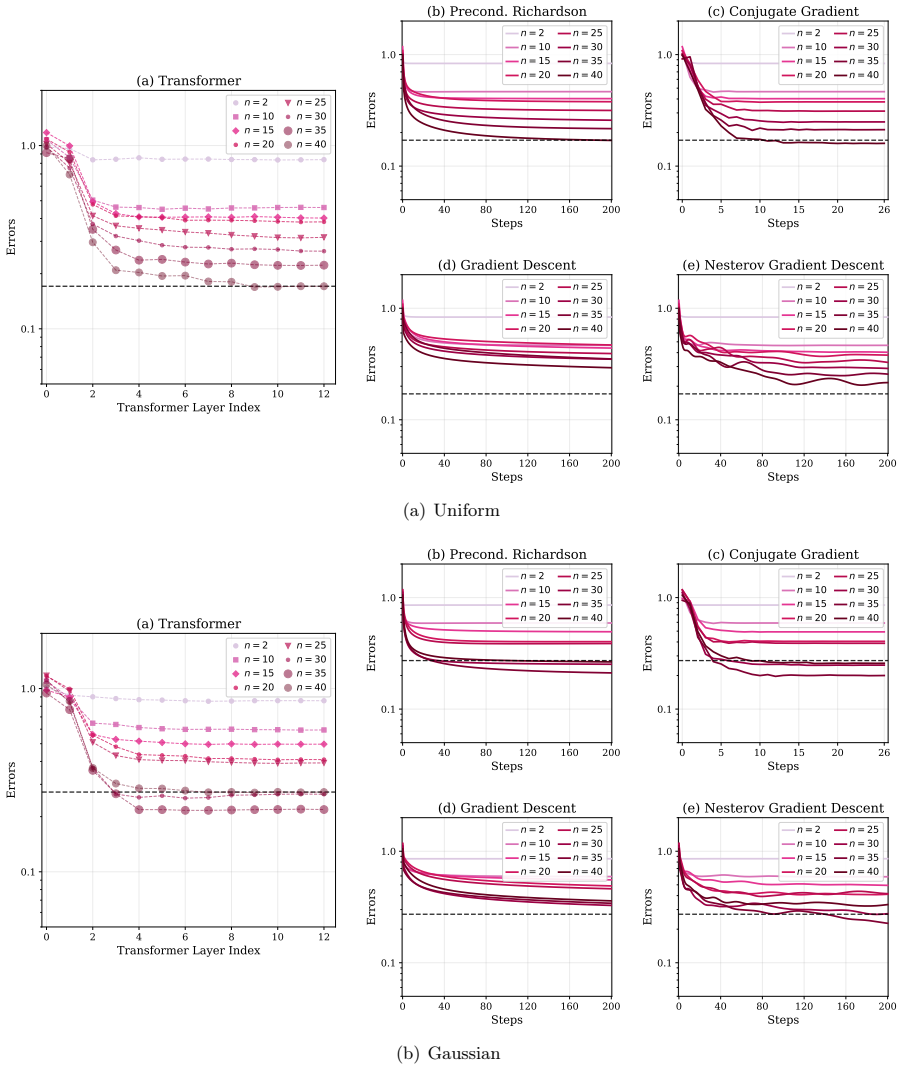
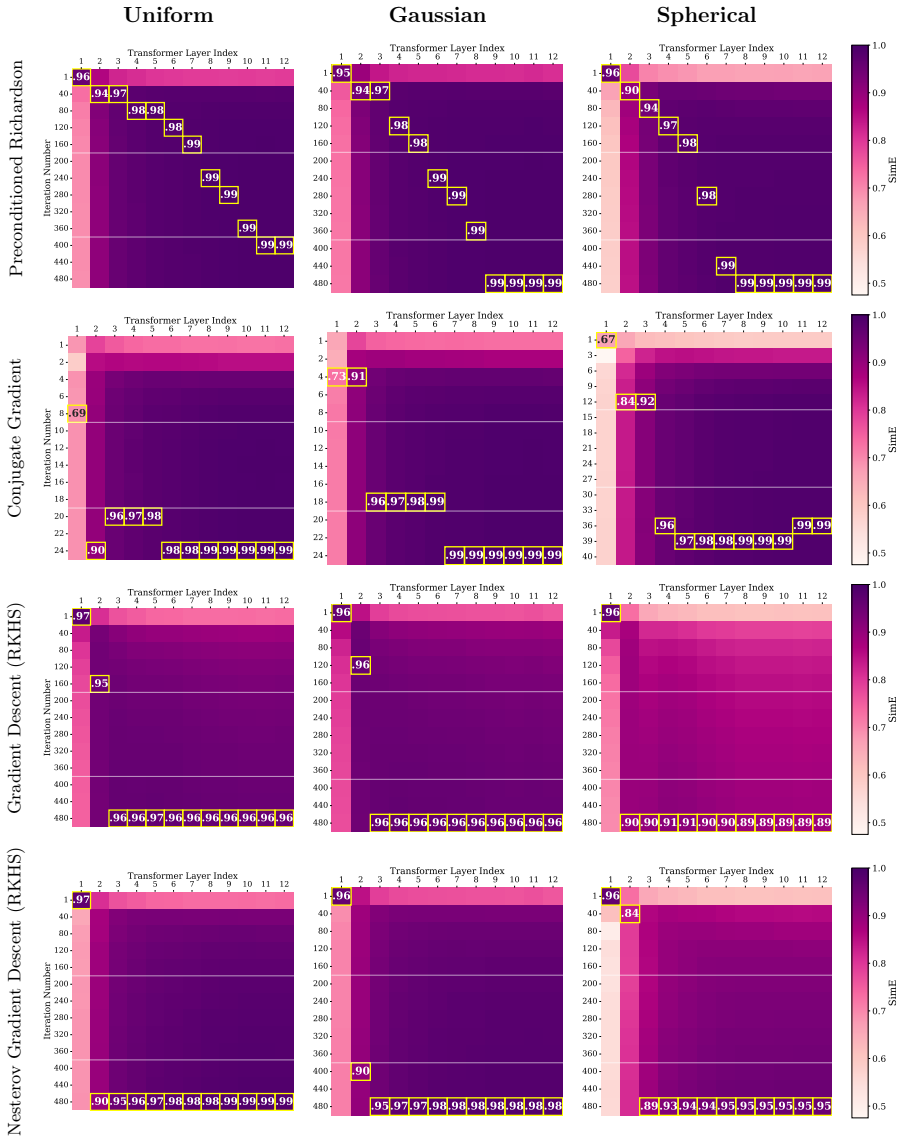
Train a GPT-2-style transformer on the same Gaussian-process regression tasks and check whether its successive layer outputs match the successive iterates of preconditioned Richardson iteration more closely than the iterates of other common KRR solvers such as conjugate gradient.
Figures







read the original abstract
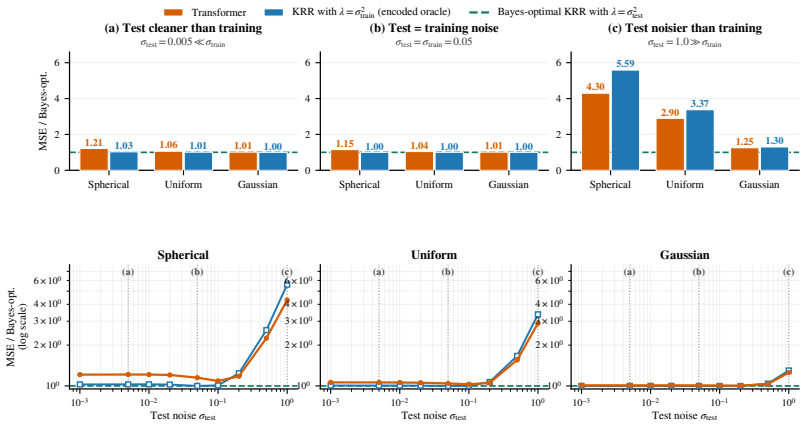
Mechanistic accounts of in-context learning (ICL) have identified iterative algorithms for linear regression and related linear prediction tasks, often using linear or ReLU attention variants. For nonlinear ICL, prior work has related softmax and kernelized attention to functional-gradient-type dynamics, but it remains unclear whether a standard transformer with softmax attention can implement a convergent solver with an end-to-end prediction-error guarantee. In this paper, we study in-context kernel ridge regression (KRR) with Gaussian kernels and show that a standard softmax-attention transformer can approximate the KRR predictor during its forward pass by implementing preconditioned Richardson iteration on the associated kernel linear system. Under bounded-data assumptions, we construct a single-head transformer with $O(\log(1/\epsilon))$ blocks and MLP width $O(\sqrt{N/\epsilon})$ that achieves $\epsilon$-accurate prediction for prompts of length $N$. Our construction reveals a functional decomposition within the transformer architecture: softmax attention produces a row-normalized Gaussian-kernel operator needed for cross-token interactions, while ReLU MLP layers act locally to approximate the intra-token scalar arithmetic required by the update. Empirically, we train GPT-2-style transformers on Gaussian-process regression tasks to further test the preconditioned Richardson interpretation. Through linear probing, we compare the transformer's layer-wise predictions with the step-wise outputs of classical KRR solvers and find that its error profiles align most consistently with preconditioned Richardson iteration. Ablation studies further support this interpretation. Together, our theory and experiments identify preconditioned Richardson iteration as a concrete mechanism that softmax-attention transformers can realize for nonlinear in-context Gaussian-kernel regression.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that a standard single-head softmax-attention transformer can implement preconditioned Richardson iteration on the kernel linear system to approximate the predictor for in-context Gaussian kernel ridge regression (KRR). Under bounded-data assumptions, it constructs a transformer with O(log(1/ε)) blocks and MLP width O(√(N/ε)) achieving ε-accurate predictions for length-N prompts. The construction decomposes the architecture into softmax attention realizing a row-normalized Gaussian-kernel operator and ReLU MLPs handling local scalar arithmetic. Empirically, GPT-2-style transformers are trained on Gaussian-process regression tasks; linear probing of layer-wise outputs is shown to align with the iteration steps of the classical solver, with supporting ablations.
Significance. If the construction and bounds hold, the work supplies an explicit mechanistic account of nonlinear ICL via iterative solvers, distinguishing the roles of attention and MLP layers in realizing kernel operators and arithmetic updates. The combination of a parameter-scaling construction with layer-wise empirical alignment to a concrete algorithm is a clear strength; it offers falsifiable predictions about internal dynamics that can be tested via probing. This advances the program of relating transformer forward passes to classical iterative methods beyond linear regression.
major comments (1)
- [Theoretical construction (abstract and main theory section)] The bounded-data assumptions (controlling operator norms of the row-normalized kernel matrix and keeping MLP approximations inside the linear-convergence regime) are load-bearing for both the O(log(1/ε)) depth guarantee and the ε-accuracy claim. The manuscript states the assumptions but provides no quantitative assessment of how often they hold for random or typical ICL prompts with Gaussian kernels; if violated, the preconditioner ceases to be contractive and the depth bound fails.
minor comments (1)
- [Empirical section] The description of the linear-probing procedure and the exact baseline solvers used for comparison could be expanded with pseudocode or explicit equations to make the alignment evidence easier to reproduce.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the work's significance and for highlighting the importance of the bounded-data assumptions in our theoretical construction. We address the major comment below and commit to revisions that strengthen the manuscript's empirical grounding.
read point-by-point responses
-
Referee: [Theoretical construction (abstract and main theory section)] The bounded-data assumptions (controlling operator norms of the row-normalized kernel matrix and keeping MLP approximations inside the linear-convergence regime) are load-bearing for both the O(log(1/ε)) depth guarantee and the ε-accuracy claim. The manuscript states the assumptions but provides no quantitative assessment of how often they hold for random or typical ICL prompts with Gaussian kernels; if violated, the preconditioner ceases to be contractive and the depth bound fails.
Authors: We agree that the bounded-data assumptions are essential to guaranteeing linear convergence of the preconditioned Richardson iteration and thus the O(log(1/ε)) depth bound. The manuscript presents the construction conditionally on these assumptions, which ensure the row-normalized kernel operator has spectral radius strictly less than one and that the local MLP approximations remain within the contraction regime. To provide the requested quantitative assessment, we will add a new subsection (and corresponding appendix) that empirically evaluates the assumptions on randomly generated ICL prompts drawn from Gaussian processes. Specifically, we will report the empirical distribution of the operator norm of the row-normalized kernel matrix for varying prompt lengths N, kernel bandwidths, and noise levels, along with the probability that the norm lies below the contractivity threshold required by our analysis. We will also include a brief robustness discussion of the iteration when the assumptions hold only approximately. These additions will be supported by new figures and will not alter the core theoretical claims. revision: yes
Circularity Check
No significant circularity; explicit construction with independent analysis
full rationale
The paper's derivation consists of an explicit, parameter-specified construction of a single-head softmax transformer (O(log(1/ε)) blocks, MLP width O(√(N/ε))) whose forward pass is shown to realize preconditioned Richardson iteration on the kernel system for in-context Gaussian KRR. Error bounds and convergence follow directly from standard operator-norm analysis of the row-normalized kernel matrix and local scalar approximation by ReLU MLPs, all under the paper's stated bounded-data assumptions; these steps do not reduce to fitted parameters, self-definitions, or prior self-citations. The empirical linear-probing experiments on trained GPT-2 models serve only as corroboration of the interpretation and are not load-bearing for the theoretical claim. No renaming of known results, smuggled ansatzes, or uniqueness theorems imported from the authors' prior work appear in the central chain.
Axiom & Free-Parameter Ledger
free parameters (2)
- Transformer depth scaling =
O(log(1/epsilon))
- MLP width scaling =
O(sqrt(N/epsilon))
axioms (1)
- domain assumption Bounded data assumptions
Reference graph
Works this paper leans on
-
[1]
Transformers learn to implement preconditioned gradient descent for in-context learning
Kwangjun Ahn, Xiang Cheng, Hadi Daneshmand, and Suvrit Sra. Transformers learn to implement preconditioned gradient descent for in-context learning. In Advances in Neural Information Processing Systems, volume 36, pages 45614--45650, 2023
work page 2023
-
[2]
What learning algorithm is in-context learning? investigations with linear models
Ekin Aky \"u rek, Dale Schuurmans, Jacob Andreas, Tengyu Ma, and Denny Zhou. What learning algorithm is in-context learning? investigations with linear models. In The Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[3]
In-context language learning: Architectures and algorithms
Ekin Aky \"u rek, Bailin Wang, Yoon Kim, and Jacob Andreas. In-context language learning: Architectures and algorithms. In International Conference on Machine Learning. PMLR, 2024
work page 2024
-
[4]
Breaking the curse of dimensionality with convex neural networks
Francis Bach. Breaking the curse of dimensionality with convex neural networks. Journal of Machine Learning Research, 18 0 (19): 0 1--53, 2017
work page 2017
-
[5]
Learning Theory from First Principles
Francis Bach. Learning Theory from First Principles. MIT Press, 2024
work page 2024
-
[6]
Transformers as statisticians: Provable in-context learning with in-context algorithm selection
Yu Bai, Fan Chen, Huan Wang, Caiming Xiong, and Song Mei. Transformers as statisticians: Provable in-context learning with in-context algorithm selection. In Advances in Neural Information Processing Systems, volume 36, pages 57125--57211, 2023
work page 2023
-
[7]
Understanding neural networks with reproducing kernel B anach spaces
Francesca Bartolucci, Ernesto De Vito, Lorenzo Rosasco, and Stefano Vigogna. Understanding neural networks with reproducing kernel B anach spaces. Applied and Computational Harmonic Analysis, 62: 0 194--236, 2023
work page 2023
-
[8]
Understanding in-context learning in transformers and LLM s by learning to learn discrete functions
Satwik Bhattamishra, Arkil Patel, Phil Blunsom, and Varun Kanade. Understanding in-context learning in transformers and LLM s by learning to learn discrete functions. In International Conference on Learning Representations, 2024
work page 2024
-
[9]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. In Advances in Neural Information Processing Systems, volume 33, pages 1877--1901, 2020
work page 1901
-
[10]
Optimal rates for the regularized least-squares algorithm
Andrea Caponnetto and Ernesto De Vito. Optimal rates for the regularized least-squares algorithm. Foundations of Computational Mathematics, 7 0 (3): 0 331--368, 2007
work page 2007
-
[11]
Siyu Chen, Heejune Sheen, Tianhao Wang, and Zhuoran Yang. Training dynamics of multi-head softmax attention for in-context learning: Emergence, convergence, and optimality. In The Thirty Seventh Annual Conference on Learning Theory, volume 247, pages 4573--4573. PMLR, 2024
work page 2024
-
[12]
Transformers implement functional gradient descent to learn non-linear functions in context
Xiang Cheng, Yuxin Chen, and Suvrit Sra. Transformers implement functional gradient descent to learn non-linear functions in context. In International Conference on Machine Learning, volume 235, pages 8002--8037. PMLR, 2024
work page 2024
-
[13]
Youngmin Cho and Lawrence K. Saul. Kernel methods for deep learning. In Advances in Neural Information Processing Systems 22, 2009
work page 2009
-
[14]
In-context learning with transformers: Softmax attention adapts to function lipschitzness
Liam Collins, Advait Parulekar, Aryan Mokhtari, Sujay Sanghavi, and Sanjay Shakkottai. In-context learning with transformers: Softmax attention adapts to function lipschitzness. In Advances in Neural Information Processing Systems, volume 37, pages 92638--92696, 2024
work page 2024
-
[15]
A practical guide to splines, volume 27
Carl De Boor. A practical guide to splines, volume 27. springer New York, 1978
work page 1978
-
[16]
Asymptotic study of in-context learning with random transformers through equivalent models, 2025
Samet Demir and Zafer Dogan. Asymptotic study of in-context learning with random transformers through equivalent models, 2025
work page 2025
-
[17]
Ronald DeVore. Nonlinear approximation. Acta numerica, 7: 0 51--150, 1998
work page 1998
-
[18]
Ronald DeVore, Boris Hanin, and Guergana Petrova. Neural network approximation. Acta Numerica, 30: 0 327--444, 2021
work page 2021
-
[19]
Sara Dragutinovi \'c , Andrew M. Saxe, and Aaditya K. Singh. Softmax linear: Transformers may learn to classify in-context by kernel gradient descent. arXiv preprint arXiv:2510.10425, 2025
-
[20]
Transformers learn to achieve second-order convergence rates for in-context linear regression
Deqing Fu, Tian-Qi Chen, Robin Jia, and Vatsal Sharan. Transformers learn to achieve second-order convergence rates for in-context linear regression. In Advances in Neural Information Processing Systems, volume 37, pages 98675--98716, 2024
work page 2024
-
[21]
Shivam Garg, Dimitris Tsipras, Percy S. Liang, and Gregory Valiant. What can transformers learn in-context? a case study of simple function classes. In Advances in Neural Information Processing Systems, volume 35, pages 30583--30598, 2022
work page 2022
-
[22]
Understanding emergent in-context learning from a kernel regression perspective
Chi Han, Ziqi Wang, Han Zhao, and Heng Ji. Understanding emergent in-context learning from a kernel regression perspective. Transactions on Machine Learning Research, 2025
work page 2025
-
[23]
In-context convergence of transformers
Yu Huang, Yuan Cheng, and Yingbin Liang. In-context convergence of transformers. In Proceedings of the 41st International Conference on Machine Learning, volume 235, pages 19660--19722. PMLR, 2024
work page 2024
-
[24]
Klusowski, Jianqing Fan, and Mengdi Wang
Zihao Li, Yuan Cao, Cheng Gao, Yihang He, Han Liu, Jason M. Klusowski, Jianqing Fan, and Mengdi Wang. One-layer transformer provably learns one-nearest neighbor in context. In Advances in Neural Information Processing Systems, volume 37, pages 82166--82204, 2024
work page 2024
-
[25]
Yue M. Lu, Mary I. Letey, Jacob A. Zavatone-Veth, Anindita Maiti, and Cengiz Pehlevan. Asymptotic theory of in-context learning by linear attention. Proceedings of the National Academy of Sciences, 122 0 (28): 0 e2502599122, 2025
work page 2025
-
[26]
Arvind V. Mahankali, Tatsunori B. Hashimoto, and Tengyu Ma. One step of gradient descent is provably the optimal in-context learner with one layer of linear self-attention. In International Conference on Learning Representations, 2024
work page 2024
-
[27]
Banach space representer theorems for neural networks and ridge splines
Rahul Parhi and Robert D Nowak. Banach space representer theorems for neural networks and ridge splines. Journal of Machine Learning Research, 22 0 (43): 0 1--40, 2021
work page 2021
-
[28]
Language models are unsupervised multitask learners
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. OpenAI Blog, 2019
work page 2019
-
[29]
Carl Edward Rasmussen and Christopher K. I. Williams. Gaussian Processes for Machine Learning. MIT Press, 2006
work page 2006
-
[30]
A Theoretical Introduction to Numerical Analysis
Victor Ryaben’kii and Semyon Tsynkov. A Theoretical Introduction to Numerical Analysis. Chapman & Hall, 2006
work page 2006
-
[31]
Towards understanding the universality of transformers for next-token prediction
Michael E Sander and Gabriel Peyr \'e . Towards understanding the universality of transformers for next-token prediction. arXiv preprint arXiv:2410.03011, 2024
-
[32]
A generalized representer theorem
Bernhard Sch \"o lkopf, Ralf Herbrich, and Alex J Smola. A generalized representer theorem. In International conference on computational learning theory, pages 416--426. Springer, 2001
work page 2001
-
[33]
Understanding in-context learning on structured manifolds: Bridging attention to kernel methods
Zhaiming Shen, Alexander Hsu, Rongjie Lai, and Wenjing Liao. Understanding in-context learning on structured manifolds: Bridging attention to kernel methods. arXiv preprint arXiv:2506.10959, 2025
-
[34]
An introduction to the conjugate gradient method without the agonizing pain
Jonathan R Shewchuk. An introduction to the conjugate gradient method without the agonizing pain. 1994
work page 1994
-
[35]
On the role of transformer feed-forward layers in nonlinear in-context learning, 2025
Haoyuan Sun, Ali Jadbabaie, and Navid Azizan. On the role of transformer feed-forward layers in nonlinear in-context learning, 2025
work page 2025
-
[36]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth \'e e Lacroix, Baptiste Rozi \`e re, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, ukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017
work page 2017
-
[38]
Linear transformers are versatile in-context learners
Max Vladymyrov, Johannes von Oswald, Mark Sandler, and Rong Ge. Linear transformers are versatile in-context learners. In Advances in Neural Information Processing Systems, volume 37, pages 48784--48809, 2024
work page 2024
-
[39]
Transformers learn in-context by gradient descent
Johannes von Oswald, Eyvind Niklasson, Ettore Randazzo, Jo \ a o Sacramento, Alexander Mordvintsev, Andrey Zhmoginov, and Max Vladymyrov. Transformers learn in-context by gradient descent. In International Conference on Machine Learning, pages 35151--35174. PMLR, 2023
work page 2023
-
[40]
Sparse representer theorems for learning in reproducing kernel B anach spaces
Rui Wang, Yuesheng Xu, and Mingsong Yan. Sparse representer theorems for learning in reproducing kernel B anach spaces. Journal of Machine Learning Research, 25 0 (93): 0 1--45, 2024
work page 2024
-
[41]
Hypothesis spaces for deep learning
Rui Wang, Yuesheng Xu, and Mingsong Yan. Hypothesis spaces for deep learning. Neural Networks, page 107995, 2025
work page 2025
- [42]
- [43]
-
[44]
Training dynamics of in-context learning in linear attention
Yedi Zhang, Freya Behrens, Florent Krzakala, and Lenka Zdeborov \'a . Training dynamics of in-context learning in linear attention. arXiv preprint arXiv:2501.16265, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.