Recognition: no theorem link
Slipstream: Trajectory-Grounded Compaction Validation for Long-Horizon Agents
Pith reviewed 2026-05-12 00:58 UTC · model grok-4.3
The pith
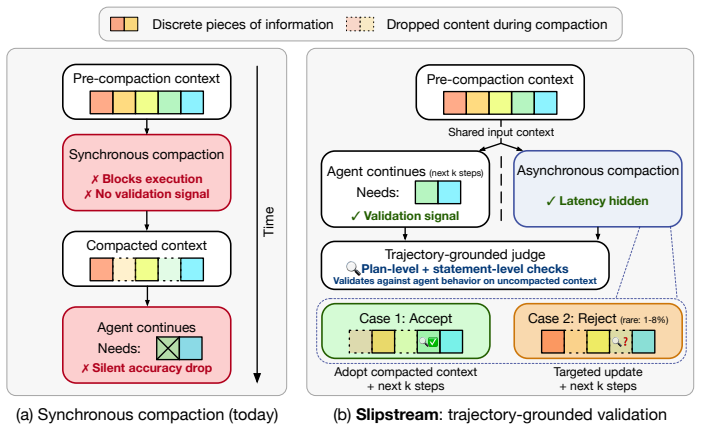
Asynchronous compaction runs the summary generator in parallel with the agent on the original trajectory so a judge can check preservation of forward intent and facts independently of the summary itself.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Slipstream shows that running the compactor in parallel with continued agent execution on the original context creates a validation signal independent of the summary; a judge LLM can therefore inspect the agent's next steps to confirm that the candidate summary preserves both forward intent and the key facts and constraints the agent depends on.
What carries the argument
The trajectory-grounded judge that validates a candidate summary by comparing it to the agent's continued reasoning trace generated from the identical pre-compaction state.
If this is right
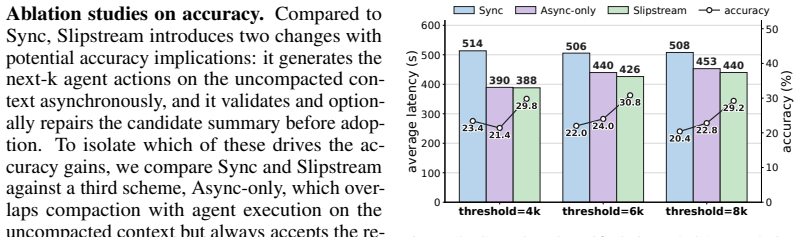
- Task accuracy rises by up to 8.8 percentage points on long-horizon coding and web-browsing benchmarks.
- End-to-end latency falls by up to 39.7 percent because compaction no longer blocks the agent's critical path.
- Validation errors are caught before they can propagate through subsequent coherent but incorrect agent steps.
- The same pre-compaction trajectory supplies both the summary and its independent validation signal.
Where Pith is reading between the lines
- If the judge works reliably, the same parallel-validation pattern could be applied to other context-reduction methods such as retrieval or memory pruning.
- Agent designs that surface explicit forward-intent statements might make the judge's check simpler and more robust.
- Repeated application across multiple compaction steps could preserve coherence over horizons far longer than single-step validation allows.
Load-bearing premise
A judge LLM can reliably determine whether a candidate summary preserves the agent's forward intent and necessary facts solely by inspecting the agent's continued reasoning on the original trajectory, without access to ground-truth future outcomes.
What would settle it
An experiment that measures whether summaries accepted by the judge produce measurably higher final task success rates than summaries rejected by the judge or than randomly chosen summaries on the same long-horizon benchmarks.
Figures




read the original abstract
To cope with the large contexts that long-horizon LLM agents produce, modern frameworks increasingly rely on compaction -- invoking an LLM to rewrite the accumulated trajectory into a shorter summary that the agent resumes from. Today, compaction runs synchronously on the critical path of agent execution but this can unpredictably degrade accuracy due to a structural validation gap: the compactor must condense context but is fundamentally unaware of precisely what information the agent will need later. Further, because post-compaction agent steps are conditioned on the new summary, targeted validation criteria do not exist and errors silently propagate through coherent but incorrect behavior. Our key insight is that asynchronous compaction efficiently addresses this gap: by running the compactor in parallel with continued agent execution on the original context, the candidate summary and the agent's next steps are generated independently from the same pre-compaction state, yielding a validation signal independent of the summary itself. We build Slipstream, a trajectory-grounded compaction system that uses a judge to validate the candidate summary against the agent's continued reasoning, checking that it preserves both the agent's forward intent and the key facts and constraints it depends on. Across long-horizon coding (SWE-bench Verified) and web-browsing (BrowseComp) workloads, Slipstream improves task accuracy by up to 8.8 percentage points while reducing end-to-end latency by up to 39.7%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Slipstream, a system for asynchronous compaction validation in long-horizon LLM agents. It identifies a structural validation gap in synchronous compaction where the compactor lacks knowledge of future agent needs, leading to silent accuracy degradation. The proposed solution runs the compactor in parallel with continued agent execution on the original pre-compaction context, then employs a judge LLM to validate candidate summaries by checking preservation of forward intent and key facts against the independently generated next-step trajectory. Empirical evaluation on SWE-bench Verified (coding) and BrowseComp (web-browsing) reports task accuracy gains of up to 8.8 percentage points and end-to-end latency reductions of up to 39.7%.
Significance. If the validation signal proves reliable and the reported gains hold under rigorous controls, this work could meaningfully advance practical context management for LLM agents by enabling compaction off the critical path without accuracy penalties. The asynchronous design provides a clean separation between summary generation and validation, and the concrete benchmark improvements constitute a practical contribution. The empirical focus on real workloads is a strength, though the absence of detailed protocol information and analysis of long-term dependency capture limits immediate impact assessment.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments section: The reported accuracy gains of up to 8.8 percentage points and latency reductions of up to 39.7% are presented without specification of the exact baselines (e.g., synchronous compaction variants or alternative summarizers), number of trials, statistical significance tests, error bars, or precise measurement protocol for end-to-end latency and task success. This information is load-bearing for interpreting the magnitude and robustness of the central empirical claims.
- [Method] Method section (asynchronous validation description): The validation relies on a judge LLM inspecting the agent's continued reasoning on the original trajectory to confirm preservation of forward intent and facts. No ablation, correlation analysis, or long-horizon experiment is provided to test whether immediate next steps reliably surface all constraints that may only become relevant many steps later, leaving the weakest assumption unexamined and risking false acceptances on tasks where dependencies are delayed.
minor comments (2)
- [Method] The manuscript would benefit from a diagram or pseudocode illustrating the parallel execution flow of the compactor and agent to clarify the independence of the validation signal.
- [Preliminaries] Notation for the pre- and post-compaction states and the judge input format should be standardized and defined explicitly in the first use.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and for acknowledging the potential practical contribution of our asynchronous compaction approach. We address each major comment below with clarifications and commitments to revisions that improve the manuscript's clarity and rigor.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: The reported accuracy gains of up to 8.8 percentage points and latency reductions of up to 39.7% are presented without specification of the exact baselines (e.g., synchronous compaction variants or alternative summarizers), number of trials, statistical significance tests, error bars, or precise measurement protocol for end-to-end latency and task success. This information is load-bearing for interpreting the magnitude and robustness of the central empirical claims.
Authors: We agree that these details are essential for evaluating the empirical claims. The current manuscript presents high-level results without sufficient protocol information. In the revised version, we will expand the Experiments section with a dedicated 'Experimental Setup' subsection specifying: the exact baselines (synchronous compaction with standard LLM summarizers and alternative methods), number of trials and seeds, statistical tests (e.g., McNemar's test for accuracy differences and paired t-tests for latency) with p-values, error bars as standard error, and the precise end-to-end latency protocol (full task duration including compaction and validation overhead). We will also update the abstract to reference these controlled comparisons. revision: yes
-
Referee: [Method] Method section (asynchronous validation description): The validation relies on a judge LLM inspecting the agent's continued reasoning on the original trajectory to confirm preservation of forward intent and facts. No ablation, correlation analysis, or long-horizon experiment is provided to test whether immediate next steps reliably surface all constraints that may only become relevant many steps later, leaving the weakest assumption unexamined and risking false acceptances on tasks where dependencies are delayed.
Authors: We acknowledge the importance of examining whether next-step trajectories capture delayed dependencies. Our design prioritizes an independent validation signal from the pre-compaction state to prevent circularity, and the observed accuracy gains on long-horizon benchmarks provide supporting evidence. To directly address this, the revised manuscript will include a new analysis subsection with: an ablation varying validation trajectory length (1, 3, and 5 steps), a correlation analysis between judge scores and final task success, and an explicit discussion of limitations for very long-term dependencies along with potential mitigations such as periodic re-validation. These will be evaluated on the existing SWE-bench and BrowseComp workloads. revision: partial
Circularity Check
No circularity: empirical system design with independent validation signal
full rationale
The paper presents Slipstream as an empirical system for asynchronous compaction in LLM agents. The central insight—that running compaction in parallel with continued execution on the original context yields an independent validation signal—is a design choice, not a derivation from equations or self-referential definitions. No load-bearing steps reduce to fitted parameters, self-citations, or ansatzes by construction. The approach is evaluated on external benchmarks (SWE-bench Verified, BrowseComp) with reported accuracy and latency improvements. The LLM judge assumption is stated but does not create internal circularity in the claimed results.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The compactor is fundamentally unaware of future information needs when summarizing synchronously.
- domain assumption Parallel execution on the original context produces an independent validation signal usable by a judge.
Reference graph
Works this paper leans on
- [1]
- [2]
-
[4]
Jimenez, Carlos E. and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik R. , booktitle =. 2024 , eprint =
work page 2024
- [5]
-
[6]
and Keutzer, Kurt and Gholami, Amir , booktitle =
Kim, Sehoon and Moon, Suhong and Tabrizi, Ryan and Lee, Nicholas and Mahoney, Michael W. and Keutzer, Kurt and Gholami, Amir , booktitle =. An. 2024 , eprint =
work page 2024
- [7]
-
[8]
How to Manage Long Context with Summarization , author =. 2025 , howpublished =
work page 2025
-
[10]
and Zhang, Hao and Stoica, Ion , booktitle =
Kwon, Woosuk and Li, Zhuohan and Zhuang, Siyuan and Sheng, Ying and Zheng, Lianmin and Yu, Cody Hao and Gonzalez, Joseph E. and Zhang, Hao and Stoica, Ion , booktitle =. Efficient Memory Management for Large Language Model Serving with. 2023 , eprint =
work page 2023
-
[12]
Cascade Inference: Memory-Efficient Shared Prefix Batch Decoding , author =. 2024 , month =
work page 2024
-
[14]
Lost in the Middle: How Language Models Use Long Contexts
Lost in the Middle: How Language Models Use Long Contexts , author =. 2023 , eprint =. doi:10.48550/arXiv.2307.03172 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.03172 2023
-
[15]
On Context Utilization in Summarization with Large Language Models , author =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2024 , address =. doi:10.18653/v1/2024.acl-long.153 , url =
-
[16]
Context Rot: How Increasing Input Tokens Impacts LLM Performance , author =. 2025 , month =
work page 2025
-
[17]
Bai, Yushi and Lv, Xin and Zhang, Jiajie and Lyu, Hongchang and Tang, Jiankai and Huang, Zhidian and Du, Zhengxiao and Liu, Xiao and Zeng, Aohan and Hou, Lei and Dong, Yuxiao and Tang, Jie and Li, Juanzi , booktitle =. 2024 , doi =
work page 2024
-
[18]
RULER: What's the Real Context Size of Your Long-Context Language Models?
Hsieh, Cheng-Ping and Sun, Simeng and Kriman, Samuel and Acharya, Shantanu and Rekesh, Dima and Jia, Fei and Zhang, Yang and Ginsburg, Boris , booktitle =. 2024 , eprint =. doi:10.48550/arXiv.2404.06654 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2404.06654 2024
-
[19]
doi:10.48550/arXiv.2407.11963 , url =
Li, Mo and Zhang, Songyang and Zhang, Taolin and Duan, Haodong and Liu, Yunxin and Chen, Kai , year =. doi:10.48550/arXiv.2407.11963 , url =. 2407.11963 , archivePrefix =
-
[20]
Rossi, Seunghyun Yoon, and Hinrich Schütze
Modarressi, Ali and Deilamsalehy, Hanieh and Dernoncourt, Franck and Bui, Trung and Rossi, Ryan A. and Yoon, Seunghyun and Sch. Forty-second International Conference on Machine Learning , year =. doi:10.48550/arXiv.2502.05167 , url =. 2502.05167 , archivePrefix =
- [22]
-
[25]
arXiv preprint arXiv:2503.14499 , year=
Measuring AI Ability to Complete Long Software Tasks , author =. Advances in Neural Information Processing Systems , year =. doi:10.48550/arXiv.2503.14499 , url =. 2503.14499 , archivePrefix =
-
[26]
Scaling long-horizon LLM agent via context-folding.CoRR, abs/2510.11967, 2025
Scaling Long-Horizon LLM Agent via Context-Folding , author =. 2025 , eprint =. doi:10.48550/arXiv.2510.11967 , url =
-
[27]
and Wutschitz, Lukas and Chen, Yanzhi and Sim, Robert and Rajmohan, Saravan , booktitle =
Kang, Minki and Chen, Wei-Ning and Han, Dongge and Inan, Huseyin A. and Wutschitz, Lukas and Chen, Yanzhi and Sim, Robert and Rajmohan, Saravan , booktitle =. 2026 , url =
work page 2026
-
[28]
Beyond Static Summarization: Proactive Memory Extraction for LLM Agents , author =. 2026 , eprint =. doi:10.48550/arXiv.2601.04463 , url =
- [29]
-
[30]
Memory & Context Management with Claude Sonnet 4.6 , author =. 2026 , howpublished =
work page 2026
-
[31]
Context Engineering: Memory, Compaction, and Tool Clearing , author =. 2026 , howpublished =
work page 2026
-
[32]
Effective Context Engineering for AI Agents , author =. 2025 , month =
work page 2025
- [33]
- [34]
-
[35]
Slash Commands, Summarization, and Improved Agent Terminal , author =. 2025 , month =
work page 2025
- [36]
- [37]
-
[38]
Context Engineering: Short-Term Memory Management with Sessions , author =. 2025 , howpublished =
work page 2025
-
[39]
Advances in Neural Information Processing Systems , volume=
Swe-agent: Agent-computer interfaces enable automated software engineering , author=. Advances in Neural Information Processing Systems , volume=
-
[41]
Advances in neural information processing systems , volume=
Toolformer: Language models can teach themselves to use tools , author=. Advances in neural information processing systems , volume=
-
[43]
Advances in Neural Information Processing Systems , volume=
Snapkv: Llm knows what you are looking for before generation , author=. Advances in Neural Information Processing Systems , volume=
-
[46]
Proceedings of the AAAI Conference on Artificial Intelligence , year=
MemoryBank: Enhancing Large Language Models with Long-Term Memory , author=. Proceedings of the AAAI Conference on Artificial Intelligence , year=
-
[47]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[50]
Evaluating the Factual Consistency of Abstractive Text Summarization , author=. Proceedings of EMNLP , year=
-
[51]
Proceedings of NAACL-HLT , year=
Evaluating Content Selection in Summarization: The Pyramid Method , author=. Proceedings of NAACL-HLT , year=
-
[52]
FEQA: A Question Answering Evaluation Framework for Faithfulness Assessment in Abstractive Summarization , author=. Proceedings of ACL , year=
-
[53]
G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment , author=. Proceedings of EMNLP , year=
-
[54]
Re-Examining System-Level Correlations of Automatic Summarization Evaluation Metrics , author=. Proceedings of NAACL , year=
-
[55]
QuestEval: Summarization Asks for Fact-based Evaluation , author=. Proceedings of EMNLP , year=
-
[56]
Extractive is not Faithful: An Investigation of Broad Unfaithfulness Problems in Extractive Summarization , author=. Proceedings of ACL , year=
-
[57]
FABLES: Evaluating Faithfulness and Content Selection in Book-Length Summarization , author=. Proceedings of COLM , year=
-
[58]
Text Summarization Branches Out , year=
ROUGE: A Package for Automatic Evaluation of Summaries , author=. Text Summarization Branches Out , year=
-
[59]
Anthropic . Automatic context compaction. https://platform.claude.com/cookbook/tool-use-automatic-context-compaction, 2026 a . Claude Cookbook. Accessed: 2026-04-30
work page 2026
-
[60]
Anthropic . Compaction. https://platform.claude.com/docs/en/build-with-claude/compaction, 2026 b . Claude API documentation (beta). Accessed: 2026-05-05
work page 2026
-
[61]
Context engineering: Memory, compaction, and tool clearing
Anthropic . Context engineering: Memory, compaction, and tool clearing. https://platform.claude.com/cookbook/tool-use-context-engineering-context-engineering-tools, 2026 c . Claude Cookbook. Accessed: 2026-04-30
work page 2026
-
[62]
Rocketkv: Accelerating long-context llm inference via two-stage kv cache compression
Payman Behnam, Yaosheng Fu, Ritchie Zhao, Po-An Tsai, Zhiding Yu, and Alexey Tumanov. Rocketkv: Accelerating long-context llm inference via two-stage kv cache compression. arXiv preprint arXiv:2502.14051, 2025
-
[63]
ByteDance Seed Team . Seed- OSS open-source models. https://github.com/ByteDance-Seed/seed-oss, 2025. Accessed: 2026-05-05
work page 2025
-
[64]
PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling
Zefan Cai, Yichi Zhang, Bofei Gao, Yuliang Liu, Yucheng Li, Tianyu Liu, Keming Lu, Wayne Xiong, Yue Dong, Junjie Hu, et al. Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling. arXiv preprint arXiv:2406.02069, 2024
work page internal anchor Pith review arXiv 2024
-
[65]
Re-examining system-level correlations of automatic summarization evaluation metrics
Daniel Deutsch, Rotem Dror, and Dan Roth. Re-examining system-level correlations of automatic summarization evaluation metrics. In Proceedings of NAACL, 2022
work page 2022
-
[66]
Yufeng Du, Minyang Tian, Srikanth Ronanki, Subendhu Rongali, Sravan Babu Bodapati, Aram Galstyan, Azton Wells, Roy Schwartz, Eliu A. Huerta, and Hao Peng. Context length alone hurts LLM performance despite perfect retrieval. In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 23281--23298, Suzhou, China, 2025. Association for C...
-
[67]
Esin Durmus, He He, and Mona Diab. Feqa: A question answering evaluation framework for faithfulness assessment in abstractive summarization. In Proceedings of ACL, 2020
work page 2020
-
[68]
Cascade inference: Memory-efficient shared prefix batch decoding
FlashInfer Team . Cascade inference: Memory-efficient shared prefix batch decoding. https://flashinfer.ai/2024/02/02/cascade-inference.html, February 2024. FlashInfer blog post. Accessed: 2026-05-04
work page 2024
-
[69]
Context rot: How increasing input tokens impacts llm performance
Kelly Hong, Anton Troynikov, and Jeff Huber. Context rot: How increasing input tokens impacts llm performance. Technical report, Chroma, July 2025. URL https://trychroma.com/research/context-rot
work page 2025
-
[70]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R. Narasimhan. SWE -bench: Can language models resolve real-world GitHub issues? In The Twelfth International Conference on Learning Representations, 2024. URL https://arxiv.org/abs/2310.06770
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[71]
Mahoney, Kurt Keutzer, and Amir Gholami
Sehoon Kim, Suhong Moon, Ryan Tabrizi, Nicholas Lee, Michael W. Mahoney, Kurt Keutzer, and Amir Gholami. An LLM compiler for parallel function calling. In Proceedings of the 41st International Conference on Machine Learning, 2024 a . URL https://arxiv.org/abs/2312.04511
-
[72]
Fables: Evaluating faithfulness and content selection in book-length summarization
Yekyung Kim, Yapei Chang, Marzena Karpinska, Aparna Garimella, Varun Manjunatha, Kyle Lo, Tanya Goyal, and Mohit Iyyer. Fables: Evaluating faithfulness and content selection in book-length summarization. In Proceedings of COLM, 2024 b
work page 2024
-
[73]
Evaluating the factual consistency of abstractive text summarization
Wojciech Kryscinski, Bryan McCann, Caiming Xiong, and Richard Socher. Evaluating the factual consistency of abstractive text summarization. In Proceedings of EMNLP, 2020
work page 2020
-
[74]
Efficient Memory Management for Large Language Model Serving with PagedAttention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with PagedAttention . In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023. URL https://arxiv.org/abs/2309.06180
work page internal anchor Pith review arXiv 2023
-
[75]
How to manage long context with summarization
LangChain . How to manage long context with summarization. https://langchain-ai.github.io/langmem/guides/summarization/, 2025. LangMem documentation. Accessed: 2026-05-05
work page 2025
-
[76]
u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K \"u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \"a schel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive nlp tasks. In Advances in Neural Information Processing Systems (NeurIPS), 2020
work page 2020
-
[77]
Snapkv: Llm knows what you are looking for before generation
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. Snapkv: Llm knows what you are looking for before generation. Advances in Neural Information Processing Systems, 37: 0 22947--22970, 2024
work page 2024
-
[78]
Rouge: A package for automatic evaluation of summaries
Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. In Text Summarization Branches Out, 2004
work page 2004
-
[79]
Lost in the Middle: How Language Models Use Long Contexts
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts, 2023 a . URL https://arxiv.org/abs/2307.03172
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[80]
G-eval: Nlg evaluation using gpt-4 with better human alignment
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-eval: Nlg evaluation using gpt-4 with better human alignment. In Proceedings of EMNLP, 2023 b
work page 2023
-
[81]
Scaling llm multi-turn rl with end-to-end summarization-based context management
Miao Lu, Weiwei Sun, Weihua Du, Zhan Ling, Xuesong Yao, Kang Liu, and Jiecao Chen. Scaling llm multi-turn rl with end-to-end summarization-based context management. arXiv preprint arXiv:2510.06727, 2025
-
[82]
GAIA: a benchmark for General AI Assistants
Gr \'e goire Mialon, Cl \'e mentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. GAIA : A benchmark for general AI assistants, 2023. URL https://arxiv.org/abs/2311.12983
work page internal anchor Pith review arXiv 2023
-
[83]
Microsoft . Compaction. https://learn.microsoft.com/en-us/agent-framework/agents/conversations/compaction, 2026. Microsoft Agent Framework documentation. Accessed: 2026-05-05
work page 2026
-
[84]
WebGPT: Browser-assisted question-answering with human feedback
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al. Webgpt: Browser-assisted question-answering with human feedback. arXiv preprint arXiv:2112.09332, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[85]
Evaluating content selection in summarization: The pyramid method
Ani Nenkova and Rebecca Passonneau. Evaluating content selection in summarization: The pyramid method. In Proceedings of NAACL-HLT, 2004
work page 2004
-
[86]
Memgpt: towards llms as operating systems
Charles Packer, Vivian Fang, Shishir\_G Patil, Kevin Lin, Sarah Wooders, and Joseph\_E Gonzalez. Memgpt: towards llms as operating systems. 2023
work page 2023
-
[87]
Specrea- son: Fast and accurate inference-time compute via speculative reasoning
Rui Pan, Yinwei Dai, Zhihao Zhang, Gabriele Oliaro, Zhihao Jia, and Ravi Netravali. Specreason: Fast and accurate inference-time compute via speculative reasoning. arXiv preprint arXiv:2504.07891, 2025
-
[88]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dess \` , Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. Advances in neural information processing systems, 36: 0 68539--68551, 2023
work page 2023
-
[89]
Questeval: Summarization asks for fact-based evaluation
Thomas Scialom, Paul-Alexis Dray, Sylvain Lamprier, Benjamin Piwowarski, Jacopo Staiano, Alex Wang, and Patrick Gallinari. Questeval: Summarization asks for fact-based evaluation. In Proceedings of EMNLP, 2021
work page 2021
-
[90]
Scaling long-horizon LLM agent via context-folding.CoRR, abs/2510.11967, 2025
Weiwei Sun, Miao Lu, Zhan Ling, Kang Liu, Xuesong Yao, Yiming Yang, and Jiecao Chen. Scaling long-horizon llm agent via context-folding, 2025. URL https://arxiv.org/abs/2510.11967
-
[91]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
Xingyao Wang, Boxuan Li, Yufan Song, Frank F Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, et al. Openhands: An open platform for ai software developers as generalist agents. arXiv preprint arXiv:2407.16741, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[92]
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents
Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeffrey Han, Isa Fulford, Hyung Won Chung, Alex Tachard Passos, William Fedus, and Amelia Glaese. BrowseComp : A simple yet challenging benchmark for browsing agents, 2025. URL https://arxiv.org/abs/2504.12516
work page internal anchor Pith review arXiv 2025
-
[93]
Haoran Wu, Can Xiao, Jiayi Nie, Xuan Guo, Binglei Lou, Jeffrey T. H. Wong, Zhiwen Mo, Cheng Zhang, Przemyslaw Forys, Chengyang Ai, Timi Adeniran, Wayne Luk, Hongxiang Fan, Jianyi Cheng, Timothy M. Jones, Rika Antonova, Robert Mullins, and Aaron Zhao. Combating the memory walls: Optimization pathways for long-context agentic LLM inference, 2025 a . URL htt...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.