Recognition: 2 theorem links
· Lean TheoremPAAC: Privacy-Aware Agentic Device-Cloud Collaboration
Pith reviewed 2026-05-12 00:58 UTC · model grok-4.3
The pith
PAAC splits LLM agent tasks across device and cloud using typed placeholders so the cloud reasons without seeing private data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PAAC aligns planner-executor decomposition with the device-cloud boundary so role specialization itself becomes the privacy mechanism: the cloud reasons over typed placeholder tokens that preserve each sensitive value's reasoning role while discarding its content, the on-device agent identifies sensitive spans and distills each step's execution outcome into compact key findings, and sanitization confines the on-device LLM to proposing masks while a deterministic registry performs all substitution and reversal.
What carries the argument
Typed placeholder tokens that encode the reasoning role of each sensitive value, combined with a deterministic registry that performs substitution and reversal without relying on the on-device LLM for those operations.
If this is right
- The same decomposition improves performance consistently across 17 additional benchmarks spanning math, science, and finance.
- Privacy gains are largest when targets do not fit fixed entity taxonomies.
- Confining the on-device model to mask proposals and outcome distillation limits error propagation.
- The approach treats the device-cloud boundary as a trust boundary rather than a simple compute split.
Where Pith is reading between the lines
- Similar role-based masking could apply to other multi-party agent systems where functional decomposition matches trust levels.
- The method implies that agent architectures can embed privacy as a structural property rather than a post-hoc filter.
- Extending placeholder types to capture more relational context might further reduce information loss on complex tasks.
Load-bearing premise
Typed placeholder tokens must retain enough structural and role information for the cloud to produce correct reasoning steps, and the on-device LLM must reliably identify sensitive spans and distill outcomes without introducing errors that reach the final answer.
What would settle it
A controlled test on an agentic benchmark where replacing real values with typed placeholders causes the cloud planner to output incorrect reasoning steps at a rate that makes final accuracy no higher than existing device-cloud baselines.
Figures






















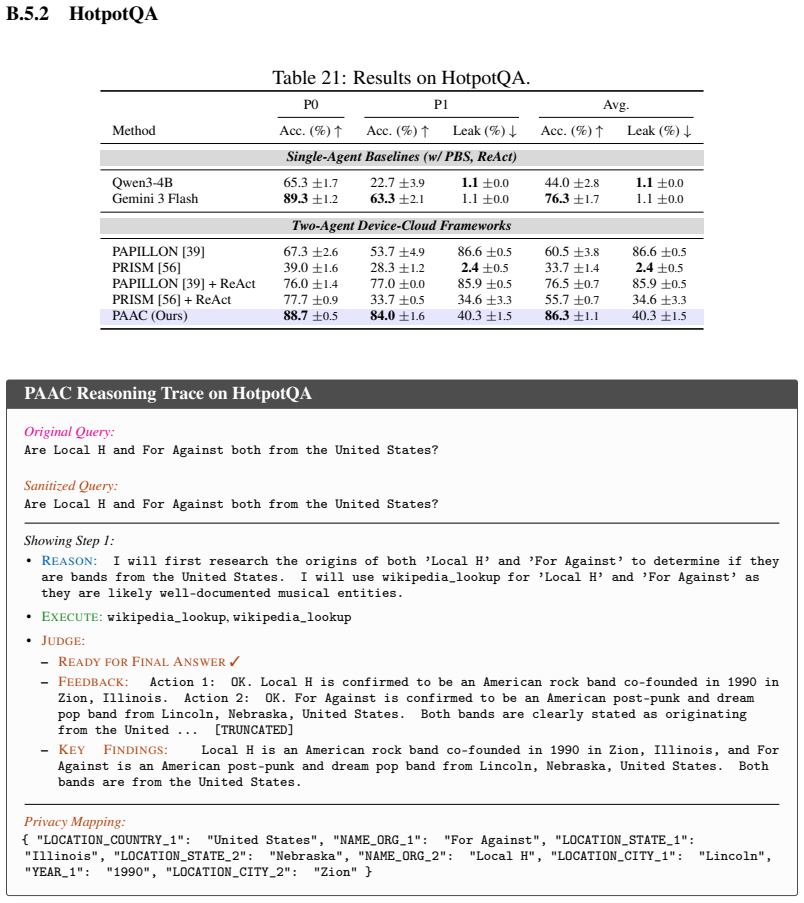

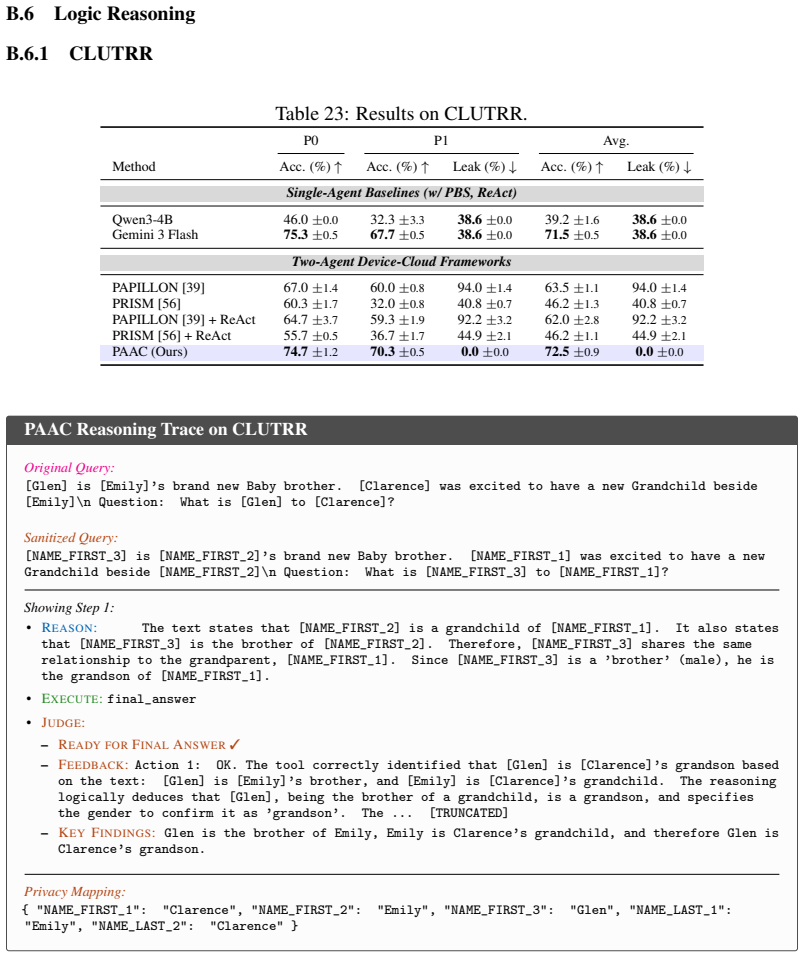
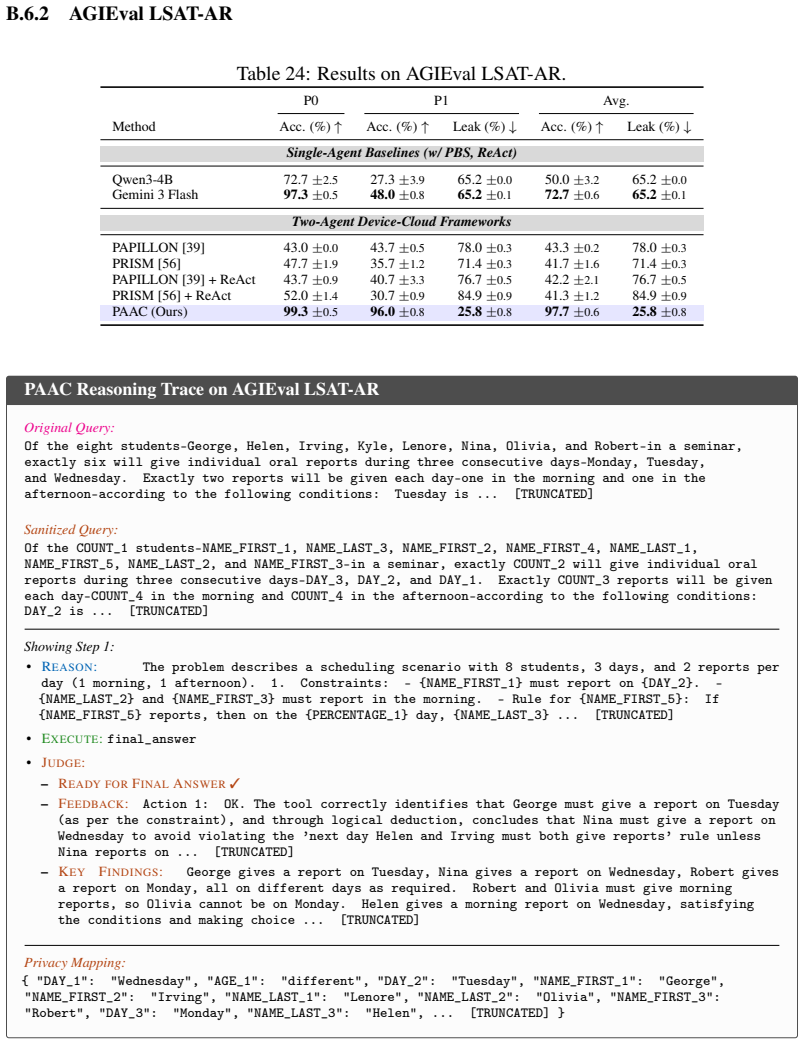




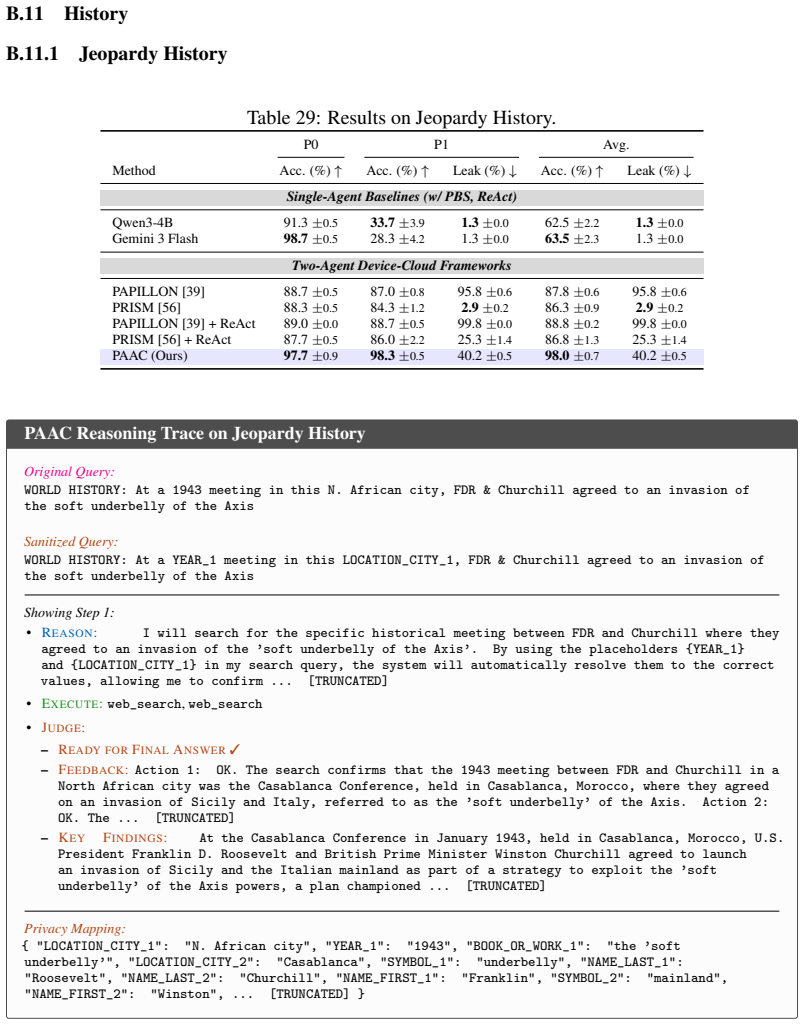








read the original abstract
Large language model (LLM) agents face a structural tension: cloud agents provide strong reasoning but expose user data, while on-device agents preserve privacy at the cost of overall capability. Existing device-cloud designs treat this boundary as a compute split rather than a trust boundary suited to agentic workloads, and existing sanitizers force a choice between policy flexibility and the structural fidelity tool calls require. In this work, we develop PAAC, a privacy-aware agentic framework that aligns planner--executor decomposition with the device-cloud boundary so that role specialization itself becomes the privacy mechanism. The cloud agent reasons over typed placeholder tokens that preserve each sensitive value's reasoning role while discarding its content, while the on-device agent identifies sensitive spans and distills each step's execution outcome into compact key findings. Sanitization confines the on-device LLM to proposing which spans to mask, while a deterministic registry performs all substitution and reversal, keeping actions directly executable on device. On three agentic benchmarks under strict privacy settings, PAAC dominates the Pareto frontier of privacy and accuracy, improving average accuracy by 15-36\% and reducing average leakage by 2-6$\times$ over state-of-the-art device-cloud baselines, with the largest margins on privacy targets outside fixed entity taxonomies. We find consistent improvements on 17 additional benchmarks spanning 10 domains, including math, science, and finance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PAAC, a privacy-aware agentic framework for LLM agents that aligns planner-executor decomposition with the device-cloud trust boundary. The cloud reasons over typed placeholder tokens that preserve each sensitive value's reasoning role while discarding content; the on-device agent identifies sensitive spans and distills execution outcomes, with a deterministic registry handling all substitution and reversal. The central claim is that, on three agentic benchmarks under strict privacy settings, PAAC dominates the privacy-accuracy Pareto frontier, delivering 15-36% higher average accuracy and 2-6× lower average leakage than state-of-the-art device-cloud baselines (with largest gains on targets outside fixed entity taxonomies), plus consistent improvements on 17 additional benchmarks across 10 domains.
Significance. If the experimental results hold, the work would be significant for private LLM agents by treating the device-cloud boundary as a trust boundary rather than a simple compute split and by using role specialization itself as the privacy mechanism. This avoids the policy-flexibility versus structural-fidelity trade-off of existing sanitizers and could enable more capable on-device agents without exposing raw data.
major comments (2)
- Abstract (central claim paragraph): The reported 15-36% accuracy gains and 2-6× leakage reductions are stated without any description of the three agentic benchmarks, how 'strict privacy settings' are enforced, baseline implementations, leakage measurement protocol, error bars, data exclusion rules, or statistical tests. This omission is load-bearing for the Pareto-dominance claim because the numerical improvements cannot be evaluated for robustness or reproducibility from the given text.
- Abstract (framework description): The approach relies on two load-bearing assumptions that receive no quantitative support: (1) typed placeholder tokens retain enough structural/role information for the cloud planner to produce correct multi-step reasoning, and (2) the on-device LLM reliably identifies sensitive spans and distills outcomes without injecting errors that propagate to final answers. No ablations on placeholder fidelity, measured on-device error rates, or propagation analysis are mentioned, so the gains cannot be confidently attributed to PAAC rather than baseline artifacts or task-specific factors.
minor comments (1)
- Abstract (final sentence): The claim of 'consistent improvements on 17 additional benchmarks spanning 10 domains' is presented without any quantitative details or domain-specific breakdowns, reducing its utility for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We agree that the abstract would benefit from additional context and will revise it accordingly to improve clarity on our claims and framework while preserving conciseness.
read point-by-point responses
-
Referee: [—] Abstract (central claim paragraph): The reported 15-36% accuracy gains and 2-6× leakage reductions are stated without any description of the three agentic benchmarks, how 'strict privacy settings' are enforced, baseline implementations, leakage measurement protocol, error bars, data exclusion rules, or statistical tests. This omission is load-bearing for the Pareto-dominance claim because the numerical improvements cannot be evaluated for robustness or reproducibility from the given text.
Authors: We agree that the abstract is too concise to allow full evaluation of the central claims. In the revised version we will expand the abstract with brief descriptions of the three agentic benchmarks, the definition and enforcement of strict privacy settings, the baseline implementations, the leakage measurement protocol, and explicit references to the error bars, data exclusion rules, and statistical tests reported in the main text. revision: yes
-
Referee: [—] Abstract (framework description): The approach relies on two load-bearing assumptions that receive no quantitative support: (1) typed placeholder tokens retain enough structural/role information for the cloud planner to produce correct multi-step reasoning, and (2) the on-device LLM reliably identifies sensitive spans and distills outcomes without injecting errors that propagate to final answers. No ablations on placeholder fidelity, measured on-device error rates, or propagation analysis are mentioned, so the gains cannot be confidently attributed to PAAC rather than baseline artifacts or task-specific factors.
Authors: We agree that the abstract does not mention the quantitative validation of these assumptions. We will revise the abstract to state that the structural fidelity of typed placeholders and the reliability of on-device sanitization (including error rates and propagation) are supported by dedicated ablations and analyses presented in the experimental sections of the manuscript. revision: yes
Circularity Check
No circularity; architectural framework with empirical results only
full rationale
The abstract describes PAAC via high-level architectural choices (planner-executor split, typed placeholders, deterministic registry) and reports benchmark outcomes (15-36% accuracy gains, 2-6× leakage reduction) without any equations, fitted parameters, derivations, or self-citations. No load-bearing step reduces to its own inputs by construction, as there is no mathematical chain or uniqueness theorem invoked. The text is self-contained at the level of system design and external benchmark comparison.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM agents can be usefully decomposed into planner and executor roles whose separation aligns with device-cloud trust boundaries.
- domain assumption Typed placeholder tokens can preserve sufficient reasoning structure for cloud agents without exposing content.
invented entities (2)
-
typed placeholder tokens
no independent evidence
-
deterministic registry
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearcloud agent reasons over typed placeholder tokens that preserve each sensitive value's reasoning role while discarding its content
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearProposer–Verifier–Registry Sanitization
Reference graph
Works this paper leans on
-
[1]
AI4Privacy. AI4Privacy: PII Masking 400k. https://huggingface.co/datasets/ ai4privacy/pii-masking-400k
-
[2]
MathQA: Towards Interpretable Math Word Problem Solving with Operation-Based Formalisms
Aida Amini, Saadia Gabriel, Shanchuan Lin, Rik Koncel-Kedziorski, Yejin Choi, and Hannaneh Hajishirzi. MathQA: Towards Interpretable Math Word Problem Solving with Operation-Based Formalisms. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and ...
work page 2019
-
[3]
$\tau^2$-Bench: Evaluating Conversational Agents in a Dual-Control Environment
Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan. τ 2-Bench: Eval- uating Conversational Agents in a Dual-Control Environment.arXiv preprint arXiv:2506.07982, 2025
work page internal anchor Pith review arXiv 2025
-
[4]
Yu Chen, Tingxin Li, Huiming Liu, and Yang Yu. Hide and Seek (HaS): A Lightweight Framework for Prompt Privacy Protection.arXiv preprint arXiv:2309.03057, 2023
-
[5]
FinQA: A Dataset of Numerical Reasoning over Financial Data
Zhiyu Chen, Wenhu Chen, Charese Smiley, Sameena Shah, Iana Borova, Dylan Langdon, Reema Moussa, Matt Beane, Ting-Hao Huang, Bryan R Routledge, et al. FinQA: A Dataset of Numerical Reasoning over Financial Data. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 3697–3711, 2021
work page 2021
-
[6]
Ziling Cheng, Meng Cao, Leila Pishdad, Yanshuai Cao, and Jackie CK Cheung. Can LLMs Reason Abstractly Over Math Word Problems Without CoT? Disentangling Abstract Formu- lation From Arithmetic Computation. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 14317–14344, 2025
work page 2025
-
[7]
Casper: Prompt Sanitization for Protecting User Privacy in Web-Based Large Language Models
Chun Jie Chong, Chenxi Hou, Zhihao Yao, and Seyed Mohammadjavad Seyed Talebi. Casper: Prompt Sanitization for Protecting User Privacy in Web-Based Large Language Models. In 2025 IEEE 12th International Conference on Cyber Security and Cloud Computing (CSCloud), pages 122–133. IEEE, 2025
work page 2025
-
[8]
Pr ϵϵmpt: Sanitizing Sensitive Prompts for LLMs
Amrita Roy Chowdhury, David Glukhov, Divyam Anshumaan, Prasad Chalasani, Nicolas Papernot, Somesh Jha, and Mihir Bellare. Pr ϵϵmpt: Sanitizing Sensitive Prompts for LLMs. arXiv preprint arXiv:2504.05147, 2025
-
[9]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training Verifiers to Solve Math Word Problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
jeopardy-gen2mc.https://huggingface.co/datasets/allenai/ jeopardy-gen2mc
Allen Institute for AI. jeopardy-gen2mc.https://huggingface.co/datasets/allenai/ jeopardy-gen2mc
-
[11]
Google DeepMind. Gemini 3 Flash. https://deepmind.google/models/gemini/flash/
-
[12]
Meera Hahn, Wenjun Zeng, Nithish Kannen, Rich Galt, Kartikeya Badola, Been Kim, and Zi Wang. Proactive Agents for Multi-Turn Text-to-Image Generation Under Uncertainty.arXiv preprint arXiv:2412.06771, 2024
-
[13]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring Massive Multitask Language Understanding.arXiv preprint arXiv:2009.03300, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[14]
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al. MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework. InThe twelfth international conference on learning representations, 2023
work page 2023
-
[15]
spaCy: Industrial- Strength Natural Language Processing in Python
Matthew Honnibal, Ines Montani, Sofie Van Landeghem, Adriane Boyd, et al. spaCy: Industrial- Strength Natural Language Processing in Python. 2020
work page 2020
-
[16]
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. What Disease does this Patient Have? A Large-scale Open Domain Question Answering Dataset from Medical Exams.Applied Sciences, 11(14):6421, 2021. 10
work page 2021
-
[17]
Minki Kang, Wei-Ning Chen, Dongge Han, Huseyin A Inan, Lukas Wutschitz, Yanzhi Chen, Robert Sim, and Saravan Rajmohan. ACON: Optimizing Context Compression for Long-horizon LLM Agents.arXiv preprint arXiv:2510.00615, 2025
-
[18]
CoDraw: Collaborative Drawing as a Testbed for Grounded Goal-driven Communication
Jin-Hwa Kim, Nikita Kitaev, Xinlei Chen, Marcus Rohrbach, Byoung-Tak Zhang, Yuandong Tian, Dhruv Batra, and Devi Parikh. CoDraw: Collaborative Drawing as a Testbed for Grounded Goal-driven Communication. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 6495–6513, 2019
work page 2019
-
[19]
Compressing Context to Enhance Inference Efficiency of Large Language Models
Yucheng Li, Bo Dong, Frank Guerin, and Chenghua Lin. Compressing Context to Enhance Inference Efficiency of Large Language Models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 6342–6353, 2023
work page 2023
-
[20]
Sam Lin, Wenyue Hua, Zhenting Wang, Mingyu Jin, Lizhou Fan, and Yongfeng Zhang. Emo- jiPrompt: Generative Prompt Obfuscation for Privacy-Preserving Communication with Cloud- based LLMs. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long P...
work page 2025
-
[21]
TruthfulQA: Measuring How Models Mimic Hu- man Falsehoods
Stephanie Lin, Jacob Hilton, and Owain Evans. TruthfulQA: Measuring How Models Mimic Hu- man Falsehoods. InProceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers), pages 3214–3252, 2022
work page 2022
-
[22]
Microsoft COCO: Common Objects in Context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft COCO: Common Objects in Context. In European conference on computer vision, pages 740–755. Springer, 2014
work page 2014
-
[23]
Anonymisation Models for Text Data: State of the Art, Challenges and Future Directions
Pierre Lison, Ildikó Pilán, David Sanchez, Montserrat Batet, and Lilja Øvrelid. Anonymisation Models for Text Data: State of the Art, Challenges and Future Directions. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers),...
work page 2021
-
[24]
Formalizing and Benchmarking Prompt Injection Attacks and Defenses
Yupei Liu, Yuqi Jia, Runpeng Geng, Jinyuan Jia, and Neil Zhenqiang Gong. Formalizing and Benchmarking Prompt Injection Attacks and Defenses. In33rd USENIX Security Symposium (USENIX Security 24), pages 1831–1847, 2024
work page 2024
-
[25]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts.arXiv preprint arXiv:2310.02255, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Inter-GPS: Interpretable Geometry Problem Solving with Formal Language and Symbolic Reasoning
Pan Lu, Ran Gong, Shibiao Jiang, Liang Qiu, Siyuan Huang, Xiaodan Liang, and Song-Chun Zhu. Inter-GPS: Interpretable Geometry Problem Solving with Formal Language and Symbolic Reasoning. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volu...
work page 2021
-
[27]
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-Refine: Iterative Refinement with Self-Feedback.Advances in neural information processing systems, 36:46534–46594, 2023
work page 2023
-
[28]
Evaluating Very Long-Term Conversational Memory of LLM Agents
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating Very Long-Term Conversational Memory of LLM Agents. InProceed- ings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851–13870, 2024
work page 2024
-
[29]
Peihua Mai, Ran Yan, Zhe Huang, Youjia Yang, and Yan Pang. Split-and-Denoise: Protect Large Language Model Inference with Local Differential Privacy.arXiv preprint arXiv:2310.09130, 2023
-
[30]
Omri Mendels, Coby Peled, Nava Vaisman Levy, Tomer Rosenthal, Limor Lahiani, et al. Microsoft Presidio: Context Aware, Pluggable and Customizable PII Anonymization Service for Text and Images.Microsoft, 2018. 11
work page 2018
-
[31]
GAIA: a benchmark for General AI Assistants
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. GAIA: a benchmark for General AI Assistants. InThe Twelfth International Conference on Learning Representations, 2023
work page 2023
-
[32]
Niloofar Mireshghallah, Maria Antoniak, Yash More, Yejin Choi, and Golnoosh Farnadi. Trust No Bot: Discovering Personal Disclosures in Human-LLM Conversations in the Wild.arXiv preprint arXiv:2407.11438, 2024
-
[33]
Ignore Previous Prompt: Attack Techniques For Language Models
Fábio Perez and Ian Ribeiro. Ignore Previous Prompt: Attack Techniques For Language Models. arXiv preprint arXiv:2211.09527, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[34]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language Models Can Teach Themselves to Use Tools.Advances in neural information processing systems, 36:68539–68551, 2023
work page 2023
-
[35]
Hadi Sheikhi, Chenyang Huang, and Osmar R Zaïane. Improving LLM’s Attachment to External Knowledge In Dialogue Generation Tasks Through Entity Anonymization. InProceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics, pages 472–...
work page 2025
-
[36]
Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face.Advances in Neural Information Processing Systems, 36:38154–38180, 2023
work page 2023
-
[37]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Re- flexion: Language Agents with Verbal Reinforcement Learning.Advances in neural information processing systems, 36:8634–8652, 2023
work page 2023
-
[38]
CLUTRR: A Diagnostic Benchmark for Inductive Reasoning from Text
Koustuv Sinha, Shagun Sodhani, Jin Dong, Joelle Pineau, and William L Hamilton. CLUTRR: A Diagnostic Benchmark for Inductive Reasoning from Text. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 4506–4515, 2019
work page 2019
-
[39]
PAPILLON: Privacy Preservation from Internet-based and Local Language Model Ensembles
Li Siyan, Vethavikashini Chithrra Raghuram, Omar Khattab, Julia Hirschberg, and Zhou Yu. PAPILLON: Privacy Preservation from Internet-based and Local Language Model Ensembles. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pa...
work page 2025
-
[40]
Latanya Sweeney. k-Anonymity: A Model for Protecting Privacy.International journal of uncertainty, fuzziness and knowledge-based systems, 10(05):557–570, 2002
work page 2002
-
[41]
FEVER: a large-scale dataset for Fact Extraction and VERification
James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. FEVER: a large-scale dataset for Fact Extraction and VERification. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 809–819, 2018
work page 2018
-
[42]
Tensor Trust: Interpretable prompt injection attacks from an online game,
Sam Toyer, Olivia Watkins, Ethan Adrian Mendes, Justin Svegliato, Luke Bailey, Tiffany Wang, Isaac Ong, Karim Elmaaroufi, Pieter Abbeel, Trevor Darrell, et al. Tensor Trust: Interpretable Prompt Injection Attacks from an Online Game.arXiv preprint arXiv:2311.01011, 2023
-
[43]
Locally Differentially Private Document Generation Using Zero Shot Prompting
Saiteja Utpala, Sara Hooker, and Pin-Yu Chen. Locally Differentially Private Document Generation Using Zero Shot Prompting. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 8442–8457, 2023
work page 2023
-
[44]
Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models
Lei Wang, Wanyu Xu, Yihuai Lan, Zhiqiang Hu, Yunshi Lan, Roy Ka-Wei Lee, and Ee- Peng Lim. Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models. InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers), pages 2609–2634, 2023. 12
work page 2023
-
[45]
arXiv preprint arXiv:2307.10635
Xiaoxuan Wang, Ziniu Hu, Pan Lu, Yanqiao Zhu, Jieyu Zhang, Satyen Subramaniam, Arjun R Loomba, Shichang Zhang, Yizhou Sun, and Wei Wang. SciBench: Evaluating College-Level Sci- entific Problem-Solving Abilities of Large Language Models.arXiv preprint arXiv:2307.10635, 2023
-
[46]
Crowdsourcing Multiple Choice Science Questions
Johannes Welbl, Nelson F Liu, and Matt Gardner. Crowdsourcing Multiple Choice Science Questions. InProceedings of the 3rd Workshop on Noisy User-generated Text, pages 94–106, 2017
work page 2017
-
[47]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, et al. AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation. InFirst conference on language modeling, 2024
work page 2024
-
[48]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 Technical Report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D Manning. HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. InProceedings of the 2018 conference on empirical methods in natural language processing, pages 2369–2380, 2018
work page 2018
-
[50]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. ReAct: Synergizing Reasoning and Acting in Language Models. InThe eleventh international conference on learning representations, 2022
work page 2022
-
[51]
Toward Super Agent System with Hybrid AI Routers
Yuhang Yao, Haixin Wang, Yibo Chen, Jiawen Wang, Min Chang Jordan Ren, Bosheng Ding, Salman Avestimehr, and Chaoyang He. Toward Super Agent System with Hybrid AI Routers. arXiv preprint arXiv:2504.10519, 2025
-
[52]
EcoAgent: An Efficient Device-Cloud Collaborative Multi-Agent Framework for Mobile Automation
Biao Yi, Xueyu Hu, Yurun Chen, Shengyu Zhang, Hongxia Yang, and Fan Wu. EcoAgent: An Efficient Device-Cloud Collaborative Multi-Agent Framework for Mobile Automation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 29838–29846, 2026
work page 2026
-
[53]
Local-Cloud Inference Offloading for LLMs in Multi-Modal, Multi-Task, Multi-Dialogue Settings
Liangqi Yuan, Dong-Jun Han, Shiqiang Wang, and Christopher Brinton. Local-Cloud Inference Offloading for LLMs in Multi-Modal, Multi-Task, Multi-Dialogue Settings. InProceedings of the Twenty-sixth International Symposium on Theory, Algorithmic Foundations, and Protocol Design for Mobile Networks and Mobile Computing, pages 201–210, 2025
work page 2025
-
[54]
MMMU: A Massive Multi-discipline Mul- timodal Understanding and Reasoning Benchmark for Expert AGI
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. MMMU: A Massive Multi-discipline Mul- timodal Understanding and Reasoning Benchmark for Expert AGI. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9556–9567, 2024
work page 2024
-
[55]
MasRouter: Learning to Route LLMs for Multi-Agent Systems
Yanwei Yue, Guibin Zhang, Boyang Liu, Guancheng Wan, Kun Wang, Dawei Cheng, and Yiyan Qi. MasRouter: Learning to Route LLMs for Multi-Agent Systems. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15549–15572, 2025
work page 2025
-
[56]
PRISM: Privacy-Aware Routing for Adaptive Cloud–Edge LLM Inference via Semantic Sketch Collaboration
Junfei Zhan, Haoxun Shen, Zheng Lin, and Tengjiao He. PRISM: Privacy-Aware Routing for Adaptive Cloud–Edge LLM Inference via Semantic Sketch Collaboration. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 28150–28158, 2026
work page 2026
-
[57]
InjecAgent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents
Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang. InjecAgent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents. InFindings of the Association for Computational Linguistics: ACL 2024, pages 10471–10506, 2024
work page 2024
-
[58]
Searching for Privacy Risks in LLM Agents via Simulation
Yanzhe Zhang and Diyi Yang. Searching for Privacy Risks in LLM Agents via Simulation. arXiv preprint arXiv:2508.10880, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
Yusen Zhang, Ruoxi Sun, Yanfei Chen, Tomas Pfister, Rui Zhang, and Sercan Ö Arık. Chain of Agents: Large Language Models Collaborating on Long-Context Tasks.Advances in Neural Information Processing Systems, 37:132208–132237, 2024. 13
work page 2024
-
[60]
AGIEval: A Human-Centric Benchmark for Evaluating Foundation Models
Wanjun Zhong, Ruixiang Cui, Yiduo Guo, Yaobo Liang, Shuai Lu, Yanlin Wang, Amin Saied, Weizhu Chen, and Nan Duan. AGIEval: A Human-Centric Benchmark for Evaluating Foundation Models. InFindings of the association for computational linguistics: NAACL 2024, pages 2299–2314, 2024
work page 2024
-
[61]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. WebArena: A Realistic Web Environment for Building Autonomous Agents.arXiv preprint arXiv:2307.13854, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[62]
‘ Adaptive (Template-Aware) [24] Note for the evaluator: per the
Wangchunshu Zhou, Yuchen Eleanor Jiang, Peng Cui, Tiannan Wang, Zhenxin Xiao, Yifan Hou, Ryan Cotterell, and Mrinmaya Sachan. RecurrentGPT: Interactive Generation of (Arbitrarily) Long Text.arXiv preprint arXiv:2305.13304, 2023. 14 Appendix A Further Analysis 17 A.1 Privacy Sanitization: Privacy Identification as the Bottleneck . . . . . . . . . . . . 17 ...
-
[63]
Therefore, m$\angle $W, which is 3x$^\circ $, equals 108$^\circ $. Privacy Mapping: { "YEAR_1": "360", "ANGLE_1": "108", "QUANTITY_1": "2x", "QUANTITY_2": "4x", "QUANTITY_3": "3x", "COUNT_1": "36", "QUANTITY_4": "x", "COUNT_2": "360", "COUNT_3": "108", "NUMBER_1": "360", ... [TRUNCATED] } Figure 18: PAAC reasoning trace on Geometry3K. 35 B.3.2 MathVista T...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.