Recognition: no theorem link
Core-Halo Decomposition: Decentralizing Large-Scale Fixed-Point Problems
Pith reviewed 2026-05-12 00:51 UTC · model grok-4.3
The pith
Core-halo decomposition lets agents solve large fixed-point equations without permanent structural bias from cross-block dependencies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By separating write ownership from read-only evaluation context and aligning the Core-Halo split with the block-dependence structure of the mean operator F-bar, the original fixed-point problem x-star equals F-bar of x-star can be solved faithfully in a decentralized multi-agent system; strict decomposition alters the operator and cannot recover the true fixed point, as shown by the Bellman closure condition and blockwise bias lower bound.
What carries the argument
Core-Halo decomposition, which assigns each agent a disjoint core for writing updates and an overlapping halo for reading external dependencies to preserve the original operator.
If this is right
- Strict decomposition necessarily changes the fixed-point operator for any operator with cross-block dependence, and this change is irreducible by standard convergence adjustments.
- Core-halo preserves the exact fixed point of the original operator once the split is aligned with dependence blocks.
- The approach retains full parallelism benefits of decentralization while achieving solution accuracy indistinguishable from centralized computation in tested settings.
- Bellman closure and blockwise bias bounds give a precise way to diagnose when strict decomposition will fail.
Where Pith is reading between the lines
- The same core-halo idea could map to distributed value iteration or policy evaluation in Markov decision processes if state-action dependencies can be partitioned similarly.
- In large-scale equilibrium computation such as traffic or market models, the method might allow agents to maintain local consistency without a central clearinghouse.
- A practical test would be to measure communication volume versus solution error on a real-world operator whose dependence graph is sparse but not block-diagonal.
Load-bearing premise
The block-dependence structure of the mean operator is identifiable and can be matched to a core-halo split without adding new bias or requiring full central coordination.
What would settle it
Compute the fixed point under strict block decomposition versus core-halo on a synthetic operator whose blocks have known cross-dependencies; if the strict solution differs from the centralized one by more than sampling error while core-halo matches exactly, the claim holds.
Figures


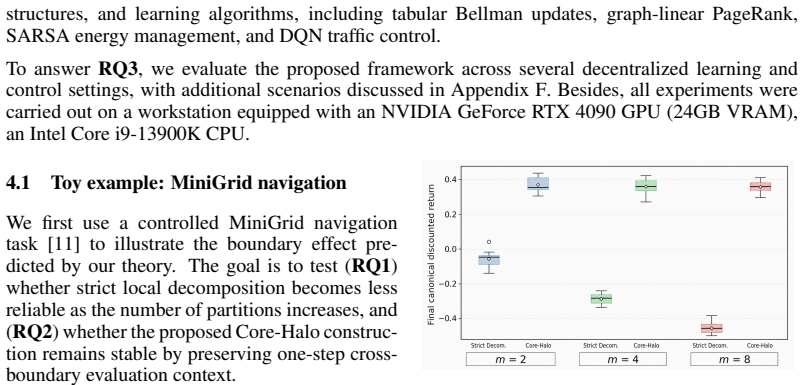

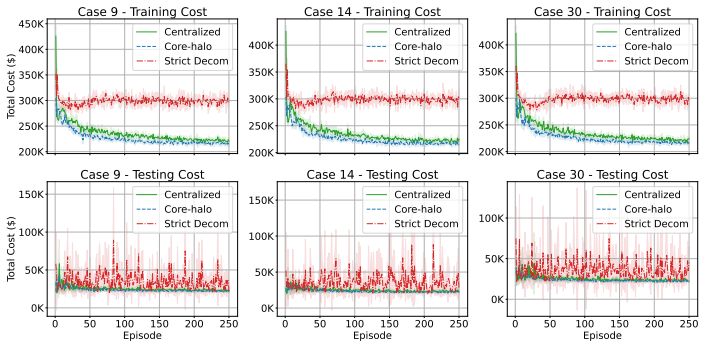



read the original abstract
We study solving large-scale fixed-point equation \(x^\star=\bar F(x^\star)\) with decomposition. Standard strict decomposition assigns each agent a disjoint block and evaluates updates using only owned coordinates. For most operators, however, a block update may depend on variables outside the block. Truncating these dependencies by strict decomposition changes the mean operator and creates structural bias that cannot be removed by more samples, smaller stepsizes, or additional consensus. We therefore propose Core-Halo decomposition, which separates write ownership from read-only evaluation context: each agent updates its own core and reads from an overlapping halo. By aligning the Core-Halo decomposition with the block-dependence structure of $\bar F$, the original fixed-point problem can be implemented faithfully in a decentralized multi-agent system. We further characterize the fundamental obstruction faced by strict decomposition through a Bellman closure condition and a blockwise bias lower bound, showing that local-only updates can alter the original fixed-point operator. Finally, we conduct extensive experiments across a range of application settings, and demonstrate that Core-Halo achieves near-centralized performance while retaining the parallelism benefits of decentralization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies decentralized solution of large-scale fixed-point equations x* = F-bar(x*) via Core-Halo decomposition, in which agents own and update disjoint core blocks while reading from overlapping halo regions. It shows that strict block decomposition generally alters the mean operator through a Bellman closure condition and induces an irreducible blockwise bias lower bound, whereas Core-Halo decomposition recovers the original fixed point when the split is aligned with the dependence blocks of F-bar. Experiments across several application domains report performance close to centralized baselines while preserving parallelism.
Significance. If the alignment step can be realized without central coordination or additional bias, the approach would enable faithful decentralized fixed-point computation at scale, with direct relevance to distributed optimization, multi-agent reinforcement learning, and large-scale equilibrium finding. The explicit bias characterization for strict decomposition is a useful theoretical contribution; the empirical results, if they hold under realistic alignment conditions, would strengthen the case for Core-Halo over existing decentralized schemes.
major comments (2)
- [§3] §3 (Bellman closure and bias lower bound): the central claim that Core-Halo recovers the original operator rests on exact alignment between the Core-Halo partition and the (unknown) block-dependence structure of F-bar. No procedure is given for agents to discover or agree on these blocks from local halo reads alone; any global identification step would either reintroduce central coordination or risk incomplete halos that re-create the bias the method seeks to avoid.
- [§5] §5 (experiments): the reported near-centralized performance is obtained under best-case alignment with the true dependence blocks. It is unclear whether the same performance is achieved when the partition must be inferred locally or when the alignment is imperfect; without such controls, the experiments do not yet demonstrate robustness of the decentralized case.
minor comments (2)
- Notation for the mean operator F-bar and the blockwise bias bound should be introduced with an explicit equation reference in the main text rather than only in the appendix.
- Figure captions for the experimental plots should state the precise alignment assumption used in each run (oracle vs. locally estimated blocks).
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our work. Below we provide point-by-point responses to the major comments, clarifying the scope of our contributions and indicating planned revisions to the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Bellman closure and bias lower bound): the central claim that Core-Halo recovers the original operator rests on exact alignment between the Core-Halo partition and the (unknown) block-dependence structure of F-bar. No procedure is given for agents to discover or agree on these blocks from local halo reads alone; any global identification step would either reintroduce central coordination or risk incomplete halos that re-create the bias the method seeks to avoid.
Authors: We thank the referee for this observation. Indeed, the theoretical guarantee that Core-Halo recovers the original fixed point relies on the Core-Halo partition being aligned with the dependence blocks of the operator. The manuscript does not include a procedure for discovering these blocks in a decentralized way from local reads, because our contribution centers on the decomposition technique and the bias analysis rather than the alignment discovery problem. In applications where the operator structure is known a priori (such as in the experimental domains considered), alignment can be set by design. We will update the manuscript to more prominently highlight this requirement and its implications for applicability. revision: partial
-
Referee: [§5] §5 (experiments): the reported near-centralized performance is obtained under best-case alignment with the true dependence blocks. It is unclear whether the same performance is achieved when the partition must be inferred locally or when the alignment is imperfect; without such controls, the experiments do not yet demonstrate robustness of the decentralized case.
Authors: The experiments in Section 5 assume perfect alignment to isolate the benefits of Core-Halo over strict decomposition and to show proximity to centralized performance. We agree that additional controls for imperfect alignment would strengthen the empirical claims. In the revised manuscript, we will include a discussion of potential performance degradation under misalignment, drawing from the bias lower bound in §3, and if feasible, add a small experiment illustrating sensitivity. revision: partial
- Decentralized discovery of the operator's block-dependence structure without central coordination or risk of incomplete halos.
Circularity Check
No significant circularity; derivation self-contained via operator properties
full rationale
The paper derives the Bellman closure condition and blockwise bias lower bound directly from properties of the mean operator F-bar under strict decomposition, without reducing to fitted parameters or self-referential definitions. Core-Halo is introduced as a structural alternative that preserves the original fixed-point equation precisely when the split aligns with the (externally given) block-dependence structure of F-bar; this alignment is an explicit modeling assumption rather than a derived or fitted quantity. No equations in the provided text equate the final result to its inputs by construction, no self-citations are invoked as load-bearing uniqueness theorems, and no ansatz is smuggled via prior work. The claim therefore stands as an independent characterization plus a proposed decomposition, not a renaming or tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The mean operator F-bar possesses an identifiable block-dependence structure that can be aligned with Core-Halo partitions.
Reference graph
Works this paper leans on
-
[1]
Zico Kolter, and Vladlen Koltun
Shaojie Bai, J. Zico Kolter, and Vladlen Koltun. Deep equilibrium models. InAdvances in Neural Information Processing Systems 32, pages 688–699, 2019
work page 2019
-
[2]
Princeton University Press, 1957
Richard Bellman.Dynamic Programming. Princeton University Press, 1957
work page 1957
- [3]
-
[4]
Dimitri P. Bertsekas and John N. Tsitsiklis.Parallel and Distributed Computation: Numerical Methods. Prentice-Hall, 1989
work page 1989
-
[5]
Finite time analysis of temporal differ- ence learning with linear function approximation
Jalaj Bhandari, Daniel Russo, and Raghav Singal. Finite time analysis of temporal differ- ence learning with linear function approximation. In S ´ebastien Bubeck, Vianney Perchet, and Philippe Rigollet, editors,Proceedings of the 31st Conference On Learning Theory, volume 75 ofProceedings of Machine Learning Research, pages 1691–1692. PMLR, 06–09 Jul 2018
work page 2018
-
[6]
Borkar.Stochastic Approximation: A Dynamical Systems Viewpoint
Vivek S. Borkar.Stochastic Approximation: A Dynamical Systems Viewpoint. Hindustan Book Agency and Cambridge University Press, 2008
work page 2008
-
[7]
Gossip algorithms: De- sign, analysis and applications
Stephen Boyd, Arpita Ghosh, Balaji Prabhakar, and Devavrat Shah. Gossip algorithms: De- sign, analysis and applications. InProceedings IEEE 24th Annual Joint Conference of the IEEE Computer and Communications Societies., volume 3, pages 1653–1664. IEEE, 2005
work page 2005
-
[8]
Randomized gossip algo- rithms.IEEE Transactions on Information Theory, 52(6):2508–2530, 2006
Stephen Boyd, Arpita Ghosh, Balaji Prabhakar, and Devavrat Shah. Randomized gossip algo- rithms.IEEE Transactions on Information Theory, 52(6):2508–2530, 2006
work page 2006
-
[9]
Stephen Boyd, Neal Parikh, Eric Chu, Borja Peleato, and Jonathan Eckstein. Distributed op- timization and statistical learning via the alternating direction method of multipliers.Founda- tions and Trends in Machine Learning, 3(1):1–122, 2011
work page 2011
-
[10]
Matthew Weinberg, Tom Griffiths, and Sergey Levine
Michael Chang, Sid Kaushik, S. Matthew Weinberg, Tom Griffiths, and Sergey Levine. De- centralized reinforcement learning: Global decision-making via local economic transactions. InProceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 1437–1447. PMLR, 2020. 10
work page 2020
-
[11]
Maxime Chevalier-Boisvert, Bolun Dai, Mark Towers, Rodrigo Perez-Vicente, Lucas Willems, Salem Lahlou, Suman Pal, Pablo Samuel Castro, and J. K. Terry. MiniGrid & MiniWorld: Modular & customizable reinforcement learning environments for goal-oriented tasks.Ad- vances in Neural Information Processing Systems, 36:73383–73394, 2023
work page 2023
-
[12]
Christofides, Riccardo Scattolini, David Mu˜noz de la Pe˜na, and Jinfeng Liu
Panagiotis D. Christofides, Riccardo Scattolini, David Mu˜noz de la Pe˜na, and Jinfeng Liu. Dis- tributed model predictive control: A tutorial review and future research directions.Computers & Chemical Engineering, 51:21–41, 2013
work page 2013
-
[13]
Doan, Siva Theja Maguluri, and Justin Romberg
Thinh T. Doan, Siva Theja Maguluri, and Justin Romberg. Finite-time analysis of distributed td(0) with linear function approximation for multi-agent reinforcement learning. InProceed- ings of the 36th International Conference on Machine Learning, pages 1626–1635, 2019
work page 2019
-
[14]
Laurent El Ghaoui, Fangda Gu, Bertrand Travacca, Armin Askari, and Alicia Y . Tsai. Implicit deep learning.SIAM Journal on Mathematics of Data Science, 3(3):930–958, 2021
work page 2021
-
[15]
Foerster, Gregory Farquhar, Triantafyllos Afouras, Nantas Nardelli, and Shimon Whiteson
Jakob N. Foerster, Gregory Farquhar, Triantafyllos Afouras, Nantas Nardelli, and Shimon Whiteson. Counterfactual multi-agent policy gradients. InProceedings of the AAAI Con- ference on Artificial Intelligence, volume 32, 2018
work page 2018
-
[16]
Samy Wu Fung, Howard Heaton, Qiuwei Li, Daniel McKenzie, Stanley J. Osher, and Wotao Yin. Jfb: Jacobian-free backpropagation for implicit networks. InProceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 6648–6656, 2022
work page 2022
-
[17]
David F. Gleich. Pagerank beyond the web.SIAM Review, 57(3):321–363, 2015
work page 2015
-
[18]
Hideaki Ishii and Roberto Tempo. Distributed randomized algorithms for the pagerank com- putation.IEEE Transactions on Automatic Control, 55(9):1987–2002, 2010
work page 1987
-
[19]
Tommi Jaakkola, Michael I. Jordan, and Satinder P. Singh. On the convergence of stochastic iterative dynamic programming algorithms.Neural Computation, 6(6):1185–1201, 1994
work page 1994
-
[20]
Soummya Kar, Jos ´e M. F. Moura, and H. Vincent Poor.QD-learning: A collaborative distributed strategy for multi-agent reinforcement learning through consensus + innovations. IEEE Transactions on Signal Processing, 61(7):1848–1862, 2013
work page 2013
-
[21]
Harold J. Kushner and G. George Yin. Asymptotic properties of distributed and communicating stochastic approximation algorithms.SIAM Journal on Control and Optimization, 25(5):1266– 1290, 1987
work page 1987
-
[22]
Harold J. Kushner and G. George Yin.Stochastic Approximation and Recursive Algorithms and Applications. Springer, 2003
work page 2003
-
[23]
On the schwarz alternating method
Pierre-Louis Lions. On the schwarz alternating method. i. InFirst International Symposium on Domain Decomposition Methods for Partial Differential Equations, pages 1–42. SIAM, 1988
work page 1988
-
[24]
Multi-agent actor-critic for mixed cooperative-competitive environments
Ryan Lowe, Yi Wu, Aviv Tamar, Jean Harb, Pieter Abbeel, and Igor Mordatch. Multi-agent actor-critic for mixed cooperative-competitive environments. InAdvances in Neural Informa- tion Processing Systems 30, pages 6379–6390, 2017
work page 2017
-
[25]
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin Riedmiller, Andreas K. Fidjeland, Georg Ostrovski, Stig Pe- tersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg, and Demis Hassabis. Human-level control through deep rein- forcem...
work page 2015
-
[26]
Angelia Nedi’c and Asuman Ozdaglar. Distributed subgradient methods for multi-agent opti- mization.IEEE Transactions on Automatic Control, 54(1):48–61, 2009
work page 2009
-
[27]
Brendan O’Donoghue, Giorgos Stathopoulos, and Stephen Boyd. A splitting method for opti- mal control.IEEE Transactions on Control Systems Technology, 21(6):2432–2442, 2013
work page 2013
-
[28]
The PageRank citation ranking: Bringing order to the web
Lawrence Page, Sergey Brin, Rajeev Motwani, and Terry Winograd. The PageRank citation ranking: Bringing order to the web. Technical report, Stanford Digital Library Technologies Project, 1998. 11
work page 1998
-
[29]
Alfio Quarteroni and Alberto Valli.Domain Decomposition Methods for Partial Differential Equations. Oxford University Press, 1999
work page 1999
-
[30]
QMIX: Monotonic value function factorisation for deep multi-agent reinforcement learning
Tabish Rashid, Mikayel Samvelyan, Christian Schroeder, Gregory Farquhar, Jakob Foerster, and Shimon Whiteson. QMIX: Monotonic value function factorisation for deep multi-agent reinforcement learning. In Jennifer Dy and Andreas Krause, editors,Proceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learn- in...
work page 2018
-
[31]
James B. Rawlings, David Q. Mayne, and Moritz M. Diehl.Model Predictive Control: Theory, Computation, and Design. Nob Hill Publishing, 2017
work page 2017
-
[32]
A stochastic approximation method.The Annals of Math- ematical Statistics, 22(3):400–407, 1951
Herbert Robbins and Sutton Monro. A stochastic approximation method.The Annals of Math- ematical Statistics, 22(3):400–407, 1951
work page 1951
-
[33]
Gavin A. Rummery and Mahesan Niranjan. On-line q-learning using connectionist systems. Technical Report CUED/F-INFENG/TR 166, University of Cambridge, Department of Engi- neering, 1994
work page 1994
-
[34]
Riccardo Scattolini. Architectures for distributed and hierarchical model predictive control–a review.Journal of Process Control, 19(5):723–731, 2009
work page 2009
-
[35]
Gianluca Serale, Massimo Fiorentini, Alfonso Capozzoli, Daniele Bernardini, and Alberto Bemporad. Model predictive control (mpc) for enhancing building and hvac system energy efficiency: Problem formulation, applications and opportunities.Energies, 11(3):631, 2018
work page 2018
-
[36]
Barry F. Smith, Petter E. Bjørstad, and William D. Gropp.Domain Decomposition: Parallel Multilevel Methods for Elliptic Partial Differential Equations. Cambridge University Press, 1996
work page 1996
-
[37]
Finite-time error bounds for linear stochastic approxi- mation and td learning
Rayadurgam Srikant and Lei Ying. Finite-time error bounds for linear stochastic approxi- mation and td learning. In Alina Beygelzimer and Daniel Hsu, editors,Proceedings of the Thirty-Second Conference on Learning Theory, volume 99 ofProceedings of Machine Learn- ing Research, pages 2803–2830. PMLR, 25–28 Jun 2019
work page 2019
-
[38]
Stankovi ´c, Nemanja Ili ´c, and Srdjan S
Milo ˇs S. Stankovi ´c, Nemanja Ili ´c, and Srdjan S. Stankovi ´c. Distributed stochastic approxi- mation: Weak convergence and network design.IEEE Transactions on Automatic Control, 61(12):4069–4074, 2016
work page 2016
-
[39]
Srdjan S. Stankovi ´c, Miloˇs S. Stankovi´c, and Duˇsan M. Stipanovi´c. Decentralized parameter estimation by consensus based stochastic approximation.IEEE Transactions on Automatic Control, 56(3):531–543, 2011
work page 2011
-
[40]
Bartolomeo Stellato, Goran Banjac, Paul Goulart, Alberto Bemporad, and Stephen Boyd. Osqp: An operator splitting solver for quadratic programs.Mathematical Programming Com- putation, 12:637–672, 2020
work page 2020
-
[41]
Haixiang Sun and Ye Shi. Understanding representation of deep equilibrium models from neural collapse perspective.Advances in Neural Information Processing Systems, 37:9634– 9667, 2024
work page 2024
-
[42]
Giannakis, Qinmin Yang, and Zaiyue Yang
Jun Sun, Gang Wang, Georgios B. Giannakis, Qinmin Yang, and Zaiyue Yang. Finite-time analysis of decentralized temporal-difference learning with linear function approximation. In Silvia Chiappa and Roberto Calandra, editors,Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics, volume 108 ofProceedings of Machi...
work page 2020
-
[43]
Leibo, Karl Tuyls, and Thore Graepel
Peter Sunehag, Guy Lever, Audrunas Gruslys, Wojciech Marian Czarnecki, Vinicius Zambaldi, Max Jaderberg, Marc Lanctot, Nicolas Sonnerat, Joel Z. Leibo, Karl Tuyls, and Thore Graepel. Value-decomposition networks for cooperative multi-agent learning based on team reward. InProceedings of the 17th International Conference on Autonomous Agents and MultiAgent...
work page 2085
-
[44]
Richard S. Sutton. Learning to predict by the methods of temporal differences.Machine Learning, 3(1):9–44, 1988
work page 1988
-
[45]
Multi-agent reinforcement learning: independent versus cooperative agents
Ming Tan. Multi-agent reinforcement learning: independent versus cooperative agents. In Proceedings of the Tenth International Conference on International Conference on Machine Learning, ICML’93, pages 330–337, San Francisco, CA, USA, 1993. Morgan Kaufmann Pub- lishers Inc
work page 1993
-
[46]
J Terry, Benjamin Black, Nathaniel Grammel, Mario Jayakumar, Ananth Hari, Ryan Sullivan, Luis S Santos, Clemens Dieffendahl, Caroline Horsch, Rodrigo Perez-Vicente, et al. Petting- zoo: Gym for multi-agent reinforcement learning.Advances in Neural Information Processing Systems, 34:15032–15043, 2021
work page 2021
-
[47]
Widlund.Domain Decomposition Methods: Algorithms and The- ory
Andrea Toselli and Olof B. Widlund.Domain Decomposition Methods: Algorithms and The- ory. Springer, 2005
work page 2005
-
[48]
John N. Tsitsiklis. Asynchronous stochastic approximation and q-learning.Machine Learning, 16(3):185–202, 1994
work page 1994
-
[49]
A theoretical and empirical analysis of expected SARSA
Harm van Seijen, Hado van Hasselt, Shimon Whiteson, and Marco Wiering. A theoretical and empirical analysis of expected SARSA. InProceedings of the IEEE Symposium on Adaptive Dynamic Programming and Reinforcement Learning, pages 177–184. IEEE, 2009
work page 2009
-
[50]
Giannakis, Gerald Tesauro, and Jian Sun
Gang Wang, Songtao Lu, Georgios B. Giannakis, Gerald Tesauro, and Jian Sun. Decentralized TD tracking with linear function approximation and its finite-time analysis. InAdvances in Neural Information Processing Systems, volume 33, 2020
work page 2020
-
[51]
Christopher J. C. H. Watkins and Peter Dayan. Q-learning.Machine Learning, 8(3–4):279– 292, 1992
work page 1992
-
[52]
Hua Wei, Chacha Chen, Guanjie Zheng, Kan Wu, Vikash V . Gayah, Kai Xu, and Zhenhui Li. Presslight: Learning max pressure control to coordinate traffic signals in arterial network. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 1290–1298. ACM, 2019
work page 2019
-
[53]
Colight: Learning network-level cooperation for traffic signal control
Hua Wei, Nan Xu, Huichu Zhang, Guanjie Zheng, Xinshi Zang, Chacha Chen, Weinan Zhang, Yanmin Zhu, Kai Xu, and Zhenhui Li. Colight: Learning network-level cooperation for traffic signal control. InProceedings of the 28th ACM International Conference on Information and Knowledge Management, pages 1913–1922. ACM, 2019
work page 1913
-
[54]
Ezra Winston and J. Zico Kolter. Monotone operator equilibrium networks. InAdvances in Neural Information Processing Systems 33, 2020
work page 2020
-
[55]
Fast linear iterations for distributed averaging.Systems & Control Letters, 53(1):65–78, 2004
Lin Xiao and Stephen Boyd. Fast linear iterations for distributed averaging.Systems & Control Letters, 53(1):65–78, 2004
work page 2004
-
[56]
Sihan Zeng, Thinh T. Doan, and Justin Romberg. Finite-time convergence rates of decentral- ized stochastic approximation with applications in multi-agent and multi-task learning.IEEE Transactions on Automatic Control, 68(5):2758–2773, 2023
work page 2023
-
[57]
Kaiqing Zhang, Zhuoran Yang, and Tamer Bas ¸ar. Decentralized multi-agent reinforcement learning with networked agents: Recent advances.Frontiers of Information Technology & Electronic Engineering, 22(6):802–814, 2021
work page 2021
-
[58]
Fully decentralized multi-agent reinforcement learning with networked agents
Kaiqing Zhang, Zhuoran Yang, Han Liu, Tong Zhang, and Tamer Bas ¸ar. Fully decentralized multi-agent reinforcement learning with networked agents. InProceedings of the 35th Inter- national Conference on Machine Learning, pages 5872–5881, 2018. 13 A Related Works Stochastic approximation, Bellman fixed points, and implicit fixed-point models.The fixed- poi...
work page 2018
-
[59]
and the stochastic-approximation interpretation of TD and value iteration give the template for Bellman fixed-point algorithms; Watkins and Dayan [51] introduced Q-learning, and Tsitsiklis [48] together with Jaakkola, Jordan, and Singh [19] established convergence for asynchronous stochastic approximation and iterative dynamic programming. The same mean-o...
-
[60]
sparse linear fixed-point solvers + DEQ- type implicit layers
analyzed fully decentralized learning with networked agents, [13] and [42] gave finite-time analyses for distributed TD, [50] developed decentralized TD tracking, [56] established finite-time theory for decentralized SA with fixed points. [57] surveys the broader area. The second line is the multi-agent RL benchmarks and baselines used in our experiments:...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.