Recognition: no theorem link
AgentPSO: Evolving Agent Reasoning Skill via Multi-agent Particle Swarm Optimization
Pith reviewed 2026-05-12 00:51 UTC · model grok-4.3
The pith
AgentPSO evolves multi-agent reasoning skills by treating each agent's natural-language description as a particle state that updates toward better performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AgentPSO models agents as particles whose states are natural-language skill descriptions. In each iteration, an agent revises its skill by blending its prior velocity, personal-best skill, global-best skill, and a self-reflective direction derived from peer reasoning trajectories. The process improves reasoning performance across the population without updating any parameters of the underlying language model and produces skills that generalize beyond the training tasks.
What carries the argument
The semantic velocity update that fuses an agent's previous direction, personal-best skill, global-best skill, and self-reflection from collective trajectories to refine natural-language reasoning skills.
If this is right
- Agents achieve higher accuracy on mathematical and general reasoning benchmarks than static single-agent skills or test-time-only multi-agent methods.
- Skills learned during evolution transfer successfully to different benchmarks.
- The same evolved skills retain their benefits when deployed on a different backbone language model.
- Reasoning gains arise from population-level discovery of reusable procedures without access to model gradients or internals.
Where Pith is reading between the lines
- The approach could be applied to evolve skills for non-reasoning tasks such as collaborative code generation or multi-step planning.
- Focusing on skill evolution rather than inference-time aggregation may reduce problems like biased consensus in debate systems.
- Evolved skills could be archived as a reusable library for deployment across multiple models and problem domains.
- Because updates require only text outputs, the method works with black-box API models that provide no internal access.
Load-bearing premise
Combining previous directions with personal and global best skills through natural-language updates produces genuine reasoning gains rather than superficial changes in prompt wording.
What would settle it
If the evolved skills show no accuracy gain on held-out benchmarks compared with random semantic perturbations or fail to transfer when applied to new tasks or models, the claim of reusable reasoning procedures would be falsified.
Figures


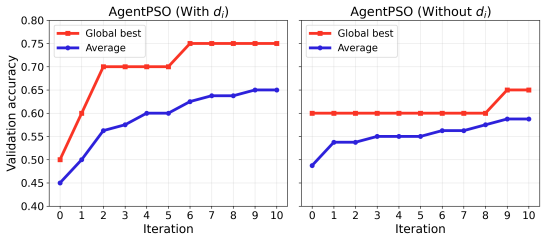






read the original abstract
Multi-agent reasoning has shown promise for improving the problem-solving ability of large language models by allowing multiple agents to explore diverse reasoning paths. However, most existing multi-agent methods rely on inference-time debate or aggregation, which can be vulnerable to incorrect peer influence and biased consensus. Moreover, the agents themselves remain static, as their underlying reasoning skills do not evolve across tasks. In this paper, we introduce AgentPSO, a particle-swarm-inspired framework for evolving multi-agent reasoning skills. AgentPSO treats each agent as a particle-like reasoner whose state is a natural-language skill and whose velocity is a semantic update direction, iteratively moving agents toward stronger skill states to improve both individual and collective reasoning performance. Across training iterations, each agent updates its skill by combining its previous velocity, personal-best skill, global-best skill, and a self-reflective direction derived from peer reasoning trajectories. This enables agents to learn reusable reasoning behaviors from both their own experiences and the strongest skills discovered by the population, without updating the parameters of the backbone language model. Experiments on mathematical and general reasoning benchmarks show that AgentPSO improves over static single-agent skills and test-time-only multi-agent reasoning baselines. The evolved skills further transfer across benchmarks and to another backbone model, suggesting that AgentPSO captures reusable reasoning procedures rather than merely optimizing benchmark-specific prompts. Code is open-sourced at https://github.com/HYUNMIN-HWANG/AgentPSO/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AgentPSO, a multi-agent framework that adapts particle swarm optimization to evolve natural-language reasoning skills for LLMs. Each agent is treated as a particle whose position is a skill description and velocity is a semantic update direction; updates combine prior velocity, personal-best skill, global-best skill, and self-reflective direction derived from peer trajectories. The method runs without gradient updates to the backbone model. Experiments on mathematical and general reasoning benchmarks report gains over static single-agent and test-time multi-agent baselines, with claimed transfer of evolved skills across benchmarks and to a different backbone model.
Significance. If the empirical claims hold under rigorous controls, the work would be significant for demonstrating a gradient-free mechanism to discover reusable, transferable reasoning procedures in multi-agent LLM systems. It directly addresses the static-agent limitation of prior multi-agent reasoning methods and provides an open-source implementation, which supports reproducibility.
major comments (3)
- [Experiments] Experiments section: the reported improvements over baselines lack any mention of the number of independent runs, variance across seeds, or statistical significance tests. Without these, it is impossible to determine whether the gains exceed what would be expected from additional inference budget or random prompt variation.
- [Method and Experiments] Method and Experiments: no component ablations are presented for the four-term update rule (inertia, cognitive/personal-best, social/global-best, self-reflective). This is load-bearing for the central claim that the PSO-style combination produces genuine skill evolution rather than iterative prompt refinement.
- [Experiments] Experiments: the paper provides no examples or qualitative analysis of the evolved skill strings before and after optimization. Without inspection of the actual natural-language content, it remains possible that transfer results reflect accumulation of benchmark-specific fragments rather than reusable procedures.
minor comments (2)
- [Abstract and Introduction] The abstract and introduction use the term 'parameter-free' for the evolution process, yet the update rule includes tunable PSO-style coefficients (inertia, cognitive, social weights) whose values are not specified or ablated.
- [Method] Figure captions and algorithm pseudocode would benefit from explicit notation for how natural-language concatenation is performed during velocity and position updates.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments, which help strengthen the empirical rigor and clarity of our work on AgentPSO. We address each major point below and commit to revisions that directly incorporate the suggested improvements.
read point-by-point responses
-
Referee: Experiments section: the reported improvements over baselines lack any mention of the number of independent runs, variance across seeds, or statistical significance tests. Without these, it is impossible to determine whether the gains exceed what would be expected from additional inference budget or random prompt variation.
Authors: We agree that reporting variance and statistical tests is necessary to rule out effects from random prompt variation or extra inference budget. In the revised manuscript, we will rerun all main experiments across 5 independent runs with distinct random seeds, report mean accuracies with standard deviations, and include paired t-tests (with p-values) comparing AgentPSO against each baseline to establish statistical significance. revision: yes
-
Referee: Method and Experiments: no component ablations are presented for the four-term update rule (inertia, cognitive/personal-best, social/global-best, self-reflective). This is load-bearing for the central claim that the PSO-style combination produces genuine skill evolution rather than iterative prompt refinement.
Authors: We acknowledge that ablations are required to isolate the contribution of the PSO-style four-term rule versus simpler iterative refinement. The revised version will add a dedicated ablation study that evaluates variants with individual terms removed or replaced (e.g., no inertia, no self-reflective component) on the primary math and general reasoning benchmarks, demonstrating that the full combination yields superior skill evolution. revision: yes
-
Referee: Experiments: the paper provides no examples or qualitative analysis of the evolved skill strings before and after optimization. Without inspection of the actual natural-language content, it remains possible that transfer results reflect accumulation of benchmark-specific fragments rather than reusable procedures.
Authors: We agree that qualitative inspection is important to substantiate claims of reusable procedures. The revision will include concrete examples of initial versus evolved skill strings for representative agents, accompanied by a qualitative analysis section that highlights recurring reasoning patterns (e.g., decomposition strategies) that persist across benchmarks and support the transfer results. revision: yes
Circularity Check
No significant circularity in claimed results
full rationale
The paper introduces an empirical PSO-inspired framework for updating natural-language agent skills via LLM calls, with central claims resting on benchmark experiments showing performance gains and cross-benchmark/model transfer. No equations, derivations, or first-principles results are presented that reduce outputs to inputs by construction, fitted parameters renamed as predictions, or load-bearing self-citations. The method is self-contained as an experimental procedure evaluated against external baselines, with no self-definitional loops or ansatz smuggling identified in the provided text.
Axiom & Free-Parameter Ledger
free parameters (1)
- PSO-style coefficients for inertia, cognitive, and social components
axioms (1)
- domain assumption Semantic combinations of natural-language skill descriptions can serve as effective velocity and position updates that improve reasoning performance.
invented entities (2)
-
Agent skill state as particle position
no independent evidence
-
Semantic update direction as particle velocity
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
GEPA: Reflective prompt evolution can outperform reinforcement learning
Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arnav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, Christopher Potts, Koushik Sen, Alex Dimakis, Ion Stoica, Dan Klein, Matei Zaharia, and Omar Khattab. GEPA: Reflective prompt evolution can outperform reinforcement learning. InThe Fourteenth International...
work page 2026
-
[3]
Self-evolving multi-agent simulations for realistic clinical interactions
Mohammad Almansoori, Komal Kumar, and Hisham Cholakkal. Self-evolving multi-agent simulations for realistic clinical interactions. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, 2025
work page 2025
-
[4]
A survey of self-evolving agents: On path to artificial super intelligence, 2025
Huan ang Gao, Jiayi Geng, Wenyue Hua, Mengkang Hu, Xinzhe Juan, Hongzhang Liu, Shilong Liu, Jiahao Qiu, Xuan Qi, Yiran Wu, Hongru Wang, Han Xiao, Yuhang Zhou, Shaokun Zhang, Jiayi Zhang, Jinyu Xiang, Yixiong Fang, Qiwen Zhao, Dongrui Liu, Qihan Ren, Cheng Qian, Zhenghailong Wang, Minda Hu, Huazheng Wang, Qingyun Wu, Heng Ji, and Mengdi Wang. A survey of s...
work page 2025
-
[5]
Anthropic. Models overview. https://platform.claude.com/docs/en/about-claude/ models/overview, 2026. Accessed: 2026-05-06
work page 2026
-
[6]
Ismail Hossain, Fuad Rahman, Moham- mad Ruhul Amin, Shafin Rahman, and Nabeel Mohammed
Nafew Azim, Abrar Ur Alam, Hasan Bin Omar, Abdullah Mohammad Muntasir Adnan Jami, Jawad Ibn Ahad, Muhammad Rafsan Kabir, Md. Ismail Hossain, Fuad Rahman, Moham- mad Ruhul Amin, Shafin Rahman, and Nabeel Mohammed. AutoDSPy: Automating modular prompt design with reinforcement learning for small and large language models. In Saloni Pot- dar, Lina Rojas-Barah...
work page 2025
-
[7]
Benchmarking large language models on answering and explaining challenging medical questions, 2024
Hanjie Chen, Zhouxiang Fang, Yash Singla, and Mark Dredze. Benchmarking large language models on answering and explaining challenging medical questions, 2024
work page 2024
-
[8]
Free-MAD: Consensus-free multi-agent debate, 2026
Yu Cui, Hang Fu, Haibin Zhang, Licheng Wang, and Cong Zuo. Free-MAD: Consensus-free multi-agent debate, 2026
work page 2026
-
[9]
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025
work page 2025
-
[10]
Improving Factuality and Reasoning in Language Models through Multiagent Debate
Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, and Igor Mordatch. Improv- ing factuality and reasoning in language models through multiagent debate.arXiv preprint arXiv:2305.14325, 2023
work page internal anchor Pith review arXiv 2023
-
[11]
M-MAD: Multidimensional multi-agent debate for advanced machine transla- tion evaluation
Zhaopeng Feng, Jiayuan Su, Jiamei Zheng, Jiahan Ren, Yan Zhang, Jian Wu, Hongwei Wang, and Zuozhu Liu. M-MAD: Multidimensional multi-agent debate for advanced machine transla- tion evaluation. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational ...
work page 2025
-
[12]
Promptbreeder: Self-referential self-improvement via prompt evolution, 2024
Chrisantha Fernando, Dylan Sunil Banarse, Henryk Michalewski, Simon Osindero, and Tim Rocktäschel. Promptbreeder: Self-referential self-improvement via prompt evolution, 2024
work page 2024
-
[13]
Lopes, and Fernando Morgado-Dias
Daniel Freitas, Luis G. Lopes, and Fernando Morgado-Dias. Particle swarm optimisation: A historical review up to the current developments.Entropy, 22(3):362, 2020
work page 2020
-
[14]
CATArena: Evaluation of LLM agents through iterative tournament competitions, 2026
Lingyue Fu, Xin Ding, Yaoming Zhu, Shao Zhang, Lin Qiu, Weiwen Liu, Weinan Zhang, Xuezhi Cao, Xunliang Cai, Jiaxin Ding, and Yong Yu. CATArena: Evaluation of LLM agents through iterative tournament competitions, 2026. 11
work page 2026
-
[15]
Ahmed G. Gad. Particle swarm optimization algorithm and its applications: A systematic review.Archives of Computational Methods in Engineering, 29:2531–2561, 2022
work page 2022
-
[16]
Zhiwei He, Tian Liang, Jiahao Xu, Qiuzhi Liu, Xingyu Chen, Yue Wang, Linfeng Song, Dian Yu, Zhenwen Liang, Wenxuan Wang, Zhuosheng Zhang, Rui Wang, Zhaopeng Tu, Haitao Mi, and Dong Yu. Deepmath-103k: A large-scale, challenging, decontaminated, and verifiable mathematical dataset for advancing reasoning. 2025
work page 2025
-
[17]
Automated Design of Agentic Systems
Shengran Hu, Cong Lu, and Jeff Clune. Automated design of agentic systems.arXiv preprint arXiv:2408.08435, 2024
work page internal anchor Pith review arXiv 2024
-
[18]
Large Language Models Cannot Self-Correct Reasoning Yet
Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. Large language models cannot self-correct reasoning yet.arXiv preprint arXiv:2310.01798, 2023
work page internal anchor Pith review arXiv 2023
-
[19]
V oting or consensus? decision-making in multi-agent debate
Lars Benedikt Kaesberg, Jonas Becker, Jan Philip Wahle, Terry Ruas, and Bela Gipp. V oting or consensus? decision-making in multi-agent debate. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Findings of the Association for Computational Linguistics: ACL 2025, pages 11640–11671, Vienna, Austria, July 2025. Associati...
work page 2025
-
[20]
J. Kennedy and R. Eberhart. Particle swarm optimization. InProceedings of ICNN’95 - International Conference on Neural Networks, volume 4, pages 1942–1948 vol.4, 1995
work page 1942
-
[21]
Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts
Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan A, Saiful Haq, Ashutosh Sharma, Thomas T. Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts. DSPy: Compiling declarative language model calls into state-of-the-art pipelines. InThe Twelfth International Conference on Learning Represent...
work page 2024
-
[22]
Decomposed prompting: A modular approach for solving complex tasks
Tushar Khot, Harsh Trivedi, Matthew Finlayson, Yao Fu, Kyle Richardson, Peter Clark, and Ashish Sabharwal. Decomposed prompting: A modular approach for solving complex tasks. In International Conference on Learning Representations (ICLR), 2023
work page 2023
-
[23]
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, et al. Solving quan- titative reasoning problems with language models.Advances in neural information processing systems, 35:3843–3857, 2022
work page 2022
-
[24]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step.arXiv preprint arXiv:2305.20050, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Enhancing multi-agent debate system performance via confidence expression
Zijie Lin and Bryan Hooi. Enhancing multi-agent debate system performance via confidence expression. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Findings of the Association for Computational Linguistics: EMNLP 2025, pages 6453–6471, Suzhou, China, November 2025. Association for Computational Linguistics
work page 2025
-
[26]
MeMAD: Structured memory of debates for enhanced multi-agent reasoning
Shuai Ling, Lizi Liao, Dongmei Jiang, and Weili Guan. MeMAD: Structured memory of debates for enhanced multi-agent reasoning. InSecond Conference on Language Modeling, 2025
work page 2025
-
[27]
Groupdebate: Enhancing the efficiency of multi-agent debate using group discussion
Tongxuan Liu, Xingyu Wang, Weizhe Huang, Wenjiang Xu, Yuting Zeng, Lei Jiang, Hailong Yang, and Jing Li. Groupdebate: Enhancing the efficiency of multi-agent debate using group discussion.arXiv preprint arXiv:2409.14051, 2024
-
[28]
Breaking mental set to improve reasoning through diverse multi-agent debate
Yexiang Liu, Jie Cao, Zekun Li, Ran He, and Tieniu Tan. Breaking mental set to improve reasoning through diverse multi-agent debate. InICLR, 2025
work page 2025
-
[29]
Lessons learned: A multi-agent framework for code LLMs to learn and improve
Yuanzhe Liu, Ryan Deng, Tim Kaler, Xuhao Chen, Charles E Leiserson, Yao Ma, and Jie Chen. Lessons learned: A multi-agent framework for code LLMs to learn and improve. InAdvances in Neural Information Processing Systems 38, 2025. 12
work page 2025
-
[30]
Self-refine: Iterative refinement with self-feedback, 2023
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Sean Welleck, Bodhisattwa Prasad Majumder, Shashank Gupta, Amir Yazdanbakhsh, and Peter Clark. Self-refine: Iterative refinement with self-feedback, 2023
work page 2023
-
[31]
OpenAI. Introducing gpt-5.5. https://openai.com/ko-KR/index/ introducing-gpt-5-5/, 2026. Accessed: 2026-05-6
work page 2026
-
[32]
Grips: Gradient-free, edit-based instruction search for prompting large language models
Archiki Prasad, Peter Hase, Xiang Zhou, and Mohit Bansal. Grips: Gradient-free, edit-based instruction search for prompting large language models. 2022
work page 2022
-
[33]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
work page 2023
-
[34]
Large language models as particle swarm optimizers
Yamato Shinohara, Jinglue Xu, Tianshui Li, and Hitoshi Iba. Large language models as particle swarm optimizers. In2025 IEEE Congress on Evolutionary Computation (CEC), pages 1–4, 2025
work page 2025
-
[35]
Debflow: Automating agent creation via agent debate.arXiv preprint arXiv:2503.23781, 2025
Jinwei Su, Yinghui Xia, Yiqun Duan, Jun Du, Jianuo Huang, Tianyu Shi, and Lewei He. Debflow: Automating agent creation via agent debate.arXiv preprint arXiv:2503.23781, 2025
-
[36]
James Surowiecki.The Wisdom of Crowds: Why the Many Are Smarter Than the Few and How Collective Wisdom Shapes Business, Economies, Societies, and Nations. Doubleday, New York, 2004
work page 2004
-
[37]
Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them
Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc V Le, Ed H Chi, Denny Zhou, , and Jason Wei. Challenging big-bench tasks and whether chain-of-thought can solve them.arXiv preprint arXiv:2210.09261, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[38]
Mixture-of-agents enhances large language model capabilities
Junlin Wang, Jue WANG, Ben Athiwaratkun, Ce Zhang, and James Zou. Mixture-of-agents enhances large language model capabilities. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[39]
Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[40]
Zora Zhiruo Wang, Jiayuan Mao, Daniel Fried, and Graham Neubig. Agent workflow memory. InForty-second International Conference on Machine Learning, 2025
work page 2025
-
[41]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
work page 2022
-
[42]
Evo-Memory: Benchmarking LLM Agent Test-time Learning with Self-Evolving Memory
Tianxin Wei, Noveen Sachdeva, Benjamin Coleman, Zhankui He, Yuanchen Bei, Xuying Ning, Mengting Ai, Yunzhe Li, Jingrui He, Ed H. Chi, Chi Wang, Shuo Chen, Fernando Pereira, Wang- Cheng Kang, and Derek Zhiyuan Cheng. Evo-memory: Benchmarking llm agent test-time learning with self-evolving memory.arXiv preprint arXiv:2511.20857, 2025
work page internal anchor Pith review arXiv 2025
-
[43]
Andrea Wynn, Harsh Satija, and Gillian Hadfield
Zhiyuan Weng, Guikun Chen, and Wenguan Wang. Do as we do, not as you think: the conformity of large language models.arXiv preprint arXiv:2501.13381, 2025
-
[44]
Comas: Co-evolving multi-agent systems via interaction rewards.CoRR, abs/2510.08529, 2025
Xiangyuan Xue, Yifan Zhou, Guibin Zhang, Zaibin Zhang, Yijiang Li, Chen Zhang, Zhenfei Yin, Philip Torr, Wanli Ouyang, and Lei Bai. Comas: Co-evolving multi-agent systems via interaction rewards.arXiv preprint arXiv:2510.08529, 2025
-
[45]
Large language models as optimizers
Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V Le, Denny Zhou, and Xinyun Chen. Large language models as optimizers. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[46]
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models.Ad- vances in neural information processing systems, 36:11809–11822, 2023. 13
work page 2023
-
[47]
Darwin gödel machine: Open-ended evolution of self-improving agents
Jenny Zhang, Shengran Hu, Cong Lu, Robert Tjarko Lange, and Jeff Clune. Darwin gödel machine: Open-ended evolution of self-improving agents. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[48]
Kai Zhang, Qiujun Huang, and Yimin Zhang. Enhancing comprehensive learning particle swarm optimization with local optima topology.Information Sciences, 471:1–18, 2019
work page 2019
-
[49]
American invitational mathematics examination (aime) 2025, 2025
Yifan Zhang and Team Math-AI. American invitational mathematics examination (aime) 2025, 2025
work page 2025
-
[50]
Chi, Quoc V Le, and Denny Zhou
Huaixiu Steven Zheng, Swaroop Mishra, Xinyun Chen, Heng-Tze Cheng, Ed H. Chi, Quoc V Le, and Denny Zhou. Take a step back: Evoking reasoning via abstraction in large language models. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[51]
Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc V Le, and Ed H. Chi. Least-to-most prompting enables complex reasoning in large language models. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[52]
Memento-skills: Let agents design agents
Huichi Zhou, Siyuan Guo, Anjie Liu, Zhongwei Yu, Ziqin Gong, Bowen Zhao, Zhixun Chen, Menglong Zhang, Yihang Chen, Jinsong Li, et al. Memento-skills: Let agents design agents. arXiv preprint arXiv:2603.18743, 2026
-
[53]
Self-discover: Large language models self-compose reasoning structures
Pei Zhou, Jay Pujara, Xiang Ren, Xinyun Chen, Heng-Tze Cheng, Quoc V . Le, Ed H. Chi, Denny Zhou, Swaroop Mishra, and Huaixiu Steven Zheng. Self-discover: Large language models self-compose reasoning structures.arXiv preprint arXiv:2402.03620, 2024
-
[54]
Large language models are human-level prompt engineers
Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan, and Jimmy Ba. Large language models are human-level prompt engineers. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[55]
Yuxin Zuo, Shang Qu, Yifei Li, Zhangren Chen, Xuekai Zhu, Ermo Hua, Kaiyan Zhang, Ning Ding, and Bowen Zhou. Medxpertqa: Benchmarking expert-level medical reasoning and understanding.arXiv preprint arXiv:2501.18362, 2025. 14 A Experimental Details Table 8:Hyperparameter settings for AgentPSO. Hyperparameter Value Number of agents 4 Number of iterations 10...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.