Recognition: no theorem link
AgentForesight: Online Auditing for Early Failure Prediction in Multi-Agent Systems
Pith reviewed 2026-05-15 05:20 UTC · model grok-4.3
The pith
A 7B model audits unfolding multi-agent trajectories online to flag the earliest decisive error using only the current prefix.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
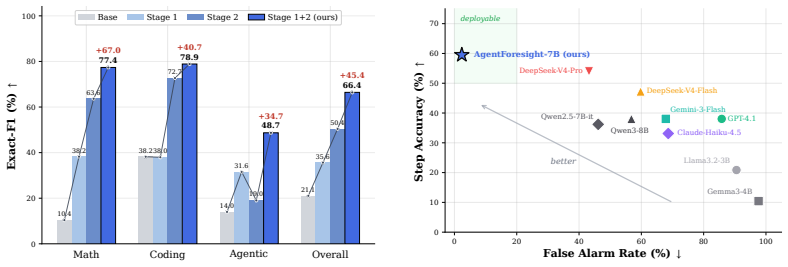
AgentForesight-7B performs online auditing on agentic trajectories by observing only the current prefix and deciding at each step whether to continue or to alarm at the earliest decisive error; it is obtained by first training a risk-anticipation prior on adjacent safe/unsafe prefix pairs and then refining that prior with a three-axis reward that jointly targets the what, where, and who of the audit verdict, yielding up to 19.9 percent higher performance and three-fold lower step localization error than leading proprietary models on AFTraj-2K and the Who&When benchmark.
What carries the argument
The coarse-to-fine reinforcement learning recipe that first equips the model with a risk-anticipation prior on adjacent safe/unsafe prefix pairs and then sharpens it into precise step-level localization under a three-axis reward jointly targeting the what, where, and who of an audit verdict.
If this is right
- Multi-agent deployments can shift from post-hoc failure analysis to live intervention that stops trajectories before they collapse.
- Auditing becomes possible at every step without access to future actions or outcomes.
- A compact 7B model can surpass much larger proprietary systems on both detection accuracy and localization precision.
- The same staged RL approach that first builds a boundary prior and then refines localization may apply to other sequential auditing tasks.
- Trajectory-level success rates can improve by catching single decisive mistakes before downstream agents accept them.
Where Pith is reading between the lines
- The framework could be embedded inside existing agent runtimes to trigger human review or automatic rollback at the moment of alarm.
- Because the auditor never sees future steps, it may generalize to open-ended real-world tasks where ground-truth failure is revealed only after the fact.
- Extending the three-axis reward to include downstream impact estimates could further reduce false alarms while preserving early detection.
- The curation pipeline's reliance on LLM judges suggests that scaling judge diversity or adding human verification loops would be a direct next measurement.
Load-bearing premise
The step-level annotations produced by consensus among multiple LLM judges correctly identify the decisive error without hindsight and the curation pipeline for safe trajectories produces data that generalizes to real deployments.
What would settle it
Run the trained auditor on a fresh set of held-out trajectories and measure whether it raises an alarm exactly at the human-identified first decisive error step and nowhere earlier, or whether it misses the error or produces false alarms.
Figures





read the original abstract
LLM-based multi-agent systems are increasingly deployed on long-horizon tasks, but a single decisive error is often accepted by downstream agents and cascades into trajectory-level failure. Existing work frames this as \emph{post-hoc failure attribution}, diagnosing the responsible agent and step after the trajectory has ended. However, this paradigm forfeits any opportunity to intervene while trajectory is still unfolding. In this work, we introduce AgentForesight, a framework that reframes this problem as online auditing: at each step of an unfolding trajectory, an auditor observes only the current prefix and must either continue the run or alarm at the earliest decisive error, without access to future steps. To this end, we curate AFTraj-2K, a corpus of agentic trajectories across Coding, Math, and Agentic domains, in which safe trajectories are retained under a strict curation pipeline and unsafe trajectories are annotated at the step of their decisive error via consensus among multiple LLM judges. Built on that, we develop AgentForesight-7B, a compact online auditor trained with a coarse-to-fine reinforcement learning recipe that first equips it with a risk-anticipation prior at the failure boundary on adjacent safe/unsafe prefix pairs, then sharpens this prior into precise step-level localization under a three-axis reward jointly targeting the what, where, and who of an audit verdict. Across AFTraj-2K and an external Who\&When benchmark, AgentForesight-7B outperforms leading proprietary models, including GPT-4.1 and DeepSeek-V4-Pro, achieving up to +19.9% performance gain and 3$\times$ lower step localization error, opening the loop from post-hoc failures detection to enabling deployment-time intervention. Project page: https://zbox1005.github.io/agent-foresight/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AgentForesight, a framework that reframes failure attribution in LLM-based multi-agent systems as an online auditing task: at each step, an auditor sees only the current trajectory prefix and must decide whether to continue or raise an alarm at the earliest decisive error. The authors curate AFTraj-2K (safe trajectories retained via strict pipeline; unsafe trajectories annotated at the decisive error step by LLM-judge consensus) and train AgentForesight-7B via a coarse-to-fine RL recipe—first instilling a risk-anticipation prior on adjacent safe/unsafe prefix pairs, then refining it with a three-axis reward targeting the what/where/who of the verdict. Experiments on AFTraj-2K and the external Who&When benchmark report that the 7B model outperforms GPT-4.1 and DeepSeek-V4-Pro by up to +19.9% while reducing step-localization error by 3×.
Significance. If the central claims hold, the work would meaningfully advance reliable deployment of long-horizon multi-agent systems by shifting from post-hoc diagnosis to prefix-based early intervention. The coarse-to-fine RL recipe and the explicit separation of safe/unsafe prefix pairs constitute a concrete technical contribution; the reported gains over strong proprietary baselines on both internal and external benchmarks are noteworthy and would be of immediate interest to the community if the annotation pipeline can be shown to avoid hindsight leakage.
major comments (2)
- [Dataset curation and annotation pipeline] Dataset curation (AFTraj-2K construction): the decisive-error step labels are produced by LLM-judge consensus on complete trajectories. Because judges observe future steps unavailable to the online auditor, the resulting positive/negative boundary may encode information that does not exist at the prefix the model actually sees. This directly affects both stages of the coarse-to-fine RL recipe and is load-bearing for the claim of genuine early prediction rather than post-hoc mimicry.
- [Experiments and results] Evaluation protocol: the reported +19.9% gain and 3× localization improvement are presented without a detailed breakdown of how the external Who&When benchmark was adapted or whether its test prefixes were constructed to exclude any future-step information used in annotation. Without this, it is difficult to assess whether the performance edge generalizes to true online deployment.
minor comments (2)
- [Training recipe] The three-axis reward weights are listed as free parameters; a brief sensitivity analysis or default values should be provided so readers can reproduce the exact training signal.
- [Metrics] Clarify the precise definition of 'step localization error' (e.g., absolute step offset, normalized distance) and whether it is computed only on trajectories where an alarm is raised.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments, which highlight important considerations for ensuring the online nature of the auditing task. We address each major point below with clarifications and proposed revisions. These changes will strengthen the transparency of our dataset construction and evaluation protocol without altering the core technical contributions.
read point-by-point responses
-
Referee: [Dataset curation and annotation pipeline] Dataset curation (AFTraj-2K construction): the decisive-error step labels are produced by LLM-judge consensus on complete trajectories. Because judges observe future steps unavailable to the online auditor, the resulting positive/negative boundary may encode information that does not exist at the prefix the model actually sees. This directly affects both stages of the coarse-to-fine RL recipe and is load-bearing for the claim of genuine early prediction rather than post-hoc mimicry.
Authors: We agree this is a substantive concern for any prefix-based prediction task. Our annotation protocol instructs judges to identify the earliest step at which the trajectory becomes irreversibly unsafe based on observable divergence (e.g., incorrect code commit, flawed reasoning chain), with explicit prompts to avoid relying on later recovery attempts. Multiple judges reach consensus only when the failure is locally detectable from the prefix onward. Nevertheless, we acknowledge that full-trajectory context can subtly influence boundary placement. In the revision we will (1) release the exact judge prompts and consensus rules, (2) add an ablation comparing performance when labels are derived from prefix-only human review on a 200-trajectory subset, and (3) include a limitations paragraph quantifying residual leakage risk. These additions provide the requested transparency while preserving the claim that the auditor itself never sees future tokens. revision: partial
-
Referee: [Experiments and results] Evaluation protocol: the reported +19.9% gain and 3× localization improvement are presented without a detailed breakdown of how the external Who&When benchmark was adapted or whether its test prefixes were constructed to exclude any future-step information used in annotation. Without this, it is difficult to assess whether the performance edge generalizes to true online deployment.
Authors: We thank the referee for noting this omission. The Who&When test prefixes were created by truncating each trajectory exactly at the original annotation's decisive-error step, discarding all subsequent tokens; no post-failure information is present in any input the model receives. We will add a dedicated appendix subsection that (a) reproduces the truncation procedure, (b) provides pseudocode for prefix construction, and (c) reports a verification step confirming zero future-token leakage. This documentation will make the online evaluation protocol fully reproducible and directly address the generalization question. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper curates AFTraj-2K with LLM-judge annotations on full trajectories for decisive error steps, then trains AgentForesight-7B via a coarse-to-fine RL procedure on prefix observations only, followed by evaluation on AFTraj-2K and an external Who&When benchmark. No equations, fitted parameters, or self-citations are shown that reduce any claimed prediction or result to the inputs by construction; the training signal and performance metrics remain independent of any tautological redefinition of the target labels.
Axiom & Free-Parameter Ledger
free parameters (1)
- three-axis reward weights
axioms (1)
- domain assumption Consensus among multiple LLM judges accurately identifies the decisive error step in unsafe trajectories
Reference graph
Works this paper leans on
-
[1]
Anthropic. Introducing claude haiku 4.5. https://www.anthropic.com/news/ claude-haiku-4-5, October 2025. Accessed: 2026-05-02
work page 2025
-
[2]
Monitoring reasoning models for misbehavior.arXiv preprint arXiv:2503.11926,
Bowen Baker, Joost Huizinga, Leo Gao, Zehao Dou, Melody Y Guan, Aleksander Madry, Wojciech Zaremba, Jakub Pachocki, and David Farhi. Monitoring reasoning models for misbehavior and the risks of promoting obfuscation.arXiv preprint arXiv:2503.11926, 2025
-
[3]
Why Do Multi-Agent LLM Systems Fail?
Mert Cemri, Melissa Z Pan, Shuyi Yang, Lakshya A Agrawal, Bhavya Chopra, Rishabh Tiwari, Kurt Keutzer, Aditya Parameswaran, Dan Klein, Kannan Ramchandran, et al. Why do multi- agent llm systems fail?arXiv preprint arXiv:2503.13657, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate
Chi-Min Chan, Weize Chen, Yusheng Su, Jianxuan Yu, Wei Xue, Shanghang Zhang, Jie Fu, and Zhiyuan Liu. Chateval: Towards better llm-based evaluators through multi-agent debate. arXiv preprint arXiv:2308.07201, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
DeepSeek-AI. Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
work page 2026
-
[7]
Gemini 3 flash: Frontier intelligence built for speed
Tulsee Doshi. Gemini 3 flash: Frontier intelligence built for speed. https://blog. google/products-and-platforms/products/gemini/gemini-3-flash/ , December
- [8]
-
[9]
Lm-polygraph: Uncertainty estimation for language models
Ekaterina Fadeeva, Roman Vashurin, Akim Tsvigun, Artem Vazhentsev, Sergey Petrakov, Kirill Fedyanin, Daniil Vasilev, Elizaveta Goncharova, Alexander Panchenko, Maxim Panov, et al. Lm-polygraph: Uncertainty estimation for language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages ...
work page 2023
-
[10]
Group-in-Group Policy Optimization for LLM Agent Training
Lang Feng, Zhenghai Xue, Tingcong Liu, and Bo An. Group-in-group policy optimization for llm agent training.arXiv preprint arXiv:2505.10978, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Gemma Team. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, March 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Alireza Ghafarollahi and Markus J Buehler. Sciagents: automating scientific discovery through bioinspired multi-agent intelligent graph reasoning.Advanced Materials, 37(22):2413523, 2025
work page 2025
-
[13]
Ali Essam Ghareeb, Benjamin Chang, Ludovico Mitchener, Angela Yiu, Caralyn J Szostkiewicz, Jon M Laurent, Muhammed T Razzak, Andrew D White, Michaela M Hinks, and Samuel G Rodriques. Robin: A multi-agent system for automating scientific discovery.arXiv preprint arXiv:2505.13400, 2025
-
[14]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
A survey on llm-as-a-judge.The Innovation, 2024
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, et al. A survey on llm-as-a-judge.The Innovation, 2024. 10
work page 2024
-
[16]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[18]
Metagpt: Meta programming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al. Metagpt: Meta programming for a multi-agent collaborative framework. InThe twelfth international conference on learning representations, 2023
work page 2023
-
[19]
Large Language Models Cannot Self-Correct Reasoning Yet
Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. Large language models cannot self-correct reasoning yet.arXiv preprint arXiv:2310.01798, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Zhenlan Ji, Daoyuan Wu, Pingchuan Ma, Zongjie Li, and Shuai Wang. Testing and under- standing erroneous planning in llm agents through synthesized user inputs.arXiv preprint arXiv:2404.17833, 2024
-
[21]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Za- mani, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Reliable weak-to-strong monitoring of llm agents.arXiv preprint arXiv:2508.19461, 2025
Neil Kale, Chen Bo Calvin Zhang, Kevin Zhu, Ankit Aich, Paula Rodriguez, Scale Red Team, Christina Q Knight, and Zifan Wang. Reliable weak-to-strong monitoring of llm agents.arXiv preprint arXiv:2508.19461, 2025
-
[24]
Shade-arena: Evaluating sabotage and monitoring in llm agents.arXiv preprint arXiv:2506.15740, 2025
Jonathan Kutasov, Yuqi Sun, Paul Colognese, Teun van der Weij, Linda Petrini, Chen Bo Calvin Zhang, John Hughes, Xiang Deng, Henry Sleight, Tyler Tracy, et al. Shade-arena: Evaluating sabotage and monitoring in llm agents.arXiv preprint arXiv:2506.15740, 2025
-
[25]
Guohao Li, Hasan Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. Camel: Communicative agents for" mind" exploration of large language model society.Advances in neural information processing systems, 36:51991–52008, 2023
work page 2023
-
[26]
ATBench: A Diverse and Realistic Agent Trajectory Benchmark for Safety Evaluation and Diagnosis
Yu Li, Haoyu Luo, Yuejin Xie, Yuqian Fu, Zhonghao Yang, Shuai Shao, Qihan Ren, Wanying Qu, Yanwei Fu, Yujiu Yang, et al. Atbench: A diverse and realistic trajectory benchmark for long-horizon agent safety.arXiv preprint arXiv:2604.02022, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Zhuofeng Li, Haoxiang Zhang, Seungju Han, Sheng Liu, Jianwen Xie, Yu Zhang, Yejin Choi, James Zou, and Pan Lu. In-the-flow agentic system optimization for effective planning and tool use.arXiv preprint arXiv:2510.05592, 2025
-
[28]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe twelfth international conference on learning representations, 2023
work page 2023
-
[29]
Bang Liu, Xinfeng Li, Jiayi Zhang, Jinlin Wang, Tanjin He, Sirui Hong, Hongzhang Liu, Shaokun Zhang, Kaitao Song, Kunlun Zhu, et al. Advances and challenges in foundation agents: From brain-inspired intelligence to evolutionary, collaborative, and safe systems.arXiv preprint arXiv:2504.01990, 2025
-
[30]
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation. Advances in neural information processing systems, 36:21558–21572, 2023. 11
work page 2023
-
[31]
Llm collaboration with multi- agent reinforcement learning
Shuo Liu, Zeyu Liang, Xueguang Lyu, and Christopher Amato. Llm collaboration with multi- agent reinforcement learning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 32150–32158, 2026
work page 2026
-
[32]
G-eval: Nlg evaluation using gpt-4 with better human alignment
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-eval: Nlg evaluation using gpt-4 with better human alignment. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 2511–2522, 2023
work page 2023
-
[33]
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: Iterative refinement with self-feedback.Advances in neural information processing systems, 36:46534–46594, 2023
work page 2023
-
[34]
Gaia: a benchmark for general ai assistants
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. Gaia: a benchmark for general ai assistants. InThe Twelfth International Conference on Learning Representations, 2023
work page 2023
-
[35]
Ning Miao, Yee Whye Teh, and Tom Rainforth. Selfcheck: Using llms to zero-shot check their own step-by-step reasoning.arXiv preprint arXiv:2308.00436, 2023
-
[36]
Kaiwen Ning, Jiachi Chen, Jingwen Zhang, Wei Li, Zexu Wang, Yuming Feng, Weizhe Zhang, and Zibin Zheng. Defining and detecting the defects of large language model-based autonomous agents.IEEE Transactions on Software Engineering, 2026
work page 2026
-
[37]
OpenAI. Gpt-5 system card. https://openai.com/index/gpt-5-system-card/ , August
- [38]
-
[39]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
work page 2022
-
[40]
Memgpt: towards llms as operating systems
Charles Packer, Vivian Fang, Shishir_G Patil, Kevin Lin, Sarah Wooders, and Joseph_E Gonza- lez. Memgpt: towards llms as operating systems. 2023
work page 2023
-
[41]
Chen Qian, Peng Wang, Dongrui Liu, Junyao Yang, Dadi Guo, Ling Tang, Jilin Mei, Qihan Ren, Shuai Shao, Yong Liu, et al. The why behind the action: Unveiling internal drivers via agentic attribution.arXiv preprint arXiv:2601.15075, 2026
-
[42]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728–53741, 2023
work page 2023
-
[43]
smolagents: A smol library to build great agentic systems.Hugging Face, 2025
Aymeric Roucher, A Villanova del Moral, Thomas Wolf, Leandro von Werra, and Erik Kaunis- mäki. smolagents: A smol library to build great agentic systems.Hugging Face, 2025
work page 2025
-
[44]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems, 36:68539– 68551, 2023
work page 2023
-
[45]
Bronson Schoen, Evgenia Nitishinskaya, Mikita Balesni, Axel Højmark, Felix Hofstätter, Jérémy Scheurer, Alexander Meinke, Jason Wolfe, Teun van der Weij, Alex Lloyd, et al. Stress testing deliberative alignment for anti-scheming training.arXiv preprint arXiv:2509.15541, 2025
-
[46]
John Schulman. Approximating KL divergence. http://joschu.net/blog/kl-approx. html, 2020. Blog post
work page 2020
-
[47]
Shuai Shao, Qihan Ren, Chen Qian, Boyi Wei, Dadi Guo, Jingyi Yang, Xinhao Song, Linfeng Zhang, Weinan Zhang, Dongrui Liu, et al. Your agent may misevolve: Emergent risks in self-evolving llm agents.arXiv preprint arXiv:2509.26354, 2025. 12
-
[48]
Hybridflow: A flexible and efficient rlhf framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. In Proceedings of the Twentieth European Conference on Computer Systems, pages 1279–1297, 2025
work page 2025
-
[49]
From commands to prompts: Llm-based semantic file system for aios
Zeru Shi, Kai Mei, Mingyu Jin, Yongye Su, Chaoji Zuo, Wenyue Hua, Wujiang Xu, Yujie Ren, Zirui Liu, Mengnan Du, et al. From commands to prompts: Llm-based semantic file system for aios. InInternational Conference on Learning Representations, volume 2025, pages 33108–33131, 2025
work page 2025
-
[50]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
work page 2023
-
[51]
Yoo Yeon Sung, Hannah Kim, and Dan Zhang. Verila: A human-centered evaluation framework for interpretable verification of llm agent failures.arXiv preprint arXiv:2503.12651, 2025
-
[52]
Math-shepherd: Verify and reinforce llms step-by-step without human annotations
Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. Math-shepherd: Verify and reinforce llms step-by-step without human annotations. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9426–9439, 2024
work page 2024
-
[53]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
Xingyao Wang, Boxuan Li, Yufan Song, Frank F Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, et al. Openhands: An open platform for ai software developers as generalist agents.arXiv preprint arXiv:2407.16741, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
work page 2022
-
[55]
Autogen: Enabling next-gen llm applications via multi-agent conversations
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, et al. Autogen: Enabling next-gen llm applications via multi-agent conversations. InFirst conference on language modeling, 2024
work page 2024
-
[56]
Zhiheng Xi, Jixuan Huang, Chenyang Liao, Baodai Huang, Honglin Guo, Jiaqi Liu, Rui Zheng, Junjie Ye, Jiazheng Zhang, Wenxiang Chen, et al. Agentgym-rl: Training llm agents for long-horizon decision making through multi-turn reinforcement learning.arXiv preprint arXiv:2509.08755, 2025
-
[57]
Agentprm: Process reward models for llm agents via step-wise promise and progress
Zhiheng Xi, Chenyang Liao, Guanyu Li, Zhihao Zhang, Wenxiang Chen, Binghai Wang, Senjie Jin, Yuhao Zhou, Jian Guan, Wei Wu, et al. Agentprm: Process reward models for llm agents via step-wise promise and progress. InProceedings of the ACM Web Conference 2026, pages 4184–4195, 2026
work page 2026
-
[58]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
Hotpotqa: A dataset for diverse, explainable multi-hop question answering
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 conference on empirical methods in natural language processing, pages 2369–2380, 2018
work page 2018
-
[60]
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models.Ad- vances in neural information processing systems, 36:11809–11822, 2023
work page 2023
-
[61]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2022
work page 2022
-
[62]
Boxuan Zhang, Yi Yu, Jiaxuan Guo, and Jing Shao. Dive into the agent matrix: A realistic evaluation of self-replication risk in llm agents.arXiv preprint arXiv:2509.25302, 2025. 13
-
[63]
Cot-uq: Improving response-wise uncertainty quantification in llms with chain-of-thought
Boxuan Zhang and Ruqi Zhang. Cot-uq: Improving response-wise uncertainty quantification in llms with chain-of-thought. InFindings of the Association for Computational Linguistics: ACL 2025, pages 26114–26133, 2025
work page 2025
-
[64]
Agentracer: Who is inducing failure in the llm agentic systems?arXiv preprint arXiv:2509.03312, 2025
Guibin Zhang, Junhao Wang, Junjie Chen, Wangchunshu Zhou, Kun Wang, and Shuicheng Yan. Agentracer: Who is inducing failure in the llm agentic systems?arXiv preprint arXiv:2509.03312, 2025
-
[65]
Shaokun Zhang, Ming Yin, Jieyu Zhang, Jiale Liu, Zhiguang Han, Jingyang Zhang, Beibin Li, Chi Wang, Huazheng Wang, Yiran Chen, et al. Which agent causes task failures and when? on automated failure attribution of llm multi-agent systems.arXiv preprint arXiv:2505.00212, 2025
-
[66]
Processbench: Identifying process errors in mathematical reasoning
Chujie Zheng, Zhenru Zhang, Beichen Zhang, Runji Lin, Keming Lu, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. Processbench: Identifying process errors in mathematical reasoning. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1009–1024, 2025
work page 2025
-
[67]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
work page 2023
-
[68]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[69]
Where llm agents fail and how they can learn from failures.arXiv preprint arXiv:2509.25370, 2025
Kunlun Zhu, Zijia Liu, Bingxuan Li, Muxin Tian, Yingxuan Yang, Jiaxun Zhang, Pengrui Han, Qipeng Xie, Fuyang Cui, Weijia Zhang, et al. Where llm agents fail and how they can learn from failures.arXiv preprint arXiv:2509.25370, 2025
-
[70]
Language agents as optimizable graphs.arXiv preprint arXiv:2402.16823, 2024
Mingchen Zhuge, Wenyi Wang, Louis Kirsch, Francesco Faccio, Dmitrii Khizbullin, and Jürgen Schmidhuber. Language agents as optimizable graphs.arXiv preprint arXiv:2402.16823, 2024
-
[71]
Does this step contain a critical error? Answer with only ‘yes’ or ‘no’
Mingchen Zhuge, Changsheng Zhao, Dylan Ashley, Wenyi Wang, Dmitrii Khizbullin, Yunyang Xiong, Zechun Liu, Ernie Chang, Raghuraman Krishnamoorthi, Yuandong Tian, et al. Agent- as-a-judge: Evaluate agents with agents.arXiv preprint arXiv:2410.10934, 2024. 14 Appendices A Algorithmic Pipeline 16 B Additional Experiment Setups 17 B.1 Details of Datasets . . ....
-
[72]
Walk through each visible step chronologically
-
[73]
For each agent action, ask: was this action appropriate given prior context? Did any tool result reveal information the agent ignored?
-
[74]
Identify the EARLIEST decisive error supported by the visible evidence, if any
-
[75]
If no step in the visible window contains a decisive error, answer SAFE. ## Response Format (STRICT) Your response MUST follow this exact two-block format: <think> Walk through the visible trajectory step-by-step. Reference specific step numbers (e.g. "step 3") and agent names (e.g. "TaskSolver", "Geography_Expert"). State whether a decisive error is supp...
-
[76]
It is a SUBSTANTIVE error, not a superficial formatting issue
-
[77]
It is a DECISIVE error: correcting it would likely prevent the failure
-
[78]
It is as EARLY as possible, but still genuinely causal
-
[79]
The mistake_step MUST be an exact step number from the trajectory
-
[80]
The mistake_agent MUST exactly match the agent at that step
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.