Recognition: no theorem link
cuRegOT: A GPU-Accelerated Solver for Entropic-Regularized Optimal Transport
Pith reviewed 2026-05-12 01:19 UTC · model grok-4.3
The pith
cuRegOT provides a GPU solver for entropic regularized optimal transport that delivers significant speedups over state-of-the-art methods with preserved convergence guarantees.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
cuRegOT is a GPU-accelerated solver for entropic-regularized optimal transport that combines an amortized symbolic analysis strategy to reduce CPU overhead, an asynchronous mechanism for generating Sinkhorn iterates, and a fused kernel for efficient gradient computation. These optimizations are supported by theoretical guarantees of convergence, and experiments show substantial speedups compared to prior GPU solvers on various benchmark tasks.
What carries the argument
Amortized symbolic analysis combined with asynchronous Sinkhorn iterate generation and fused gradient kernels, addressing CPU bottlenecks and irregular memory patterns in GPU-based OT solving.
Load-bearing premise
The GPU-specific optimizations do not alter the convergence behavior or numerical accuracy of the entropic OT solver through changes in execution or floating-point operations.
What would settle it
Reproducing the benchmark experiments and finding either insufficient speedups or failures in convergence guarantees would disprove the paper's main results.
Figures








read the original abstract
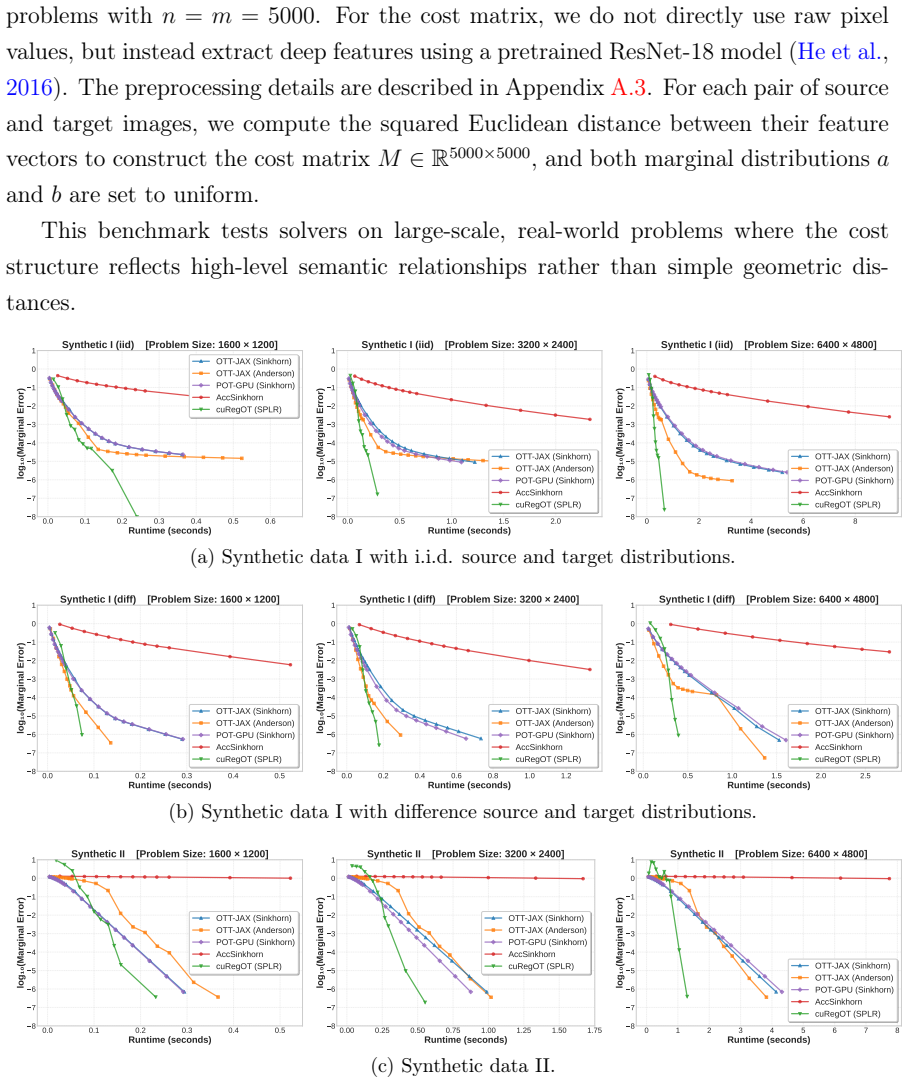
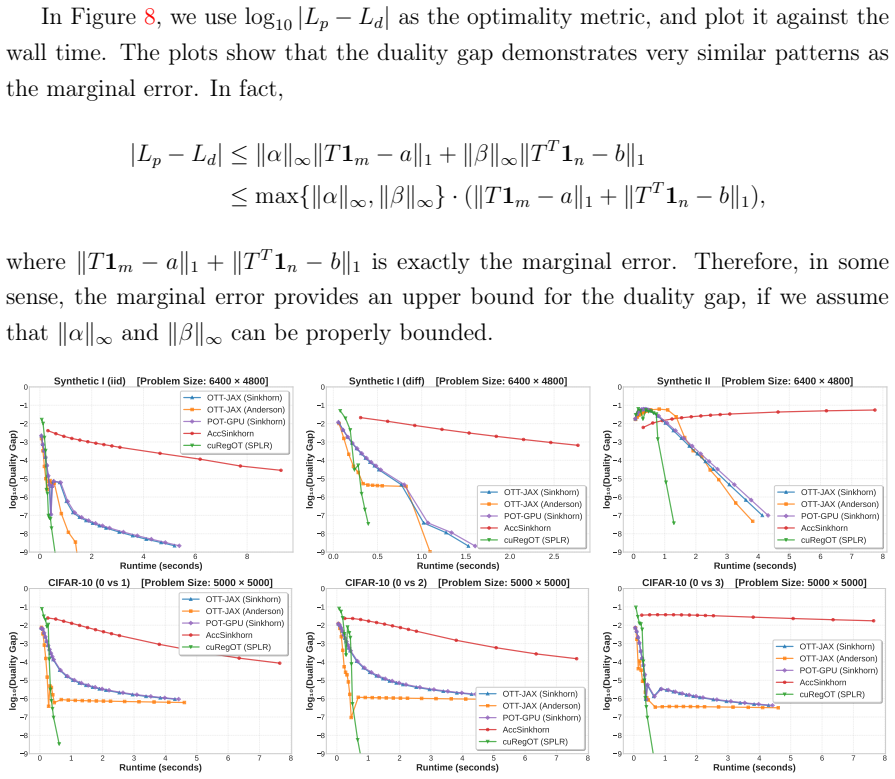
Optimal transport (OT) has emerged as a fundamental tool in modern machine learning, yet its computational cost remains a significant bottleneck for large-scale applications. While harnessing the massive parallelism of modern GPU hardware is critical for efficiency, the de facto standard Sinkhorn algorithm, despite its ease of parallelization, often suffers from slow convergence in challenging problems. More recently, the sparse-plus-low-rank quasi-Newton method offers a balance between convergence rate and per-iteration complexity; however, its efficiency on GPUs is severely hindered by the serial nature of sparse matrix symbolic analysis and irregular memory access patterns. To bridge this gap, we present cuRegOT, a high-performance GPU solver tailored for entropic-regularized OT. We introduce a suite of algorithmic and architectural optimizations, including an amortized symbolic analysis strategy to mitigate CPU bottlenecks, an asynchronous Sinkhorn iterates generation mechanism, and a fused kernel for bandwidth-efficient gradient evaluation. These strategies are backed by rigorous theoretical guarantees ensuring algorithmic convergence. Extensive numerical experiments demonstrate that cuRegOT achieves significant speedups over state-of-the-art GPU-based solvers across a variety of benchmark tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces cuRegOT, a GPU-accelerated solver for entropic-regularized optimal transport. It targets the sparse-plus-low-rank quasi-Newton method by adding an amortized symbolic analysis pass to reduce CPU bottlenecks, an asynchronous mechanism for Sinkhorn iterate generation, and fused kernels for bandwidth-efficient gradient evaluation. The work asserts that these changes are accompanied by rigorous theoretical convergence guarantees and reports substantial empirical speedups over prior GPU OT solvers on benchmark tasks.
Significance. If the claimed convergence guarantees are shown to hold under asynchrony and kernel fusion, and if the speedups are reproducible while preserving numerical accuracy, the solver could meaningfully accelerate large-scale OT computations in machine learning pipelines such as generative modeling and domain adaptation.
major comments (1)
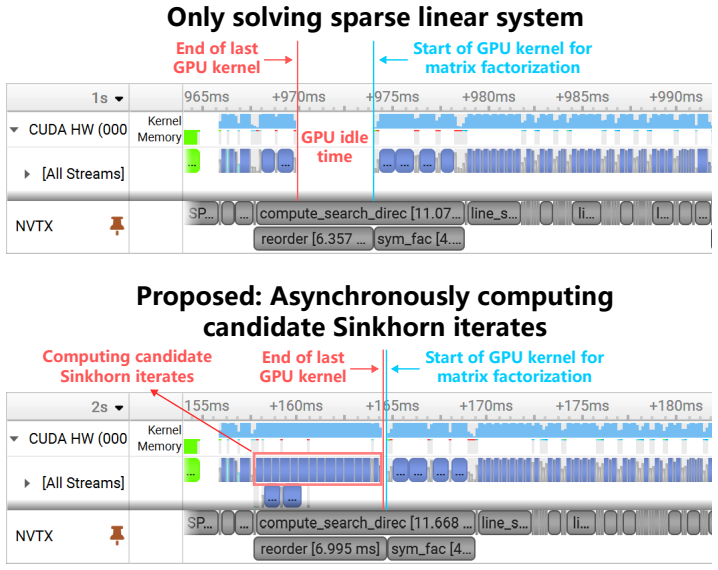
- Abstract: the assertion of 'rigorous theoretical guarantees ensuring algorithmic convergence' for the asynchronous Sinkhorn iterates generation mechanism is load-bearing for the central claim. The provided description gives no indication that the analysis accounts for relaxed synchronization, non-deterministic iteration ordering, or altered floating-point accumulation from kernel fusion; if the proof assumes synchronous updates, the guarantees do not automatically transfer to the delivered GPU code.
minor comments (1)
- §4 (Experiments): the speed-up tables would benefit from explicit reporting of the number of independent runs, standard deviations, and any data-exclusion rules to allow readers to assess robustness.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback on the manuscript. We address the major comment below and will incorporate revisions to improve clarity.
read point-by-point responses
-
Referee: Abstract: the assertion of 'rigorous theoretical guarantees ensuring algorithmic convergence' for the asynchronous Sinkhorn iterates generation mechanism is load-bearing for the central claim. The provided description gives no indication that the analysis accounts for relaxed synchronization, non-deterministic iteration ordering, or altered floating-point accumulation from kernel fusion; if the proof assumes synchronous updates, the guarantees do not automatically transfer to the delivered GPU code.
Authors: We agree that the abstract statement requires more precise scoping to avoid ambiguity. The convergence analysis establishes guarantees for the underlying sparse-plus-low-rank quasi-Newton method and the associated Sinkhorn iterations under standard synchronous assumptions. The asynchronous mechanism reorders the generation of iterates on the GPU for improved throughput but computes identical mathematical updates to the synchronous version; each new iterate is produced from the preceding state without changing the fixed-point equations or the sequence of operations. Kernel fusion is applied only to the gradient evaluation step and preserves the exact arithmetic result up to standard floating-point associativity, which does not affect the convergence conditions. We will revise the abstract to state that the guarantees apply to the core algorithmic framework, and we will add a short paragraph in the methods section explaining the equivalence of the asynchronous implementation to its synchronous counterpart together with additional numerical checks confirming identical convergence behavior. revision: yes
Circularity Check
No circularity: algorithmic implementation with independent convergence claims
full rationale
The paper describes a GPU-accelerated implementation of the Sinkhorn algorithm for entropic OT, introducing practical optimizations (amortized analysis, asynchronous iteration, kernel fusion) and stating that these are supported by standard theoretical convergence guarantees. No equations, fitted parameters, or predictions are presented that reduce by construction to quantities defined on the same data or via self-referential definitions. The central claims concern engineering speedups and preservation of existing theory under implementation changes; these do not form a closed derivation loop. The work is self-contained as a software contribution without load-bearing self-citations or ansatz smuggling.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Entropic regularization yields a strictly convex problem whose unique solution can be recovered by Sinkhorn-type iterations
- domain assumption Sparse matrix symbolic analysis can be amortized across multiple right-hand sides without changing the nonzero pattern
Reference graph
Works this paper leans on
-
[1]
Altschuler, J., Niles-Weed , J., and Rigollet, P. (2017). Near-linear time approximation algorithms for optimal transport via Sinkhorn iteration. In Advances in Neural Information Processing Systems , volume 30
work page 2017
-
[2]
Arjovsky, M., Chintala, S., and Bottou, L. (2017). Wasserstein generative adversarial networks. In Proceedings of the 34th International Conference on Machine Learning , pages 214--223
work page 2017
-
[3]
Courty, N., Flamary, R., Tuia, D., and Rakotomamonjy, A. (2017). Optimal transport for domain adaptation. IEEE Transactions on Pattern Analysis and Machine Intelligence , 39(9):1853--1865
work page 2017
-
[4]
Cuturi, M. (2013). Sinkhorn distances: Lightspeed computation of optimal transport. In Advances in Neural Information Processing Systems , volume 26
work page 2013
- [5]
-
[6]
Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., and Li, F.-F. (2009). ImageNet : A large-scale hierarchical image database. In 2009 IEEE Conference on Computer Vision and Pattern Recognition , pages 248--255
work page 2009
-
[7]
Z., Boisbunon, A., Chambon, S., Chapel, L., Corenflos, A., Fatras, K., Fournier, N., et al
Flamary, R., Courty, N., Gramfort, A., Alaya, M. Z., Boisbunon, A., Chambon, S., Chapel, L., Corenflos, A., Fatras, K., Fournier, N., et al. (2021). POT : Python optimal transport. Journal of Machine Learning Research , 22(78):1--8
work page 2021
-
[8]
He, K., Zhang, X., Ren, S., and Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition , pages 770--778
work page 2016
-
[9]
Krizhevsky, A. (2009). Learning multiple layers of features from tiny images. Technical Report
work page 2009
-
[10]
Lin, T., Ho, N., and Jordan, M. I. (2022). On the efficiency of entropic regularized algorithms for optimal transport. Journal of Machine Learning Research , 23(137):1--42
work page 2022
-
[11]
Lindb \"a ck, J., Wang, Z., and Johansson, M. (2023). Bringing regularized optimal transport to lightspeed: a splitting method adapted for GPUs . In Advances in Neural Information Processing Systems , volume 36, pages 26845--26871
work page 2023
-
[12]
Lu, H. and Yang, J. (2024). PDOT : A practical primal-dual algorithm and a GPU -based solver for optimal transport. arXiv preprint arXiv:2407.19689
-
[13]
Mor \'e , J. J. and Thuente, D. J. (1994). Line search algorithms with guaranteed sufficient decrease. ACM Transactions on Mathematical Software (TOMS) , 20(3):286--307
work page 1994
-
[14]
Nocedal, J. and Wright, S. J. (2006). Numerical optimization . Springer
work page 2006
-
[15]
Okuta, R., Unno, Y., Nishino, D., Hido, S., and Loomis, C. (2017). CuPy : A NumPy -compatible library for NVIDIA GPU calculations. In Proceedings of Workshop on Machine Learning Systems (LearningSys) in The Thirty-first Annual Conference on Neural Information Processing Systems (NIPS)
work page 2017
-
[16]
Ouyang, X., Zheng, H., Liang, H., Zhang, J., Qiu, Y., Meng, C., and Li, M. (2026). Sparsification techniques for large-scale optimal transport problems. Wiley Interdisciplinary Reviews: Computational Statistics , 18(1):e70056
work page 2026
-
[17]
Pele, O. and Werman, M. (2009). Fast and robust earth mover's distances. In 2009 IEEE 12th international conference on computer vision , pages 460--467. IEEE
work page 2009
-
[18]
Peyr \'e , G., Cuturi, M., et al. (2019). Computational optimal transport: With applications to data science. Foundations and Trends in Machine Learning , 11(5-6):355--607
work page 2019
-
[19]
Schiebinger, G., Shu, J., Tabaka, M., Cleary, B., Subramanian, V., Solomon, A., Gould, J., Liu, S., Lin, S., Berube, P., et al. (2019). Optimal-transport analysis of single-cell gene expression identifies developmental trajectories in reprogramming. Cell , 176(4):928--943
work page 2019
-
[20]
Schmitzer, B. (2019). Stabilized sparse scaling algorithms for entropy regularized transport problems. SIAM Journal on Scientific Computing , 41(3):A1443--A1481
work page 2019
-
[21]
Sinkhorn, R. (1964). A relationship between arbitrary positive matrices and doubly stochastic matrices. The Annals of Mathematical Statistics , 35(2):876--879
work page 1964
-
[22]
Solomon, J., De Goes, F., Peyr \'e , G., Cuturi, M., Butscher, A., Nguyen, A., Du, T., and Guibas, L. (2015). Convolutional Wasserstein distances: Efficient optimal transportation on geometric domains. ACM Transactions on Graphics (ToG) , 34(4):1--11
work page 2015
-
[23]
Tang, X., Shavlovsky, M., Rahmanian, H., Tardini, E., Thekumparampil, K. K., Xiao, T., and Ying, L. (2024). Accelerating Sinkhorn algorithm with sparse Newton iterations. In The Twelfth International Conference on Learning Representations
work page 2024
-
[24]
Tang, Z. and Qiu, Y. (2024). Safe and sparse Newton method for entropic-regularized optimal transport. In Advances in Neural Information Processing Systems , volume 38
work page 2024
-
[25]
Villani, C. et al. (2009). Optimal transport: old and new . Springer
work page 2009
-
[26]
Wang, C. and Qiu, Y. (2025). The sparse-plus-low-rank quasi- Newton method for entropic-regularized optimal transport. In Proceedings of the 42nd International Conference on Machine Learning , pages 64202--64221
work page 2025
-
[27]
Yule, G. U. (1912). On the methods of measuring association between two attributes. Journal of the Royal Statistical Society , 75(6):579--642
work page 1912
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.