Recognition: 2 theorem links
· Lean TheoremCurvature-Aware Captioning:Leveraging Geodesic Attention for 3D Scene Understanding
Pith reviewed 2026-05-12 02:39 UTC · model grok-4.3
The pith
Curvature complementarity between Oblique and Lorentz manifolds lets geodesic attention handle both precise object locations and coherent scene hierarchies in 3D captioning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Curvature-Aware Captioning framework integrates self-attention within Oblique space to enforce dimensional homogeneity while establishing long-range dependencies, together with bidirectional geodesic cross-attention within Lorentz space to model hierarchical semantic relationships across scene instances. Theoretical analysis confirms that the curvature complementarity between the Oblique manifold and Lorentz hyperboloid resolves the Euclidean-hyperbolic conflict, ensuring feature stability via isotropic optimization while preserving inherent hierarchical relationships.
What carries the argument
Curvature complementarity between the Oblique manifold and Lorentz hyperboloid, which lets geodesic self-attention and cross-attention balance local geometric precision with global semantic hierarchies.
If this is right
- Object localization becomes more accurate because dimensional homogeneity is preserved in the Oblique space.
- Scene descriptions gain coherence and richness because hierarchical relationships are modeled explicitly in the Lorentz space.
- The method reaches state-of-the-art scores on both localization and descriptive metrics on the ScanRefer and Nr3D benchmarks.
Where Pith is reading between the lines
- The same dual-manifold attention pattern could be tested on other 3D tasks such as instance segmentation where both local geometry and scene-wide structure matter.
- The approach might reduce reliance on heavy data augmentation for point clouds if the curvature complementarity already supplies stable features.
- Performance on dense rather than sparse inputs is not examined, so the method's behavior when point density increases remains open.
Load-bearing premise
That self-attention inside Oblique space and bidirectional geodesic cross-attention inside Lorentz space will together produce both fine localization and coherent hierarchical descriptions from sparse point clouds without creating new instabilities.
What would settle it
A direct comparison on sparse point cloud scenes in which the dual-manifold method shows no gain or a loss in object localization precision or scene-description coherence relative to standard Euclidean attention baselines.
Figures


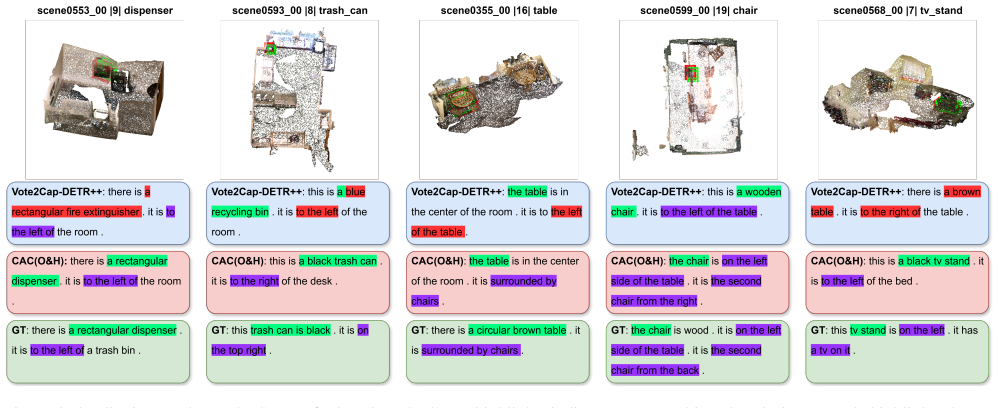
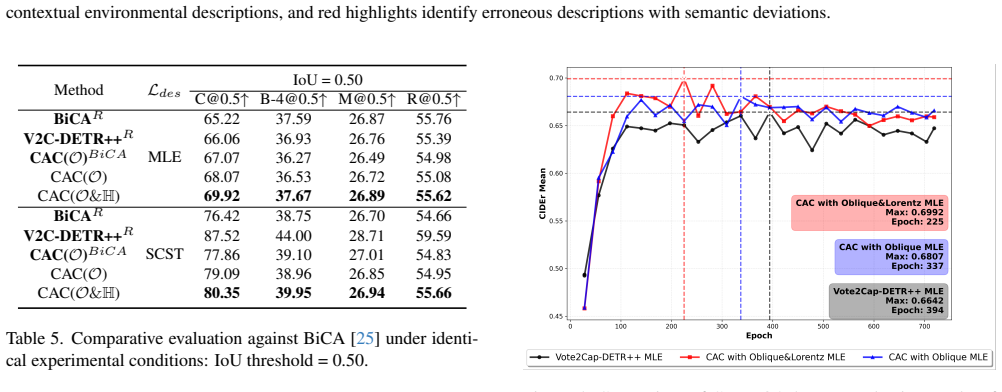
read the original abstract
Accurate 3D scene description is fundamental to robotic navigation and augmented reality, yet current dense captioning methods face significant limitations in processing sparse point cloud data. % Existing approaches that apply Euclidean embedding spaces struggle to simultaneously preserve fine-grained local geometric details and model exponentially growing global semantic hierarchies, leading to either inaccurate localization or disjointed, shallow scene descriptions. % In this work, we propose a novel \textbf{\textsc{Curvature-Aware Captioning}} framework, integrating novel non-Euclidean geodesic attention mechanisms, to resolve the localization-contextualization conflict. % Specifically, self-attention within Oblique space enforces dimensional homogeneity while establishing long-range dependencies. Bidirectional geodesic cross-attention within Lorentz space models hierarchical semantic relationships across scene instances, enabling simultaneous precision in object localization and coherence in scene descriptions. % Theoretical analysis confirms that the curvature complementarity between the Oblique manifold and Lorentz hyperboloid resolves the Euclidean-hyperbolic conflict, ensuring feature stability via isotropic optimization while preserving inherent hierarchical relationships. Extensive experiments on ScanRefer and Nr3D benchmarks demonstrate state-of-the-art performance, with significant gains in both localization accuracy and descriptive richness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a Curvature-Aware Captioning framework for 3D scene understanding on sparse point clouds. It combines self-attention on the Oblique manifold (to enforce dimensional homogeneity and long-range dependencies) with bidirectional geodesic cross-attention on the Lorentz hyperboloid (to model hierarchical semantic relationships). The central claim is that curvature complementarity between these two non-Euclidean spaces resolves the Euclidean-hyperbolic conflict, yielding isotropic optimization, feature stability, and simultaneous gains in localization precision and scene-description coherence. Experiments are reported to achieve state-of-the-art results on the ScanRefer and Nr3D benchmarks.
Significance. If the theoretical complementarity and empirical gains are rigorously established, the work would offer a principled non-Euclidean alternative to standard Euclidean embeddings for dense captioning, potentially improving the balance between local geometry and global hierarchy in 3D vision tasks relevant to robotics and AR.
major comments (3)
- [§3.2] §3.2 (Theoretical Analysis): The assertion that 'curvature complementarity between the Oblique manifold and Lorentz hyperboloid resolves the Euclidean-hyperbolic conflict, ensuring feature stability via isotropic optimization' is presented without an explicit derivation, proof sketch, or stability condition (e.g., no equation showing cancellation of instabilities or the isotropic condition). This is load-bearing for the framework's justification; absent such analysis, the claimed advantage of the geodesic mechanisms over Euclidean baselines remains unverified.
- [§4] §4 (Experiments): The abstract states 'significant gains in both localization accuracy and descriptive richness' and SOTA performance, yet no quantitative results, error bars, ablation tables, or statistical significance tests are referenced in the provided text. Without these, the empirical support for the central claim cannot be assessed.
- [§3.1] §3.1 (Method): The definitions of the geodesic attention mechanisms in Oblique and Lorentz spaces are introduced as novel but lack concrete implementation details (e.g., no explicit formulation of the geodesic distance or attention weight computation) that would allow reproduction or verification of the claimed dimensional homogeneity and hierarchy preservation.
minor comments (2)
- The abstract contains stray LaTeX artifacts ('%') that should be removed for clarity.
- Notation for the Oblique manifold and Lorentz hyperboloid should be introduced consistently with standard references in the non-Euclidean geometry literature.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. We will revise the manuscript to strengthen the theoretical justification, ensure all empirical claims are explicitly supported by referenced results, and provide the missing implementation details for reproducibility.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Theoretical Analysis): The assertion that 'curvature complementarity between the Oblique manifold and Lorentz hyperboloid resolves the Euclidean-hyperbolic conflict, ensuring feature stability via isotropic optimization' is presented without an explicit derivation, proof sketch, or stability condition (e.g., no equation showing cancellation of instabilities or the isotropic condition). This is load-bearing for the framework's justification; absent such analysis, the claimed advantage of the geodesic mechanisms over Euclidean baselines remains unverified.
Authors: We agree that the current presentation of the theoretical analysis would benefit from greater rigor. In the revised manuscript we will expand §3.2 with an explicit derivation, including a proof sketch that shows how the opposing curvatures produce cancellation of instabilities and satisfy the isotropic optimization condition. The new material will contain the relevant equations and a direct comparison to Euclidean baselines. revision: yes
-
Referee: [§4] §4 (Experiments): The abstract states 'significant gains in both localization accuracy and descriptive richness' and SOTA performance, yet no quantitative results, error bars, ablation tables, or statistical significance tests are referenced in the provided text. Without these, the empirical support for the central claim cannot be assessed.
Authors: The full manuscript already reports quantitative results, error bars, ablation tables, and SOTA comparisons in Section 4 and the associated tables. To address the concern, we will add explicit cross-references from the abstract and introduction to these tables and will include statistical significance tests (paired t-tests with p-values) in the revised version. revision: partial
-
Referee: [§3.1] §3.1 (Method): The definitions of the geodesic attention mechanisms in Oblique and Lorentz spaces are introduced as novel but lack concrete implementation details (e.g., no explicit formulation of the geodesic distance or attention weight computation) that would allow reproduction or verification of the claimed dimensional homogeneity and hierarchy preservation.
Authors: We will augment §3.1 with the explicit closed-form expressions for the geodesic distances on both manifolds and the precise formulas used to compute the attention weights. Pseudocode for the bidirectional geodesic cross-attention module will also be added to facilitate reproduction. revision: yes
Circularity Check
No circularity: theoretical claim asserted without reduction to inputs
full rationale
The paper asserts that 'Theoretical analysis confirms that the curvature complementarity between the Oblique manifold and Lorentz hyperboloid resolves the Euclidean-hyperbolic conflict' but provides no equations, derivations, or self-citations in the given text that reduce this confirmation to a fitted parameter, self-definition, or prior author result by construction. The framework introduces Oblique self-attention and Lorentz cross-attention as novel components justified by the claimed complementarity, with performance claims resting on benchmark experiments rather than a closed loop. No load-bearing step exhibits the enumerated circular patterns; the derivation chain remains self-contained against external validation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Oblique manifold and Lorentz hyperboloid possess complementary curvature properties that resolve Euclidean embedding limitations for 3D point clouds
invented entities (1)
-
Geodesic attention mechanisms in Oblique and Lorentz spaces
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theoretical analysis confirms that the curvature complementarity between the Oblique manifold and Lorentz hyperboloid resolves the Euclidean-hyperbolic conflict, ensuring feature stability via isotropic optimization while preserving inherent hierarchical relationships.
-
IndisputableMonolith/Cost/FunctionalEquation.leandAlembert_cosh_solution_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
GHL (x,y) = 1/√c arcosh(−c⟨x,y⟩L)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Joint diagonalization on the oblique manifold for independent component analysis
P-A Absil and Kyle A Gallivan. Joint diagonalization on the oblique manifold for independent component analysis. In2006 IEEE international conference on acoustics speech and signal processing proceedings, pages V–V . IEEE, 2006. 1, 2
work page 2006
-
[2]
Referit3d: Neural listeners for fine-grained 3d object identification in real-world scenes
Panos Achlioptas, Ahmed Abdelreheem, Fei Xia, Mohamed Elhoseiny, and Leonidas Guibas. Referit3d: Neural listeners for fine-grained 3d object identification in real-world scenes. InEuropean conference on computer vision, pages 422–440. Springer, 2020. 6, 7
work page 2020
-
[3]
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Men- sch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736,
-
[4]
Scanqa: 3d question answering for spatial scene understanding
Daichi Azuma, Taiki Miyanishi, Shuhei Kurita, and Motoaki Kawanabe. Scanqa: 3d question answering for spatial scene understanding. Inproceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19129– 19139, 2022. 2
work page 2022
-
[5]
Michael M Bronstein, Joan Bruna, Yann LeCun, Arthur Szlam, and Pierre Vandergheynst. Geometric deep learning: going beyond euclidean data.IEEE Signal Processing Mag- azine, 34(4):18–42, 2017. 1
work page 2017
-
[6]
3djcg: A unified framework for joint dense captioning and visual grounding on 3d point clouds
Daigang Cai, Lichen Zhao, Jing Zhang, Lu Sheng, and Dong Xu. 3djcg: A unified framework for joint dense captioning and visual grounding on 3d point clouds. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16464–16473, 2022. 1, 2, 6
work page 2022
-
[7]
Hyperbolic deep reinforcement learn- ing.arXiv preprint arXiv:2210.01542, 2022
Edoardo Cetin, Benjamin Chamberlain, Michael Bronstein, and Jonathan J Hunt. Hyperbolic deep reinforcement learn- ing.arXiv preprint arXiv:2210.01542, 2022. 2
-
[8]
Scanrefer: 3d object localization in rgb-d scans using natural language
Dave Zhenyu Chen, Angel X Chang, and Matthias Nießner. Scanrefer: 3d object localization in rgb-d scans using natural language. InEuropean conference on computer vision, pages 202–221. Springer, 2020. 2, 6, 7
work page 2020
-
[9]
Scanrefer: 3d object localization in rgb-d scans using natural language
Dave Zhenyu Chen, Angel X Chang, and Matthias Nießner. Scanrefer: 3d object localization in rgb-d scans using natural language. pages 202–221, 2020. 6
work page 2020
-
[10]
D 3 net: A unified speaker-listener architecture for 3d dense captioning and visual grounding
Dave Zhenyu Chen, Qirui Wu, Matthias Nießner, and An- gel X Chang. D 3 net: A unified speaker-listener architecture for 3d dense captioning and visual grounding. InEuropean Conference on Computer Vision, pages 487–505. Springer,
-
[11]
End-to-end 3d dense captioning with vote2cap-detr
Sijin Chen, Hongyuan Zhu, Xin Chen, Yinjie Lei, Gang Yu, and Tao Chen. End-to-end 3d dense captioning with vote2cap-detr. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11124– 11133, 2023. 2, 6
work page 2023
-
[12]
Sijin Chen, Hongyuan Zhu, Mingsheng Li, Xin Chen, Peng Guo, Yinjie Lei, Gang Yu, Taihao Li, and Tao Chen. V ote2cap-detr++: Decoupling localization and describing for end-to-end 3d dense captioning.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(11):7331– 7347, 2024. 1, 2, 4, 5, 6
work page 2024
-
[13]
Executing your commands via motion diffusion in latent space
Xin Chen, Biao Jiang, Wen Liu, Zilong Huang, Bin Fu, Tao Chen, and Gang Yu. Executing your commands via motion diffusion in latent space. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18000–18010, 2023. 1
work page 2023
-
[14]
Scan2cap: Context-aware dense captioning in rgb- d scans
Zhenyu Chen, Ali Gholami, Matthias Nießner, and Angel X Chang. Scan2cap: Context-aware dense captioning in rgb- d scans. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3193–3203,
-
[15]
Unit3d: A unified transformer for 3d dense captioning and visual grounding
Zhenyu Chen, Ronghang Hu, Xinlei Chen, Matthias Nießner, and Angel X Chang. Unit3d: A unified transformer for 3d dense captioning and visual grounding. InProceed- ings of the IEEE/CVF international conference on computer vision, pages 18109–18119, 2023. 1
work page 2023
-
[16]
Scannet: Richly-annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Hal- ber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5828–5839, 2017. 2, 6
work page 2017
-
[17]
Hyper- bolic image-text representations
Karan Desai, Maximilian Nickel, Tanmay Rajpurohit, Justin Johnson, and Shanmukha Ramakrishna Vedantam. Hyper- bolic image-text representations. InInternational Confer- ence on Machine Learning, pages 7694–7731. PMLR, 2023. 4
work page 2023
-
[18]
Hyperbolic entailment cones for learning hierarchical em- beddings
Octavian Ganea, Gary B ´ecigneul, and Thomas Hofmann. Hyperbolic entailment cones for learning hierarchical em- beddings. InInternational conference on machine learning, pages 1646–1655. PMLR, 2018. 2
work page 2018
-
[19]
Ziyang Guo, Anyou Min, Bing Yang, Junhong Chen, Hong Li, and Junbin Gao. A sparse oblique-manifold nonnega- tive matrix factorization for hyperspectral unmixing.IEEE Transactions on Geoscience and Remote Sensing, 60:1–13,
-
[20]
Jakob Hedicke. Lorentzian distance functions in contact ge- ometry.Journal of Topology and Analysis, 16(02):205–225,
-
[21]
Pointgroup: Dual-set point grouping for 3d instance segmentation
Li Jiang, Hengshuang Zhao, Shaoshuai Shi, Shu Liu, Chi- Wing Fu, and Jiaya Jia. Pointgroup: Dual-set point grouping for 3d instance segmentation. InProceedings of the IEEE/CVF conference on computer vision and Pattern recognition, pages 4867–4876, 2020. 2
work page 2020
-
[22]
More: Multi-order relation mining for dense captioning in 3d scenes
Yang Jiao, Shaoxiang Chen, Zequn Jie, Jingjing Chen, Lin Ma, and Yu-Gang Jiang. More: Multi-order relation mining for dense captioning in 3d scenes. InEuropean Conference on Computer Vision, pages 528–545. Springer, 2022. 1, 2, 6
work page 2022
-
[23]
Context-aware alignment and mutual masking for 3d- language pre-training
Zhao Jin, Munawar Hayat, Yuwei Yang, Yulan Guo, and Yin- jie Lei. Context-aware alignment and mutual masking for 3d- language pre-training. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 10984–10994, 2023. 2, 6
work page 2023
-
[24]
Valentin Khrulkov, Leyla Mirvakhabova, Evgeniya Usti- nova, Ivan Oseledets, and Victor Lempitsky. Hyperbolic image embeddings. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 6418–6428, 2020. 2
work page 2020
-
[25]
Bi-directional contextual attention for 3d dense captioning
Minjung Kim, Hyung Suk Lim, Soonyoung Lee, Bumsoo Kim, and Gunhee Kim. Bi-directional contextual attention for 3d dense captioning. InEuropean Conference on Com- puter Vision, pages 385–401. Springer, 2024. 1, 7, 8
work page 2024
-
[26]
Wonjae Kim, Sanghyuk Chun, Taekyung Kim, Dongyoon Han, and Sangdoo Yun. Hype: Hyperbolic entailment fil- tering for underspecified images and texts.arXiv preprint arXiv:2404.17507, 2024. 3
-
[27]
arXiv preprint arXiv:2506.16504 , year=
Zeqiang Lai, Yunfei Zhao, Haolin Liu, Zibo Zhao, Qingxi- ang Lin, Huiwen Shi, Xianghui Yang, Mingxin Yang, Shuhui Yang, Yifei Feng, et al. Hunyuan3d 2.5: Towards high- fidelity 3d assets generation with ultimate details.arXiv preprint arXiv:2506.16504, 2025. 1
-
[28]
Zhengyu Li, Xuan Tang, Zihao Xu, Xihao Wang, Hui Yu, Mingsong Chen, et al. Geodesic self-attention for 3d point clouds.Advances in Neural Information Processing Systems, 35:6190–6203, 2022. 2
work page 2022
-
[29]
Zhi-Hao Lin, Sheng-Yu Huang, and Yu-Chiang Frank Wang. Learning of 3d graph convolution networks for point cloud analysis.IEEE Transactions on Pattern Analysis and Ma- chine Intelligence, 44(8):4212–4224, 2021. 1
work page 2021
-
[30]
Application of hyperbolic space attention mechanisms in 3d point cloud classification
Lamei Liu and Zhiqiang Liu. Application of hyperbolic space attention mechanisms in 3d point cloud classification. In2024 6th International Conference on Communications, Information System and Computer Engineering, pages 658–
-
[31]
Chuanjiang Long, Zhen Dong, Keqiang Wang, Feng Yu, Chaobin He, and Zhong-Ren Chen. Molecular weight distribution shape approach for simultaneously enhancing the stiffness, ductility and strength of isotropic semicrys- talline polymers based on linear unimodal and bimodal polyethylenes.Polymer, 275:125936, 2023. 4
work page 2023
-
[32]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 6
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[33]
Aihua Mao, Zhi Yang, Wanxin Chen, Ran Yi, and Yong-jin Liu. Complete 3d relationships extraction modality align- ment network for 3d dense captioning.IEEE Transactions on Visualization and Computer Graphics, 30(8):4867–4880,
-
[34]
An end-to- end transformer model for 3d object detection
Ishan Misra, Rohit Girdhar, and Armand Joulin. An end-to- end transformer model for 3d object detection. InProceed- ings of the IEEE/CVF international conference on computer vision, pages 2906–2917, 2021. 2, 4, 5
work page 2021
-
[35]
Antonio Montanaro, Diego Valsesia, and Enrico Magli. Re- thinking the compositionality of point clouds through regu- larization in the hyperbolic space.Advances in Neural Infor- mation Processing Systems, 35:33741–33753, 2022. 2
work page 2022
-
[36]
Efficient non- maximum suppression
Alexander Neubeck and Luc Van Gool. Efficient non- maximum suppression. In18th international conference on pattern recognition, pages 850–855. IEEE, 2006. 6
work page 2006
-
[37]
Maximillian Nickel and Douwe Kiela. Poincar ´e embeddings for learning hierarchical representations.Advances in neural information processing systems, 30, 2017. 2
work page 2017
-
[38]
PyTorch: An Imperative Style, High-Performance Deep Learning Library
A Paszke. Pytorch: An imperative style, high-performance deep learning library.arXiv preprint arXiv:1912.01703,
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[39]
Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space.Advances in neural information processing systems, 30, 2017. 2, 4
work page 2017
-
[40]
Transductive few-shot classification on the oblique manifold
Guodong Qi, Huimin Yu, Zhaohui Lu, and Shuzhao Li. Transductive few-shot classification on the oblique manifold. InProceedings of the IEEE/CVF international conference on computer vision, pages 8412–8422, 2021. 1, 2
work page 2021
-
[41]
Accept the modality gap: An exploration in the hyperbolic space
Sameera Ramasinghe, Violetta Shevchenko, Gil Avraham, and Ajanthan Thalaiyasingam. Accept the modality gap: An exploration in the hyperbolic space. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27263–27272, 2024. 3
work page 2024
-
[42]
Self-critical sequence training for image captioning
Steven J Rennie, Etienne Marcheret, Youssef Mroueh, Jerret Ross, and Vaibhava Goel. Self-critical sequence training for image captioning. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 7008–7024,
-
[43]
Ryohei Shimizu, YUSUKE Mukuta, and Tatsuya Harada. Hyperbolic neural networks++. InInternational Conference on Learning Representations, 2021. 3
work page 2021
-
[44]
Cider: Consensus-based image description evalua- tion
Ramakrishna Vedantam, C Lawrence Zitnick, and Devi Parikh. Cider: Consensus-based image description evalua- tion. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4566–4575, 2015. 6
work page 2015
-
[46]
Heng Wang, Chaoyi Zhang, Jianhui Yu, and Weidong Cai. Spatiality-guided transformer for 3d dense captioning on point clouds.arXiv preprint arXiv:2204.10688, 2022. 1, 2
-
[47]
Hypliloc: Towards effective lidar pose regression with hyperbolic fusion
Sijie Wang, Qiyu Kang, Rui She, Wei Wang, Kai Zhao, Yang Song, and Wee Peng Tay. Hypliloc: Towards effective lidar pose regression with hyperbolic fusion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5176–5185, 2023. 2
work page 2023
-
[48]
Yifan Xie, Jihua Zhu, Shiqi Li, Naiwen Hu, and Pengcheng Shi. Hecpg: Hyperbolic embedding and confident patch- guided network for point cloud matching.IEEE Transactions on Geoscience and Remote Sensing, 62:1–12, 2024. 2
work page 2024
-
[49]
Hypformer: Exploring effi- cient transformer fully in hyperbolic space
Menglin Yang, Harshit Verma, Delvin Ce Zhang, Jiahong Liu, Irwin King, and Rex Ying. Hypformer: Exploring effi- cient transformer fully in hyperbolic space. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Dis- covery and Data Mining, pages 3770–3781, 2024. 2
work page 2024
-
[50]
Shuquan Ye, Dongdong Chen, Songfang Han, and Jing Liao. 3d question answering.IEEE Transactions on Visualization and Computer Graphics, 30(3):1772–1786, 2022. 2
work page 2022
-
[51]
X-trans2cap: Cross- modal knowledge transfer using transformer for 3d dense captioning
Zhihao Yuan, Xu Yan, Yinghong Liao, Yao Guo, Guan- bin Li, Shuguang Cui, and Zhen Li. X-trans2cap: Cross- modal knowledge transfer using transformer for 3d dense captioning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8563– 8573, 2022. 2, 6
work page 2022
-
[52]
Hype-han: Hyperbolic hierarchical attention network for semantic embedding
Chengkun Zhang and Junbin Gao. Hype-han: Hyperbolic hierarchical attention network for semantic embedding. In Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence, pages 3990–3996, 2021. 1
work page 2021
-
[53]
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
Hao Zhang, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel M Ni, and Heung-Yeung Shum. Dino: Detr with improved denoising anchor boxes for end-to-end object detection.arXiv preprint arXiv:2203.03605, 2022. 5
work page internal anchor Pith review arXiv 2022
-
[54]
Wang Zhao, Yan-Pei Cao, Jiale Xu, Yuejiang Dong, and Ying Shan. Assembler: Scalable 3d part assembly via anchor point diffusion.arXiv preprint arXiv:2506.17074, 2025. 1
-
[55]
Contextual modeling for 3d dense captioning on point clouds.arXiv preprint arXiv:2210.03925, 2022
Yufeng Zhong, Long Xu, Jiebo Luo, and Lin Ma. Contextual modeling for 3d dense captioning on point clouds.arXiv preprint arXiv:2210.03925, 2022. 6
-
[56]
Deformable DETR: Deformable Transformers for End-to-End Object Detection
Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable detr: Deformable trans- formers for end-to-end object detection.arXiv preprint arXiv:2010.04159, 2020. 5
work page internal anchor Pith review Pith/arXiv arXiv 2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.