Recognition: 2 theorem links
· Lean TheoremFundamental Trade-Offs in Multi-Bit Watermarking of Stochastic Processes
Pith reviewed 2026-05-12 01:28 UTC · model grok-4.3
The pith
Matched converse and achievability bounds characterize the optimal trade-offs in multi-bit watermarking of stochastic processes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
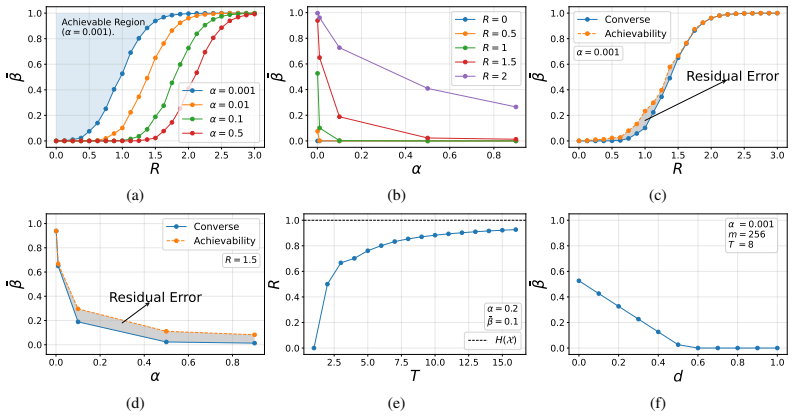
By casting watermark embedding as distributional information embedding and detection as multiple hypothesis testing under explicit distortion and rate constraints, the paper derives matched converse and achievability bounds that fully characterize the optimal trade-offs among false-alarm probability, detection error probability, distortion, and information rate for watermarking stochastic processes.
What carries the argument
The distributional information-embedding problem paired with multiple-hypothesis testing under distortion and rate constraints, which yields the four fundamental metrics and their trade-off bounds.
If this is right
- Any valid watermarking scheme must respect the converse bounds on the four metrics.
- The achievability bounds demonstrate that the limits are tight and attainable by some constructions.
- For stationary ergodic processes, the asymptotic limits provide benchmarks as the sample size grows.
- The reference construction empirically confirms the predicted trade-offs in practice.
Where Pith is reading between the lines
- These bounds could help set practical parameters for watermarking in generative models like language models without relying on specific embedding techniques.
- Extensions might consider non-stationary processes or finite-blocklength refinements beyond the asymptotic regime.
- Similar frameworks could apply to related problems in data hiding or steganography with multiple bits.
Load-bearing premise
That watermark embedding can be precisely captured as a distributional information-embedding problem and detection as multiple-hypothesis testing, with the processes being stationary and ergodic for the asymptotic results.
What would settle it
A concrete counterexample would be a watermarking scheme for a stationary ergodic process that achieves a combination of false-alarm rate, detection error, distortion, and rate violating one of the derived converse bounds.
Figures

read the original abstract
We study multi-bit watermarking for data generated by stochastic processes, where a hidden message is embedded during sampling and must be decodable by an authorized detector that possesses side information unavailable to unauthorized observers. In high-stakes deployments, a practical watermark must simultaneously control false alarms, preserve generation quality without distorting the output distribution, and support reliable multi-bit decoding. Satisfying all three goals at once inevitably creates fundamental trade-offs. We formulate watermark embedding as a distributional information-embedding problem and watermark detection as a multiple-hypothesis testing problem under distortion and rate constraints, leading to four fundamental metrics: false-alarm probability, detection error probability, distortion, and information rate. Within this information-theoretic framework, we derive matched converse and achievability bounds that characterize the optimal trade-offs and provide scheme-agnostic benchmarks for any watermarking method. For stationary ergodic stochastic processes, we further obtain matched asymptotic limits and connect them to the finite-sample regime. Finally, we present a reference watermarking construction satisfying our assumptions and empirically illustrating the predicted trade-offs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies multi-bit watermarking for stochastic processes by modeling embedding as a distributional information-embedding problem and detection as multiple-hypothesis testing under distortion and rate constraints. It derives matched converse and achievability bounds characterizing optimal trade-offs among false-alarm probability, detection error probability, distortion, and information rate. For stationary ergodic processes, it obtains matched asymptotic limits connected to the finite-sample regime and presents a reference construction that empirically illustrates the trade-offs.
Significance. If the matched bounds are rigorously established, the work supplies scheme-agnostic benchmarks for watermarking methods, which is a valuable contribution to the information-theoretic analysis of watermarking. The asymptotic-to-finite-sample connection and the reference construction that satisfies the modeling assumptions provide concrete strengths that can guide practical designs.
major comments (1)
- Abstract: the central claim that the bounds 'provide scheme-agnostic benchmarks for any watermarking method' is qualified by the stationarity and ergodicity requirement. Without ergodicity the asymptotic rate-distortion and error-exponent limits generally fail to exist or match, so the scheme-agnostic character of the trade-off surface does not automatically extend to the non-ergodic processes that arise in many practical deployments. The manuscript should either restrict the scope of the claim or supply a concrete argument showing why the finite-sample connection remains meaningful outside the ergodic class.
minor comments (1)
- Abstract: the four fundamental metrics are introduced only after the modeling step; naming them explicitly (false-alarm probability, detection error probability, distortion, information rate) at the first mention would improve readability.
Simulated Author's Rebuttal
We thank the referee for the careful review and the suggestion to clarify the scope of our claims. We address the major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: Abstract: the central claim that the bounds 'provide scheme-agnostic benchmarks for any watermarking method' is qualified by the stationarity and ergodicity requirement. Without ergodicity the asymptotic rate-distortion and error-exponent limits generally fail to exist or match, so the scheme-agnostic character of the trade-off surface does not automatically extend to the non-ergodic processes that arise in many practical deployments. The manuscript should either restrict the scope of the claim or supply a concrete argument showing why the finite-sample connection remains meaningful outside the ergodic class.
Authors: We agree that the scheme-agnostic benchmarks and matched asymptotic limits are derived under the assumptions of stationarity and ergodicity. The abstract phrasing could be read more broadly than intended. We will revise the abstract to explicitly qualify the claim as applying to stationary ergodic processes (e.g., 'provide scheme-agnostic benchmarks for any watermarking method of stationary ergodic stochastic processes'), consistent with the body of the paper. We do not supply an argument for non-ergodic cases, as establishing the relevant limits outside ergodicity would require substantial new analysis beyond the current scope. revision: yes
Circularity Check
Standard information-theoretic derivation with no circularity
full rationale
The paper formulates watermarking as a distributional information-embedding problem and detection as multiple-hypothesis testing, then derives matched converse and achievability bounds under explicit stationarity and ergodicity assumptions for the asymptotic limits. These are standard technical conditions in information theory that enable the existence of rate-distortion and error-exponent limits via the ergodic theorem; they are stated upfront rather than smuggled in. No equations reduce by construction to fitted parameters, self-definitions, or load-bearing self-citations. The reference construction is presented as satisfying the model assumptions but does not serve as the sole justification for the bounds themselves. The derivation chain is self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Stochastic processes under study are stationary and ergodic.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe formulate watermark embedding as a distributional information-embedding problem and watermark detection as a multiple-hypothesis testing problem under distortion and rate constraints... For stationary ergodic stochastic processes, we further obtain matched asymptotic limits
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearTheorem 4... R ≤ max_{P: D_KL(P∥Q)≤d} H_P(X)
Reference graph
Works this paper leans on
- [1]
-
[2]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[3]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Eguchi, Po - Ssu Huang, and Richard Socher
Ali Madani, Bryan McCann, Nikhil Naik, Nitish Shirish Keskar, Namrata Anand, Raphael R Eguchi, Po-Ssu Huang, and Richard Socher. Progen: Language modeling for protein generation. arXiv preprint arXiv:2004.03497, 2020
-
[5]
Dustin Tran, Rajesh Ranganath, and David Blei. Hierarchical implicit models and likelihood- free variational inference.Advances in Neural Information Processing Systems, 30, 2017
work page 2017
-
[6]
Machine learning for synthetic data generation: a review.arXiv preprint arXiv:2302.04062, 2023
Yingzhou Lu, Lulu Chen, Yuanyuan Zhang, Minjie Shen, Huazheng Wang, Xiao Wang, Ca- pucine van Rechem, Tianfan Fu, and Wenqi Wei. Machine learning for synthetic data generation: a review.arXiv preprint arXiv:2302.04062, 2023
-
[7]
A watermark for large language models
John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, and Tom Goldstein. A watermark for large language models. InInternational Conference on Machine Learning, pages 17061–17084. PMLR, 2023
work page 2023
-
[8]
Provable robust watermarking for AI-generated text.arXiv preprint arXiv:2306.17439, 2023
Xuandong Zhao, Prabhanjan Ananth, Lei Li, and Yu-Xiang Wang. Provable robust watermarking for AI-generated text.arXiv preprint arXiv:2306.17439, 2023
-
[9]
Adaptive text watermark for large language models
Yepeng Liu and Yuheng Bu. Adaptive text watermark for large language models. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[10]
Scalable watermarking for identifying large language model outputs.Nature, 634(8035):818–823, 2024
Sumanth Dathathri, Abigail See, Sumedh Ghaisas, Po-Sen Huang, Rob McAdam, Johannes Welbl, Vandana Bachani, Alex Kaskasoli, Robert Stanforth, Tatiana Matejovicova, et al. Scalable watermarking for identifying large language model outputs.Nature, 634(8035):818–823, 2024
work page 2024
-
[11]
Robust distortion- free watermarks for language models.arXiv preprint arXiv:2307.15593, 2023
Rohith Kuditipudi, John Thickstun, Tatsunori Hashimoto, and Percy Liang. Robust distortion- free watermarks for language models.arXiv preprint arXiv:2307.15593, 2023
-
[12]
Advancing beyond identification: Multi- bit watermark for large language models
KiYoon Yoo, Wonhyuk Ahn, and Nojun Kwak. Advancing beyond identification: Multi- bit watermark for large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 4031–4055, 2024
work page 2024
-
[13]
Watermarking language models for many adaptive users
Aloni Cohen, Alexander Hoover, and Gabe Schoenbach. Watermarking language models for many adaptive users. In2025 IEEE Symposium on Security and Privacy (SP), pages 2583–2601. IEEE, 2025
work page 2025
-
[14]
Provably robust multi-bit watermarking for {AI-generated} text
Wenjie Qu, Wengrui Zheng, Tianyang Tao, Dong Yin, Yanze Jiang, Zhihua Tian, Wei Zou, Jinyuan Jia, and Jiaheng Zhang. Provably robust multi-bit watermarking for {AI-generated} text. In34th USENIX Security Symposium (USENIX Security 25), pages 201–220, 2025
work page 2025
-
[15]
Optimal Multi-bit Generative Watermarking Schemes Under Worst-Case False-Alarm Constraints
Yu-Shin Huang, Chao Tian, and Krishna Narayanan. Optimal multi-bit generative watermarking schemes under worst-case false-alarm constraints, 2026. URL https://arxiv.org/abs/ 2604.08759
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Watermarking for large language models: A survey.Mathematics, 13(9):1420, 2025
Zhiguang Yang, Gejian Zhao, and Hanzhou Wu. Watermarking for large language models: A survey.Mathematics, 13(9):1420, 2025
work page 2025
-
[17]
Haiyun He, Yepeng Liu, Ziqiao Wang, Yongyi Mao, and Yuheng Bu. Distributional information embedding: A framework for multi-bit watermarking.arXiv preprint arXiv:2501.16558, 2025
-
[18]
Massieh Kordi Boroujeny, Ya Jiang, Kai Zeng, and Brian Mark. Multi-bit distortion-free watermarking for large language models.arXiv preprint arXiv:2402.16578, 2024. 11
-
[19]
P. Moulin and J.A. O’Sullivan. Information-theoretic analysis of watermarking. In2000 IEEE International Conference on Acoustics, Speech, and Signal Processing. Proceedings (Cat. No.00CH37100), volume 6, pages 3630–3633 vol.6, 2000. doi: 10.1109/ICASSP.2000.860188
-
[20]
Theoretically grounded framework for LLM watermarking: A distribution-adaptive approach
Haiyun He, Yepeng Liu, Ziqiao Wang, Yongyi Mao, and Yuheng Bu. Theoretically grounded framework for LLM watermarking: A distribution-adaptive approach. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[21]
Neri Merhav and Erez Sabbag. Optimal watermark embedding and detection strategies under limited detection resources.IEEE Transactions on Information Theory, 54(1):255–274, 2008. doi: 10.1109/TIT.2007.911210
-
[22]
Capacity of steganographic channels.IEEE Transactions on Information Theory, 55(4):1775–1792, 2009
Jeremiah J Harmsen and William A Pearlman. Capacity of steganographic channels.IEEE Transactions on Information Theory, 55(4):1775–1792, 2009
work page 2009
-
[23]
Aiwei Liu, Leyi Pan, Yijian Lu, Jingjing Li, Xuming Hu, Xi Zhang, Lijie Wen, Irwin King, Hui Xiong, and Philip Yu. A survey of text watermarking in the era of large language models.ACM Computing Surveys, 57(2):1–36, 2024
work page 2024
-
[24]
Position: LLM Watermarking Should Align Stakeholders' Incentives for Practical Adoption
Yepeng Liu, Xuandong Zhao, Dawn Song, Gregory W Wornell, and Yuheng Bu. Position: Llm watermarking should align stakeholders’ incentives for practical adoption.arXiv preprint arXiv:2510.18333, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Sok: Watermarking for ai-generated content, 2024
Xuandong Zhao, Sam Gunn, Miranda Christ, Jaiden Fairoze, Andres Fabrega, Nicholas Carlini, Sanjam Garg, Sanghyun Hong, Milad Nasr, Florian Tramer, et al. Sok: Watermarking for ai-generated content, 2024
work page 2024
-
[26]
Erasing the invisible: A stress-test challenge for image watermarks
Mucong Ding, Tahseen Rabbani, Bang An, Souradip Chakraborty, Chenghao Deng, Mehrdad Saberi, Yuxin Wen, Xuandong Zhao, Mo Zhou, Anirudh Satheesh, et al. Erasing the invisible: A stress-test challenge for image watermarks. InNeurIPS 2024 Competition Track, 2024
work page 2024
-
[27]
Yepeng Liu, Yiren Song, Hai Ci, Yu Zhang, Haofan Wang, Mike Zheng Shou, and Yuheng Bu. Image watermarks are removable using controllable regeneration from clean noise.arXiv preprint arXiv:2410.05470, 2024
-
[28]
Siqi Hui, Yiren Song, Sanping Zhou, Ye Deng, Wenli Huang, and Jinjun Wang. Autoregressive images watermarking through lexical biasing: An approach resistant to regeneration attack. arXiv preprint arXiv:2506.01011, 2025
-
[29]
Enhancing privacy in biosecurity with watermarked protein design.Bioinformatics, page btaf141, 2025
Yanshuo Chen, Zhengmian Hu, Yihan Wu, Ruibo Chen, Yongrui Jin, Marcus Zhan, Chengjin Xie, Wei Chen, and Heng Huang. Enhancing privacy in biosecurity with watermarked protein design.Bioinformatics, page btaf141, 2025
work page 2025
-
[30]
Yepeng Liu, Xuandong Zhao, Dawn Song, and Yuheng Bu. Dataset protection via watermarked canaries in retrieval-augmented llms.arXiv preprint arXiv:2502.10673, 2025
-
[31]
Xiaojun Xu, Yuanshun Yao, and Yang Liu. Learning to watermark llm-generated text via reinforcement learning.arXiv preprint arXiv:2403.10553, 2024
-
[32]
Protecting language generation models via invisible watermarking
Xuandong Zhao, Yu-Xiang Wang, and Lei Li. Protecting language generation models via invisible watermarking. InInternational Conference on Machine Learning, pages 42187–42199. PMLR, 2023
work page 2023
-
[33]
In-Context Watermarks for Large Language Models
Yepeng Liu, Xuandong Zhao, Christopher Kruegel, Dawn Song, and Yuheng Bu. In-context watermarks for large language models.arXiv preprint arXiv:2505.16934, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Watermarking language models through language models.arXiv preprint arXiv:2411.05091, 2024
Agnibh Dasgupta, Abdullah Tanvir, and Xin Zhong. Watermarking language models through language models.arXiv preprint arXiv:2411.05091, 2024
-
[35]
Li An, Yujian Liu, Yepeng Liu, Yang Zhang, Yuheng Bu, and Shiyu Chang. Defending llm watermarking against spoofing attacks with contrastive representation learning.arXiv preprint arXiv:2504.06575, 2025. 12
-
[36]
Li An, Yujian Liu, Yepeng Liu, Yuheng Bu, Yang Zhang, and Shiyu Chang. A reinforcement learning framework for robust and secure llm watermarking.arXiv preprint arXiv:2510.21053, 2025
-
[37]
Postmark: A robust blackbox watermark for large language models
Yapei Chang, Kalpesh Krishna, Amir Houmansadr, John Frederick Wieting, and Mohit Iyyer. Postmark: A robust blackbox watermark for large language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 8969–8987, 2024
work page 2024
-
[38]
Robust Spectral Watermark for Synthetic Tabular Data
Yizhou Zhao, Xiang Li, Peter Song, Qi Long, and Weijie Su. Tab-drw: A dft-based robust watermark for generative tabular data.arXiv preprint arXiv:2511.21600, 2025
work page internal anchor Pith review arXiv 2025
-
[39]
T Tony Cai, Xiang Li, Qi Long, Weijie J Su, and Garrett G Wen. Optimal detection for language watermarks with pseudorandom collision.arXiv preprint arXiv:2510.22007, 2025
-
[40]
Xiang Li, Feng Ruan, Huiyuan Wang, Qi Long, and Weijie J Su. Robust detection of watermarks for large language models under human edits.Journal of the Royal Statistical Society Series B: Statistical Methodology, page qkaf056, 2025
work page 2025
-
[41]
Weiqing He, Xiang Li, Tianqi Shang, Li Shen, Weijie Su, and Qi Long. On the empirical power of goodness-of-fit tests in watermark detection.arXiv preprint arXiv:2510.03944, 2025
-
[42]
Xiang Li, Garrett Wen, Weiqing He, Jiayuan Wu, Qi Long, and Weijie J Su. Optimal estimation of watermark proportions in hybrid ai-human texts.arXiv preprint arXiv:2506.22343, 2025
-
[43]
Xiang Li, Feng Ruan, Huiyuan Wang, Qi Long, and Weijie J Su. A statistical framework of watermarks for large language models: Pivot, detection efficiency and optimal rules.The Annals of Statistics, 53(1):322–351, 2025
work page 2025
-
[44]
Heavywater and simplexwater: Distortion-free llm watermarks for low-entropy distributions
Dor Tsur, Carol Xuan Long, Claudio Mayrink Verdun, Sajani Vithana, Hsiang Hsu, Chun-Fu Chen, Haim H Permuter, and Flavio Calmon. Heavywater and simplexwater: Distortion-free llm watermarks for low-entropy distributions. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[45]
Baihe Huang, Banghua Zhu, Hanlin Zhu, Jason D Lee, Jiantao Jiao, and Michael I Jordan. Towards optimal statistical watermarking.arXiv preprint arXiv:2312.07930, 2023
-
[46]
Lee, Kannan Ramchandran, Michael Jordan, and Jiantao Jiao
Baihe Huang, Hanlin Zhu, Julien Piet, Banghua Zhu, Jason D. Lee, Kannan Ramchandran, Michael Jordan, and Jiantao Jiao. Watermarking using semantic-aware speculative sam- pling: from theory to practice, 2025. URL https://openreview.net/forum?id= LdIlnsePNt
work page 2025
-
[47]
Pseudorandom error-correcting codes
Miranda Christ and Sam Gunn. Pseudorandom error-correcting codes. InAnnual International Cryptology Conference, pages 325–347. Springer, 2024
work page 2024
-
[48]
The Coding Limits of Robust Watermarking for Generative Models
Danilo Francati, Yevin Nikhel Goonatilake, Shubham Pawar, Daniele Venturi, and Giuseppe Ateniese. The coding limits of robust watermarking for generative models.arXiv preprint arXiv:2509.10577, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Where am i from? identifying origin of llm-generated content
Liying Li, Yihan Bai, and Minhao Cheng. Where am i from? identifying origin of llm-generated content. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 12218–12229, 2024
work page 2024
-
[50]
Haoyu Jiang, Xuhong Wang, Ping Yi, Shanzhe Lei, and Yilun Lin. Credid: Credible multi-bit watermark for large language models identification.arXiv preprint arXiv:2412.03107, 2024
-
[51]
Robust multi-bit text watermark with llm-based paraphrasers.arXiv preprint arXiv:2412.03123,
Xiaojun Xu, Jinghan Jia, Yuanshun Yao, Yang Liu, and Hang Li. Robust multi-bit text watermark with llm-based paraphrasers.arXiv preprint arXiv:2412.03123, 2024
-
[52]
Undetectable steganography for language models.Transactions on Machine Learning Research, 2024
Or Zamir. Undetectable steganography for language models.Transactions on Machine Learning Research, 2024
work page 2024
-
[53]
An undetectable watermark for generative image models.arXiv preprint arXiv:2410.07369, 2024
Sam Gunn, Xuandong Zhao, and Dawn Song. An undetectable watermark for generative image models.arXiv preprint arXiv:2410.07369, 2024. 13
-
[54]
Watermarking of large language models
Scott Aaronson. Watermarking of large language models. https://simons.berkeley. edu/talks/scott-aaronson-ut-austin-openai-2023-08-17 , 2023. Ac- cessed: 2023-08
work page 2023
-
[55]
Gumbel.Statistical Theory of Extreme Values and Some Practical Applications: A Series of Lectures
E.J. Gumbel.Statistical Theory of Extreme Values and Some Practical Applications: A Series of Lectures. Applied mathematics series. U.S. Government Printing Office, 1954. URL https://books.google.com/books?id=SNpJAAAAMAAJ. 14 A Related Works Watermarking techniques have been widely explored across various stochastic processes, including text [ 23–25], ima...
work page 1954
-
[56]
proposes a theoretical framework that jointly optimizes the watermarking scheme and detector, showing that watermarks should be adaptive to the LLM’s output distribution to achieve the best detectability–distortion trade-off. Li et al. [43] casts LLM watermark detection as hypothesis testing with pivotal statistics, providing provable Type-I error control...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.