Recognition: no theorem link
VECTOR-Drive: Tightly Coupled Vision-Language and Trajectory Expert Routing for End-to-End Autonomous Driving
Pith reviewed 2026-05-12 01:44 UTC · model grok-4.3
The pith
By routing tokens to separate vision-language and trajectory experts while sharing self-attention, VECTOR-DRIVE resolves the coupling trade-off in vision-language-action models for autonomous driving.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
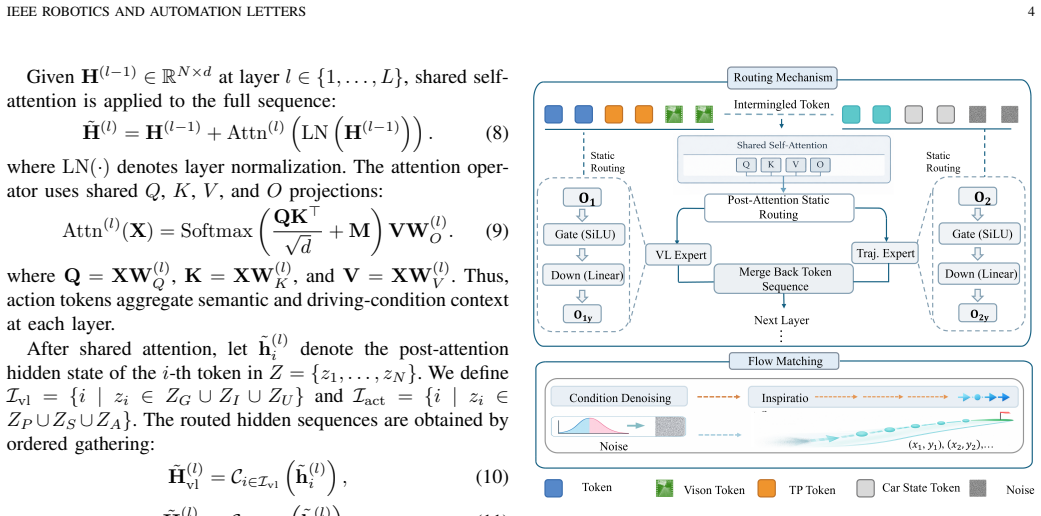
VECTOR-DRIVE keeps all tokens coupled through shared self-attention and routes feed-forward computation according to token semantics. Vision and language tokens are processed by a Vision-Language Expert to preserve semantic priors, while target-point, ego-state, and noisy action tokens are routed to a Trajectory Expert for motion-specific computation. On the action-token pathway, a flow-matching planner refines noisy action tokens into future waypoints and speed profiles. This design couples semantic reasoning and motion planning within a single multimodal Transformer while separating task-specific FFN computation, delivering an 88.91 Driving Score on Bench2Drive.
What carries the argument
Semantic-aware expert routing inside a shared-attention Transformer, with a Vision-Language Expert for vision and language tokens and a Trajectory Expert for motion tokens, plus flow-matching on the action pathway.
If this is right
- Semantic priors from vision-language pretraining remain intact while motion-specific computation occurs without entanglement.
- Task conflicts between language reasoning and trajectory prediction decrease because only the feed-forward layers are specialized.
- Progressive training combined with flow-based action decoding produces smoother and more accurate waypoints and speed profiles.
- Shared attention plus semantic routing outperforms both fully shared backbones and decoupled reasoning-action pipelines on the benchmark.
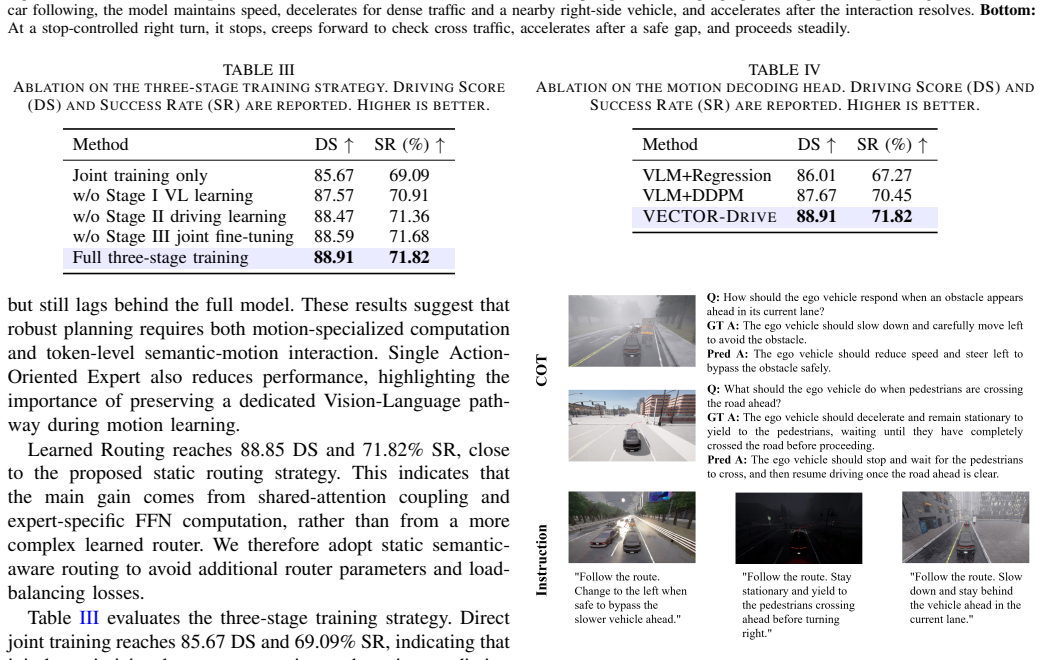
- Ablation studies isolate the contribution of each component, confirming that removing any one reduces overall driving performance.
Where Pith is reading between the lines
- The same partial-decoupling pattern could apply to other multimodal control problems where high-level semantics must inform low-level actions without full specialization.
- Dynamic routing that adapts expert choice to scene complexity rather than fixed token categories might further reduce conflicts in varied driving conditions.
- Scaling the underlying vision-language backbone while retaining this routing structure could improve generalization to unseen environments without retraining the entire model.
Load-bearing premise
That routing only the feed-forward networks by token semantics while keeping all self-attention shared is sufficient to preserve necessary multimodal interactions without introducing task conflicts or information loss.
What would settle it
An ablation that removes the expert routing, replaces it with a single shared feed-forward network for every token, and measures no drop or even an increase in the 88.91 Driving Score on the same Bench2Drive evaluation would falsify the value of the separation.
Figures



read the original abstract
End-to-end autonomous driving requires models to understand traffic scenes, infer driving intent, and generate executable motion plans. Recent vision-language-action (VLA) models inherit semantic priors from large-scale vision-language pretraining, yet still face a coupling trade-off: fully shared backbones preserve multimodal interaction but may entangle language reasoning and trajectory prediction, whereas decou pled reasoning-action pipelines reduce task conflict but weaken semantic-motion coupling. We propose VECTOR-DRIVE, a tightly coupled VLA framework built on Qwen2.5-VL-3B. VECTOR-DRIVE keeps all tokens coupled through shared self attention and routes feed-forward computation according to token semantics. Vision and language tokens are processed by a Vision-Language Expert to preserve semantic priors, while target-point, ego-state, and noisy action tokens are routed to a Trajectory Expert for motion-specific computation. On the action-token pathway, a flow-matching planner refines noisy action tokens into future waypoints and speed profiles. This design couples semantic reasoning and motion planning within a single multimodal Transformer while separating task-specific FFN computation. On Bench2Drive, VECTOR-DRIVE achieves 88.91 Driving Score and outperforms representative end-to end and VLA-based baselines. Qualitative results and ablations further validate the benefits of shared attention, semantic-aware expert routing, progressive training, and flow-based action de coding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces VECTOR-DRIVE, a tightly coupled vision-language-action (VLA) framework for end-to-end autonomous driving built on Qwen2.5-VL-3B. All tokens remain coupled through shared self-attention, while feed-forward network computation is routed by token semantics: vision and language tokens use a Vision-Language Expert to retain semantic priors, and target-point, ego-state, and noisy action tokens use a Trajectory Expert for motion-specific processing. A flow-matching planner decodes the action tokens into future waypoints and speed profiles. The central claim is an 88.91 Driving Score on Bench2Drive that outperforms representative end-to-end and VLA baselines, supported by ablations on shared attention, semantic routing, progressive training, and flow-based decoding.
Significance. If the reported benchmark result holds under rigorous scrutiny, the architecture provides a concrete mechanism for preserving multimodal coupling while mitigating task conflict in VLA models for autonomous driving. The combination of shared self-attention with semantic-aware expert routing, together with flow-matching action decoding, offers a middle path between fully shared backbones and fully decoupled pipelines. The ablations directly test each design choice and appear internally consistent with the stated goals, which strengthens the contribution if the empirical evidence is made reproducible.
major comments (1)
- The experimental evaluation reports an 88.91 Driving Score on Bench2Drive and outperformance over baselines, yet supplies no details on baseline implementations, exact metric definitions and computation, statistical significance testing, data splits, or potential confounds. This absence is load-bearing for the central empirical claim and prevents verification of the result.
minor comments (2)
- The abstract and introduction use the term 'end-to end' with an extraneous space; standardize to 'end-to-end' throughout.
- Figure captions and the description of token routing would benefit from an explicit diagram or pseudocode showing how semantic classification determines expert assignment for each token type.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The primary concern raised regarding insufficient experimental details is valid and directly impacts the verifiability of our central claims. We have revised the manuscript to provide the requested information and improve reproducibility.
read point-by-point responses
-
Referee: The experimental evaluation reports an 88.91 Driving Score on Bench2Drive and outperformance over baselines, yet supplies no details on baseline implementations, exact metric definitions and computation, statistical significance testing, data splits, or potential confounds. This absence is load-bearing for the central empirical claim and prevents verification of the result.
Authors: We agree that the original submission lacked adequate details on these elements, which is essential for independent verification. In the revised manuscript, we have expanded Section 4 (Experiments) with a dedicated subsection on 'Reproducibility and Evaluation Protocol.' This includes: (1) explicit descriptions of baseline implementations, noting which were reproduced from official codebases with our adaptations for fair comparison under the same Qwen2.5-VL-3B backbone and training regime; (2) precise definitions and computation formulas for the Driving Score and sub-metrics drawn directly from the Bench2Drive benchmark paper, including how they aggregate collision, off-road, and progress components; (3) details on data splits (e.g., training on the official 100k+ clips with 80/10/10 train/val/test partitioning) and any filtering applied; (4) statistical significance results, reporting mean and standard deviation over three independent runs with different random seeds, along with p-values where relevant; and (5) discussion of potential confounds such as hardware (NVIDIA A100 GPUs), hyperparameter sensitivity, and evaluation environment consistency. These additions directly address the load-bearing nature of the empirical claim. revision: yes
Circularity Check
No significant circularity; empirical benchmark result
full rationale
The manuscript proposes an end-to-end VLA architecture that couples vision-language tokens via shared self-attention while routing FFN layers to separate Vision-Language and Trajectory Experts, then applies a flow-matching decoder on action tokens. The load-bearing claim is the measured 88.91 Driving Score on the external Bench2Drive benchmark together with ablation results that directly compare the shared-attention and routing choices. No equations, fitted parameters, or predictions are presented that reduce by construction to the inputs; the reported performance is obtained through standard supervised training and evaluation on held-out test data rather than any self-definitional or self-citation chain.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The pretrained Qwen2.5-VL-3B backbone supplies useful semantic priors that transfer to driving scenes.
- domain assumption Flow-matching can reliably refine noisy action tokens into valid future waypoints and speed profiles.
invented entities (2)
-
Vision-Language Expert
no independent evidence
-
Trajectory Expert
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Multi-modal fusion transformer for end-to-end autonomous driving,
A. Prakash, K. Chitta, and A. Geiger, “Multi-modal fusion transformer for end-to-end autonomous driving,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 7077– 7087
work page 2021
-
[2]
Planning-oriented autonomous driving,
Y . Hu, J. Yang, L. Chen, K. Li, C. Sima, X. Zhu, S. Chai, S. Du, T. Lin, W. Wanget al., “Planning-oriented autonomous driving,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 17 853–17 862
work page 2023
-
[3]
Para- drive: Parallelized architecture for real-time autonomous driving,
X. Weng, B. Ivanovic, Y . Wang, Y . Wang, and M. Pavone, “Para- drive: Parallelized architecture for real-time autonomous driving,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 15 449–15 458
work page 2024
-
[4]
Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving,
B. Liao, S. Chen, H. Yin, B. Jiang, C. Wang, S. Yan, X. Zhang, X. Li, Y . Zhang, Q. Zhanget al., “Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 12 037–12 047
work page 2025
-
[5]
Y . Li, L. Fan, J. He, Y . Wang, Y . Chen, Z. Zhang, and T. Tan, “Enhancing end-to-end autonomous driving with latent world model,”arXiv preprint arXiv:2406.08481, 2024
-
[6]
Hydra-MDP: End-to-end Multimodal Planning with Multi-target Hydra-Distillation
Z. Li, K. Li, S. Wang, S. Lan, Z. Yu, Y . Ji, Z. Li, Z. Zhu, J. Kautz, Z. Wu et al., “Hydra-mdp: End-to-end multimodal planning with multi-target hydra-distillation,”arXiv preprint arXiv:2406.06978, 2024
work page internal anchor Pith review arXiv 2024
-
[7]
P. Wu, X. Jia, L. Chen, J. Yan, H. Li, and Y . Qiao, “Trajectory-guided control prediction for end-to-end autonomous driving: A simple yet strong baseline,” inAdvances in Neural Information Processing Systems, vol. 35, 2022
work page 2022
-
[8]
Think twice before driving: Towards scalable decoders for end-to-end autonomous driving,
X. Jia, P. Wu, L. Chen, J. Xie, C. He, J. Yan, and H. Li, “Think twice before driving: Towards scalable decoders for end-to-end autonomous driving,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023
work page 2023
-
[9]
X. Jia, Y . Gao, L. Chen, J. Yan, P. L. Liu, and H. Li, “Driveadapter: Breaking the coupling barrier of perception and planning in end-to-end autonomous driving,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023
work page 2023
-
[10]
Vad: Vectorized scene representation for efficient autonomous driving,
B. Jiang, S. Chen, Q. Xu, B. Liao, J. Chen, H. Zhou, Q. Zhang, W. Liu, C. Huang, and X. Wang, “Vad: Vectorized scene representation for efficient autonomous driving,”ICCV, 2023
work page 2023
-
[11]
Drivetransformer: Unified trans- former for scalable end-to-end autonomous driving,
X. Jia, J. You, Z. Zhang, and J. Yan, “Drivetransformer: Unified trans- former for scalable end-to-end autonomous driving,” inInternational Conference on Learning Representations, 2025
work page 2025
-
[12]
Bench2drive: Towards multi-ability benchmarking of closed-loop end-to-end autonomous driv- ing,
X. Jia, Z. Yang, Q. Li, Z. Zhang, and J. Yan, “Bench2drive: Towards multi-ability benchmarking of closed-loop end-to-end autonomous driv- ing,”Advances in Neural Information Processing Systems, vol. 37, pp. 819–844, 2024
work page 2024
-
[13]
Drivelm: Driving with graph visual ques- tion answering,
C. Sima, K. Renz, K. Chitta, L. Chen, H. Zhang, C. Xie, J. Beißwenger, P. Luo, A. Geiger, and H. Li, “Drivelm: Driving with graph visual ques- tion answering,” inEuropean conference on computer vision. Springer, 2024, pp. 256–274
work page 2024
-
[14]
B. Jiang, S. Chen, B. Liao, X. Zhang, W. Yin, Q. Zhang, C. Huang, W. Liu, and X. Wang, “Senna: Bridging large vision-language models and end-to-end autonomous driving,”arXiv preprint arXiv:2410.22313, 2024
-
[15]
Rt-2: Vision-language-action models transfer web knowledge to robotic control,
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahidet al., “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” inConference on Robot Learning. PMLR, 2023, pp. 2165–2183
work page 2023
-
[16]
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
X. Tian, J. Gu, B. Li, Y . Liu, Y . Wang, Z. Zhao, K. Zhan, P. Jia, X. Lang, and H. Zhao, “Drivevlm: The convergence of autonomous driving and large vision-language models,”arXiv preprint arXiv:2402.12289, 2024
work page internal anchor Pith review arXiv 2024
-
[17]
Simlingo: Vision-only closed-loop autonomous driving with language-action alignment,
K. Renz, L. Chen, E. Arani, and O. Sinavski, “Simlingo: Vision-only closed-loop autonomous driving with language-action alignment,” in Proceedings of the Computer Vision and Pattern Recognition Confer- ence, 2025, pp. 11 993–12 003
work page 2025
-
[18]
H. Fu, D. Zhang, Z. Zhao, J. Cui, D. Liang, C. Zhang, D. Zhang, H. Xie, B. Wang, and X. Bai, “Orion: A holistic end-to-end autonomous driving framework by vision-language instructed action generation,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 24 823–24 834
work page 2025
-
[19]
Z. Zhou, T. Cai, S. Z. Zhao, Y . Zhang, Z. Huang, B. Zhou, and J. Ma, “Autovla: A vision-language-action model for end-to-end autonomous driving with adaptive reasoning and reinforcement fine-tuning,”arXiv preprint arXiv:2506.13757, 2025
work page internal anchor Pith review arXiv 2025
-
[20]
T. Wang, E. Xie, R. Chu, Z. Li, and P. Luo, “Drivecot: Integrating chain-of-thought reasoning with end-to-end driving,”arXiv preprint arXiv:2403.16996, 2024
-
[21]
Sce2drivex: A generalized mllm framework for scene-to-drive learning,
R. Zhao, Q. Yuan, J. Li, H. Hu, Y . Li, Z. Gao, and F. Gao, “Sce2drivex: A generalized mllm framework for scene-to-drive learning,”IEEE Robotics and Automation Letters, 2025
work page 2025
-
[22]
Gra- dient surgery for multi-task learning,
T. Yu, S. Kumar, A. Gupta, S. Levine, K. Hausman, and C. Finn, “Gra- dient surgery for multi-task learning,”Advances in neural information processing systems, vol. 33, pp. 5824–5836, 2020
work page 2020
-
[23]
C. Ding, Z. Lu, S. Wang, R. Cheng, and V . N. Boddeti, “Mitigating task interference in multi-task learning via explicit task routing with non-learnable primitives,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 7756–7765
work page 2023
-
[24]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichteret al., “π 0: A vision-language-action flow model for general robot control,”arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Y . Li, S. Shang, W. Liu, B. Zhan, H. Wang, Y . Wang, Y . Chen, X. Wang, Y . An, C. Tang, L. Hou, L. Fan, and Z. Zhang, “Drivevla-w0: World models amplify data scaling law in autonomous driving,”arXiv preprint arXiv:2510.12796, 2025
-
[26]
Z. Yang, Y . Chai, X. Jia, Q. Li, Y . Shao, X. Zhu, H. Su, and J. Yan, “Drivemoe: Mixture-of-experts for vision-language-action model in end- to-end autonomous driving,”arXiv preprint arXiv:2505.16278, 2025
-
[27]
Y . Li, M. Tian, D. Zhu, J. Zhu, Z. Lin, Z. Xiong, and X. Zhao, “Drive- r1: Bridging reasoning and planning in vlms for autonomous driving IEEE ROBOTICS AND AUTOMATION LETTERS 9 with reinforcement learning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 8, 2026, pp. 6708–6716
work page 2026
-
[28]
Latentvla: Efficient vision-language models for autonomous driving via latent action prediction
C. Xie, C. Sima, T. Li, B. Sun, J. Wu, Z. Hao, and H. Li, “Flare: Learning future-aware latent representations from vision-language models for autonomous driving,”arXiv preprint arXiv:2601.05611, 2026
-
[29]
Y . Li, K. Xiong, X. Guo, F. Li, S. Yan, G. Xu, L. Zhou, L. Chen, H. Sun, B. Wang, K. Ma, G. Chen, H. Ye, W. Liu, and X. Wang, “Recogdrive: A reinforced cognitive framework for end-to-end autonomous driving,” arXiv preprint arXiv:2506.08052, 2025
-
[30]
J.-T. Zhai, Z. Feng, J. Du, Y . Mao, J.-J. Liu, Z. Tan, Y . Zhang, X. Ye, and J. Wang, “Rethinking the open-loop evaluation of end-to- end autonomous driving in nuscenes,”arXiv preprint arXiv:2305.10430, 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.