Recognition: 2 theorem links
· Lean TheoremRennala MVR: Improved Time Complexity for Parallel Stochastic Optimization via Momentum-Based Variance Reduction
Pith reviewed 2026-05-12 01:42 UTC · model grok-4.3
The pith
Variance reduction improves time complexity for parallel stochastic optimization under mean-squared smoothness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Rennala MVR is a parallel first-order method that inserts momentum-based variance reduction into the time-optimal skeleton of Rennala SGD. Under the mean-squared smoothness assumption, its oracle complexity and time complexity both improve over Rennala SGD in the heterogeneous-machine setting, with matching lower bounds established for the time metric.
What carries the argument
Rennala MVR, the momentum-variance-reduced parallel optimizer that maintains the asynchronous worker structure of Rennala SGD while applying variance-reduced gradient estimates to cut effective noise in wall-clock time.
If this is right
- Time complexity, not iteration complexity, becomes the decisive metric for heterogeneous parallel training.
- Variance reduction can be applied without destroying the time-optimality structure of Rennala SGD.
- Lower bounds confirm that the reported time-complexity gains are tight in the analyzed regimes.
- The improvement holds for nonconvex smooth problems once mean-squared smoothness is granted.
Where Pith is reading between the lines
- The same momentum variance reduction may yield time gains in other distributed first-order methods whose analysis currently stops at iteration complexity.
- Practical implementations could replace the exact variance reduction with cheaper approximations while preserving most of the time benefit.
- If mean-squared smoothness holds for typical deep-learning losses, the method offers a direct route to faster training on real heterogeneous hardware.
Load-bearing premise
The loss function satisfies mean-squared smoothness, allowing the variance reduction step to convert into a genuine reduction in wall-clock time rather than only iteration count.
What would settle it
Run Rennala MVR and Rennala SGD on the same stochastic quadratic problem known to obey mean-squared smoothness, using the exact parameter regime where the theory predicts a time-complexity gap; if the measured wall-clock time to target accuracy shows no improvement for Rennala MVR, the claim is falsified.
Figures

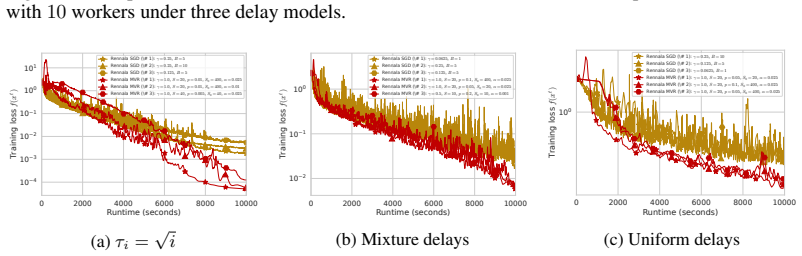


read the original abstract
Large-scale machine learning models are trained on clusters of machines that exhibit heterogeneous performance due to hardware variability, network delays, and system-level instabilities. In such environments, time complexity rather than iteration complexity becomes the relevant performance metric for optimization algorithms. Recent work by Tyurin and Richt\'{a}rik (2023) established the first time complexity analysis for parallel first-order stochastic optimization, proposing Rennala SGD as a time-optimal method for smooth nonconvex optimization. However, Rennala SGD is fundamentally a modification of SGD, and variance reduction techniques are known to improve the iteration complexity of SGD. In this work, we investigate whether variance reduction can also improve time complexity in heterogeneous systems. We show that, under a mean-squared smoothness assumption, variance reduction can improve time complexity in relevant parameter regimes. To this end, we propose Rennala MVR, a variance-reduced extension of Rennala SGD based on momentum-based variance reduction, and analyze its oracle and time complexity. We establish lower bounds for time complexity under these assumptions. On a stochastic quadratic benchmark, experiments with the exact method support the theory, while neural-network experiments with a practical inexact variant show similar empirical gains over Rennala SGD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Rennala MVR, a momentum-based variance-reduced extension of Rennala SGD for parallel first-order stochastic optimization in heterogeneous computing environments. It claims that, under a mean-squared smoothness assumption, the method improves time complexity (as opposed to iteration complexity) over Rennala SGD in relevant parameter regimes. The paper provides oracle and time complexity analyses, establishes lower bounds under the stated assumptions, and reports supporting experiments on a stochastic quadratic benchmark (with the exact method) and neural-network training (with a practical inexact variant).
Significance. If the claims hold, the result would extend time-complexity analysis of parallel stochastic methods to variance reduction, which is relevant for large-scale ML training on clusters with hardware and network variability. The inclusion of lower bounds and the distinction between oracle and wall-clock metrics are positive features that ground the contribution in the heterogeneous-systems setting.
major comments (2)
- [Analysis] Analysis section: The central claim that variance reduction yields a time-complexity improvement is conditioned on the mean-squared smoothness assumption, yet the manuscript does not isolate whether this assumption is essential (e.g., by deriving the complexity expressions under standard smoothness alone or exhibiting a regime where the gain disappears without mean-squared smoothness). Without such a comparison, it remains unclear whether the improvement is enabled by the assumption or is an artifact of the proof technique.
- [Experiments] Experiments section: The stochastic quadratic benchmark satisfies mean-squared smoothness by construction, while the neural-network experiments employ an inexact practical variant of the method; this experimental design does not provide a direct test of whether the observed gains over Rennala SGD require the mean-squared smoothness assumption or would appear under weaker conditions.
minor comments (1)
- [Abstract and Introduction] The abstract and introduction would benefit from an explicit statement of the precise time-complexity expressions (including dependence on the number of machines and heterogeneity parameters) to allow readers to immediately compare Rennala MVR with Rennala SGD.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The positive assessment of the work's significance is appreciated. Below we respond point-by-point to the major comments, indicating where revisions will be made and where certain aspects remain beyond the current scope.
read point-by-point responses
-
Referee: [Analysis] Analysis section: The central claim that variance reduction yields a time-complexity improvement is conditioned on the mean-squared smoothness assumption, yet the manuscript does not isolate whether this assumption is essential (e.g., by deriving the complexity expressions under standard smoothness alone or exhibiting a regime where the gain disappears without mean-squared smoothness). Without such a comparison, it remains unclear whether the improvement is enabled by the assumption or is an artifact of the proof technique.
Authors: The mean-squared smoothness assumption enables tighter control over the variance terms when accounting for heterogeneous computation times and delays, which is essential for the momentum-based variance reduction to improve the dependence on the heterogeneity parameters in the time-complexity bound. Under standard smoothness the same decoupling does not hold, and the resulting time complexity would match that of Rennala SGD. We will add a clarifying remark in the analysis section (and in the discussion of lower bounds) explaining the role of the assumption and stating that the complexity expressions under standard smoothness revert to the baseline rate. However, constructing an explicit function class or regime that satisfies standard smoothness but not mean-squared smoothness, and demonstrating the disappearance of the gain, constitutes additional technical work that lies outside the present manuscript. revision: partial
-
Referee: [Experiments] Experiments section: The stochastic quadratic benchmark satisfies mean-squared smoothness by construction, while the neural-network experiments employ an inexact practical variant of the method; this experimental design does not provide a direct test of whether the observed gains over Rennala SGD require the mean-squared smoothness assumption or would appear under weaker conditions.
Authors: The stochastic quadratic is deliberately chosen because it satisfies the assumption exactly, permitting a clean validation of the derived oracle and time complexities. The neural-network experiments are included only to illustrate that a practical, inexact implementation still yields empirical improvements on a realistic task; they are not claimed to test the assumption. We will expand the experiments section with a short paragraph that explicitly ties the quadratic results to the assumption and notes that empirical gains on neural networks are consistent with but not a proof of necessity. A controlled comparison under standard smoothness alone would require a different benchmark family and is left for future investigation. revision: yes
- Exhibiting a concrete regime or counterexample function where the time-complexity improvement vanishes without the mean-squared smoothness assumption.
Circularity Check
No significant circularity; analysis is independent of inputs
full rationale
The paper introduces Rennala MVR as a momentum-based variance-reduced extension of Rennala SGD and derives its oracle and time complexity bounds under an explicit mean-squared smoothness assumption, along with matching lower bounds. These steps constitute a fresh complexity analysis rather than any self-definitional reduction, fitted-parameter renaming, or load-bearing self-citation chain. The cited prior work (Tyurin and Richtárik 2023) supplies the baseline algorithm but is not invoked as a uniqueness theorem or ansatz that forces the new result. Experiments on quadratics and neural nets are presented as empirical support, not as the derivation itself. No equation or claim reduces by construction to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mean-squared smoothness assumption
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe show that, under a mean-squared smoothness assumption, variance reduction can improve time complexity in relevant parameter regimes... Rennala MVR... oracle complexity O(¯LΔσ/ε^{3/2} + σ²/ε)
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclearAssumption 2.4 (Mean-squared smoothness)... E[∥∇f(x;ξ)−∇f(y;ξ)∥²] ≤ ¯L²∥x−y∥²
Reference graph
Works this paper leans on
-
[1]
First Provably Optimal Asynchronous
Artavazd Maranjyan , year =. First Provably Optimal Asynchronous
-
[2]
Artavazd Maranjyan and Peter Richt. Ringleader. The Fourteenth International Conference on Learning Representations , year=
-
[3]
Artavazd Maranjyan and Alexander Tyurin and Peter Richt. Ringmaster. 2025 , booktitle=
work page 2025
-
[4]
Maranjyan, Artavazd and Saad, El Mehdi and Richt. 2025 , booktitle=
work page 2025
-
[5]
Artavazd Maranjyan and Omar Shaikh Omar and Peter Richt. MindFlayer. The 41st Conference on Uncertainty in Artificial Intelligence , year=
-
[6]
Transactions on Machine Learning Research , issn=
Artavazd Maranjyan and Mher Safaryan and Peter Richt. Transactions on Machine Learning Research , issn=. 2025 , url=
work page 2025
-
[7]
arXiv preprint arXiv:2412.17054 , year=
Differentially Private Random Block Coordinate Descent , author=. arXiv preprint arXiv:2412.17054 , year=
-
[8]
Condat, Laurent and Maranjyan, Artavazd and Richt. Proc. of International Conference on Learning Representations (ICLR) , year=
-
[9]
Journal of Contemporary Mathematical Analysis (Armenian Academy of Sciences) , volume=
Grigoryan, Martin and Kamont, Anna and Maranjyan, Artavazd , title=. Journal of Contemporary Mathematical Analysis (Armenian Academy of Sciences) , volume=. 2023 , publisher=
work page 2023
-
[10]
Grigoryan, Martin and Maranjyan, Artavazd , journal=. On the divergence of
-
[11]
On the unconditional convergence of
Grigoryan, Tigran M and Maranjyan, Artavazd , journal=. On the unconditional convergence of
-
[12]
On the Ineffectiveness of Variance Reduced Optimization for Deep Learning , volume =
Defazio, Aaron and Bottou, Leon , booktitle =. On the Ineffectiveness of Variance Reduced Optimization for Deep Learning , volume =
-
[13]
O'Donnell, James and Crownhart, Casey , journal =. We did the math on. 2025 , month =
work page 2025
-
[14]
The growing energy footprint of artificial intelligence , author=. Joule , volume=. 2023 , publisher=
work page 2023
-
[15]
Measuring the environmental impact of delivering
Elsworth, Cooper and Huang, Keguo and Patterson, David and Schneider, Ian and Sedivy, Robert and Goodman, Savannah and Townsend, Ben and Ranganathan, Parthasarathy and Dean, Jeff and Vahdat, Amin and others , journal=. Measuring the environmental impact of delivering
-
[16]
The rising costs of training frontier
Cottier, Ben and Rahman, Robi and Fattorini, Loredana and Maslej, Nestor and Besiroglu, Tamay and Owen, David , journal=. The rising costs of training frontier
- [17]
-
[18]
Keller Jordan and Yuchen Jin and Vlado Boza and Jiacheng You and Franz Cesista and Laker Newhouse and Jeremy Bernstein , title =. 2024 , url =
work page 2024
-
[19]
Nesterov Method for Asynchronous Pipeline Parallel Optimization , author=. 2025 , booktitle=
work page 2025
-
[20]
arXiv preprint arXiv:1910.05124 , year=
Pipemare: Asynchronous pipeline parallel dnn training , author=. arXiv preprint arXiv:1910.05124 , year=
-
[21]
arXiv preprint arXiv:2509.19029 , year=
Clapping: Removing Per-sample Storage for Pipeline Parallel Distributed Optimization with Communication Compression , author=. arXiv preprint arXiv:2509.19029 , year=
-
[22]
International Conference on Machine Learning , pages=
Shampoo: Preconditioned stochastic tensor optimization , author=. International Conference on Machine Learning , pages=. 2018 , organization=
work page 2018
-
[23]
Proceedings of the 30th International Conference on Machine Learning , pages =
Online Learning under Delayed Feedback , author =. Proceedings of the 30th International Conference on Machine Learning , pages =. 2013 , editor =
work page 2013
-
[24]
Bistritz, Ilai and Zhou, Zhengyuan and Chen, Xi and Bambos, Nicholas and Blanchet, Jose , booktitle =. Online
-
[25]
International Conference on Machine Learning , pages=
Adapting to delays and data in adversarial multi-armed bandits , author=. International Conference on Machine Learning , pages=. 2021 , organization=
work page 2021
-
[26]
Bandit Online Learning with Unknown Delays , author =. Proceedings of the Twenty-Second International Conference on Artificial Intelligence and Statistics , pages =. 2019 , editor =
work page 2019
-
[27]
The Nonstochastic Multiarmed Bandit Problem , journal =
Auer, Peter and Cesa-Bianchi, Nicol\`. The Nonstochastic Multiarmed Bandit Problem , journal =. 2002 , doi =. https://doi.org/10.1137/S0097539701398375 , abstract =
-
[28]
Asynchronous federated optimization,
Asynchronous federated optimization , author=. arXiv preprint arXiv:1903.03934 , year=
-
[29]
Journal of Machine Learning Research , volume=
A general theory for federated optimization with asynchronous and heterogeneous clients updates , author=. Journal of Machine Learning Research , volume=
-
[30]
Advances in Neural Information Processing Systems , volume=
Asynchronous parallel stochastic gradient for nonconvex optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[31]
The Thirteenth International Conference on Learning Representations , year=
Tight Time Complexities in Parallel Stochastic Optimization with Arbitrary Computation Dynamics , author=. The Thirteenth International Conference on Learning Representations , year=
-
[32]
Wang, Qiyuan and Yang, Qianqian and He, Shibo and Shi, Zhiguo and Chen, Jiming , journal=
-
[33]
IEEE Transactions on Wireless Communications , volume=
Asynchronous federated learning over wireless communication networks , author=. IEEE Transactions on Wireless Communications , volume=. 2022 , publisher=
work page 2022
-
[34]
IEEE Transactions on Automatic Control , volume=
Distributed asynchronous deterministic and stochastic gradient optimization algorithms , author=. IEEE Transactions on Automatic Control , volume=. 1986 , publisher=
work page 1986
-
[35]
Journal of Machine Learning Research , volume=
Asynchronous iterations in optimization: New sequence results and sharper algorithmic guarantees , author=. Journal of Machine Learning Research , volume=
- [36]
-
[37]
Efficient large-scale language model training on
Narayanan, Deepak and Shoeybi, Mohammad and Casper, Jared and LeGresley, Patrick and Patwary, Mostofa and Korthikanti, Vijay and Vainbrand, Dmitri and Kashinkunti, Prethvi and Bernauer, Julie and Catanzaro, Bryan and others , booktitle=. Efficient large-scale language model training on
-
[38]
Proceedings of the 44th Annual International Symposium on Computer Architecture , pages=
In-Datacenter Performance Analysis of a Tensor Processing Unit , author=. Proceedings of the 44th Annual International Symposium on Computer Architecture , pages=. 2017 , month=
work page 2017
- [39]
-
[40]
Proceedings of the AAAI conference on artificial intelligence , volume=
Energy and policy considerations for modern deep learning research , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[41]
Advances in Neural Information Processing Systems , editor =
Cyclades: Conflict-free Asynchronous Machine Learning , author =. Advances in Neural Information Processing Systems , editor =
-
[42]
Proceedings of the 39th International Conference on Machine Learning , pages =
Delay-Adaptive Step-sizes for Asynchronous Learning , author =. Proceedings of the 39th International Conference on Machine Learning , pages =. 2022 , editor =
work page 2022
-
[43]
Proceedings of the 34th International Conference on Machine Learning , pages =
Asynchronous Stochastic Gradient Descent with Delay Compensation , author =. Proceedings of the 34th International Conference on Machine Learning , pages =. 2017 , editor =
work page 2017
-
[44]
Rajbhandari, Samyam and Rasley, Jeff and Ruwase, Olatunji and He, Yuxiong , booktitle=. 2020 , organization=
work page 2020
-
[45]
J. Edward Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Weizhu Chen , booktitle=
-
[46]
Transactions on Machine Learning Research , issn=
Efficient Large Language Models: A Survey , author=. Transactions on Machine Learning Research , issn=. 2024 , url=
work page 2024
-
[47]
Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
Goyal, Priya and Doll. Accurate, Large Minibatch. arXiv preprint arXiv:1706.02677 , year=
work page internal anchor Pith review arXiv
-
[48]
Diloco: Distributed low- communication training of language models.arXiv preprint arXiv:2311.08105,
Arthur Douillard and Qixuan Feng and Andrei A. Rusu and Rachita Chhaparia and Yani Donchev and Adhiguna Kuncoro and Marc'Aurelio Ranzato and Arthur Szlam and Jiajun Shen , year=. 2311.08105 , archivePrefix=
-
[49]
Proceedings of the 10th USENIX Conference on Networked Systems Design and Implementation , pages =
Ananthanarayanan, Ganesh and Ghodsi, Ali and Shenker, Scott and Stoica, Ion , title =. Proceedings of the 10th USENIX Conference on Networked Systems Design and Implementation , pages =. 2013 , publisher =
work page 2013
-
[50]
Annals of Mathematical Statistics , volume=
A Stochastic Approximation Method , author=. Annals of Mathematical Statistics , volume=
-
[51]
Optimization Methods for Large-Scale Machine Learning , journal =
Bottou, L\'. Optimization Methods for Large-Scale Machine Learning , journal =. 2018 , doi =
work page 2018
-
[52]
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and Al-Dahle, Ahmad and Letman, Aiesha and Mathur, Akhil and Schelten, Alan and Vaughan, Alex and others , journal=. The
-
[53]
Covington, Paul and Adams, Jay and Sargin, Emre , booktitle=. Deep neural networks for
-
[54]
End to End Learning for Self-Driving Cars
End to end learning for self-driving cars , author=. arXiv preprint arXiv:1604.07316 , year=
work page internal anchor Pith review arXiv
-
[55]
Large Scale Distributed Deep Networks , url =
Dean, Jeffrey and Corrado, Greg and Monga, Rajat and Chen, Kai and Devin, Matthieu and Mao, Mark and Ranzato, Marc aurelio and Senior, Andrew and Tucker, Paul and Yang, Ke and Le, Quoc and Ng, Andrew , booktitle =. Large Scale Distributed Deep Networks , url =
-
[56]
PyTorch Distributed: Experiences on Accelerating Data Parallel Training,
Pytorch distributed: Experiences on accelerating data parallel training , author=. arXiv preprint arXiv:2006.15704 , year=
-
[57]
Advances in Neural Information Processing Systems , volume=
Communication efficient distributed machine learning with the parameter server , author=. Advances in Neural Information Processing Systems , volume=
-
[58]
arXiv preprint arXiv:1806.00582 (2018)
Federated learning with non-iid data , author=. arXiv preprint arXiv:1806.00582 , year=
-
[59]
IEEE Transactions on Neural Networks and Learning Systems , volume=
Towards personalized federated learning , author=. IEEE Transactions on Neural Networks and Learning Systems , volume=. 2022 , publisher=
work page 2022
-
[60]
SIAM Journal on Optimization , volume=
A convergent incremental gradient method with a constant step size , author=. SIAM Journal on Optimization , volume=. 2007 , publisher=
work page 2007
-
[61]
Defazio, Aaron and Bach, Francis and Lacoste-Julien, Simon , journal=
-
[62]
SIAM Journal on Optimization , volume=
On the convergence rate of incremental aggregated gradient algorithms , author=. SIAM Journal on Optimization , volume=. 2017 , publisher=
work page 2017
-
[63]
Advances in Neural Information Processing Systems , volume=
A stochastic gradient method with an exponential convergence rate for finite training sets , author=. Advances in Neural Information Processing Systems , volume=
-
[64]
Mathematical Programming , volume=
Minimizing finite sums with the stochastic average gradient , author=. Mathematical Programming , volume=. 2017 , publisher=
work page 2017
-
[65]
International Conference on Machine Learning , pages=
No one idles: Efficient heterogeneous federated learning with parallel edge and server computation , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[66]
IEEE Transactions on Mobile Computing , year=
Achieving linear speedup in asynchronous federated learning with heterogeneous clients , author=. IEEE Transactions on Mobile Computing , year=
-
[67]
International Conference on Artificial Intelligence and Statistics , pages=
Asynchronous distributed optimization with stochastic delays , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2022 , organization=
work page 2022
-
[68]
Incremental Aggregated Asynchronous
Xiaolu Wang and Yuchang Sun and Hoi To Wai and Jun Zhang , year=. Incremental Aggregated Asynchronous
-
[69]
SIAM Journal on Optimization , volume=
Global convergence rate of proximal incremental aggregated gradient methods , author=. SIAM Journal on Optimization , volume=. 2018 , publisher=
work page 2018
-
[70]
SIAM Journal on Optimization , volume=
Perturbed iterate analysis for asynchronous stochastic optimization , author=. SIAM Journal on Optimization , volume=. 2017 , publisher=
work page 2017
-
[71]
Advances in Neural Information Processing Systems , volume=
Distributed delayed stochastic optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[72]
arXiv preprint arXiv:2502.08206 , year=
Optimizing Asynchronous Federated Learning: A Delicate Trade-Off Between Model-Parameter Staleness and Update Frequency , author=. arXiv preprint arXiv:2502.08206 , year=
-
[73]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[74]
Decentralized Stochastic Optimization and Gossip Algorithms with Compressed Communication , year =
Anastasia Koloskova and Sebastian U Stich and Martin Jaggi , booktitle =. Decentralized Stochastic Optimization and Gossip Algorithms with Compressed Communication , year =
-
[75]
Language Models are Few-Shot Learners , url =
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Winte...
-
[76]
Achiam, Josh and Adler, Steven and Agarwal, Sandhini and Ahmad, Lama and Akkaya, Ilge and Aleman, Florencia Leoni and Almeida, Diogo and Altenschmidt, Janko and Altman, Sam and Anadkat, Shyamal and others , journal=
-
[77]
Gemini: A Family of Highly Capable Multimodal Models
Gemini: a family of highly capable multimodal models , author=. arXiv preprint arXiv:2312.11805 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[78]
Cong Fang and Chris Junchi Li and Zhouchen Lin and Tong Zhang , booktitle =
-
[79]
The 34th International Conference on Machine Learning , year =
Nguyen, Lam and Liu, Jie and Scheinberg, Katya and Tak. The 34th International Conference on Machine Learning , year =
-
[80]
arXiv preprint arXiv:2106.05203 , title =
Peter Richt\'. arXiv preprint arXiv:2106.05203 , title =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.