Recognition: no theorem link
FragileFlow: Spectral Control of Correct-but-Fragile Predictions for Foundation Model Robustness
Pith reviewed 2026-05-12 01:07 UTC · model grok-4.3
The pith
FragileFlow uses spectral control on margin-aware error flows from correct predictions to deliver deterministic worst-class robustness in foundation models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that correct-but-fragile predictions can be identified by a margin buffer, their off-class probability mass organized into a vulnerable-risk matrix, and the matrix subjected to empirical spectral control; the resulting object admits the first PAC-Bayes upper bound, which under a stability condition yields a conservative deterministic guarantee of worst-class robustness.
What carries the argument
The margin-aware error flow object, defined as the structured probability leakage from true classes in still-correct predictions and assembled into a class-wise vulnerable-risk matrix whose spectral properties are directly regularized by FragileFlow.
If this is right
- Empirical spectral control improves the proposed theory-facing risk measures over matched baselines.
- Perturbed worst-class accuracy increases in most tested settings on LLM and VLM adaptation tasks.
- Clean accuracy is preserved across all comparisons.
- The PAC-Bayes bound offers a conservative route from observed spectral properties to deterministic worst-class robustness.
Where Pith is reading between the lines
- The same margin-buffer and matrix construction could be adapted to regression or sequence-generation tasks to surface analogous fragile outputs.
- The vulnerable-risk matrix may expose systematic class-confusion patterns that persist across different perturbation strengths.
- If the stability condition can be verified or relaxed on new data, the method offers a lightweight post-training route to worst-class guarantees without full retraining.
Load-bearing premise
The stability condition that converts the PAC-Bayes upper bound on the margin-aware error-flow object into a deterministic worst-class robustness guarantee.
What would settle it
A benchmark experiment in which spectral control of the vulnerable-risk matrix is applied yet worst-class accuracy under perturbations fails to rise or the empirical risk measures do not improve over matched baselines.
Figures



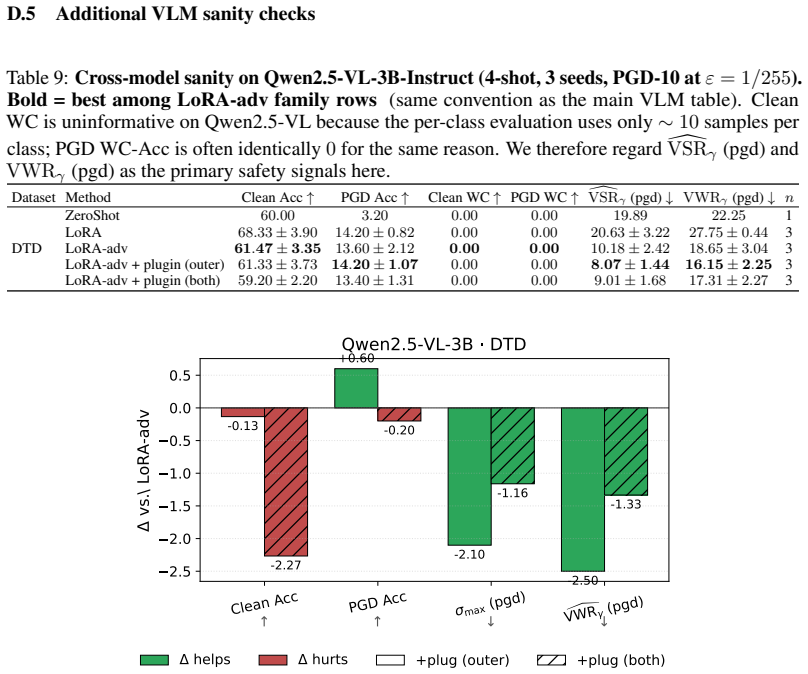
read the original abstract
Robust adaptation of LLMs and VLMs is often evaluated by average accuracy or average consistency under perturbations. However, these averages can hide a structured failure mode: a prediction may remain correct while probability mass already flows from particular true classes toward systematic wrong competitors near the decision boundary. In this paper, we formalize this phenomenon as margin-aware error flow and introduce FragileFlow, a plug-in regularizer that uses a calibrated margin buffer to identify correct-but-fragile predictions and organize their off-class probability mass into a class-wise vulnerable-risk matrix. Theoretically, we provide the first PAC-Bayes upper bound for this margin-aware error-flow object, showing how empirical spectral control yields a conservative route to deterministic worst-class robustness under a stability condition. Experiments on multiple-choice LLM benchmarks and few-shot CLIP adaptation show that FragileFlow consistently improves the proposed theory-facing risk measures over matched baselines, yields perturbed worst-class accuracy gains in most settings, and preserves clean accuracy across comparisons.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes margin-aware error flow as a structured failure mode in which correct predictions in LLMs and VLMs nonetheless exhibit probability mass flowing toward systematic wrong competitors. It introduces FragileFlow, a plug-in regularizer that employs a calibrated margin buffer to identify fragile predictions and organizes off-class mass into a class-wise vulnerable-risk matrix. The central theoretical contribution is a PAC-Bayes upper bound on this error-flow object, which, under an invoked stability condition, is claimed to yield a conservative deterministic guarantee on worst-class robustness via empirical spectral control. Experiments on multiple-choice LLM benchmarks and few-shot CLIP adaptation report consistent gains on theory-facing risk measures, perturbed worst-class accuracy in most settings, and preservation of clean accuracy relative to matched baselines.
Significance. If the derivation and the stability condition can be made rigorous and verifiable, the work supplies a novel lens on robustness that moves beyond average accuracy or consistency metrics toward structured, worst-class guarantees. The combination of a PAC-Bayes bound with a practical spectral regularizer is potentially valuable for safety-critical deployment of foundation models. The reported empirical pattern—improved risk measures without clean-accuracy degradation—is a positive signal, though its reliability cannot yet be assessed from the provided details.
major comments (3)
- [Abstract, §3 (theoretical development)] Abstract and theoretical section: The PAC-Bayes upper bound is presented as the first such bound for the margin-aware error-flow object and as supplying a conservative route to deterministic worst-class robustness under a stability condition. No derivation, explicit statement of the bound, or definition of the stability condition appears in the abstract, and the full text does not clarify whether the bound is independent of quantities fitted during regularization or whether the stability condition is enforced by FragileFlow. This renders the central theoretical claim unverifiable and load-bearing.
- [Experiments (§4–5)] Experimental section: The claims of consistent improvement on theory-facing risk measures and perturbed worst-class accuracy gains rest on comparisons whose details are absent—no description of how the regularizer or vulnerable-risk matrix is computed, no error bars, no specification of the stability condition's empirical status post-training, and no ablation isolating the contribution of spectral control. These omissions prevent assessment of whether the reported gains are robust or whether the stability condition actually holds.
- [§3 (stability condition), §4 (experiments)] §3 and §4: The stability condition is invoked to bridge the PAC-Bayes bound to deterministic worst-class robustness, yet no experiment tests whether the condition is satisfied by models trained with FragileFlow or what occurs under violation. Without such verification, the advertised conservative guarantee cannot be confirmed and the bound may not deliver the claimed robustness.
minor comments (2)
- [§2] Notation for the vulnerable-risk matrix and margin-aware error flow should be introduced with explicit equations at first use rather than relying on prose descriptions.
- [Abstract, §5] The abstract states that FragileFlow 'preserves clean accuracy across comparisons,' but the experimental tables or figures should report the exact clean-accuracy deltas with standard deviations to substantiate this claim.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and describe the revisions we will make to improve clarity, verifiability, and empirical support.
read point-by-point responses
-
Referee: Abstract and theoretical section: The PAC-Bayes upper bound is presented as the first such bound for the margin-aware error-flow object and as supplying a conservative route to deterministic worst-class robustness under a stability condition. No derivation, explicit statement of the bound, or definition of the stability condition appears in the abstract, and the full text does not clarify whether the bound is independent of quantities fitted during regularization or whether the stability condition is enforced by FragileFlow. This renders the central theoretical claim unverifiable and load-bearing.
Authors: We agree that the abstract and main theoretical section require an explicit statement of the bound and a clear definition of the stability condition. The derivation appears in the appendix; the bound is constructed to remain independent of regularization parameters, and FragileFlow is designed to enforce the stability condition via the margin buffer and spectral regularizer. In the revision we will (i) add the explicit bound and stability definition to the abstract and §3, (ii) include a concise derivation sketch in the main text, and (iii) state the independence and enforcement properties explicitly. revision: yes
-
Referee: Experimental section: The claims of consistent improvement on theory-facing risk measures and perturbed worst-class accuracy gains rest on comparisons whose details are absent—no description of how the regularizer or vulnerable-risk matrix is computed, no error bars, no specification of the stability condition's empirical status post-training, and no ablation isolating the contribution of spectral control. These omissions prevent assessment of whether the reported gains are robust or whether the stability condition actually holds.
Authors: We acknowledge these omissions. The computation of the regularizer and vulnerable-risk matrix is outlined in §4, but we will expand this with explicit formulas, pseudocode, and implementation details. We will also report error bars from multiple random seeds, the post-training empirical value of the stability condition on each benchmark, and an ablation that isolates the spectral-control term. These additions will allow readers to assess robustness of the gains. revision: yes
-
Referee: §3 and §4: The stability condition is invoked to bridge the PAC-Bayes bound to deterministic worst-class robustness, yet no experiment tests whether the condition is satisfied by models trained with FragileFlow or what occurs under violation. Without such verification, the advertised conservative guarantee cannot be confirmed and the bound may not deliver the claimed robustness.
Authors: We agree that direct verification of the stability condition is necessary to support the deterministic guarantee. In the revised manuscript we will add an empirical check that measures whether the condition holds for FragileFlow-trained models on the reported benchmarks and discuss the behavior observed when the condition is mildly violated. This will strengthen the connection between the theoretical bound and the experimental results. revision: yes
Circularity Check
Derivation chain is self-contained; no circular reductions identified
full rationale
The paper defines the margin-aware error-flow object and FragileFlow regularizer from first principles using a calibrated margin buffer and class-wise vulnerable-risk matrix. It then states a new PAC-Bayes upper bound on this explicitly defined object and connects the bound to worst-class robustness only under an explicitly invoked stability condition. No provided equations or steps show the bound, the spectral control, or the robustness guarantee reducing to fitted parameters, self-citations, or the conclusion by construction. Experiments are reported as separate empirical checks on risk measures and accuracy, not as inputs that force the theoretical claims. The stability condition is treated as an assumption rather than a derived or fitted property, keeping the chain non-circular.
Axiom & Free-Parameter Ledger
free parameters (1)
- calibrated margin buffer
axioms (1)
- domain assumption Stability condition under which empirical spectral control yields deterministic worst-class robustness
invented entities (2)
-
margin-aware error flow
no independent evidence
-
vulnerable-risk matrix
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Better fine-tuning by reducing representational collapse
Armen Aghajanyan, Akshat Shrivastava, Anchit Gupta, Naman Goyal, Luke Zettlemoyer, and Sonal Gupta. Better fine-tuning by reducing representational collapse. InInternational Conference on Learning Representations, 2021
work page 2021
-
[2]
Enhancing LLM robustness to perturbed instructions: An empirical study
Aryan Agrawal, Lisa Alazraki, Shahin Honarvar, Thomas Mensink, and Marek Rei. Enhancing LLM robustness to perturbed instructions: An empirical study. InICLR 2025 Workshop on Building Trust in Language Models and Applications, 2025
work page 2025
-
[3]
Stronger generalization bounds for deep nets via a compression approach
Sanjeev Arora, Rong Ge, Behnam Neyshabur, and Yi Zhang. Stronger generalization bounds for deep nets via a compression approach. InProceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pages 254–263. PMLR, 2018
work page 2018
-
[4]
Robustness may be at odds with fairness: An empirical study on class-wise accuracy
Philipp Benz, Chaoning Zhang, Adil Karjauv, and In So Kweon. Robustness may be at odds with fairness: An empirical study on class-wise accuracy. In Luca Bertinetto, João F. Henriques, Samuel Albanie, Michela Paganini, and Gül Varol, editors,NeurIPS 2020 Workshop on Pre- registration in Machine Learning, volume 148 ofProceedings of Machine Learning Researc...
work page 2020
-
[5]
Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S
Rishi Bommasani, Drew A. Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S. Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, Erik Brynjolfsson, S. Buch, Dallas Card, Rodrigo Castellon, Niladri S. Chatterji, Annie S. Chen, Kathleen A. Creel, Jared Davis, Dora Demszky, Chris Donahue, Moussa Doumbouya, Esin Durmus, Stefano...
work page 2021
-
[6]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott G...
work page 1901
-
[7]
Institute of Mathematical Statistics, Beachwood, Ohio, 2007
Olivier Catoni.PAC-Bayesian Supervised Classification: The Thermodynamics of Statistical Learning. Institute of Mathematical Statistics, Beachwood, Ohio, 2007
work page 2007
-
[8]
Describing textures in the wild
Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, Sammy Mohamed, and Andrea Vedaldi. Describing textures in the wild. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3606–3613, 2014
work page 2014
-
[9]
Think you have solved question answering? try ARC, the AI2 reasoning challenge, 2018
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try ARC, the AI2 reasoning challenge, 2018. 10
work page 2018
-
[10]
Gintare Karolina Dziugaite and Daniel M. Roy. Computing nonvacuous generalization bounds for deep (stochastic) neural networks with many more parameters than training data. In Proceedings of the Thirty-Third Conference on Uncertainty in Artificial Intelligence, 2017
work page 2017
-
[11]
Li Fei-Fei, Rob Fergus, and Pietro Perona. Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories.Computer Vision and Image Understanding, 106(1):59–70, 2007
work page 2007
-
[12]
Sharpness-aware min- imization for efficiently improving generalization
Pierre Foret, Ariel Kleiner, Hossein Mobahi, and Behnam Neyshabur. Sharpness-aware min- imization for efficiently improving generalization. InInternational Conference on Learning Representations, 2021
work page 2021
-
[13]
Few- shot adversarial low-rank fine-tuning of vision-language models, 2025
Sajjad Ghiasvand, Haniyeh Ehsani Oskouie, Mahnoosh Alizadeh, and Ramtin Pedarsani. Few- shot adversarial low-rank fine-tuning of vision-language models, 2025
work page 2025
-
[14]
Goodfellow, Jonathon Shlens, and Christian Szegedy
Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adver- sarial examples. In Yoshua Bengio and Yann LeCun, editors,3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, 2015
work page 2015
-
[15]
Evaluating concurrent robustness of language models across diverse challenge sets
Vatsal Gupta, Pranshu Pandya, Tushar Kataria, Vivek Gupta, and Dan Roth. Evaluating concurrent robustness of language models across diverse challenge sets. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 22162–22184, Miami, Florida, USA, 2024. Association for Computational Linguistics
work page 2024
-
[16]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022
work page 2022
-
[17]
Jinwei Hu, Yi Dong, Youcheng Sun, and Xiaowei Huang. Tapas are free! training-free adaptation of programmatic agents via llm-guided program synthesis in dynamic environments. Proceedings of the AAAI Conference on Artificial Intelligence, 40(35):29477–29485, Mar. 2026
work page 2026
-
[18]
Jinwei Hu, Xinmiao Huang, Youcheng Sun, Yi Dong, and Xiaowei Huang. Lying with truths: Open-channel multi-agent collusion for belief manipulation via generative montage.arXiv preprint arXiv:2601.01685, 2026
-
[19]
Jinwei Hu, Zhenglin Huang, Xiangyu Yin, Wenjie Ruan, Guangliang Cheng, Yi Dong, and Xiaowei Huang. Falcon: Fine-grained activation manipulation by contrastive orthogonal unalignment for large language model. In D. Belgrave, C. Zhang, H. Lin, R. Pascanu, P. Koniusz, M. Ghassemi, and N. Chen, editors,Advances in Neural Information Processing Systems, volume...
work page 2025
-
[20]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b, 2023
work page 2023
-
[21]
Haoming Jiang, Pengcheng He, Weizhu Chen, Xiaodong Liu, Jianfeng Gao, and Tuo Zhao. SMART: Robust and efficient fine-tuning for pre-trained natural language models through prin- cipled regularized optimization. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 2177–2190. Association for Computational Linguist...
work page 2020
-
[22]
Enhancing robust fairness via confusional spectral regularization
Gaojie Jin, Sihao Wu, Jiaxu Liu, Tianjin Huang, and Ronghui Mu. Enhancing robust fairness via confusional spectral regularization. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[23]
Wat: improve the worst-class robustness in adversarial training
Boqi Li and Weiwei Liu. Wat: improve the worst-class robustness in adversarial training. In Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence and Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence and Thirteenth Symposium on Educational Advances in Artificial Intelligence, AAAI’23/IAAI’23/EAAI’23. AAAI...
work page 2023
-
[24]
Zhuoyun Li, Boxuan Wang, Jinwei Hu, Zhenglin Huang, Qisong He, Xinmiao Huang, Guan- gliang Cheng, Xiaowei Huang, and Yi Dong. Where do prompt perturbations break generation? a segment-level view of robustness in lora-tuned language models, 2026
work page 2026
-
[25]
PAC-tuning: Fine-tuning pre-trained language models with PAC-driven perturbed gradient descent
Guangliang Liu, Zhiyu Xue, Xitong Zhang, Kristen Johnson, and Rongrong Wang. PAC-tuning: Fine-tuning pre-trained language models with PAC-driven perturbed gradient descent. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12178–12189, Singapore, December 202...
work page 2023
-
[26]
PAC-bayes compression bounds so tight that they can explain generalization
Sanae Lotfi, Marc Anton Finzi, Sanyam Kapoor, Andres Potapczynski, Micah Goldblum, and Andrew Gordon Wilson. PAC-bayes compression bounds so tight that they can explain generalization. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors, Advances in Neural Information Processing Systems, 2022
work page 2022
-
[27]
Sanae Lotfi, Marc Anton Finzi, Yilun Kuang, Tim G. J. Rudner, Micah Goldblum, and An- drew Gordon Wilson. Non-vacuous generalization bounds for large language models. In Proceedings of the 41st International Conference on Machine Learning, volume 235 ofPro- ceedings of Machine Learning Research, pages 32801–32818. PMLR, 2024
work page 2024
-
[28]
Towards deep learning models resistant to adversarial attacks
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks. InInternational Conference on Learning Representations, 2018
work page 2018
-
[29]
Understanding zero- shot adversarial robustness for large-scale models
Chengzhi Mao, Scott Geng, Junfeng Yang, Xin Wang, and Carl V ondrick. Understanding zero- shot adversarial robustness for large-scale models. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[30]
David A. McAllester. PAC-bayesian model averaging. InProceedings of the Twelfth Annual Conference on Computational Learning Theory, COLT ’99, pages 164–170, New York, NY , USA, 1999. ACM
work page 1999
-
[31]
Mistral AI. Mistral-7B-Instruct-v0.2. https://huggingface.co/mistralai/ Mistral-7B-Instruct-v0.2, 2023. Hugging Face model card
work page 2023
-
[32]
Morris, Eli Lifland, Jin Yong Yoo, Jake Grigsby, Di Jin, and Yanjun Qi
John X. Morris, Eli Lifland, Jin Yong Yoo, Jake Grigsby, Di Jin, and Yanjun Qi. TextAttack: A framework for adversarial attacks, data augmentation, and adversarial training in NLP. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 119–126. Association for Computational Linguistics, 2020
work page 2020
-
[33]
Deterministic PAC-bayesian generalization bounds for deep networks via generalizing noise-resilience
Vaishnavh Nagarajan and Zico Kolter. Deterministic PAC-bayesian generalization bounds for deep networks via generalizing noise-resilience. InInternational Conference on Learning Representations, 2019
work page 2019
-
[34]
A PAC- bayesian approach to spectrally-normalized margin bounds for neural networks
Behnam Neyshabur, Srinadh Bhojanapalli, David McAllester, and Nathan Srebro. A PAC- bayesian approach to spectrally-normalized margin bounds for neural networks. InInternational Conference on Learning Representations, 2018
work page 2018
-
[35]
Towards calibrated robust fine-tuning of vision-language models
Changdae Oh, Hyesu Lim, Mijoo Kim, Dongyoon Han, Sangdoo Yun, Jaegul Choo, Alexander Hauptmann, Zhi-Qi Cheng, and Kyungwoo Song. Towards calibrated robust fine-tuning of vision-language models. InAdvances in Neural Information Processing Systems, volume 37, 2024
work page 2024
-
[36]
Parkhi, Andrea Vedaldi, Andrew Zisserman, and C
Omkar M. Parkhi, Andrea Vedaldi, Andrew Zisserman, and C. V . Jawahar. Cats and dogs. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3498–3505, 2012
work page 2012
-
[37]
Prompt perturbation consistency learning for robust language models
Yao Qiang, Subhrangshu Nandi, Ninareh Mehrabi, Greg Ver Steeg, Anoop Kumar, Anna Rumshisky, and Aram Galstyan. Prompt perturbation consistency learning for robust language models. InFindings of the Association for Computational Linguistics: EACL 2024, pages 1357–1370, St. Julian’s, Malta, 2024. Association for Computational Linguistics
work page 2024
-
[38]
Qwen Team. Qwen2.5-1.5B-Instruct. https://huggingface.co/Qwen/Qwen2.5-1. 5B-Instruct, 2024. Hugging Face model card. 12
work page 2024
- [39]
-
[40]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceed- ings of the 38th International Conference on Machine Learning, volume 139 ofProceedings...
work page 2021
-
[41]
Beyond accuracy: Behavioral testing of NLP models with CheckList
Marco Tulio Ribeiro, Tongshuang Wu, Carlos Guestrin, and Sameer Singh. Beyond accuracy: Behavioral testing of NLP models with CheckList. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4902–4912. Association for Computational Linguistics, 2020
work page 2020
-
[42]
Christian Schlarmann, Naman Deep Singh, Francesco Croce, and Matthias Hein. Robust CLIP: Unsupervised adversarial fine-tuning of vision embeddings for robust large vision- language models. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Proceedings of the 41st Internatio...
work page 2024
-
[43]
Improving robust fairness via balance adversarial training
Chunyu Sun, Chenye Xu, Chengyuan Yao, Siyuan Liang, Yichao Wu, Ding Liang, Xianglong Liu, and Aishan Liu. Improving robust fairness via balance adversarial training. InProceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence and Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence and Thirteenth Symposium on Ed...
work page 2023
-
[44]
CommonsenseQA: A question answering challenge targeting commonsense knowledge
Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. CommonsenseQA: A question answering challenge targeting commonsense knowledge. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguis- tics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4149–4158. Association...
work page 2019
-
[45]
Analysis and applications of class- wise robustness in adversarial training
Qi Tian, Kun Kuang, Kelu Jiang, Fei Wu, and Yisen Wang. Analysis and applications of class- wise robustness in adversarial training. InProceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, KDD ’21, page 1561–1570, New York, NY , USA,
-
[46]
Association for Computing Machinery
-
[47]
Adversarial glue: A multi-task benchmark for robustness evaluation of language models
Boxin Wang, Chejian Xu, Shuohang Wang, Shuohang Wang, Zhe Gan, Yu Cheng, Jianfeng Gao, Ahmed Awadallah, and Bo Li. Adversarial glue: A multi-task benchmark for robustness evaluation of language models. In J. Vanschoren and S. Yeung, editors,Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks, volume 1, 2021
work page 2021
-
[48]
Tapt: Test-time adversarial prompt tuning for robust inference in vision-language models
Xin Wang, Kai Chen, Jiaming Zhang, Jingjing Chen, and Xingjun Ma. Tapt: Test-time adversarial prompt tuning for robust inference in vision-language models. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 19910–19920, 2025
work page 2025
-
[49]
Improving robust generalization by direct PAC-bayesian bound minimization
Zifan Wang, Nan Ding, Tomer Levinboim, Xi Chen, and Radu Soricut. Improving robust generalization by direct PAC-bayesian bound minimization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16458–16468, 2023
work page 2023
-
[50]
CFA: Class-wise calibrated fair adversarial training
Zeming Wei, Yifei Wang, Yiwen Guo, and Yisen Wang. CFA: Class-wise calibrated fair adversarial training. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8193–8201, 2023
work page 2023
-
[51]
Adversarial weight perturbation helps robust generalization
Dongxian Wu, Shu-Tao Xia, and Yisen Wang. Adversarial weight perturbation helps robust generalization. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 2958–2969. Curran Associates, Inc., 2020
work page 2020
-
[52]
Han Xu, Xiaorui Liu, Yaxin Li, Anil K. Jain, and Jiliang Tang. To be robust or to be fair: Towards fairness in adversarial training. InProceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, pages 11492–11501. PMLR, 2021. 13
work page 2021
-
[53]
Hongyang Zhang, Yaodong Yu, Jiantao Jiao, Eric Xing, Laurent El Ghaoui, and Michael I. Jordan. Theoretically principled trade-off between robustness and accuracy. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors,Proceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 7472–
-
[54]
PMLR, 09–15 Jun 2019
work page 2019
-
[55]
Adversarial prompt tuning for vision-language models
Jiaming Zhang, Xingjun Ma, Xin Wang, Lingyu Qiu, Jiaqi Wang, Yu-Gang Jiang, and Jitao Sang. Adversarial prompt tuning for vision-language models. InComputer Vision – ECCV 2024: 18th European Conference, Milan, Italy, September 29–October 4, 2024, Proceedings, Part XLV, page 56–72, Berlin, Heidelberg, 2024. Springer-Verlag
work page 2024
-
[56]
Freelb: Enhanced adversarial training for natural language understanding
Chen Zhu, Yu Cheng, Zhe Gan, Siqi Sun, Tom Goldstein, and Jingjing Liu. Freelb: Enhanced adversarial training for natural language understanding. InInternational Conference on Learning Representations, 2020
work page 2020
-
[57]
Promptrobust: Towards evaluating the robustness of large language models on adversarial prompts
Kaijie Zhu, Jindong Wang, Jiaheng Zhou, Zichen Wang, Hao Chen, Yidong Wang, Linyi Yang, Wei Ye, Yue Zhang, Neil Gong, and Xing Xie. Promptrobust: Towards evaluating the robustness of large language models on adversarial prompts. InProceedings of the 1st ACM Workshop on Large AI Systems and Models with Privacy and Safety Analysis, LAMPS ’24, page 57–68, Ne...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.