Recognition: no theorem link
Improving Lexical Difficulty Prediction with Context-Aligned Contrastive Learning and Ridge Ensembling
Pith reviewed 2026-05-12 02:21 UTC · model grok-4.3
The pith
Context-aligned contrastive learning plus ridge ensembles structure word representations to predict lexical difficulty more stably across first languages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Context-Aligned Contrastive Regression integrates ridge regression ensembling with Cross-View Context and Ordinal Soft Contrastive Learning objectives so that the resulting representations simultaneously achieve better cross-lingual alignment, preserve language-specific nuances, and capture the ordinal structure of lexical difficulty, which in turn produces more stable performance across difficulty levels on three L1 datasets.
What carries the argument
Context-Aligned Contrastive Regression, formed by combining a ridge regression ensemble with Cross-View Context Contrastive Learning and Ordinal Soft Contrastive Learning to structure the embedding space.
Load-bearing premise
The two contrastive objectives will structure the embedding space to capture cross-lingual alignment and ordinal difficulty ordering without introducing new biases or requiring extensive per-dataset tuning.
What would settle it
Retraining the same base models on the three L1 datasets using only standard regression loss and finding equivalent or higher accuracy plus alignment metrics than the contrastive-plus-ensemble version.
Figures




read the original abstract
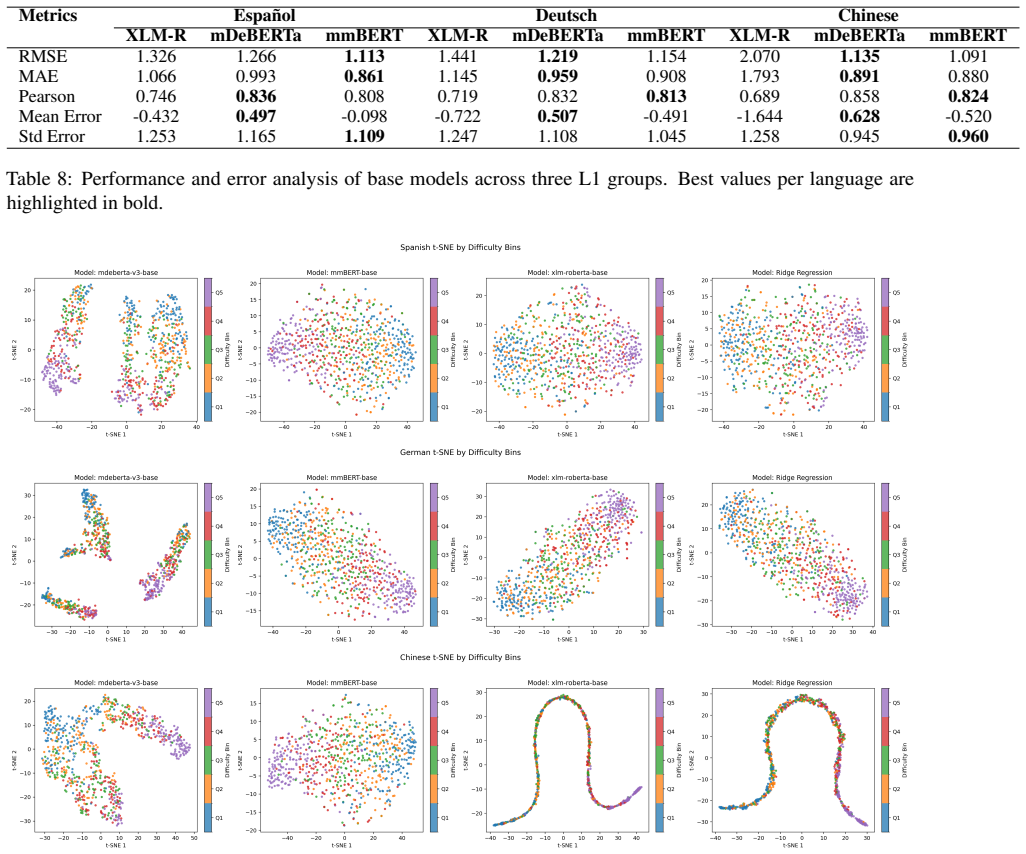
Lexical difficulty prediction is a fundamental problem in language learning and readability assessment, requiring models to estimate word difficulty across different first-language (L1) backgrounds. However, existing approaches rely on regression-only training with scalar supervision, which does not explicitly structure the representation space, limiting their ability to capture cross-lingual alignment and ordinal difficulty. To mitigate these issues, we propose Context-Aligned Contrastive Regression, which integrates Ridge regression ensemble with two complementary objectives, i.e., Cross-View Context and Ordinal Soft Contrastive Learning. Experiments on three L1 datasets show that (i) contrastive objectives improve cross-lingual representation alignment while preserving language-specific nuances, (ii) the learned representations capture the ordinal structure of lexical difficulty, and (iii) the ensemble effectively mitigates systematic biases of individual models, leading to more stable performance across difficulty levels.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Context-Aligned Contrastive Regression for lexical difficulty prediction across L1 backgrounds. It integrates two contrastive objectives (Cross-View Context alignment and Ordinal Soft Contrastive Learning) with a Ridge regression ensemble to structure representations for better cross-lingual alignment, ordinal difficulty ordering, and bias mitigation. Experiments on three L1 datasets are claimed to support improved alignment while preserving nuances, ordinal capture, and stable performance.
Significance. If the empirical claims hold, the work could advance lexical difficulty modeling by moving beyond scalar regression to explicitly structured embeddings that handle both alignment and ordinality. The ridge ensemble for bias mitigation and the dual contrastive objectives represent a practical recipe that may generalize to other ordinal prediction tasks in NLP.
major comments (1)
- [§3.2] §3.2 (Ordinal Soft Contrastive Learning objective): the formulation pulls positives and pushes negatives proportionally to label similarity but contains no explicit ranking constraint (e.g., no term enforcing ||e_i - e_j|| < ||e_i - e_k|| whenever difficulty(d_i) < difficulty(d_j) < difficulty(d_k)). Soft contrastive losses with temperature or margin hyperparameters can be satisfied by non-monotonic clusters while still preserving L1 nuances, which directly undermines claim (ii) that the representations capture ordinal structure; the downstream ridge ensemble cannot recover ordinality that was never encoded.
minor comments (2)
- [Abstract] Abstract: reports positive experimental outcomes on three L1 datasets but omits all quantitative numbers, baseline comparisons, ablation results, and error analysis, making it impossible to assess robustness from the summary alone.
- [§4] §4 (Experiments): the description of hyperparameter selection for the two contrastive objectives across datasets should include whether tuning was performed independently per L1 or shared, to clarify risks of post-hoc choices affecting the reported gains.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review of our manuscript. The comment on the Ordinal Soft Contrastive Learning objective raises a substantive point about the strength of the ordinal constraints in our loss. We address this directly below, clarifying the design rationale while acknowledging where additional evidence would strengthen the presentation. We are prepared to revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Ordinal Soft Contrastive Learning objective): the formulation pulls positives and pushes negatives proportionally to label similarity but contains no explicit ranking constraint (e.g., no term enforcing ||e_i - e_j|| < ||e_i - e_k|| whenever difficulty(d_i) < difficulty(d_j) < difficulty(d_k)). Soft contrastive losses with temperature or margin hyperparameters can be satisfied by non-monotonic clusters while still preserving L1 nuances, which directly undermines claim (ii) that the representations capture ordinal structure; the downstream ridge ensemble cannot recover ordinality that was never encoded.
Authors: We appreciate the referee's precise observation on the loss formulation. The Ordinal Soft Contrastive Learning objective weights positive and negative pairs proportionally to the similarity of their difficulty labels, using a temperature-scaled contrastive term. This graded mechanism is intended to induce a continuous embedding geometry in which distance reflects ordinal proximity: pairs with closer difficulty scores experience stronger attraction, while more distant pairs are repelled more forcefully. Although the loss lacks an explicit hard ranking constraint over all triples, the proportional scaling creates a soft ordering pressure that, in combination with the Cross-View Context Alignment objective, favors monotonic arrangements in the representation space. Our empirical results across the three L1 datasets show improved performance that is stable across difficulty levels, consistent with the representations having captured ordinal structure. We agree, however, that an explicit verification of this property (e.g., correlation between embedding distances and difficulty differences) would provide stronger support for claim (ii) and would also clarify the contribution of the ridge ensemble. We will add such an analysis, together with a brief discussion of the soft versus hard ranking distinction, in the revised manuscript. revision: partial
Circularity Check
No circularity: empirical method with independent experimental validation
full rationale
The paper proposes an empirical training recipe (Context-Aligned Contrastive Regression) that combines two contrastive objectives with a ridge ensemble. All central claims ((i) improved alignment, (ii) ordinal structure capture, (iii) bias mitigation) are presented as outcomes of experiments on held-out portions of three L1 datasets. No mathematical derivation chain exists in the abstract or described method; the objectives are defined as training losses whose effects are measured post-training rather than assumed by construction. No self-citation load-bearing steps, no fitted parameters renamed as predictions, and no ansatz or uniqueness theorem imported from prior author work. The reader's assessment of score 1.0 is consistent with a minor self-citation risk at most, but the core results remain externally falsifiable via the reported metrics.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
and Samatova, Barnokhon and others , title =
Goyibova, Nigora and Muslimov, N. and Samatova, Barnokhon and others , title =. International Journal of Educational Research , year =. doi:10.1016/j.ijer.2025.102501 , url =
-
[2]
Alshumrani, H. A. , title =. Asian Journal of Second and Foreign Language Education , year =. doi:10.1186/s40862-023-00242-0 , url =
-
[3]
Bao, Z. and Peng, C. , title =. Frontiers in Psychology , year =. doi:10.3389/fpsyg.2024.1289106 , url =
- [4]
-
[5]
Journal of Azerbaijan Language and Education Studies , author=
Exploring Language Acquisition: The Role of Native Language Interference in ESL Learners , volume=. Journal of Azerbaijan Language and Education Studies , author=. 2024 , month=. doi:10.69760/jales.2024.00105 , abstractNote=
-
[6]
Pajak, Bozena and Creel, Sarah C. and Levy, Roger , title =. Journal of Experimental Psychology: Learning, Memory, and Cognition , volume =. 2016 , doi =
work page 2016
-
[7]
Behavior Research Methods , volume =
Garten, Justin and Kennedy, Blair and Sagae, Kenji and Dehghani, Morteza , title =. Behavior Research Methods , volume =. 2019 , doi =
work page 2019
- [8]
-
[9]
Publications Manual , year = "1983", publisher =
work page 1983
-
[10]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
- [11]
-
[12]
Dan Gusfield , title =. 1997
work page 1997
-
[13]
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
work page 2015
-
[14]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[15]
S em E val-2021 Task 1: Lexical Complexity Prediction
Shardlow, Matthew and Evans, Richard and Paetzold, Gustavo Henrique and Zampieri, Marcos. S em E val-2021 Task 1: Lexical Complexity Prediction. Proceedings of the 15th International Workshop on Semantic Evaluation (SemEval-2021). 2021. doi:10.18653/v1/2021.semeval-1.1
-
[16]
S em E val 2016 Task 11: Complex Word Identification
Paetzold, Gustavo and Specia, Lucia. S em E val 2016 Task 11: Complex Word Identification. Proceedings of the 10th International Workshop on Semantic Evaluation ( S em E val-2016). 2016. doi:10.18653/v1/S16-1085
-
[17]
Transformer Architectures for Vocabulary Test Item Difficulty Prediction
Skidmore, Lucy and Felice, Mariano and Dunn, Karen. Transformer Architectures for Vocabulary Test Item Difficulty Prediction. Proceedings of the 20th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2025). 2025. doi:10.18653/v1/2025.bea-1.12
-
[18]
The BEA 2024 Shared Task on the Multilingual Lexical Simplification Pipeline
Shardlow, Matthew and Alva-Manchego, Fernando and Batista-Navarro, Riza and Bott, Stefan and Calderon Ramirez, Saul and Cardon, R. The BEA 2024 Shared Task on the Multilingual Lexical Simplification Pipeline. Proceedings of the 19th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2024). 2024
work page 2024
-
[19]
A Report on the Complex Word Identification Shared Task 2018
Yimam, Seid Muhie and Biemann, Chris and Malmasi, Shervin and Paetzold, Gustavo and Specia, Lucia and S tajner, Sanja and Tack, Ana \"i s and Zampieri, Marcos. A Report on the Complex Word Identification Shared Task 2018. Proceedings of the Thirteenth Workshop on Innovative Use of NLP for Building Educational Applications. 2018. doi:10.18653/v1/W18-0507
-
[20]
Inferring Psycholinguistic Properties of Words
Paetzold, Gustavo and Specia, Lucia. Inferring Psycholinguistic Properties of Words. Proceedings of the 2016 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies. 2016. doi:10.18653/v1/N16-1050
-
[21]
CAMB at CWI Shared Task 2018: Complex Word Identification with Ensemble-Based Voting
Gooding, Sian and Kochmar, Ekaterina. CAMB at CWI Shared Task 2018: Complex Word Identification with Ensemble-Based Voting. Proceedings of the Thirteenth Workshop on Innovative Use of NLP for Building Educational Applications. 2018. doi:10.18653/v1/W18-0520
-
[22]
Proceedings of the 37th International Conference on Machine Learning , pages =
A Simple Framework for Contrastive Learning of Visual Representations , author =. Proceedings of the 37th International Conference on Machine Learning , pages =. 2020 , editor =
work page 2020
-
[23]
Representation Learning with Contrastive Predictive Coding , author=. 2019 , eprint=
work page 2019
-
[24]
Supervised Contrastive Learning , url =
Khosla, Prannay and Teterwak, Piotr and Wang, Chen and Sarna, Aaron and Tian, Yonglong and Isola, Phillip and Maschinot, Aaron and Liu, Ce and Krishnan, Dilip , booktitle =. Supervised Contrastive Learning , url =
-
[25]
Journal of Machine Learning Research , year =
Fabian Pedregosa and Francis Bach and Alexandre Gramfort , title =. Journal of Machine Learning Research , year =
-
[26]
Thirty-seventh Conference on Neural Information Processing Systems , year =
Rank-N-Contrast: Learning Continuous Representations for Regression , author =. Thirty-seventh Conference on Neural Information Processing Systems , year =
-
[27]
Frontiers in Neuroscience , volume =
TractoSCR: a Novel Supervised Contrastive Regression Framework for Prediction of Neurocognitive Measures Using Multi-Site Harmonized Diffusion MRI Tractography , author =. Frontiers in Neuroscience , volume =. 2024 , doi =
work page 2024
-
[28]
The Twelfth International Conference on Learning Representations , year =
ConR: Contrastive Regularizer for Deep Imbalanced Regression , author =. The Twelfth International Conference on Learning Representations , year =
-
[29]
Unsupervised Cross-lingual Representation Learning at Scale
Conneau, Alexis and Khandelwal, Kartikay and Goyal, Naman and Chaudhary, Vishrav and Wenzek, Guillaume and Guzm \'a n, Francisco and Grave, Edouard and Ott, Myle and Zettlemoyer, Luke and Stoyanov, Veselin. Unsupervised Cross-lingual Representation Learning at Scale. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. ...
-
[30]
DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-Disentangled Embedding Sharing , author=. 2023 , eprint=
work page 2023
-
[31]
mmBERT: A Modern Multilingual Encoder with Annealed Language Learning , author=. 2025 , eprint=
work page 2025
- [32]
-
[33]
Rotaru, Armand. ANDI at S em E val-2021 Task 1: Predicting complexity in context using distributional models, behavioural norms, and lexical resources. Proceedings of the 15th International Workshop on Semantic Evaluation (SemEval-2021). 2021. doi:10.18653/v1/2021.semeval-1.84
-
[34]
Agree to Disagree: Exploring Subjectivity in Lexical Complexity
Shardlow, Matthew. Agree to Disagree: Exploring Subjectivity in Lexical Complexity. Proceedings of the 2nd Workshop on Tools and Resources to Empower People with REAding DIfficulties (READI) within the 13th Language Resources and Evaluation Conference. 2022
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.