Recognition: 2 theorem links
· Lean TheoremSearchSkill: Teaching LLMs to Use Search Tools with Evolving Skill Banks
Pith reviewed 2026-05-12 01:48 UTC · model grok-4.3
The pith
Language models achieve higher accuracy on knowledge-intensive questions by selecting reusable search skills from an evolving bank before generating queries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SearchSkill makes query planning explicit through reusable search skills. At each step the model first selects a skill, then generates a search or answer action conditioned on the selected skill card. The skill inventory is not fixed: the framework maintains an evolving SkillBank, expands or refines it from recurrent failure patterns, and reconstructs affected trajectories before supervised training. The resulting two-stage SFT recipe aligns training with the inference-time protocol of skill selection followed by skill-grounded execution, producing better exact match scores and improved retrieval behavior on knowledge-intensive QA tasks.
What carries the argument
The evolving SkillBank, a dynamic collection of reusable search skills that the model selects from before conditioning its next action on the skill card.
If this is right
- Higher exact-match scores on knowledge-intensive QA benchmarks for both open-source and closed-source models.
- Fewer copied first queries during search.
- More atomic, hop-focused queries instead of broad ones.
- More correct answers obtained within a fixed small search budget.
Where Pith is reading between the lines
- The same skill-selection mechanism could be applied to other tool-using domains such as code execution or API calls.
- An evolving skill bank might allow models to adapt to new knowledge domains without complete retraining.
- Reduced waste from ineffective queries could lower the computational cost of retrieval-augmented generation pipelines.
Load-bearing premise
Recurrent failure patterns can be automatically identified and converted into refined skills that produce genuinely better model behavior after the two-stage supervised fine-tuning.
What would settle it
No improvement in exact-match scores or no reduction in copied first queries on knowledge-intensive QA benchmarks when the model is trained and evaluated with the SearchSkill procedure versus standard tool-use fine-tuning.
Figures


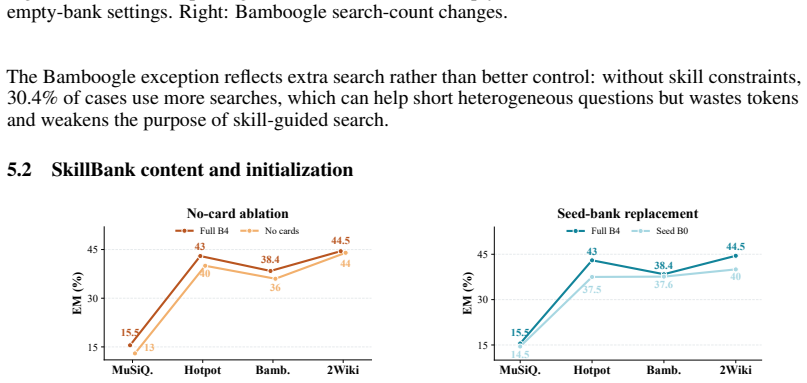
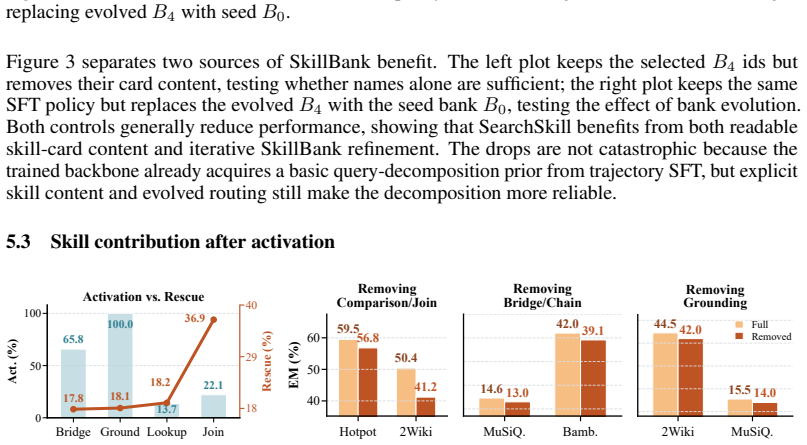







read the original abstract
Teaching language models to use search tools is not only a question of whether they search, but also of whether they issue good queries. This is especially important in open-domain question answering, where broad or copied queries often waste retrieval budget and derail later reasoning. We propose \Ours, a framework that makes query planning explicit through reusable search skills. At each step, the model first selects a skill, then generates a search or answer action conditioned on the selected skill card. The skill inventory itself is not fixed: SearchSkill maintains an evolving SkillBank, expands or refines it from recurrent failure patterns, and reconstructs affected trajectories before supervised training. The resulting two-stage SFT recipe aligns training with the inference-time protocol of skill selection followed by skill-grounded execution. Across open-source and closed-source models, SearchSkill improves exact match on knowledge-intensive QA benchmarks and yields better retrieval behavior, including fewer copied first queries, more atomic hop-focused queries, and more correct answers within a small search budget. These results suggest that explicit skill-conditioned query planning is a lightweight alternative to treating search as an undifferentiated action.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SearchSkill, a framework for improving LLM search tool use in open-domain QA by making query planning explicit: at each step the model selects a reusable skill from an evolving SkillBank and then generates a skill-conditioned search or answer action. The SkillBank is dynamically expanded or refined from automatically detected recurrent failure patterns, after which affected trajectories are reconstructed; a two-stage SFT procedure then aligns the training distribution with the inference-time protocol of skill selection followed by skill-grounded execution. The central empirical claim is that this yields higher exact-match scores on knowledge-intensive QA benchmarks for both open- and closed-source models, together with improved retrieval behavior (fewer copied first queries, more atomic hop-focused queries, and higher success rates within a small search budget).
Significance. If the reported gains are reproducible and the evolving-SkillBank component is shown to be responsible for them, the work would offer a lightweight, interpretable alternative to undifferentiated tool-use fine-tuning. Explicit skill cards and failure-driven evolution could reduce wasted retrieval budget and improve multi-hop reasoning efficiency; the two-stage SFT alignment is a sound design choice that matches training to inference. The absence of any quantitative results, baselines, or ablations in the provided description, however, prevents a firm assessment of whether these benefits materialize or whether they stem primarily from the skill-conditioned action format rather than the evolution mechanism.
major comments (2)
- [§4 and §3.2] §4 (Experiments) and §3.2 (SkillBank Evolution): the central attribution of gains to the evolving SkillBank is not supported by any ablation that compares the full method against a fixed initial SkillBank under the identical two-stage SFT protocol. Without this isolation, improvements could arise entirely from the skill-selection format and SFT alignment rather than from automatic failure-pattern refinement and trajectory reconstruction.
- [Results section] Results section: the abstract asserts exact-match improvements and better retrieval statistics (fewer copied queries, more atomic hops, higher success within budget) yet supplies no tables, numerical values, baseline comparisons (e.g., ReAct, standard tool-use SFT), number of runs, or statistical tests. This absence makes it impossible to judge whether the data support the stated claims.
minor comments (2)
- [§3] Notation for the SkillBank and skill cards is introduced without a clear formal definition or example card; a table or figure showing an initial SkillBank and an evolved entry would improve readability.
- [§3.2] The description of how recurrent failure patterns are automatically identified and turned into new or refined skills lacks pseudocode or a concrete example, leaving the evolution procedure underspecified.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that stronger isolation of the evolving SkillBank's contribution and more explicit quantitative reporting are needed to support the central claims. We address each major comment below.
read point-by-point responses
-
Referee: [§4 and §3.2] §4 (Experiments) and §3.2 (SkillBank Evolution): the central attribution of gains to the evolving SkillBank is not supported by any ablation that compares the full method against a fixed initial SkillBank under the identical two-stage SFT protocol. Without this isolation, improvements could arise entirely from the skill-selection format and SFT alignment rather than from automatic failure-pattern refinement and trajectory reconstruction.
Authors: We agree that the manuscript does not contain an ablation isolating the evolving SkillBank against a fixed initial SkillBank under the identical two-stage SFT protocol. The reported experiments compare the full SearchSkill pipeline to ReAct and standard tool-use SFT baselines, but do not include this specific control. We will add the requested ablation in the revised version to demonstrate whether the automatic failure-pattern detection and trajectory reconstruction contribute beyond the skill-selection format and SFT alignment alone. revision: yes
-
Referee: [Results section] Results section: the abstract asserts exact-match improvements and better retrieval statistics (fewer copied queries, more atomic hops, higher success within budget) yet supplies no tables, numerical values, baseline comparisons (e.g., ReAct, standard tool-use SFT), number of runs, or statistical tests. This absence makes it impossible to judge whether the data support the stated claims.
Authors: We acknowledge that the submitted version does not present tables, numerical values, baseline comparisons, run counts, or statistical tests in the results section. The full manuscript will be revised to include comprehensive tables reporting exact-match scores, retrieval behavior metrics, direct comparisons to ReAct and standard tool-use SFT, experimental details on the number of runs, and any statistical tests. The abstract will also be updated to reference these concrete results. revision: yes
Circularity Check
No circularity; empirical framework evaluated on external benchmarks
full rationale
The paper describes SearchSkill as an empirical training recipe: explicit skill selection followed by skill-grounded execution, with an evolving SkillBank that identifies recurrent failures, expands or refines skills, and reconstructs trajectories for a two-stage SFT procedure. All performance claims (exact-match gains, fewer copied queries, more atomic hops, higher success within budget) are presented as outcomes measured on held-out knowledge-intensive QA benchmarks across open- and closed-source models. No equations, uniqueness theorems, or self-citations are invoked to derive results by construction; the method is not self-definitional, and no fitted parameter is relabeled as a prediction. The derivation chain is therefore self-contained against external evaluation.
Axiom & Free-Parameter Ledger
invented entities (1)
-
SkillBank
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearAt each step, the model first selects a skill, then generates a search or answer action conditioned on the selected skill card. The skill inventory itself is not fixed: SearchSkill maintains an evolving SkillBank, expands or refines it from recurrent failure patterns...
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe optimize Lexec(θ) ... Lbank(θ) ... two-stage supervised fine-tuning recipe
Reference graph
Works this paper leans on
-
[1]
Self-rag: Learn- ing to retrieve, generate, and critique through self-reflection
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self-rag: Learn- ing to retrieve, generate, and critique through self-reflection. InThe Twelfth International Conference on Learning Representations, 2023
work page 2023
-
[2]
Rae, Erich Elsen, and Laurent Sifre
Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George van den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, Diego de Las Casas, Aurelia Guy, Jacob Menick, Roman Ring, Tom Hennigan, Saffron Huang, Loren Maggiore, Chris Jones, Albin Cassirer, Andy Brock, Michela Paganini, Geoffrey Irving, Ori...
work page 2022
-
[3]
Unified active retrieval for retrieval augmented generation
Qinyuan Cheng, Xiaonan Li, Shimin Li, Qin Zhu, Zhangyue Yin, Yunfan Shao, Linyang Li, Tianxiang Sun, Hang Yan, and Xipeng Qiu. Unified active retrieval for retrieval augmented generation. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 17153–17166, 2024
work page 2024
-
[4]
Retrieval augmented language model pre-training
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Mingwei Chang. Retrieval augmented language model pre-training. InInternational conference on machine learning, pages 3929–3938. PMLR, 2020
work page 2020
-
[5]
Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps. InProceedings of the 28th International Conference on Computational Linguistics, pages 6609–6625, 2020
work page 2020
-
[6]
Cascade: Cumulative agentic skill creation through autonomous development and evolution
Xu Huang, Junwu Chen, Yuxing Fei, Zhuohan Li, Philippe Schwaller, and Gerbrand Ceder. Cascade: Cumulative agentic skill creation through autonomous development and evolution. arXiv preprint arXiv:2512.23880, 2025
-
[7]
Leveraging passage retrieval with generative models for open domain question answering
Gautier Izacard and Edouard Grave. Leveraging passage retrieval with generative models for open domain question answering. InProceedings of the 16th conference of the european chapter of the association for computational linguistics: main volume, pages 874–880, 2021
work page 2021
-
[8]
Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Timo Schick, Jane Dwivedi-Yu, Armand Joulin, Sebastian Riedel, and Edouard Grave. Atlas: Few-shot learning with retrieval augmented language models.Journal of Machine Learning Research, 24(251): 1–43, 2023
work page 2023
-
[9]
Pengcheng Jiang, Jiacheng Lin, Lang Cao, Runchu Tian, SeongKu Kang, Zifeng Wang, Jimeng Sun, and Jiawei Han. Deepretrieval: Hacking real search engines and retrievers with large language models via reinforcement learning, 2025. URL https://arxiv.org/abs/2503. 00223
work page 2025
-
[10]
Active retrieval augmented generation
Zhengbao Jiang, Frank F Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. Active retrieval augmented generation. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 7969–7992, 2023
work page 2023
-
[11]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Za- mani, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning, 2025. URLhttps://arxiv.org/abs/2503.09516
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension
Mandar Joshi, Eunsol Choi, Daniel S Weld, and Luke Zettlemoyer. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1601–1611, 2017. 10
work page 2017
-
[13]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pages 6769–6781, 2020
work page 2020
-
[14]
Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. Natural questions: A benchmark for question answering research.Transact...
work page 2019
-
[15]
Retrieval-augmented generation for knowledge-intensive nlp tasks, 2020
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive nlp tasks, 2020
work page 2020
-
[16]
arXiv preprint arXiv:2603.02176 , year=
Hao Li, Chunjiang Mu, Jianhao Chen, Siyue Ren, Zhiyao Cui, Yiqun Zhang, Lei Bai, and Shuyue Hu. Organizing, orchestrating, and benchmarking agent skills at ecosystem scale, 2026. URLhttps://arxiv.org/abs/2603.02176
-
[17]
Search-o1: Agentic Search-Enhanced Large Reasoning Models
Xiaoxi Li, Guanting Dong, Jiajie Jin, Yuyao Zhang, Yujia Zhou, Yutao Zhu, Peitian Zhang, and Zhicheng Dou. Search-o1: Agentic search-enhanced large reasoning models, 2025. URL https://arxiv.org/abs/2501.05366
work page internal anchor Pith review arXiv 2025
-
[18]
arXiv preprint arXiv:2602.08004 , year=
George Ling, Shanshan Zhong, and Richard Huang. Agent skills: A data-driven analysis of claude skills for extending large language model functionality, 2026. URL https://arxiv. org/abs/2602.08004
-
[19]
Agent skills in the wild: An empirical study of security vulnerabilities at scale,
Yi Liu, Weizhe Wang, Ruitao Feng, Yao Zhang, Guangquan Xu, Gelei Deng, Yuekang Li, and Leo Zhang. Agent skills in the wild: An empirical study of security vulnerabilities at scale,
- [20]
-
[21]
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Ha- jishirzi. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories. InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers), pages 9802–9822, 2023
work page 2023
-
[22]
WebGPT: Browser-assisted question-answering with human feedback
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christo- pher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, Xu Jiang, Karl Cobbe, Tyna Eloundou, Gretchen Krueger, Kevin Button, Matthew Knight, Benjamin Chess, and John Schulman. Webgpt: Browser-assisted question-answering with human feedback, 2022. URL https:/...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
Measuring and narrowing the compositionality gap in language models
Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A Smith, and Mike Lewis. Measuring and narrowing the compositionality gap in language models. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 5687–5711, 2023
work page 2023
-
[24]
arXiv preprint arXiv.2304.08354,
Yujia Qin, Shengding Hu, Yankai Lin, Weize Chen, Ning Ding, Ganqu Cui, Zheni Zeng, Yufei Huang, Chaojun Xiao, Chi Han, Yi Ren Fung, Yusheng Su, Huadong Wang, Cheng Qian, Runchu Tian, Kunlun Zhu, Shihao Liang, Xingyu Shen, Bokai Xu, Zhen Zhang, Yining Ye, Bowen Li, Ziwei Tang, Jing Yi, Yuzhang Zhu, Zhenning Dai, Lan Yan, Xin Cong, Yaxi Lu, Weilin Zhao, Yux...
-
[25]
Qwen Team. Qwen2.5 technical report, 2025. URL https://arxiv.org/abs/2412.15115
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems, 36: 68539–68551, 2023
work page 2023
-
[27]
R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning
Huatong Song, Jinhao Jiang, Yingqian Min, Jie Chen, Zhipeng Chen, Wayne Xin Zhao, Lei Fang, and Ji-Rong Wen. R1-searcher: Incentivizing the search capability in llms via reinforcement learning.arXiv preprint arXiv:2503.05592, 2025. 11
work page internal anchor Pith review arXiv 2025
-
[28]
Hao Sun, Zile Qiao, Jiayan Guo, Xuanbo Fan, Yingyan Hou, Yong Jiang, Pengjun Xie, Yan Zhang, Fei Huang, and Jingren Zhou. Zerosearch: Incentivize the search capability of llms without searching, 2025. URLhttps://arxiv.org/abs/2505.04588
-
[29]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. MuSiQue: Multihop questions via single-hop question composition.Transactions of the Association for Computational Linguistics, 10:539–554, 2022
work page 2022
-
[30]
Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions. In Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers), pages 10014–10037, 2023
work page 2023
-
[31]
Reinforcement learning for self-improving agent with skill library, 2025
Jiongxiao Wang, Qiaojing Yan, Yawei Wang, Yijun Tian, Soumya Smruti Mishra, Zhichao Xu, Megha Gandhi, Panpan Xu, and Lin Lee Cheong. Reinforcement learning for self-improving agent with skill library.arXiv preprint arXiv:2512.17102, 2025
-
[32]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. Text embeddings by weakly-supervised contrastive pre-training. arXiv preprint arXiv:2212.03533, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[33]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models, 2022. URLhttps://arxiv.org/abs/2201.11903
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[34]
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
Peng Xia, Jianwen Chen, Hanyang Wang, Jiaqi Liu, Kaide Zeng, Yu Wang, Siwei Han, Yiyang Zhou, Xujiang Zhao, Haifeng Chen, Zeyu Zheng, Cihang Xie, and Huaxiu Yao. Skillrl: Evolving agents via recursive skill-augmented reinforcement learning, 2026. URL https: //arxiv.org/abs/2602.08234
work page internal anchor Pith review arXiv 2026
-
[35]
Hotpotqa: A dataset for diverse, explainable multi-hop question answering
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 conference on empirical methods in natural language processing, pages 2369–2380, 2018
work page 2018
-
[36]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[37]
MemSkill: Learning and Evolving Memory Skills for Self-Evolving Agents
Haozhen Zhang, Quanyu Long, Jianzhu Bao, Tao Feng, Weizhi Zhang, Haodong Yue, and Wenya Wang. Memskill: Learning and evolving memory skills for self-evolving agents.arXiv preprint arXiv:2602.02474, 2026
work page internal anchor Pith review arXiv 2026
-
[38]
SkillWeaver: Web Agents can Self-Improve by Discovering and Honing Skills
Boyuan Zheng, Michael Y . Fatemi, Xiaolong Jin, Zora Zhiruo Wang, Apurva Gandhi, Yueqi Song, Yu Gu, Jayanth Srinivasa, Gaowen Liu, Graham Neubig, and Yu Su. Skillweaver: Web agents can self-improve by discovering and honing skills, 2025. URL https://arxiv.org/ abs/2504.07079. A Experimental setups A.1 Data process We construct the training pool with a cov...
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.