Recognition: 2 theorem links
· Lean TheoremInvestigating Anisotropy in Visual Grounding under Controlled Counterfactual Perturbations
Pith reviewed 2026-05-12 02:17 UTC · model grok-4.3
The pith
Embedding anisotropy shows no correlation with visual grounding models' approximation on mismatched captions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
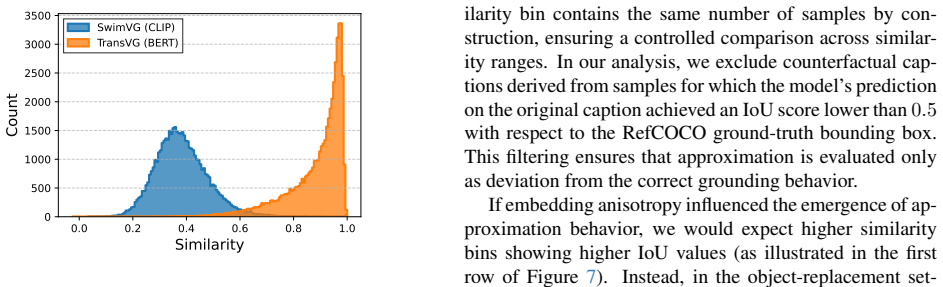
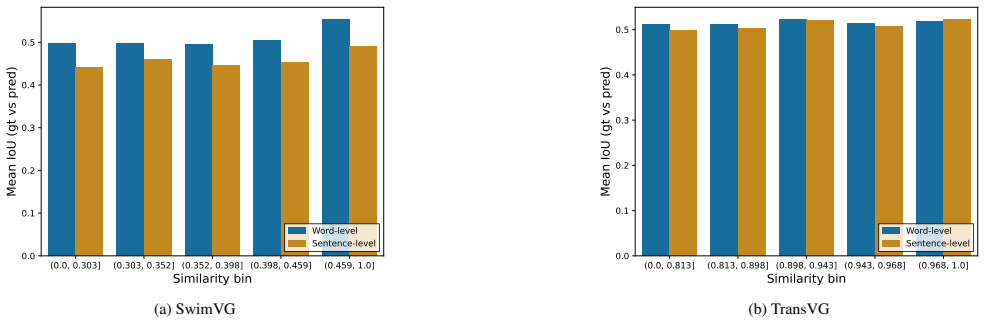
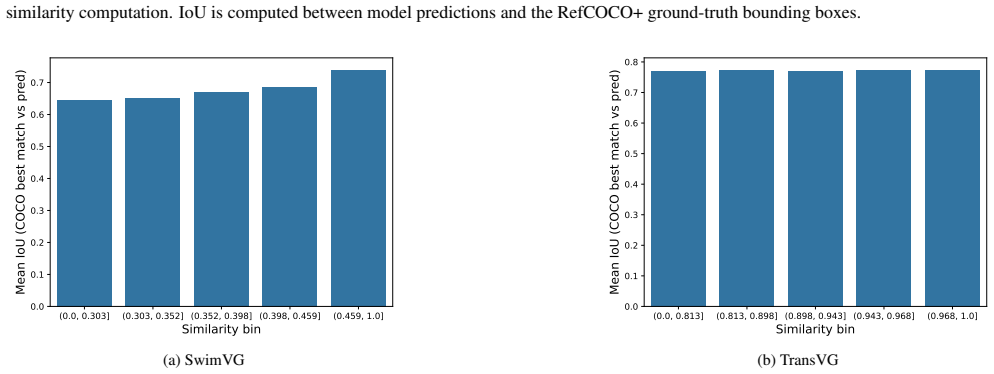
Adopting a mechanistic interpretability approach, the work applies a similarity-controlled counterfactual caption generation protocol to perturb object or contextual components within predefined embedding similarity intervals. Experiments on BERT-based TransVG and CLIP-based SwimVG models reveal no meaningful correlation between cosine similarity and approximation behavior, indicating that anisotropy does not account for counterfactual failures in visual grounding.
What carries the argument
Similarity-controlled counterfactual caption generation protocol that perturbs object or contextual components within predefined embedding similarity intervals to measure grounding behavior as a function of alignment.
If this is right
- Robustness improvements in visual grounding must target finer-grained geometric properties of the embedding space rather than anisotropy alone.
- Counterfactual errors in grounding models occur independently of cosine similarity levels across the tested architectures.
- Mechanistic analysis should next examine factors such as attention patterns or multi-component alignment to explain approximation behavior.
Where Pith is reading between the lines
- The same controlled perturbation approach could be applied to other vision-language tasks to test whether the absence of correlation is specific to grounding.
- Evaluation benchmarks for visual grounding should routinely include mismatched captions to expose approximation tendencies that current metrics overlook.
- Training objectives that explicitly discourage partial satisfaction of referring expressions may prove more effective than adjustments to embedding geometry.
Load-bearing premise
The similarity-controlled counterfactual caption generation protocol isolates anisotropy effects without introducing confounding changes in semantic content or model attention patterns.
What would settle it
A replication experiment that finds a strong correlation between cosine similarity and approximation rates when applying the same protocol to additional models would falsify the central claim.
Figures




read the original abstract
Visual Grounding benchmarks assume that the object described by a referring expression is always present in the image, and grounding models are therefore rarely evaluated under semantically mismatched captions. In such cases, models frequently exhibit approximation behavior, producing a plausible bounding box that satisfies only part of the expression (\eg, preserving the original object while ignoring modified contextual cues). Because mismatched captions represent realistic edge cases, this behavior compromises reliability and raises concerns from an explainability perspective. Identifying its underlying causes is thus essential for improving model faithfulness and interpretability. Adopting a mechanistic interpretability viewpoint, this work examines whether embedding anisotropy contributes to counterfactual failures. A similarity-controlled counterfactual caption generation protocol is introduced to systematically perturb object or contextual components within predefined embedding similarity intervals, enabling a fine-grained analysis of grounding behavior as a function of alignment. Experiments on two Transformer-based models with markedly different embedding geometries (BERT-based TransVG and CLIP-based SwimVG) reveal no meaningful correlation between cosine similarity and approximation. These findings suggest that anisotropy alone does not account for counterfactual errors, and that robustness requires investigating finer-grained geometric properties of the embedding space.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that embedding anisotropy does not explain approximation behavior in visual grounding under counterfactual mismatched captions. Using a new similarity-controlled counterfactual caption generation protocol that perturbs object or contextual components within fixed cosine-similarity intervals, experiments on two Transformer models with different embedding geometries (BERT-based TransVG and CLIP-based SwimVG) find no meaningful correlation between cosine similarity and the models' tendency to produce partial matches. The authors conclude that robustness improvements must target finer-grained geometric properties beyond anisotropy.
Significance. If the null result is robust, the work is significant for mechanistic interpretability in multimodal grounding: it provides a negative finding that rules out a plausible geometric explanation for a known failure mode, thereby narrowing the search space for causes of unfaithful behavior and motivating study of other embedding-space properties. The controlled protocol and dual-model design are strengths that could make the result reusable for future ablation studies.
major comments (2)
- [§3 and §4] §3 (Method) and §4 (Experiments): the similarity-controlled counterfactual protocol is presented as isolating anisotropy effects, yet no quantitative checks (e.g., attention-map stability, token-level contribution scores, or semantic decomposition metrics) are reported across the cosine-similarity bands. Without such controls, any observed lack of correlation could be confounded by unintended shifts in attention patterns or partial semantics, directly undermining the central claim that anisotropy alone does not account for the errors.
- [§4.2] §4.2 (Results): the abstract and results state 'no meaningful correlation' between cosine similarity and approximation, but the manuscript provides no details on the precise approximation metric, the statistical test employed, effect-size thresholds, or confidence intervals. This absence prevents verification of the strength of the null finding and makes it impossible to assess whether the result is robust to reasonable variations in analysis choices.
minor comments (1)
- [Abstract / §2] The abstract and introduction use 'approximation behavior' without an early formal definition; a concise operational definition should appear in §2 or the start of §3.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our controlled counterfactual protocol and strengthen the statistical reporting. We address each major point below and commit to revisions where the manuscript is incomplete.
read point-by-point responses
-
Referee: [§3 and §4] §3 (Method) and §4 (Experiments): the similarity-controlled counterfactual protocol is presented as isolating anisotropy effects, yet no quantitative checks (e.g., attention-map stability, token-level contribution scores, or semantic decomposition metrics) are reported across the cosine-similarity bands. Without such controls, any observed lack of correlation could be confounded by unintended shifts in attention patterns or partial semantics, directly undermining the central claim that anisotropy alone does not account for the errors.
Authors: The protocol generates counterfactuals by targeted replacement of object or context phrases while enforcing that the full caption embedding remains inside a narrow cosine-similarity band relative to the original; this construction directly constrains global alignment. Nevertheless, we agree that local attention or contribution shifts could still vary within a band and potentially confound the null result. In the revision we will add (i) attention-map stability measured by cosine similarity of attention weights on the perturbed tokens across similarity bands and (ii) a simple token-level contribution score (gradient-based) averaged per band. These supplementary checks will be reported in a new subsection of §4. revision: partial
-
Referee: [§4.2] §4.2 (Results): the abstract and results state 'no meaningful correlation' between cosine similarity and approximation, but the manuscript provides no details on the precise approximation metric, the statistical test employed, effect-size thresholds, or confidence intervals. This absence prevents verification of the strength of the null finding and makes it impossible to assess whether the result is robust to reasonable variations in analysis choices.
Authors: We accept that the current text omits these operational details. The approximation metric is the fraction of trials in which the predicted box overlaps the ground-truth object box by IoU > 0.5 while failing to satisfy the modified contextual cue (i.e., partial match). Correlation is assessed with Pearson’s r together with 95 % bootstrap confidence intervals and a pre-specified negligible-effect threshold of |r| < 0.15. We will insert a dedicated paragraph in §4.2 that defines the metric, states the test, reports the exact r values, p-values, CIs, and the threshold used for each model and perturbation type. revision: yes
Circularity Check
No circularity: empirical measurement of correlation under controlled perturbations
full rationale
The paper is an empirical study that introduces a similarity-controlled counterfactual caption protocol and measures grounding behavior (approximation) as a function of cosine similarity on two models. The central claim is the observed lack of correlation, which is a direct experimental result rather than a derivation or fitted prediction. No equations, self-definitional steps, or load-bearing self-citations appear in the provided text; the protocol is a methodological contribution whose validity is assessed by the measurements themselves, not by reducing to prior inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Cosine similarity in embedding space is a valid proxy for semantic alignment between original and perturbed captions.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearExperiments on two Transformer-based models... reveal no meaningful correlation between cosine similarity and approximation.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclearA similarity-controlled counterfactual caption generation protocol... within predefined embedding similarity intervals
Reference graph
Works this paper leans on
-
[1]
Billion-scale pretraining with vision transformers for multi-task visual representations
Josh Beal, Hao-Yu Wu, Dong Huk Park, Andrew Zhai, and Dmitry Kislyuk. Billion-scale pretraining with vision transformers for multi-task visual representations. In2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), page 1431–1440, Waikoloa, HI, USA, 2022. IEEE. 1
work page 2022
-
[2]
Silin Cheng, Yang Liu, Xinwei He, Sebastien Ourselin, Lei Tan, and Gen Luo. Weakmcn: Multi-task collaborative net- work for weakly supervised referring expression compre- hension and segmentation. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), page 9175–9185, 2025. ISSN: 2575-7075. 2
work page 2025
-
[3]
Jiajun Deng, Zhengyuan Yang, Daqing Liu, Tianlang Chen, Wengang Zhou, Yanyong Zhang, Houqiang Li, and Wanli Ouyang. Transvg++: End-to-end visual grounding with language conditioned vision transformer.IEEE Transac- tions on Pattern Analysis and Machine Intelligence, 45(11): 13636–13652, 2023. 2, 3, 5
work page 2023
-
[4]
Bert: Pre-training of deep bidirectional trans- formers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional trans- formers for language understanding. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Lan- guage Technologies, Volume 1 (Long and Short Papers), page 4171–4186, Minneapol...
work page 2019
-
[5]
On isotropy calibration of transformer models
Yue Ding, Karolis Martinkus, Damian Pascual, Simon Clematide, and Roger Wattenhofer. On isotropy calibration of transformer models. InProceedings of the Third Work- shop on Insights from Negative Results in NLP, page 1–9, Dublin, Ireland, 2022. Association for Computational Lin- guistics. 1, 3, 6
work page 2022
-
[6]
Kawin Ethayarajh. How contextual are contextualized word representations? comparing the geometry of bert, elmo, and gpt-2 embeddings. InProceedings of the 2019 Confer- ence on Empirical Methods in Natural Language Process- ing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), page 55–65, Hong Kong, China, 2019. Asso...
work page 2019
-
[7]
Modularized textual grounding for counterfactual re- silience
Zhiyuan Fang, Shu Kong, Charless Fowlkes, and Yezhou Yang. Modularized textual grounding for counterfactual re- silience. In2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), page 6371–6381, 2019. ISSN: 2575-7075. 3, 4
work page 2019
-
[8]
Alejandro Fuster Baggetto and Victor Fresno. Is anisotropy really the cause of bert embeddings not being semantic? In Findings of the Association for Computational Linguistics: EMNLP 2022, page 4271–4281, Abu Dhabi, United Arab Emirates, 2022. Association for Computational Linguistics. 1, 3, 6
work page 2022
-
[9]
Anisotropy is inherent to self-attention in transformers
Nathan Godey, ´Eric Clergerie, and Benoˆıt Sagot. Anisotropy is inherent to self-attention in transformers. InProceedings of the 18th Conference of the European Chapter of the Asso- ciation for Computational Linguistics (Volume 1: Long Pa- pers), page 35–48, St. Julian’s, Malta, 2024. Association for Computational Linguistics. 3
work page 2024
-
[10]
Lixia Ji, Yunlong Du, Yiping Dang, Wenzhao Gao, and Han Zhang. A survey of methods for addressing the chal- lenges of referring image segmentation.Neurocomputing, 583:127599, 2024. 2
work page 2024
-
[11]
Refclip: A universal teacher for weakly supervised referring expression comprehension
Lei Jin, Gen Luo, Yiyi Zhou, Xiaoshuai Sun, Guannan Jiang, Annan Shu, and Rongrong Ji. Refclip: A universal teacher for weakly supervised referring expression comprehension. In2023 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), page 01–10, 2023. ISSN: 2575-
work page 2023
-
[12]
Yongmin Kim, Chenhui Chu, and Sadao Kurohashi. Flexible visual grounding. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics: Student Research Workshop, page 285–299, Dublin, Ireland, 2022. Association for Computational Linguistics. 2
work page 2022
-
[13]
Berg, Wan-Yen Lo, Piotr Doll ´ar, and Ross Girshick
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C. Berg, Wan-Yen Lo, Piotr Doll ´ar, and Ross Girshick. Segment anything. In2023 IEEE/CVF In- ternational Conference on Computer Vision (ICCV), page 3992–4003, 2023. ISSN: 2380-7504. 3
work page 2023
-
[14]
Hongbing Li, Xinran Wang, Linyi Yang, Qi Li, and Bo Xiao. Sala: Semantic alignment and localization alignment for vi- sual grounding.Neurocomputing, 654:131265, 2025. 2
work page 2025
-
[15]
Iterative robust visual grounding with masked reference based centerpoint supervision
Menghao Li, Chunlei Wang, Wenquan Feng, Shuchang Lyu, Guangliang Cheng, Xiangtai Li, Binghao Liu, and Qi Zhao. Iterative robust visual grounding with masked reference based centerpoint supervision. In2023 IEEE/CVF Interna- tional Conference on Computer Vision Workshops (ICCVW), page 4653–4658, 2023. ISSN: 2473-9944. 2
work page 2023
-
[16]
Benchmark evalua- tions, applications, and challenges of large vision language models: A survey,
Zongxia Li, Xiyang Wu, Hongyang Du, Fuxiao Liu, Huy Nghiem, and Guangyao Shi. A survey of state of the art large vision language models: Alignment, benchmark, evaluations and challenges. (arXiv:2501.02189), 2025. arXiv:2501.02189 [cs]. 1
-
[17]
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C. Lawrence Zitnick. Microsoft coco: Common objects in context. In Computer Vision – ECCV 2014, page 740–755, Cham, 2014. Springer International Publishing. 2, 4
work page 2014
-
[18]
Jingyu Liu, Liang Wang, and Ming Hsuan Yang. Refer- ring expression generation and comprehension via attributes: 16th ieee international conference on computer vision, iccv
-
[19]
page 4866–4874, 2017. 2
work page 2017
-
[20]
Grounding dino: Mar- rying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, and Lei Zhang. Grounding dino: Mar- rying dino with grounded pre-training for open-set object detection. InComputer Vision – ECCV 2024, page 38–55, Cham, 2025. Springer Nature Switzerland. 3
work page 2024
-
[21]
Generation and comprehension of unambiguous object descriptions
Junhua Mao, Jonathan Huang, Alexander Toshev, Oana Camburu, Alan Yuille, and Kevin Murphy. Generation and comprehension of unambiguous object descriptions. In2016 IEEE Conference on Computer Vision and Pattern Recogni- tion (CVPR), page 11–20, 2016. 1, 2
work page 2016
-
[22]
George A. Miller. Wordnet: A lexical database for english. In Speech and Natural Language: Proceedings of a Workshop Held at Harriman, New York, February 23-26, 1992, 1992. 4
work page 1992
-
[23]
The strange geome- try of skip-gram with negative sampling
David Mimno and Laure Thompson. The strange geome- try of skip-gram with negative sampling. InProceedings of the 2017 Conference on Empirical Methods in Natural Lan- guage Processing, page 2873–2878, Copenhagen, Denmark,
work page 2017
-
[24]
Association for Computational Linguistics. 3, 6
-
[25]
Bonan Min, Hayley Ross, Elior Sulem, Amir Pouran Ben Veyseh, Thien Huu Nguyen, Oscar Sainz, Eneko Agirre, Ilana Heintz, and Dan Roth. Recent advances in natural lan- guage processing via large pre-trained language models: A survey.ACM Comput. Surv., 56(2):30:1–30:40, 2023. 1
work page 2023
-
[26]
explo- sion/spacy: v3.7.2: Fixes for apis and requirements, 2023
Ines Montani, Matthew Honnibal, Matthew Honnibal, Adri- ane Boyd, Sofie Van Landeghem, and Henning Peters. explo- sion/spacy: v3.7.2: Fixes for apis and requirements, 2023. 4
work page 2023
-
[27]
Maxime Oquab, Timoth ´ee Darcet, Th´eo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel HAZIZA, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herve Je- gou, Julien Mairal, Patr...
work page 2024
-
[28]
Kosmos-2: Grounding Multimodal Large Language Models to the World
Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, and Furu Wei. Kosmos-2: Ground- ing multimodal large language models to the world. (arXiv:2306.14824), 2023. arXiv:2306.14824 [cs]. 3
work page internal anchor Pith review arXiv 2023
-
[29]
Bryan A. Plummer, Liwei Wang, Chris M. Cervantes, Juan C. Caicedo, Julia Hockenmaier, and Svetlana Lazeb- nik. Flickr30k entities: Collecting region-to-phrase corre- spondences for richer image-to-sentence models. In2015 IEEE International Conference on Computer Vision (ICCV), page 2641–2649, 2015. 1, 2
work page 2015
-
[30]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine Learning, page 8748–8763. PMLR, 2021. 3
work page 2021
-
[31]
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. (arXiv:1506.01497), 2016. arXiv:1506.01497 [cs]. 7
-
[32]
Liangtao Shi, Ting Liu, Xiantao Hu, Yue Hu, Quanjun Yin, and Richang Hong. Swimvg: Step-wise multimodal fusion and adaption for visual grounding.IEEE Transactions on Multimedia, page 1–12, 2025. 2, 3, 5
work page 2025
-
[34]
arXiv:1706.03762 [cs]. 2
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Use: Universal segment embeddings for open-vocabulary image segmenta- tion
Xiaoqi Wang, Wenbin He, Xiwei Xuan, Clint Sebastian, Jorge Piazentin Ono, Xin Li, Sima Behpour, Thang Doan, Liang Gou, Han-Wei Shen, and Liu Ren. Use: Universal segment embeddings for open-vocabulary image segmenta- tion. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), page 4187–4196, 2024. ISSN: 2575-7075. 3
work page 2024
-
[36]
Robert Wolfe and Aylin Caliskan. Contrastive visual seman- tic pretraining magnifies the semantics of natural language representations. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), page 3050–3061, Dublin, Ireland, 2022. As- sociation for Computational Linguistics. 6
work page 2022
-
[37]
Florence-2: Advancing a unified representation for a variety of vision tasks
Bin Xiao, Haiping Wu, Weijian Xu, Xiyang Dai, Houdong Hu, Yumao Lu, Michael Zeng, Ce Liu, and Lu Yuan. Florence-2: Advancing a unified representation for a variety of vision tasks. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), page 4818–4829,
-
[38]
Reme: A data-centric framework for training-free open-vocabulary segmentation
Xiwei Xuan, Ziquan Deng, and Kwan-Liu Ma. Reme: A data-centric framework for training-free open-vocabulary segmentation. (arXiv:2506.21233), 2025. arXiv:2506.21233 [cs]. 3
-
[39]
Jiabo Ye, Junfeng Tian, Ming Yan, Xiaoshan Yang, Xuwu Wang, Ji Zhang, Liang He, and Xin Lin. Shifting more atten- tion to visual backbone: Query-modulated refinement net- works for end-to-end visual grounding. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), page 15481–15491, 2022. 2
work page 2022
-
[40]
Peter Young, Alice Lai, Micah Hodosh, and Julia Hocken- maier. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descrip- tions.Transactions of the Association for Computational Linguistics, 2:67–78, 2014. 2
work page 2014
-
[41]
Licheng Yu, Patrick Poirson, Shan Yang, Alexander C. Berg, and Tamara L. Berg. Modeling context in referring expres- sions. InComputer Vision – ECCV 2016, page 69–85, Cham,
work page 2016
-
[42]
Springer International Publishing. 1, 2, 3
-
[43]
Licheng Yu, Zhe Lin, Xiaohui Shen, Jimei Yang, Xin Lu, Mohit Bansal, and Tamara L. Berg. Mattnet: Modular at- tention network for referring expression comprehension. In 2018 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, page 1307–1315, 2018. ISSN: 2575-7075. 2
work page 2018
-
[44]
Revisiting counterfactual prob- lems in referring expression comprehension
Zhihan Yu and Ruifan Li. Revisiting counterfactual prob- lems in referring expression comprehension. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), page 13438–13448, 2024. ISSN: 2575-
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.