Recognition: no theorem link
AI Native Asset Intelligence
Pith reviewed 2026-05-13 06:33 UTC · model grok-4.3
The pith
AI-native asset intelligence framework converts heterogeneous security signals into normalized asset importance scores by separating intrinsic exposure from contextual factors using modeling and deterministic aggregation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
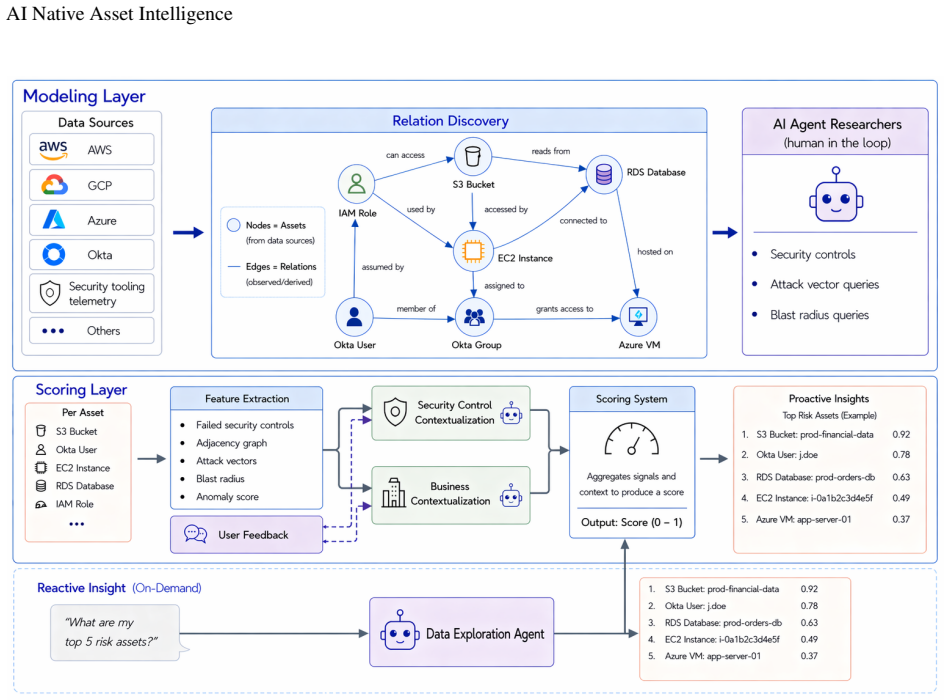
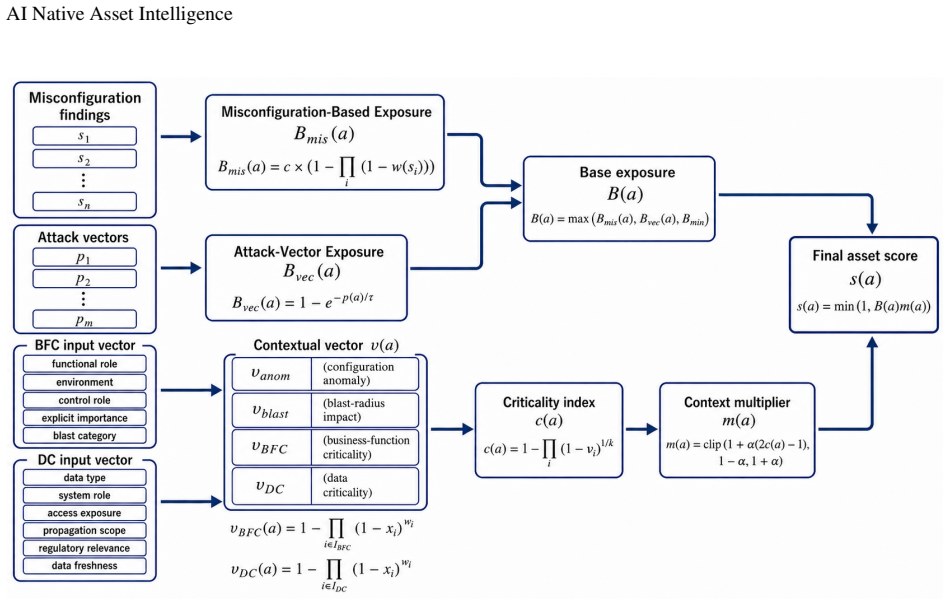
The framework transforms heterogeneous security data into a structured intelligence layer for consistent, contextual, and proactive asset-level reasoning, with the scoring system separating intrinsic exposure from contextual importance.
Load-bearing premise
That deterministic aggregation combined with AI contextualization will produce stable, non-reactive prioritization across diverse enterprise environments without introducing new inconsistencies from the severity mappings or business classifications.
Figures


read the original abstract
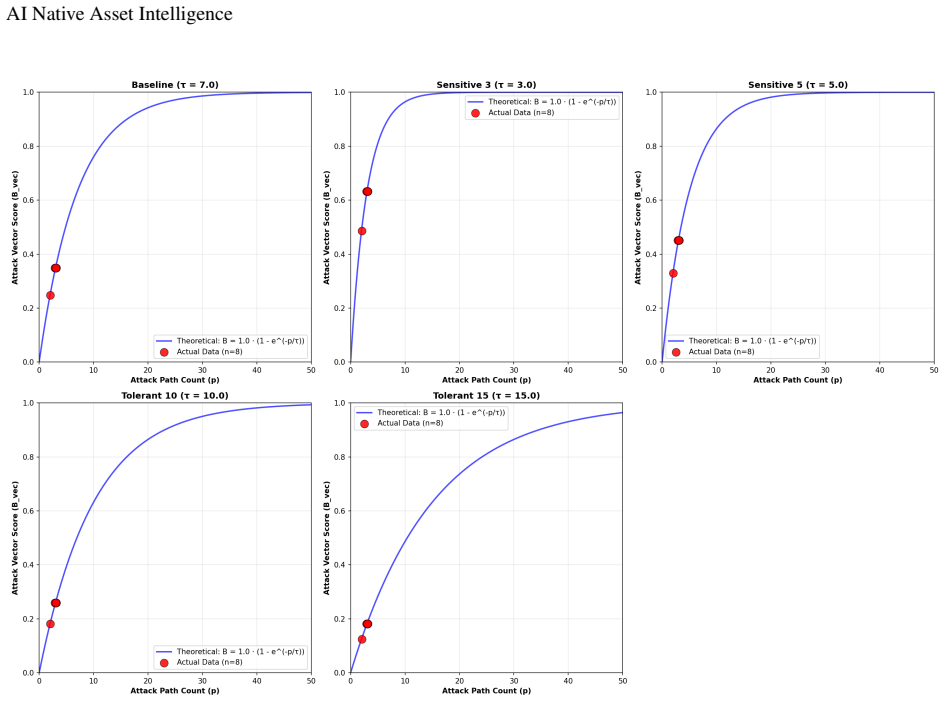
Modern security environments generate fragmented signals across cloud resources, identities, configurations, and third-party security tools. Although AI-native security assistants improve access to this data, they remain largely reactive: users must ask the right questions and interpret disconnected findings. This does not scale in enterprise environments, where signal importance depends on exposure, exploitability, dependencies, and business context. Repeated AI queries may therefore produce unstable prioritization without a structured basis for comparing assets. This paper introduces AI-native asset intelligence, a framework that transforms heterogeneous security data into a structured intelligence layer for consistent, contextual, and proactive asset-level reasoning. The framework combines a modeling layer, representing assets, identities, relationships, controls, attack vectors, and blast-radius patterns, with a scoring layer that converts fragmented signals into a normalized measure of asset importance. The scoring system separates intrinsic exposure, based on misconfigurations and attack-vector evidence, from contextual importance, based on anomaly, blast radius, business criticality, and data criticality. AI contextualization refines severity and business/data classifications, while deterministic aggregation preserves consistency. We evaluate the scoring system on a production snapshot with 131,625 resources across 15 vendors and 178 asset types. Sensitivity analyses and ablations show that severity mappings control finding sensitivity, AI severity adjustment refines prioritization, attack-vector scoring responds to rare exploitability evidence, and contextual modulation selectively modifies exposed resources based on business or data importance. The results support AI-native asset intelligence as a foundation for stable prioritization and proactive security-posture reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Circularity Check
No significant circularity: framework definition and single-snapshot evaluation are self-contained
full rationale
The paper defines a modeling layer (assets, identities, relationships, controls, attack vectors, blast-radius patterns) and a scoring layer that separates intrinsic exposure (misconfigurations, attack-vector evidence) from contextual importance (anomaly, blast radius, business/data criticality). AI contextualization refines classifications while deterministic aggregation is stated to preserve consistency. Evaluation consists of sensitivity analyses and ablations on one production snapshot (131625 resources). No equations, predictions, or uniqueness theorems are presented that reduce by construction to fitted parameters, self-citations, or renamed inputs. The central claims are definitional and empirically illustrated rather than derived from prior results that themselves depend on the target framework. This is the normal non-circular case for a systems/framework paper.
Axiom & Free-Parameter Ledger
free parameters (1)
- severity mappings
axioms (1)
- domain assumption Deterministic aggregation preserves consistency in prioritization
invented entities (1)
-
AI-native asset intelligence framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Yuhao Liu, Yingnan Zhou, Hanfeng Zhang, Zhiwei Chang, Sihan Xu, Yan Jia, Wei Wang, and Zheli Liu. Rethinking software misconfigurations in the real world: An empirical study and literature analysis.arXiv preprint arXiv:2412.11121, 2024
-
[2]
Design and Implementation of an Open-Source Security Framework for Cloud Infrastructure
Wanru Shao. Design and implementation of an open-source security framework for cloud infrastructure.arXiv preprint arXiv:2604.03331, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Forum of Incident Response and Security Teams. Common vulnerability scoring system version 4.0: Specification 21 AI Native Asset Intelligence document, 2023. Document Version 1.2
work page 2023
-
[4]
Exploit prediction scoring system (epss).Digital Threats: Research and Practice, 2(3):1–17, 2021
Jay Jacobs, Sasha Romanosky, Benjamin Edwards, Michael Roytman, and Idris Adjerid. Exploit prediction scoring system (epss).Digital Threats: Research and Practice, 2(3):1–17, 2021
work page 2021
-
[5]
Exploit prediction scoring system (epss), 2026
Forum of Incident Response and Security Teams. Exploit prediction scoring system (epss), 2026. Accessed 2026-04-26
work page 2026
-
[6]
Householder, Eric Hatleback, Art Manion, Madison Oliver, Vijay S
Jonathan Spring, Allen D. Householder, Eric Hatleback, Art Manion, Madison Oliver, Vijay S. Sarvepalli, Laurie Tyzenhaus, and Charles G. Yarbrough. Prioritizing vulnerability response: A stakeholder-specific vulnerability categorization (version 2.0). Technical report, Software Engineering Institute, Carnegie Mellon University, April 2021
work page 2021
-
[7]
Criticality analysis process model: Prioritizing systems and components
Celia Paulsen, Jon Boyens, Nadya Bartol, and Kris Winkler. Criticality analysis process model: Prioritizing systems and components. Technical Report NIST IR 8179, National Institute of Standards and Technology, 2018
work page 2018
-
[8]
Quinn, Nahla Ivy, Matthew Barrett, Gregory A
Stephen D. Quinn, Nahla Ivy, Matthew Barrett, Gregory A. Witte, and Robert K. Gardner. Prioritizing cybersecurity risk for enterprise risk management. Technical Report NIST IR 8286B-upd1, National Institute of Standards and Technology, 2025
work page 2025
-
[9]
Quinn, Nahla Ivy, Julie Chua, Matthew Barrett, Larry Feldman, Daniel Topper, Gregory A
Stephen D. Quinn, Nahla Ivy, Julie Chua, Matthew Barrett, Larry Feldman, Daniel Topper, Gregory A. Witte, and Robert K. Gardner. Using business impact analysis to inform risk prioritization and response. Technical Report NIST IR 8286D-upd1, National Institute of Standards and Technology, 2025
work page 2025
-
[10]
Cvss: Ubiquitous and broken.Digital Threats: Research and Practice, 4(1):1:1–1:12, 2023
Henry Howland. Cvss: Ubiquitous and broken.Digital Threats: Research and Practice, 4(1):1:1–1:12, 2023
work page 2023
- [11]
-
[12]
Grasp: Hardening serverless applications through graph reachability analysis of security policies
Isaac Polinsky, Pubali Datta, Adam Bates, and William Enck. Grasp: Hardening serverless applications through graph reachability analysis of security policies. InProceedings of the ACM Web Conference 2024, pages 1644–1655, 2024
work page 2024
- [13]
-
[14]
Jana Glöckler, Johannes Sedlmeir, Muriel Frank, and Gilbert Fridgen. A systematic review of identity and access management requirements in enterprises and potential contributions of self-sovereign identity.Business & Information Systems Engineering, 66(4):421–440, 2024
work page 2024
-
[15]
Graph mining for cybersecurity: A survey.ACM Computing Surveys, 2024
Bo Yan, Cheng Yang, Chuan Shi, Yong Fang, Qi Li, Yanfang Ye, and Junping Du. Graph mining for cybersecurity: A survey.ACM Computing Surveys, 2024
work page 2024
-
[16]
Cavp: A context-aware vulnerability prioritization model.Computers & Security, 116:102639, 2022
Bill Jung, Yan Li, and Tamir Bechor. Cavp: A context-aware vulnerability prioritization model.Computers & Security, 116:102639, 2022
work page 2022
-
[17]
Smartpatch: A patch prioritization framework.Computers in Industry, 137:103595, 2022
Geeta Yadav, Praveen Gauravaram, Arun Kumar Jindal, and Kolin Paul. Smartpatch: A patch prioritization framework.Computers in Industry, 137:103595, 2022
work page 2022
-
[18]
Ghazanfar, Ali Raza, and Mohsin Pasha
Halima Ibrahim Kure, Shareeful Islam, M. Ghazanfar, Ali Raza, and Mohsin Pasha. Asset criticality and risk prediction for an effective cybersecurity risk management of cyber-physical system.Neural Computing and Applications, 34(1):493–514, 2022
work page 2022
-
[19]
Yuning Jiang, Nay Oo, Qiaoran Meng, Hoon Wei Lim, and Biplab Sikdar. A survey on vulnerability prioritization: Taxonomy, metrics, and research challenges.CoRR, abs/2502.11070, 2025
-
[20]
Leslie F. Sikos. Cybersecurity knowledge graphs.Knowledge and Information Systems, 65:3511–3531, 2023
work page 2023
-
[21]
A survey on cybersecurity knowledge graph construction.Computers & Security, 136:103524, 2024
Xiaojuan Zhao, Rong Jiang, Yue Han, Aiping Li, and Zhichao Peng. A survey on cybersecurity knowledge graph construction.Computers & Security, 136:103524, 2024
work page 2024
-
[22]
Building a cybersecurity knowledge graph with cybergraph
Paolo Falcarin and Fabio Dainese. Building a cybersecurity knowledge graph with cybergraph. InProceedings of the 2024 ACM/IEEE 4th International Workshop on Engineering and Cybersecurity of Critical Systems and the 2024 IEEE/ACM Second International Workshop on Software Vulnerability, 2024
work page 2024
-
[23]
Yutong Cheng, Osama Bajaber, Saimon Amanuel Tsegai, Dawn Song, and Peng Gao. Ctinexus: Leveraging optimized llm in-context learning for constructing cybersecurity knowledge graphs under data scarcity.CoRR, abs/2410.21060, 2024
-
[24]
Reasoning on graphs: Faithful and interpretable large language model reasoning
Linhao Luo, Yuan-Fang Li, Gholamreza Haffari, and Shirui Pan. Reasoning on graphs: Faithful and interpretable large language model reasoning. InThe Twelfth International Conference on Learning Representations, 2024. 22 AI Native Asset Intelligence
work page 2024
-
[25]
Yixin Ji, Kaixin Wu, Juntao Li, Wei Chen, Mingjie Zhong, Jia Xu, and Min Zhang. Retrieval and reasoning on kgs: Integrate knowledge graphs into large language models for complex question answering. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 7598–7610, 2024
work page 2024
-
[26]
Kewei Cheng, Nesreen K. Ahmed, Ryan A. Rossi, Theodore L. Willke, and Yizhou Sun. Neural-symbolic methods for knowledge graph reasoning: A survey.ACM Transactions on Knowledge Discovery from Data, 18(9):225:1–225:44, 2024
work page 2024
-
[27]
Large language models for cyber security: A systematic literature review.ACM Computing Surveys, 2025
Hanxiang Xu, Shenao Wang, Ningke Li, Kailong Wang, Yanjie Zhao, Kai Chen, Ting Yu, Yang Liu, and Haoyu Wang. Large language models for cyber security: A systematic literature review.ACM Computing Surveys, 2025
work page 2025
-
[28]
Gal Engelberg, Konstantin Koutsyi, Leon Goldberg, Reuven Elezra, Idan Pinto, Tal Moalem, Shmuel Cohen, and Yoni Weintrob. Sola-visibility-ispm: Benchmarking agentic ai for identity security posture management visibility, 2026
work page 2026
-
[29]
CORTEX: Collaborative LLM Agents for High-Stakes Alert Triage, September 2025
Bowen Wei, Yuan Shen Tay, Howard Liu, Jinhao Pan, Kun Luo, Ziwei Zhu, and Chris Jordan. Cortex: Collaborative llm agents for high-stakes alert triage.CoRR, abs/2510.00311, 2025
-
[30]
Yuyang Zhou, Guang Cheng, Kang Du, and Zihan Chen. Toward intelligent and secure cloud: Large language model empowered proactive defense.CoRR, abs/2412.21051, 2024
-
[31]
Experiences of using agentic ai to fill tooling gaps in a security operations center
Kritan Banstola, Faayed Al Faisal, and Xinming Ou. Experiences of using agentic ai to fill tooling gaps in a security operations center. InWorkshop on SOC Operations and Construction (WOSOC), co-located with the NDSS Symposium, 2026
work page 2026
-
[32]
Prosa: Assessing and understanding the prompt sensitivity of llms
Jingming Zhuo, Songyang Zhang, Xinyu Fang, Haodong Duan, Dahua Lin, and Kai Chen. Prosa: Assessing and understanding the prompt sensitivity of llms. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 1950–1976, 2024
work page 2024
-
[33]
Efficient multi-prompt evaluation of llms
Felipe Maia Polo, Ronald Xu, Lucas Weber, Mírian Silva, Onkar Bhardwaj, Leshem Choshen, Allysson Flavio Melo de Oliveira, Yuekai Sun, and Mikhail Yurochkin. Efficient multi-prompt evaluation of llms. In Advances in Neural Information Processing Systems 37, 2024
work page 2024
-
[34]
Flaw or artifact? rethinking prompt sensitivity in evaluating llms
Andong Hua, Kenan Tang, Chenhe Gu, Jindong Gu, Eric Wong, and Yao Qin. Flaw or artifact? rethinking prompt sensitivity in evaluating llms. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 19889–19899, 2025
work page 2025
-
[35]
Mohammed Himayath Ali, Mohammed Aqib Abdullah, Mohammed Mudassir Uddin, and Shahnawaz Alam. Securecai: Injection-resilient llm assistants for cybersecurity operations.CoRR, abs/2601.07835, 2026
-
[36]
MITRE ATT&CK: Adversarial tactics, techniques, and common knowledge
MITRE Corporation. MITRE ATT&CK: Adversarial tactics, techniques, and common knowledge. https: //attack.mitre.org/, 2024. Accessed: 2026-04-26
work page 2024
-
[37]
Common Weakness Enumeration (CWE)
MITRE Corporation. Common Weakness Enumeration (CWE). https://cwe.mitre.org/, 2024. Accessed: 2026-04-26
work page 2024
-
[38]
Common Attack Pattern Enumeration and Classification (CAPEC)
MITRE Corporation. Common Attack Pattern Enumeration and Classification (CAPEC). https://capec. mitre.org/, 2024. Accessed: 2026-04-26. 23
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.