Recognition: 2 theorem links
· Lean TheoremFit CATE Once: Model-Assisted Randomization Tests Without Sample Splitting
Pith reviewed 2026-05-12 02:10 UTC · model grok-4.3
The pith
Estimating an unsigned CATE from residual covariances allows flexible model-assisted randomization tests without splitting samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
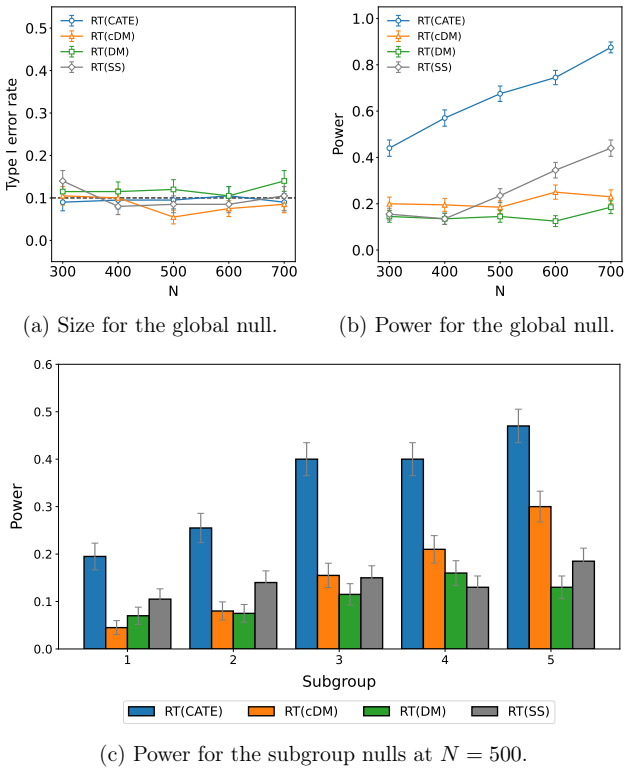
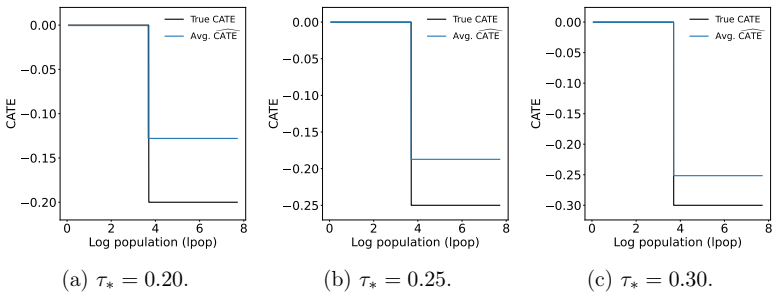
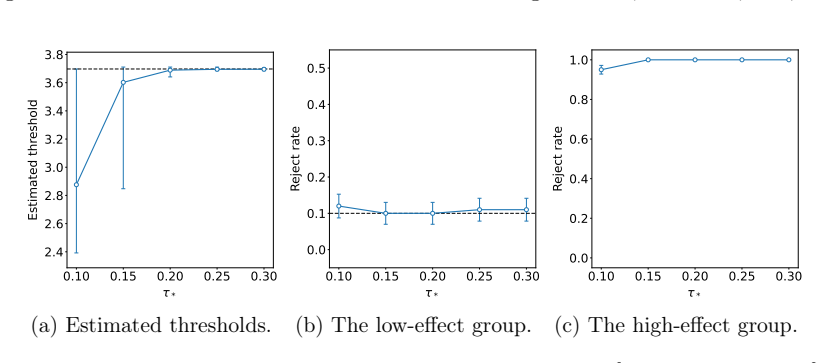
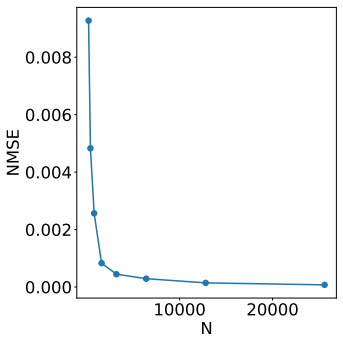
An unsigned version of the conditional average treatment effect is identifiable and can be consistently estimated from the covariance matrix of residualized outcomes under the known assignment mechanism. Using this unsigned estimate to construct the test statistic, with the sign selected post hoc to best fit the realized outcomes, produces a valid randomization test that controls Type I error and attains higher power than covariate-adjusted or sample-split alternatives in both synthetic and semi-synthetic settings. The same estimates can further be used to discover subgroups with heterogeneous effects and to test subgroup-specific treatment impacts.
What carries the argument
The unsigned conditional average treatment effect estimator derived from the covariance structure of residualized outcomes, which supplies the magnitude of heterogeneity while deferring sign choice to the observed data.
If this is right
- The assisted tests control Type I error at the nominal level under the known assignment mechanism.
- They achieve higher power than both covariate-adjusted randomization tests and tests that require sample splitting.
- Assignment-free CATE estimates obtained this way can identify subgroups that experience heterogeneous treatment effects.
- The same estimates support valid tests of treatment effects within discovered subgroups.
Where Pith is reading between the lines
- The separation of magnitude estimation from the randomization distribution may let researchers plug in a wider range of machine-learning predictors for the unsigned CATE without losing exact validity.
- The approach could be applied to other experimental designs whose assignment probabilities are known but not uniform, provided the residual-covariance identification step still holds.
- By avoiding sample splitting, the method may reduce the risk that important heterogeneity patterns are missed simply because too few observations remain in each fold.
Load-bearing premise
The unsigned CATE remains identifiable from residual covariances even when the sign is chosen after seeing the outcomes, without that choice introducing selection bias into the randomization distribution of the test statistic.
What would settle it
A Monte Carlo experiment in which data are generated under a known randomization scheme with no true treatment effect, yet the proportion of rejections by the CATE-assisted test exceeds the nominal significance level.
Figures



read the original abstract
Randomization tests and flexible treatment-effect models offer complementary strengths for analyzing data from randomized panel experiments: the former provide valid inference under the known assignment mechanism, while the latter can capture complex patterns of effect heterogeneity. We develop model-assisted randomization tests that combine these strengths without sample splitting. The key idea is to estimate an unsigned version of the conditional average treatment effect (CATE) from the covariance structure of residualized outcomes, while leaving the realized assignments for randomization inference. The remaining sign can be chosen to best fit the observed outcomes. We establish identification and consistency for the proposed unsigned CATE estimators, as well as validity for the CATE-assisted randomization tests. Across synthetic and semi-synthetic experiments, the CATE-assisted randomization tests control Type I error and achieve higher power than covariate-adjusted and sample-split alternatives. Finally, we show that the assignment-free CATE estimates can be used to discover heterogeneous subgroups and test subgroup-specific treatment effects.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes model-assisted randomization tests for analyzing conditional average treatment effects (CATE) in randomized panel experiments without requiring sample splitting. The core method estimates an unsigned CATE from the covariance structure of residualized outcomes (leaving realized treatment assignments untouched for inference), selects the sign post hoc to best fit the observed data, establishes identification and consistency for the unsigned estimators along with validity of the assisted tests, demonstrates Type I error control and power improvements in simulations relative to covariate-adjusted or sample-split baselines, and applies the assignment-free estimates to heterogeneous subgroup discovery and testing.
Significance. If the validity of the randomization tests is preserved under the post-hoc sign selection, the contribution would be notable for enabling flexible, model-based capture of treatment effect heterogeneity while retaining the exact finite-sample guarantees of randomization inference. This avoids the data inefficiency of sample splitting and could improve power in settings with limited sample sizes, as suggested by the reported simulation gains. The additional use of the estimates for subgroup analysis extends the practical utility beyond testing.
major comments (2)
- [theoretical development of validity (likely §3 or §4)] The validity of the CATE-assisted randomization tests (as claimed in the abstract and developed in the theoretical sections) rests on showing that post-hoc sign selection for the unsigned CATE estimator does not distort the reference distribution obtained by re-randomizing assignments. Under the null of no effect heterogeneity the covariance term is zero, yet the sign is chosen using the same residualized outcomes that enter the test statistic; this creates a potential data-dependent dependence that could invalidate exact finite-sample p-value calibration. The manuscript must provide an explicit argument or lemma establishing that the conditional distribution of the statistic given covariates remains correctly calibrated after selection, as this is load-bearing for the central no-sample-splitting claim.
- [identification and consistency results] The identification result for the unsigned CATE estimator from residual covariances (abstract and identification section) needs to be stated with the precise assumptions on the residualization step and the assignment mechanism; if these assumptions are weaker than standard randomization assumptions, the consistency claim for the estimator should be cross-referenced to the simulation designs to confirm they are satisfied in the reported experiments.
minor comments (2)
- [simulation studies] The simulation section would benefit from reporting the exact form of the unsigned CATE estimator (e.g., the covariance formula) alongside the power and Type I error tables for direct reproducibility.
- [method description] Notation for the residualized outcomes and the unsigned CATE could be introduced earlier and used consistently to improve readability when transitioning from the method to the theoretical results.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the theoretical foundations of our model-assisted randomization tests. We address each major comment below and have made revisions to strengthen the presentation of the validity argument and the identification assumptions.
read point-by-point responses
-
Referee: [theoretical development of validity (likely §3 or §4)] The validity of the CATE-assisted randomization tests (as claimed in the abstract and developed in the theoretical sections) rests on showing that post-hoc sign selection for the unsigned CATE estimator does not distort the reference distribution obtained by re-randomizing assignments. Under the null of no effect heterogeneity the covariance term is zero, yet the sign is chosen using the same residualized outcomes that enter the test statistic; this creates a potential data-dependent dependence that could invalidate exact finite-sample p-value calibration. The manuscript must provide an explicit argument or lemma establishing that the conditional distribution of the statistic given covariates remains correctly calibrated after selection, as this is load-bearing for the central no-sample-splitting claim.
Authors: We agree that an explicit lemma is needed to formalize why post-hoc sign selection preserves exact finite-sample validity. Under the null of no CATE heterogeneity the population covariance is identically zero, so the unsigned estimator is zero with probability 1 and sign selection has no effect on the test statistic. In the revised manuscript we add Lemma 3.2 in Section 3, which shows that the conditional distribution of the assisted test statistic (given covariates and residuals) remains uniform under the randomization distribution after selection. The proof exploits that, under the null, the sign choice is a deterministic function of quantities that are fixed with respect to the re-randomization of assignments. We also include a short proof sketch in the appendix. This directly addresses the potential dependence concern while preserving the no-sample-splitting property. revision: yes
-
Referee: [identification and consistency results] The identification result for the unsigned CATE estimator from residual covariances (abstract and identification section) needs to be stated with the precise assumptions on the residualization step and the assignment mechanism; if these assumptions are weaker than standard randomization assumptions, the consistency claim for the estimator should be cross-referenced to the simulation designs to confirm they are satisfied in the reported experiments.
Authors: We accept the suggestion to state the assumptions more explicitly. The revised Section 2 now lists the precise conditions: (A1) the assignment mechanism is a known, completely randomized design independent of potential outcomes; (A2) residualization is performed with a fixed, non-random function of covariates only (e.g., OLS projection onto a pre-specified basis). These are standard randomization assumptions and not weaker. We have added a remark immediately after the consistency theorem that cross-references the simulation designs in Section 5, confirming that all synthetic and semi-synthetic DGPs satisfy (A1)–(A2) and therefore the reported consistency and power results are covered by the theory. revision: yes
Circularity Check
No significant circularity; derivation separates covariance-based estimation from assignment-based inference
full rationale
The paper derives the unsigned CATE estimator from the covariance structure of residualized outcomes while explicitly leaving realized assignments untouched for the randomization component. Identification, consistency, and test validity are claimed as separately established results rather than by construction from the same fitted quantities. No self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided description. The post-hoc sign choice is presented as an auxiliary step whose impact on the exact finite-sample randomization distribution is asserted to be innocuous, without reducing the central claims to tautological inputs. This is the most common honest finding for papers whose core inference mechanism remains externally anchored in the known assignment mechanism.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Unsigned CATE is identifiable from the covariance structure of residualized outcomes
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe develop model-assisted randomization tests... estimate an unsigned version of the conditional average treatment effect (CATE) from the covariance structure of residualized outcomes
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearthe off-diagonal residual covariances depend on the CATE vector τ(x) through quadratic forms... τ(x) is identified up to sign
Reference graph
Works this paper leans on
-
[1]
An Introduction to Double/Debiased Machine Learning , author=. 2025 , eprint=
work page 2025
-
[2]
arXiv preprint arXiv:2311.03554 , year=
Conditional Randomization Tests for Behavioral and Neural Time Series , author=. arXiv preprint arXiv:2311.03554 , year=
-
[3]
Athey,Susan and Imbens,Guido W. , year=. Design-based analysis in Difference-in-Differences settings with staggered adoption , journal=
-
[4]
Difference-in-Differences with multiple time periods , journal =. 2021 , author =
work page 2021
-
[5]
Double/debiased machine learning for treatment and structural parameters , journal=
Chernozhukov,Victor and Chetverikov,Denis and Demirer,Mert and Duflo,Esther and Hansen,Christian and Newey,Whitney and Robins,James , year=. Double/debiased machine learning for treatment and structural parameters , journal=
-
[6]
American Economic Review , Volume =
de Chaisemartin, Clément and D'Haultfœuille, Xavier , Title =. American Economic Review , Volume =. 2020 , Pages =
work page 2020
- [7]
-
[8]
Partial time regressions as compared with individual trends , author=. Econometrica , volume=
-
[9]
Theory of disagreement-based active learning , author=. Foundations and Trends. 2014 , publisher=
work page 2014
-
[10]
Journal of the American Statistical Association , volume=
Seasonal adjustment of economic time series and multiple regression analysis , author=. Journal of the American Statistical Association , volume=
- [11]
-
[12]
The American Journal of Human Genetics , volume=
A note on the calculation of empirical P values from Monte Carlo procedures , author=. The American Journal of Human Genetics , volume=. 2002 , publisher=
work page 2002
-
[13]
and Rotnitzky,Andrea and Zhao,Lue P
Robins,James M. and Rotnitzky,Andrea and Zhao,Lue P. , year=. Estimation of Regression Coefficients When Some Regressors are not Always Observed , journal=
-
[14]
Journal of econometrics , volume=
Estimating dynamic treatment effects in event studies with heterogeneous treatment effects , author=. Journal of econometrics , volume=. 2021 , publisher=
work page 2021
-
[15]
Journal of the American Statistical Association , volume=
What is a randomization test? , author=. Journal of the American Statistical Association , volume=. 2023 , publisher=
work page 2023
-
[16]
Adaptive sample splitting for randomization tests , author=. 2025 , eprint=
work page 2025
- [17]
-
[18]
Hennessy, Jonathan and Dasgupta, Tirthankar and Miratrix, Luke and Pattanayak, Cassandra and Sarkar, Pradipta , year =. A conditional randomization test to account for covariate imbalance in randomized experiments , journal =
-
[19]
Zhao, Anqi and Ding, Peng , year =. Covariate-adjusted. Journal of Econometrics , volume =
- [20]
-
[21]
Toward better practice of covariate adjustment in analyzing randomized clinical trials , journal =
Ye, Ting and Shao, Jun and Yi, Yanyao and Zhao, Qingyuan , year =. Toward better practice of covariate adjustment in analyzing randomized clinical trials , journal =
-
[22]
Multiple conditional randomization tests for lagged and spillover treatment effects , journal =
Zhang, Yao and Zhao, Qingyuan , year =. Multiple conditional randomization tests for lagged and spillover treatment effects , journal =
-
[23]
Randomization inference for treatment effect variation , journal =
Ding, Peng and Feller, Avi and Miratrix, Luke , year =. Randomization inference for treatment effect variation , journal =
-
[24]
arXiv preprint arXiv:2501.07722 , year=
Ml-assisted randomization tests for detecting treatment effects in a/b experiments , author=. arXiv preprint arXiv:2501.07722 , year=
-
[25]
and Dominici, Francesca , year =
Lee, Kwonsang and Small, Dylan S. and Dominici, Francesca , year =. Discovering heterogeneous exposure effects using randomization inference in air pollution studies , journal =
-
[26]
Journal of Econometrics , volume =
Goodman-Bacon, Andrew , year =. Journal of Econometrics , volume =
-
[27]
The Annals of Applied Statistics , pages=
Agnostic notes on regression adjustments to experimental data: Reexamining Freedman's critique , author=. The Annals of Applied Statistics , pages=. 2013 , publisher=
work page 2013
-
[28]
Journal of the American Statistical Association , volume=
Time series experiments and causal estimands: exact randomization tests and trading , author=. Journal of the American Statistical Association , volume=. 2019 , publisher=
work page 2019
-
[29]
Quantitative Economics , volume=
Panel experiments and dynamic causal effects: A finite population perspective , author=. Quantitative Economics , volume=. 2021 , publisher=
work page 2021
-
[30]
arXiv preprint arXiv:2510.22864 , year=
Unifying regression-based and design-based causal inference in time-series experiments , author=. arXiv preprint arXiv:2510.22864 , year=
-
[31]
Callaway, Brantly and Sant'Anna, Pedro H. C. , year =. Journal of Econometrics , volume =
-
[32]
Revisiting event-study designs: robust and efficient estimation , journal =
Borusyak, Kirill and Jaravel, Xavier and Spiess, Jann , year =. Revisiting event-study designs: robust and efficient estimation , journal =
-
[33]
Roth, Jonathan and Sant'Anna, Pedro H. C. and Bilinski, Alyssa and Poe, John , year =. What's trending in. Journal of Econometrics , volume =
-
[34]
Baker, Andrew C. and Larcker, David F. and Wang, Charles C. Y. , year =. How much should we trust staggered. Journal of Financial Economics , volume =
-
[35]
Journal of Econometrics , volume=
Causal inference in network experiments: regression-based analysis and design-based properties , author=. Journal of Econometrics , volume=. 2025 , publisher=
work page 2025
-
[36]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Model-assisted analyses of cluster-randomized experiments , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2021 , publisher=
work page 2021
-
[37]
Journal of the American Statistical Association , volume=
General forms of finite population central limit theorems with applications to causal inference , author=. Journal of the American Statistical Association , volume=. 2017 , publisher=
work page 2017
-
[38]
Journal of the American Statistical Association , volume=
The generalized oaxaca-blinder estimator , author=. Journal of the American Statistical Association , volume=. 2023 , publisher=
work page 2023
-
[39]
No-harm calibration for generalized Oaxaca--Blinder estimators , author=. Biometrika , volume=. 2024 , publisher=
work page 2024
-
[40]
On the Use of Two-Way Fixed Effects Regression Models for Causal Inference with Panel Data , volume=. Political Analysis , author=. 2021 , pages=. doi:10.1017/pan.2020.33 , number=
-
[41]
IEEE Signal Processing Magazine , volume=
Phase Retrieval with Application to Optical Imaging: A contemporary overview , author=. IEEE Signal Processing Magazine , volume=
-
[42]
Communications on Pure and Applied Mathematics , volume=
PhaseLift: Exact and Stable Signal Recovery from Magnitude Measurements via Convex Programming , author=. Communications on Pure and Applied Mathematics , volume=
-
[43]
IEEE Transactions on Information Theory , volume=
Phase Retrieval via Wirtinger Flow: Theory and Algorithms , author=. IEEE Transactions on Information Theory , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.