Recognition: 2 theorem links
· Lean TheoremFlame3D: Zero-shot Compositional Reasoning of 3D Scenes with Agentic Language Models
Pith reviewed 2026-05-12 02:05 UTC · model grok-4.3
The pith
A training-free framework lets off-the-shelf language models reason about complex 3D scenes by editing memories and inventing spatial tools at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Flame3D stores 3D scenes as editable visual-textual memories and exposes them to an off-the-shelf MLLM through both fixed and agent-synthesized spatial tools, enabling zero-shot compositional reasoning over free space, grounding, hypothetical objects, and geometric relationships without 3D-specific training.
What carries the argument
Editable visual-textual 3D memory exposed through fixed and self-synthesized spatial tools that the agent composes at inference time.
If this is right
- Competitive results on ScanQA are achieved without any 3D-language fine-tuning.
- Synthesized tools at inference time are required for success on multi-hop spatial reasoning in Compose3D.
- External data or human corrections can be inserted into the memory without retraining the model.
- Open-ended reasoning about empty space and absent objects becomes possible through on-the-fly program synthesis.
- Progress in 3D understanding can shift toward richer scene memories and compositional abstractions rather than larger training sets.
Where Pith is reading between the lines
- The same memory-plus-tool design could support dynamic scenes if the memory is updated in real time.
- Robotic planning systems might reuse the identical editable memory for both perception and action sequencing.
- Limits in current MLLM spatial reasoning may be addressed more effectively by better tool libraries than by additional training data.
- The approach invites tests on whether tool synthesis scales to longer reasoning chains or to scenes with many interacting objects.
Load-bearing premise
An off-the-shelf multimodal language model can reliably interpret and execute both fixed and self-generated spatial tools on the editable 3D memory without substantial hallucinations on complex tasks.
What would settle it
Systematic failure of the MLLM to correctly apply agent-synthesized spatial programs on multi-hop queries from the Compose3D benchmark would show that inference-time tool synthesis does not deliver the claimed generalization.
Figures











read the original abstract
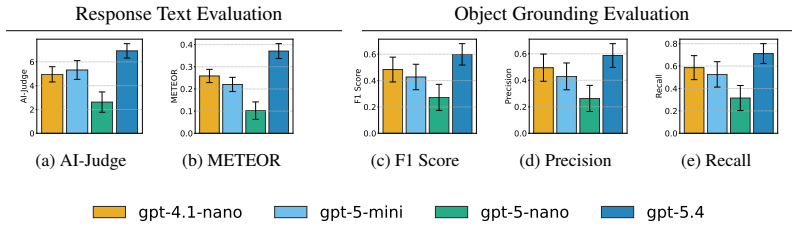
3D scene understanding spans reasoning about free space, object grounding, hypothetical object insertions, complex geometric relationships, and integrating all of these with external tools and data sources. Existing 3D understanding methods typically rely on large-scale 3D-language training or focus on object grounding and simple spatial relationships. We argue that the broad generalization that motivates 3D-language training can be achieved at inference time, without 3D-specific training. We propose Flame3D, a training-free framework that represents scenes as editable visual-textual 3D memories and exposes them to an off-the-shelf MLLM through composable spatial tools. Flame3D also lets the agent synthesize custom spatial programs at inference time, enabling open-ended reasoning over layouts, empty space, and objects not yet present in the scene. External data and corrections can be added to the memory without retraining. In addition to showing competitive performance to finetuned 3D-LMM methods on ScanQA, we study multi-hop 3D reasoning capabilities of Flame3D by evaluating it on a curated compositional spatial-reasoning benchmark, Compose3D. We find that fixed tools fall short and that the agent's ability to synthesize spatial operations at inference time is essential. These results invite the question: should future progress in 3D scene understanding focus on richer scene memories and expressive compositional abstractions?
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Flame3D, a training-free, zero-shot framework for compositional 3D scene reasoning. Scenes are encoded as editable visual-textual 3D memories that an off-the-shelf MLLM accesses via composable spatial tools; the agent can synthesize custom spatial programs at inference time to support open-ended queries over layouts, free space, and hypothetical insertions. The work reports competitive performance against finetuned 3D-LMMs on ScanQA and introduces the Compose3D benchmark to demonstrate that tool synthesis is essential because fixed tools underperform on multi-hop spatial tasks.
Significance. If the results hold, the work shows that broad 3D generalization can be realized at inference time without 3D-specific training by combining editable memories with agentic tool synthesis. This offers a potential alternative to large-scale 3D-language pretraining. Credit is given for the explicitly training-free design, use of off-the-shelf MLLMs, introduction of the Compose3D compositional benchmark, and the explicit empirical contrast between fixed and synthesizable tools.
major comments (2)
- [Compose3D evaluation] The central claim that inference-time tool synthesis is essential rests on the statement that 'fixed tools fall short' on Compose3D, yet the manuscript supplies no quantitative breakdown of synthesis success rate, per-step tool-execution accuracy, hallucination frequency on geometric or empty-space relations, or recovery behavior across multi-hop chains. Without these metrics it is impossible to attribute observed performance to the proposed mechanism rather than benchmark leniency or short task depth.
- [Framework and method description] The framework's reliability hinges on the off-the-shelf MLLM correctly parsing the editable 3D memory, invoking or inventing spatial tools, and maintaining state without substantial hallucinations. The manuscript provides no implementation details on memory construction, update protocol, prompting strategy for synthesis, or verification of tool outputs, leaving the weakest assumption (MLLM reliability on self-synthesized tools) untested.
minor comments (2)
- [Abstract] The abstract claims 'competitive performance' on ScanQA but does not name the exact metrics, baselines, or numerical margins; these should be stated explicitly even in the abstract.
- [Method] Notation for the editable visual-textual memory and the distinction between fixed versus synthesizable tools is introduced without a compact summary table or diagram, making the compositional abstraction harder to follow on first reading.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the training-free nature of Flame3D, the introduction of Compose3D, and the empirical contrast between fixed and synthesizable tools. We address each major comment below and will incorporate the suggested clarifications and analyses in the revised manuscript.
read point-by-point responses
-
Referee: [Compose3D evaluation] The central claim that inference-time tool synthesis is essential rests on the statement that 'fixed tools fall short' on Compose3D, yet the manuscript supplies no quantitative breakdown of synthesis success rate, per-step tool-execution accuracy, hallucination frequency on geometric or empty-space relations, or recovery behavior across multi-hop chains. Without these metrics it is impossible to attribute observed performance to the proposed mechanism rather than benchmark leniency or short task depth.
Authors: We agree that a more granular breakdown would strengthen attribution of the performance gains to tool synthesis. Our current results demonstrate a clear gap between fixed-tool and synthesizable-tool variants on multi-hop Compose3D tasks, but we did not report per-step synthesis success rates, execution accuracy, or hallucination frequencies. In the revision we will add these metrics by post-hoc analysis of the agent's tool-invocation traces, including synthesis success rate, per-step geometric/empty-space accuracy, hallucination counts, and recovery behavior across chain lengths. revision: yes
-
Referee: [Framework and method description] The framework's reliability hinges on the off-the-shelf MLLM correctly parsing the editable 3D memory, invoking or inventing spatial tools, and maintaining state without substantial hallucinations. The manuscript provides no implementation details on memory construction, update protocol, prompting strategy for synthesis, or verification of tool outputs, leaving the weakest assumption (MLLM reliability on self-synthesized tools) untested.
Authors: We acknowledge that the manuscript describes the framework at a high level but omits low-level implementation specifics. In the revised version we will expand the Methods section with: (i) the exact procedure for constructing and updating the editable visual-textual 3D memory, (ii) the prompting templates and few-shot examples used for tool synthesis, (iii) the protocol for verifying tool outputs before state update, and (iv) a dedicated failure-case analysis that quantifies MLLM reliability on self-synthesized tools using the same Compose3D logs. revision: yes
Circularity Check
No circularity; framework is a new inference-time proposal relying on external off-the-shelf MLLM
full rationale
The paper introduces Flame3D as a training-free system that represents 3D scenes via editable visual-textual memories and exposes them to an external MLLM through fixed and synthesizable spatial tools. The central argument—that broad 3D generalization can be achieved at inference time without 3D-specific training—is advanced by describing the architecture and reporting competitive results on ScanQA plus a new Compose3D benchmark. No equations, fitted parameters, or self-referential definitions appear in the provided text; the performance claims rest on the independent capabilities of the chosen MLLM rather than on any loop that reduces the output to the paper's own inputs by construction. Self-citations, if present, are not load-bearing for the core mechanism. This is a standard non-circular proposal of a new agentic framework.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Off-the-shelf multimodal large language models possess sufficient reasoning capabilities to utilize composable spatial tools and synthesize custom programs for 3D scene understanding when given an appropriate memory representation.
invented entities (2)
-
Editable visual-textual 3D memories
no independent evidence
-
Composable spatial tools with inference-time synthesis
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose Flame3D, a training-free framework that represents scenes as editable visual-textual 3D memories and exposes them to an off-the-shelf MLLM through composable spatial tools... the agent’s ability to synthesize spatial operations at inference time is essential.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
fixed tools fall short and that the agent’s ability to synthesize spatial operations at inference time is essential
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
3d-llm: Injecting the 3d world into large language models
Yining Hong, Haoyu Zhen, Peihao Chen, Shuhong Zheng, Yilun Du, Zhenfang Chen, and Chuang Gan. 3d-llm: Injecting the 3d world into large language models. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,NeurIPS, 2023
work page 2023
-
[2]
Chat-3d: Data- efficiently tuning large language model for universal dialogue of 3d scenes, 2023
Zehan Wang, Haifeng Huang, Yang Zhao, Ziang Zhang, and Zhou Zhao. Chat-3d: Data- efficiently tuning large language model for universal dialogue of 3d scenes, 2023
work page 2023
-
[3]
Spatiallm: Training large language models for structured indoor modeling
Yongsen Mao, Junhao Zhong, Chuan Fang, Jia Zheng, Rui Tang, Hao Zhu, Ping Tan, and Zihan Zhou. Spatiallm: Training large language models for structured indoor modeling. InAdvances in Neural Information Processing Systems, 2025
work page 2025
-
[4]
Spatialrgpt: Grounded spatial reasoning in vision-language models
An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Ruihan Yang, Jan Kautz, Xiaolong Wang, and Sifei Liu. Spatialrgpt: Grounded spatial reasoning in vision-language models. In NeurIPS, 2024
work page 2024
-
[5]
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, An- drei A. Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, and Raia Hadsell. Overcoming catastrophic forgetting in neural networks.Proceedings of the National Academy of Sciences, 2017
work page 2017
-
[6]
Weichen Zhang, Ruiying Peng, Chen Gao, Jianjie Fang, Xin Zeng, Kaiyuan Li, Ziyou Wang, Jinqiang Cui, Xin Wang, Xinlei Chen, et al. The point, the vision and the text: Does point cloud boost spatial reasoning of large language models?arXiv preprint arXiv:2504.04540, 2025
-
[7]
Do 3d large language models really understand 3d spatial relationships? InICLR, 2026
Xianzheng Ma, Tao Sun, Shuai Chen, Yash Bhalgat, Jindong Gu, Angel X Chang, Iro Armeni, Iro Laina, Songyou Peng, and Victor Adrian Prisacariu. Do 3d large language models really understand 3d spatial relationships? InICLR, 2026
work page 2026
-
[8]
Tenenbaum, Celso Miguel de Melo, Madhava Krishna, Liam Paull, Florian Shkurti, and Antonio Torralba
Krishna Murthy Jatavallabhula, Alihusein Kuwajerwala, Qiao Gu, Mohd Omama, Tao Chen, Shuang Li, Ganesh Iyer, Soroush Saryazdi, Nikhil Keetha, Ayush Tewari, Joshua B. Tenenbaum, Celso Miguel de Melo, Madhava Krishna, Liam Paull, Florian Shkurti, and Antonio Torralba. Conceptfusion: Open-set multimodal 3d mapping.Robotics: Science and Systems (RSS), 2023
work page 2023
-
[9]
Lerf: Language embedded radiance fields
Justin* Kerr, Chung Min* Kim, Ken Goldberg, Angjoo Kanazawa, and Matthew Tancik. Lerf: Language embedded radiance fields. InICCV, 2023
work page 2023
-
[10]
Hierarchical Open-V ocabulary 3D Scene Graphs for Language-Grounded Robot Navigation
Abdelrhman Werby, Chenguang Huang, Martin Büchner, Abhinav Valada, and Wolfram Burgard. Hierarchical Open-V ocabulary 3D Scene Graphs for Language-Grounded Robot Navigation. In RSS, 2024
work page 2024
-
[11]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InICML, 2021
work page 2021
-
[12]
Shun Taguchi, Hideki Deguchi, Takumi Hamazaki, and Hiroyuki Sakai. Spatialprompting: Keyframe-driven zero-shot spatial reasoning with off-the-shelf multimodal large language models.arXiv preprint arXiv:2505.04911, 2025
-
[13]
See&trek: Training-free spatial prompting for multimodal large language model
Pengteng Li, Pinhao Song, Wuyang Li, Huizai Yao, Weiyu Guo, Yijie Xu, Dugang Liu, and Hui Xiong. See&trek: Training-free spatial prompting for multimodal large language model. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview.net/forum?id=2exr4mlbx1
work page 2026
-
[14]
Agent3d-zero: An agent for zero-shot 3d understanding
Sha Zhang, Di Huang, Jiajun Deng, Shixiang Tang, Wanli Ouyang, Tong He, and Yanyong Zhang. Agent3d-zero: An agent for zero-shot 3d understanding. In Aleš Leonardis, Elisa Ricci, Stefan Roth, Olga Russakovsky, Torsten Sattler, and Gül Varol, editors,ECCV, pages 186–202, Cham, 2024. Springer Nature Switzerland. ISBN 978-3-031-72655-2
work page 2024
-
[15]
Jianing Yang, Xuweiyi Chen, Shengyi Qian, Nikhil Madaan, Madhavan Iyengar, David F. Fouhey, and Joyce Chai. Llm-grounder: Open-vocabulary 3d visual grounding with large language model as an agent. InICRA, 2024. 10
work page 2024
-
[16]
Nader Zantout, Haochen Zhang, Pujith Kachana, Jinkai Qiu, Ji Zhang, and Wenshan Wang. Sort3d: Spatial object-centric reasoning toolbox for zero-shot 3d grounding using large language models, 2025. URLhttps://arxiv.org/abs/2504.18684
-
[17]
Sayplan: Grounding large language models using 3d scene graphs for scalable robot task planning
Krishan Rana, Jesse Haviland, Sourav Garg, Jad Abou-Chakra, Ian Reid, and Niko Suenderhauf. Sayplan: Grounding large language models using 3d scene graphs for scalable robot task planning. InCoRL, 2023
work page 2023
-
[18]
Beyond bare queries: Open-vocabulary object grounding with 3d scene graph
Sergey Linok, Tatiana Zemskova, Svetlana Ladanova, Roman Titkov, Dmitry Yudin, Maxim Monastyrny, and Aleksei Valenkov. Beyond bare queries: Open-vocabulary object grounding with 3d scene graph. InICRA, 2025
work page 2025
-
[19]
Scanqa: 3d question answering for spatial scene understanding
Daichi Azuma, Taiki Miyanishi, Shuhei Kurita, and Motoaki Kawanabe. Scanqa: 3d question answering for spatial scene understanding. InCVPR, 2022
work page 2022
-
[20]
An embodied generalist agent in 3d world
Jiangyong Huang, Silong Yong, Xiaojian Ma, Xiongkun Linghu, Puhao Li, Yan Wang, Qing Li, Song-Chun Zhu, Baoxiong Jia, and Siyuan Huang. An embodied generalist agent in 3d world. InICML, 2024
work page 2024
-
[21]
Think3d: Thinking with space for spatial reasoning
Zaibin Zhang, Yuhan Wu, Lianjie Jia, Yifan Wang, Zhongbo Zhang, Yijiang Li, Binghao Ran, Fuxi Zhang, Zhuohan Sun, Zhenfei Yin, et al. Think3d: Thinking with space for spatial reasoning. 2026
work page 2026
-
[22]
Sqa3d: Situated question answering in 3d scenes
Xiaojian Ma, Silong Yong, Zilong Zheng, Qing Li, Yitao Liang, Song-Chun Zhu, and Siyuan Huang. Sqa3d: Situated question answering in 3d scenes. InICLR, 2023
work page 2023
-
[23]
Pointllm: Empowering large language models to understand point clouds
Runsen Xu, Xiaolong Wang, Tai Wang, Yilun Chen, Jiangmiao Pang, and Dahua Lin. Pointllm: Empowering large language models to understand point clouds. InECCV, 2024
work page 2024
-
[24]
Spatialvlm: Endowing vision-language models with spatial reasoning capabilities
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. In CVPR, 2024
work page 2024
-
[25]
Ll3da: Visual interactive instruction tuning for omni-3d understanding, reasoning, and planning
Sijin Chen, Xin Chen, Chi Zhang, Mingsheng Li, Gang Yu, Hao Fei, Hongyuan Zhu, Jiayuan Fan, and Tao Chen. Ll3da: Visual interactive instruction tuning for omni-3d understanding, reasoning, and planning. InCVPR, 2024
work page 2024
-
[26]
Openscene: 3d scene understanding with open vocabularies
Songyou Peng, Kyle Genova, Chiyu "Max" Jiang, Andrea Tagliasacchi, Marc Pollefeys, and Thomas Funkhouser. Openscene: 3d scene understanding with open vocabularies. InCVPR, 2023
work page 2023
-
[27]
Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning
Qiao Gu, Ali Kuwajerwala, Sacha Morin, Krishna Murthy Jatavallabhula, Bipasha Sen, Aditya Agarwal, Corban Rivera, William Paul, Kirsty Ellis, Rama Chellappa, et al. Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning. InICRA, 2024
work page 2024
-
[28]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InICLR, 2023
work page 2023
-
[29]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettle- moyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. InNeurIPS, 2023
work page 2023
-
[30]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models. arXiv preprint arXiv: Arxiv-2305.16291, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Code as policies: Language model programs for embodied control
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, and Andy Zeng. Code as policies: Language model programs for embodied control. InICRA, 2023
work page 2023
-
[32]
Progprompt: Generating situated robot task plans using large language models
Ishika Singh, Valts Blukis, Arsalan Mousavian, Ankit Goyal, Danfei Xu, Jonathan Tremblay, Dieter Fox, Jesse Thomason, and Animesh Garg. Progprompt: Generating situated robot task plans using large language models. InICRA, 2023. 11
work page 2023
-
[33]
CaP-X: A framework for benchmarking and improving coding agents for robot manipulation
Max Fu, Justin Yu, Karim El-Refai, Ethan Kou, Haoru Xue, Huang Huang, Wenli Xiao, Guanzhi Wang, Fei-Fei Li, Guanya Shi, Jiajun Wu, Shankar Sastry, Yuke Zhu, Ken Goldberg, and Jim Fan. CaP-X: A framework for benchmarking and improving coding agents for robot manipulation. arXiv preprint arXiv:2603.22435, 2025. URLhttps://arxiv.org/abs/2603.22435
-
[34]
brian ichter, Anthony Brohan, Yevgen Chebotar, Chelsea Finn, Karol Hausman, Alexander Herzog, Daniel Ho, Julian Ibarz, Alex Irpan, Eric Jang, Ryan Julian, Dmitry Kalashnikov, Sergey Levine, Yao Lu, Carolina Parada, Kanishka Rao, Pierre Sermanet, Alexander T Toshev, Vincent Vanhoucke, Fei Xia, Ted Xiao, Peng Xu, Mengyuan Yan, Noah Brown, Michael Ahn, Omar ...
work page 2023
-
[35]
Goat: Go to any thing.RSS, 2024
Matthew Chang, Theophile Gervet, Mukul Khanna, Sriram Yenamandra, Dhruv Shah, So Min, Kavit Shah, Chris Paxton, Saurabh Gupta, Dhruv Batra, et al. Goat: Go to any thing.RSS, 2024
work page 2024
-
[36]
Navigating to objects in the real world.Science Robotics, 2023
Theophile Gervet, Soumith Chintala, Dhruv Batra, Jitendra Malik, and Devendra Singh Chaplot. Navigating to objects in the real world.Science Robotics, 2023
work page 2023
-
[37]
Procthor: Large-scale embodied ai using procedural generation.NeurIPS, 2022
Matt Deitke, Eli VanderBilt, Alvaro Herrasti, Luca Weihs, Kiana Ehsani, Jordi Salvador, Winson Han, Eric Kolve, Aniruddha Kembhavi, and Roozbeh Mottaghi. Procthor: Large-scale embodied ai using procedural generation.NeurIPS, 2022
work page 2022
-
[38]
Inner monologue: Em- bodied reasoning through planning with language models
Wenlong Huang, Fei Xia, Ted Xiao, Harris Chan, Jacky Liang, Pete Florence, Andy Zeng, Jonathan Tompson, Igor Mordatch, Yevgen Chebotar, Pierre Sermanet, Tomas Jackson, Noah Brown, Linda Luu, Sergey Levine, Karol Hausman, and brian ichter. Inner monologue: Em- bodied reasoning through planning with language models. In Karen Liu, Dana Kulic, and Jeff Ichnow...
work page 2023
-
[39]
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior. InIn the 36th Annual ACM Symposium on User Interface Software and Technology (UIST ’23), UIST ’23, New York, NY , USA, 2023. Association for Computing Machinery
work page 2023
-
[40]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
PostGIS Project Steering Committee.PostGIS: Spatial and Geographic Objects for PostgreSQL,
-
[42]
URLhttps://postgis.net
-
[43]
Stephen Robertson and Hugo Zaragoza.The probabilistic relevance framework: BM25 and beyond. 2009
work page 2009
-
[44]
3d-vista: Pre-trained transformer for 3d vision and text alignment
Zhu Ziyu, Ma Xiaojian, Chen Yixin, Deng Zhidong, Huang Siyuan, and Li Qing. 3d-vista: Pre-trained transformer for 3d vision and text alignment. InICCV, 2023
work page 2023
-
[45]
Video-3d llm: Learning position-aware video representation for 3d scene understanding
Duo Zheng, Shijia Huang, and Liwei Wang. Video-3d llm: Learning position-aware video representation for 3d scene understanding. InCVPR, 2025
work page 2025
-
[46]
Cvp: Central- peripheral vision-inspired multimodal model for spatial reasoning
Zeyuan Chen, Xiang Zhang, Haiyang Xu, Jianwen Xie, and Zhuowen Tu. Cvp: Central- peripheral vision-inspired multimodal model for spatial reasoning. InWACV, 2026
work page 2026
-
[47]
Mvbench: A comprehensive multi-modal video understanding benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, Limin Wang, and Yu Qiao. Mvbench: A comprehensive multi-modal video understanding benchmark. InCVPR, 2024. 12
work page 2024
-
[48]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report. a...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. Video instruction tuning with synthetic data, 2024. URLhttps://arxiv.org/abs/2410.02713
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner
Angela Dai, Angel X. Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. InProc. Computer Vision and Pattern Recognition (CVPR), IEEE, 2017
work page 2017
-
[51]
Scannet++: A high- fidelity dataset of 3d indoor scenes
Chandan Yeshwanth, Yueh-Cheng Liu, Matthias Nießner, and Angela Dai. Scannet++: A high- fidelity dataset of 3d indoor scenes. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12–22, 2023
work page 2023
-
[52]
Conversational image segmentation: Grounding abstract concepts with scalable supervision
Aadarsh Sahoo and Georgia Gkioxari. Conversational image segmentation: Grounding abstract concepts with scalable supervision. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026
work page 2026
-
[53]
Bleu: a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. ACL, 2002
work page 2002
-
[54]
Meteor: an automatic metric for mt evaluation with high levels of correlation with human judgments
Alon Lavie and Abhaya Agarwal. Meteor: an automatic metric for mt evaluation with high levels of correlation with human judgments. ACL, 2007
work page 2007
-
[55]
ROUGE: A package for automatic evaluation of summaries
Chin-Yew Lin. ROUGE: A package for automatic evaluation of summaries. InText Summariza- tion Branches Out. ACL, 2004
work page 2004
-
[56]
Lawrence Zitnick, and Devi Parikh
Ramakrishna Vedantam, C. Lawrence Zitnick, and Devi Parikh. Cider: Consensus-based image description evaluation. InCVPR, 2015
work page 2015
-
[57]
Sagar Bharadwaj, Harrison Williams, Luke Wang, Michael Liang, Tao Jin, Srinivasan Seshan, and Anthony Rowe. Openflame: Federated visual positioning system to enable large-scale aug- mented reality applications. In2025 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), pages 706–716, 2025. doi: 10.1109/ISMAR67309.2025.00080
-
[58]
OpenFLAME: A Federated Spatial Naming Infrastructure
Sagar Bharadwaj, Ziyong Ma, Ivan Liang, Michael Farb, Anthony Rowe, and Srinivasan Seshan. OpenFLAME: A Federated Spatial Naming Infrastructure. In Katerina Argyraki and Aurojit Panda, editors,1st New Ideas in Networked Systems (NINeS 2026), volume 139 ofOpen Access Series in Informatics (OASIcs), pages 20:1–20:26, Dagstuhl, Germany, 2026. Schloss Dagstuh...
-
[59]
URL https://drops.dagstuhl.de/entities/document/10.4230/OASIcs.NINeS. 2026.20
-
[60]
Uniting the world by dividing it: Federated maps to enable spatial applications
Sagar Bharadwaj, Anthony Rowe, and Srinivasan Seshan. Uniting the world by dividing it: Federated maps to enable spatial applications. InProceedings of the 2025 Workshop on Hot Topics in Operating Systems, pages 74–79, 2025
work page 2025
-
[61]
Gabriel Ilharco, Mitchell Wortsman, Ross Wightman, Cade Gordon, Nicholas Carlini, Rohan Taori, Achal Dave, Vaishaal Shankar, Hongseok Namkoong, John Miller, Hannaneh Hajishirzi, Ali Farhadi, and Ludwig Schmidt. Openclip, July 2021. URL https://doi.org/10.5281/ zenodo.5143773. If you use this software, please cite it as below
work page 2021
-
[62]
A statistical method for evaluating systematic relationships
Robert R Sokal, Charles D Michener, et al. A statistical method for evaluating systematic relationships. 1958
work page 1958
-
[63]
Structure-from-motion revisited
Johannes Lutz Schönberger and Jan-Michael Frahm. Structure-from-motion revisited. In Conference on Computer Vision and Pattern Recognition (CVPR), 2016
work page 2016
-
[64]
A density-based algorithm for discovering clusters in large spatial databases with noise
Martin Ester, Hans-Peter Kriegel, Jörg Sander, and Xiaowei Xu. A density-based algorithm for discovering clusters in large spatial databases with noise. InProceedings of the Second International Conference on Knowledge Discovery and Data Mining, KDD’96, page 226–231. AAAI Press, 1996. 13
work page 1996
-
[65]
Dave Zhenyu Chen, Angel X. Chang, and Matthias Nießner. Scanrefer: 3d object localization in rgb-d scans using natural language. InECCV, 2020
work page 2020
-
[66]
Deep modular co-attention networks for visual question answering
Zhou Yu, Jun Yu, Yuhao Cui, Dacheng Tao, and Qi Tian. Deep modular co-attention networks for visual question answering. InCVPR, 2019
work page 2019
-
[67]
Scene-llm: Extending language model for 3d visual understanding and reasoning,
Rao Fu, Jingyu Liu, Xilun Chen, Yixin Nie, and Wenhan Xiong. Scene-llm: Extending language model for 3d visual understanding and reasoning.arXiv preprint arXiv:2403.11401, 2024
-
[68]
Chat-3d v2: Bridging 3d scene and large language models with object identifiers
Haifeng Huang, Zehan Wang, Rongjie Huang, Luping Liu, Xize Cheng, Yang Zhao, Tao Jin, and Zhou Zhao. Chat-3d v2: Bridging 3d scene and large language models with object identifiers. arXiv preprint arXiv:2312.08168, 2023
-
[69]
Chat-scene: Bridging 3d scene and large language models with object identifiers
Haifeng Huang, Yilun Chen, Zehan Wang, Rongjie Huang, Runsen Xu, Tai Wang, Luping Liu, Xize Cheng, Yang Zhao, Jiangmiao Pang, and Zhou Zhao. Chat-scene: Bridging 3d scene and large language models with object identifiers. InNeurIPS, 2024
work page 2024
-
[70]
Chenming Zhu, Tai Wang, Wenwei Zhang, Jiangmiao Pang, and Xihui Liu. Llava-3d: A simple yet effective pathway to empowering lmms with 3d-awareness.arXiv preprint arXiv:2409.18125, 2024. 14 A 3D Instance Segmentation Pipeline This section details the multi-stage pipeline that converts posed RGB frames into persistent 3D in- stance components referenced in ...
- [71]
-
[72]
CLIP embedding.The unique lemmatized labels are embedded with OpenCLIP [ 59] to obtain dense semantic representations
-
[73]
Agglomerative clustering.We cluster the embeddings using average-linkage agglomerative clustering [60] with a cosine-distance threshold (default 0.05). Within each cluster, the label whose embedding is closest to the cluster centroid is selected as the canonical representative, and all labels in the cluster are replaced by it. After normalization, we perf...
-
[74]
Construct amask canvasusing a painter’s algorithm: masks are sorted by bounding-box area (largest first) and painted onto an (H×W) index map, so that smaller masks on top override larger background masks
-
[75]
Project all COLMAP 2D feature points (whose 3D correspondences are known) onto the canvas. Each feature point’s pixel location is looked up in the index map to determine which mask (if any) it falls inside
-
[76]
Accumulate the 3D point IDs for each (object, sequence, instance) triple across all frames in the subsequence
-
[77]
Apply a per-mask DBSCAN [62] pass on the accumulated 3D coordinates (defaultε= 0.5 m, min_samples= 5) to discard spatial outlier points caused by noisy 2D projections. 15 The result is a dictionary mapping each instance triple (object slug, sequence index, SAM3 tracking ID) to its set of associated 3D point IDs. A.5 Mask Connectivity Graph The same physic...
-
[78]
Entities and Relations.Identifying or referring to an entity through an open-ended descrip- tion, possibly relative to other entities.Example:which object is closest to the red plastic chair?
-
[79]
Affordance.Reasoning about potential actions an agent can perform on an entity.Example: where can I sit in this room?
-
[80]
Functionality.Reasoning about the function of an entity.Example:find me something that can help with cleaning the room
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.