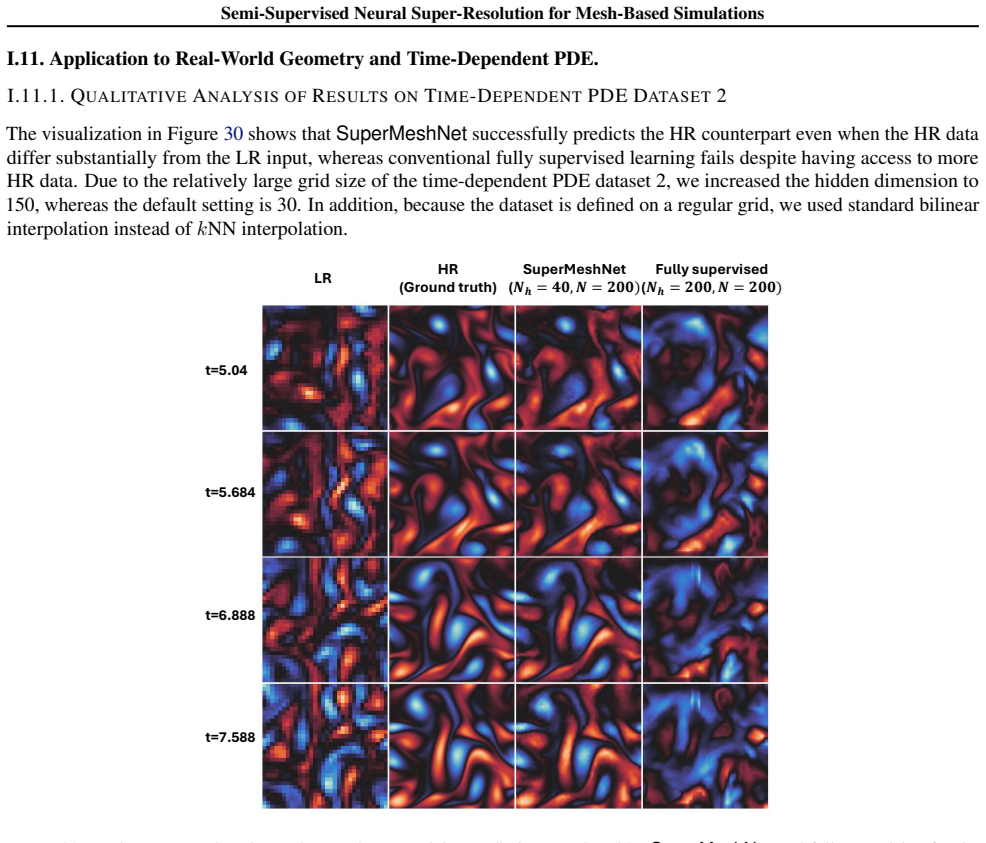
Recognition: 2 theorem links
· Lean TheoremSemi-Supervised Neural Super-Resolution for Mesh-Based Simulations
Pith reviewed 2026-05-12 04:06 UTC · model grok-4.3
The pith
SuperMeshNet uses semi-supervised complementary MPNNs to super-resolve mesh simulations with 90% less high-resolution data while beating fully supervised accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
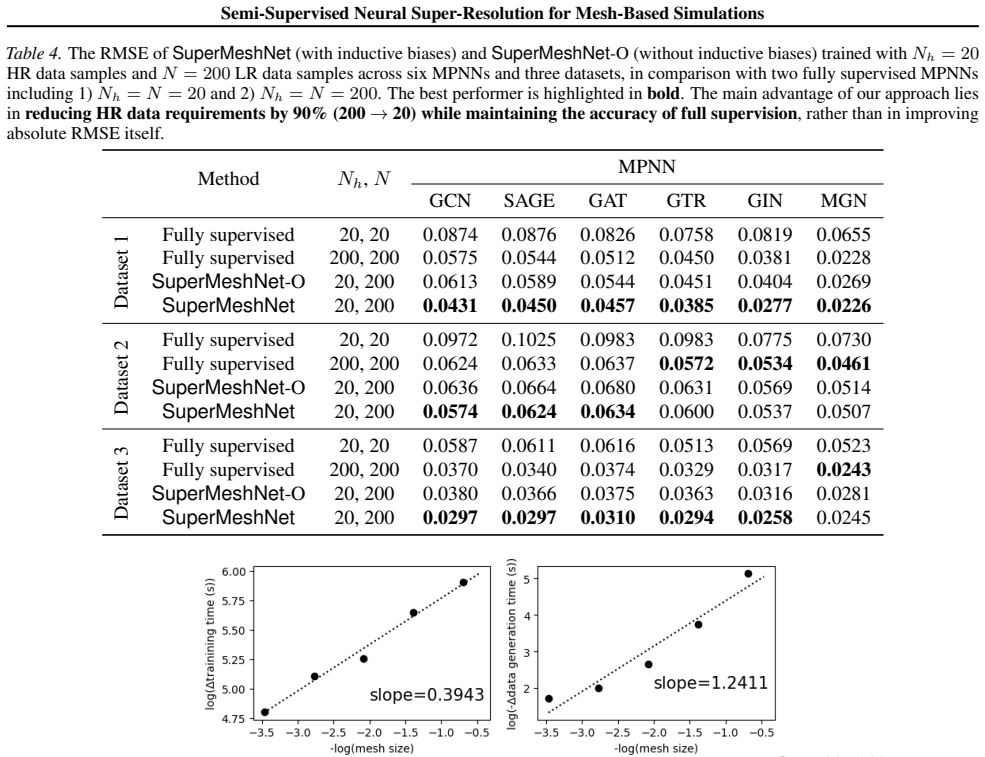
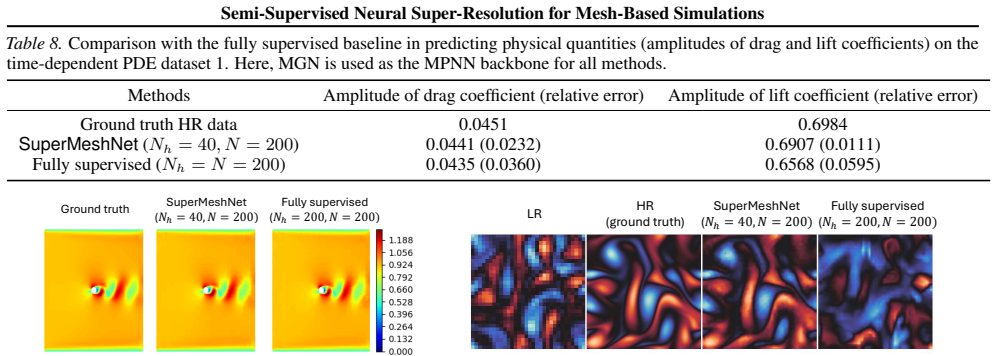
SuperMeshNet is a semi-supervised super-resolution framework for mesh-based PDE simulations that introduces complementary learning: two MPNN-based models are trained jointly so that one leverages abundant unpaired low-resolution data to provide supervisory signal to the other, which is itself trained on limited paired low-to-high data; the framework is further augmented by inductive biases that improve reconstruction quality, allowing it to reach lower RMSE than a fully supervised benchmark while using only 10 percent of the high-resolution training examples.
What carries the argument
Complementary learning between two jointly trained MPNN models that exchange supervisory signals derived from paired LR-HR examples and unpaired LR simulations
If this is right
- High-fidelity mesh simulations become feasible with far fewer expensive high-resolution training runs.
- Super-resolution post-processing can be applied to existing libraries of cheap low-resolution simulation outputs.
- Inductive biases can be combined with semi-supervised training to further reduce error without extra labeled data.
- The same complementary-learning pattern may apply to other graph-structured physical simulation tasks.
Where Pith is reading between the lines
- The approach may generalize to other graph neural network architectures used for PDE solving where high-resolution labels are scarce.
- It could enable real-time or interactive super-resolution inside engineering design loops that currently cannot afford fine-mesh training sets.
- Consistency between the two complementary models on unpaired data might serve as an implicit regularizer that improves robustness to mesh topology changes.
- Testing the method on time-dependent or multi-physics simulations would reveal whether the data-efficiency gain persists beyond steady-state problems.
Load-bearing premise
The two jointly trained complementary MPNN models can extract useful supervisory signal from abundant unpaired low-resolution data without introducing systematic biases that degrade super-resolved output on unseen meshes.
What would settle it
Train the model on a new collection of meshes where the distribution of the unpaired low-resolution runs differs markedly from the paired runs; if the RMSE on held-out high-resolution test cases is then higher than that of the fully supervised baseline trained on all available high-resolution data, the data-efficiency claim is falsified.
Figures



























read the original abstract
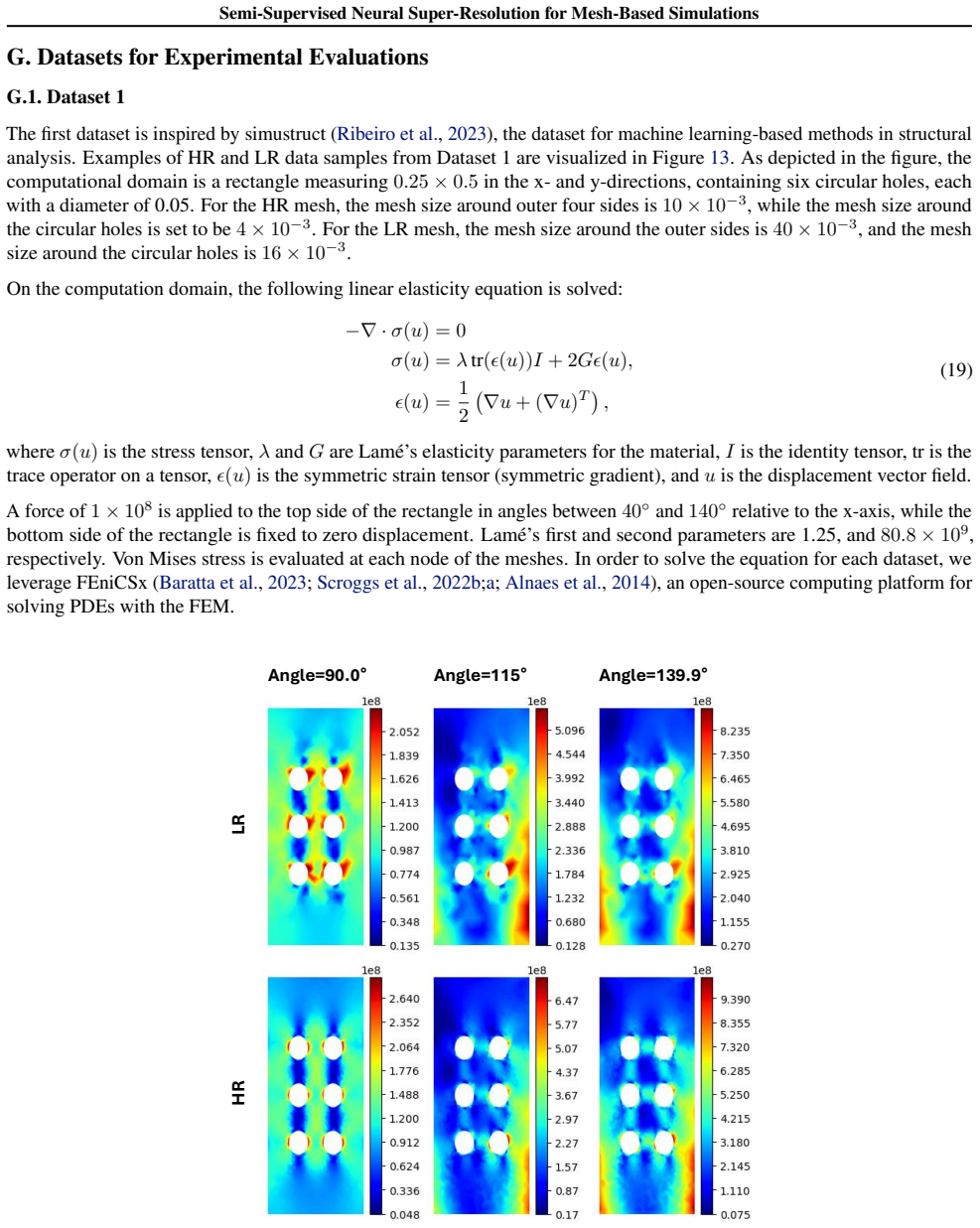
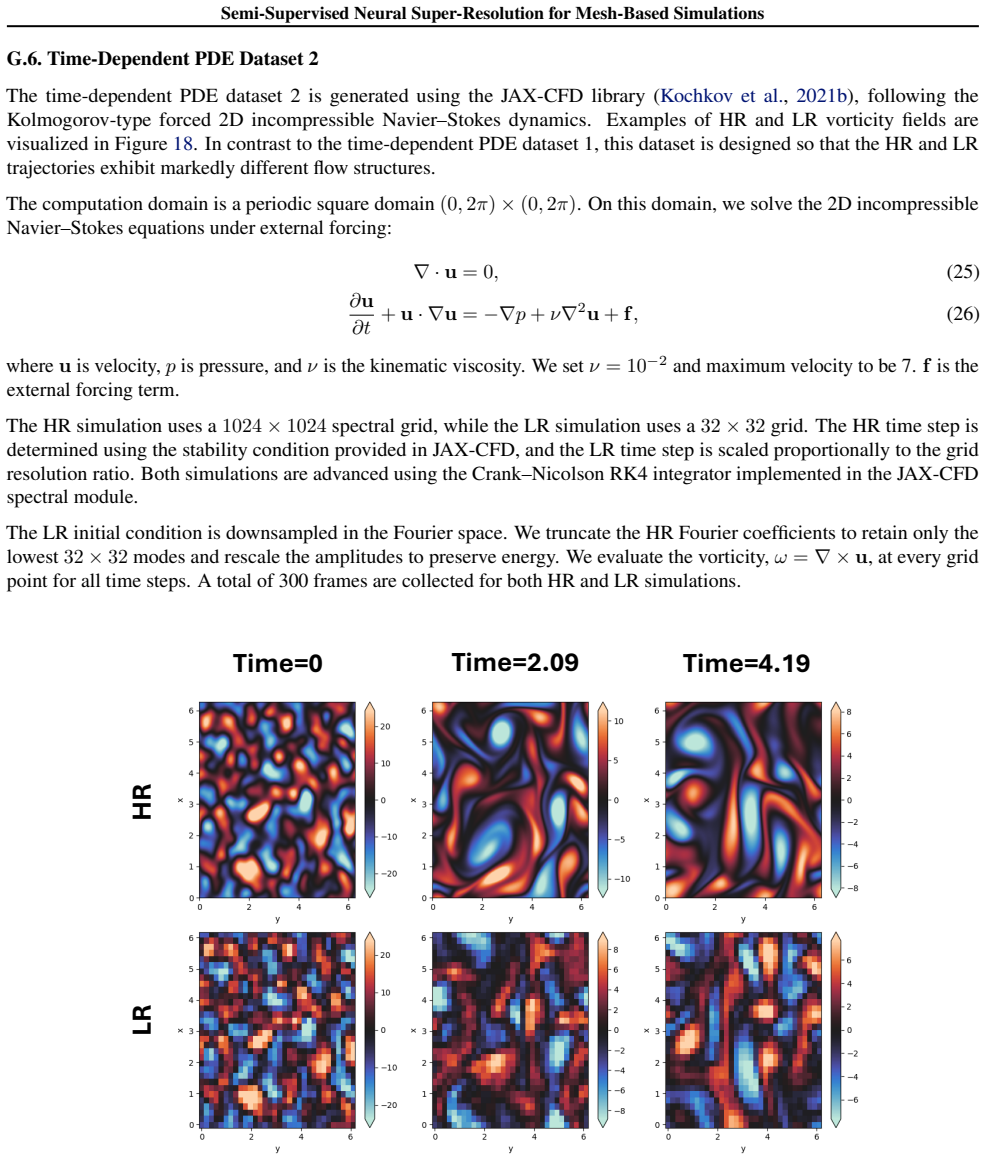
Mesh-based simulations provide high-fidelity solutions to partial differential equations (PDEs), but achieving such accuracy typically requires fine meshes, leading to substantial computational overhead. Super-resolution techniques aim to mitigate this cost by reconstructing high-resolution (HR), high-fidelity solutions from low-cost, low-resolution (LR) counterparts. However, training neural networks for super-resolution often demands large amounts of expensive HR supervision data. To address this challenge, we propose SuperMeshNet, an HR data-efficient super-resolution framework for mesh-based simulations aided by message passing neural networks (MPNNs). At its core, SuperMeshNet introduces complementary learning, a semi-supervised approach that effectively leverages both 1) a small amount of paired LR-HR data and 2) abundant unpaired LR data via two jointly trained, complementary MPNN-based models. Additionally, our model is enriched by inductive biases, which are empirically shown to further improve super-resolution performance. Extensive experiments demonstrate that SuperMeshNet requires 90% less HR data to achieve even lower root mean square error (RMSE) than that of the fully supervised benchmark without the inductive biases. The source code and datasets are available at https://github.com/jykim-git/SuperMeshNet.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SuperMeshNet, a semi-supervised super-resolution framework for mesh-based PDE simulations. It uses two jointly trained complementary MPNN models that leverage a small amount of paired LR-HR data together with abundant unpaired LR data, augmented by inductive biases. The central empirical claim is that the method achieves lower RMSE than a fully supervised benchmark while requiring only 10% of the HR training data.
Significance. If the performance claims are robust, the work could meaningfully reduce the cost of generating high-fidelity training data for neural surrogates in computational science. The public release of code and datasets is a clear strength that supports reproducibility and follow-on work.
major comments (1)
- [Experimental evaluation] The fully supervised benchmark explicitly omits the inductive biases present in SuperMeshNet. No ablation is reported that trains the bias-equipped architecture in a purely supervised regime on the identical 10% paired HR data (without the second complementary model or unpaired LR data). This comparison is required to determine whether the semi-supervised complementary learning, rather than the inductive biases alone, is responsible for the reported data-efficiency and RMSE improvement.
minor comments (2)
- The abstract and methods would benefit from an explicit statement of how the inductive biases are realized inside the MPNN layers (e.g., specific message-passing rules or architectural constraints).
- Table or figure captions should clearly indicate the exact fraction of HR data used in each compared method so that the 90% reduction claim can be verified at a glance.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The suggestion to clarify the source of performance gains through an additional ablation is well-taken and will strengthen the experimental section. We address the major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Experimental evaluation] The fully supervised benchmark explicitly omits the inductive biases present in SuperMeshNet. No ablation is reported that trains the bias-equipped architecture in a purely supervised regime on the identical 10% paired HR data (without the second complementary model or unpaired LR data). This comparison is required to determine whether the semi-supervised complementary learning, rather than the inductive biases alone, is responsible for the reported data-efficiency and RMSE improvement.
Authors: We agree that this ablation is necessary to isolate the contribution of the semi-supervised complementary learning from the inductive biases. In the submitted manuscript, the fully supervised baseline was implemented without inductive biases to provide a standard comparison point from the literature, while SuperMeshNet combines both the biases and the semi-supervised training. To directly address the concern, we will include in the revised manuscript results for the bias-equipped MPNN architecture trained in a purely supervised regime on the same 10% paired HR data (without the complementary model or unpaired LR data). This will enable a clearer attribution of the observed RMSE improvements and data efficiency. revision: yes
Circularity Check
No significant circularity; empirical method with independent experimental validation
full rationale
The paper describes an empirical semi-supervised training procedure for mesh super-resolution using complementary MPNN models and added inductive biases. No equations, derivations, or predictions are presented that reduce the reported RMSE or data-efficiency claims to fitted constants or self-referential definitions by construction. Performance is evaluated via standard train/test splits on simulation datasets against external benchmarks, with no load-bearing self-citations or ansatzes that collapse the central result to its inputs. The method is self-contained as a practical ML framework rather than a closed-form theoretical derivation.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SuperMeshNet introduces complementary learning... two jointly trained, complementary MPNN-based models... node-level centering and message-level centering
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
inductive biases... subtracts the mean of all node embeddings... message-level centering
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Brefeld, U., Gärtner, T., Scheffer, T., and Wrobel, S
URL https://openreview.net/forum? id=bx2roi8hca8. Brefeld, U., Gärtner, T., Scheffer, T., and Wrobel, S. Ef- ficient co-regularised least squares regression.Pro- ceedings of the 23rd International Conference on Machine Learning, 2006. URL https://api. semanticscholar.org/CorpusID:2025415. Chen, Y ., Welling, M., and Smola, A. Super-samples from kernel her...
work page 2006
-
[2]
URL https://api.semanticscholar. org/CorpusID:220424832. Guo, Y ., Song, J., Cao, X., Zhao, C., and Leng, H. Physics field super-resolution reconstruction via enhanced diffusion model and Fourier neu- ral operator.Theoretical and Applied Mechanics Letters, 15(5):100604, 2025. ISSN 2095-0349. doi: https://doi.org/10.1016/j.taml.2025.100604. URL https://www...
-
[3]
URL https://www.sciencedirect.com/ science/article/pii/S2092678216303879
doi: https://doi.org/10.2478/IJNAOE-2013-0011. URL https://www.sciencedirect.com/ science/article/pii/S2092678216303879. Kipf, T. N. and Welling, M. Semi-supervised classifica- tion with graph convolutional networks. InInternational Conference on Learning Representations (ICLR), 2017. Kochkov, D., Smith, J. A., Alieva, A., Wang, Q., Brenner, M. P., and Ho...
-
[4]
ISSN 1530-9827. doi: 10.1115/1.4053671. URL https://doi.org/10.1115/1.4053671. Obiols-Sales, O., Vishnu, A., Malaya, N. P., and Chan- dramowlishwaran, A. SURFNet: Super-resolution of tur- bulent flows with transfer learning using small datasets. InProceedings of the 30th International Conference on Parallel Architectures and Compilation Techniques, PACT ’...
-
[5]
URL https://www.sciencedirect.com/ science/article/pii/S0021999118307125. Ribeiro, B. A., Ribeiro, J. A., Ahmed, F., Penedones, H., Belinha, J., Sarmento, L., Bessa, M. A., and Tavares, S. SimuStruct: Simulated structural plate with holes 11 Semi-Supervised Neural Super-Resolution for Mesh-Based Simulations dataset with machine learning applications. InWo...
work page 2023
-
[6]
Santurkar, S., Tsipras, D., Ilyas, A., and M ˛ adry, A
URL https://openreview.net/forum? id=s3tOuyR1vM7. Santurkar, S., Tsipras, D., Ilyas, A., and M ˛ adry, A. How does batch normalization help optimization? InProceed- ings of the 32nd International Conference on Neural In- formation Processing Systems, NIPS’18, pp. 2488–2498, Red Hook, NY , USA, 2018. Curran Associates Inc. Scroggs, M. W., Baratta, I. A., R...
-
[7]
URL https://openreview.net/forum? id=B9t708KMr9d. Tarvainen, A. and Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. InProceedings of the 31st International Conference on Neural Informa- tion Processing Systems, NIPS’17, pp. 1195–1204, Red Hook, NY , USA, 2017. Curran Asso...
work page 2017
-
[8]
URL https://openreview.net/forum? id=rJXMpikCZ. Wetzel, S. J., Melko, R. G., and Tamblyn, I. Twin neural net- work regression is a semi-supervised regression algorithm. Machine Learning: Science and Technology, 3(4):045007, oct 2022. doi: 10.1088/2632-2153/ac9885. URL https: //dx.doi.org/10.1088/2632-2153/ac9885. Xu, K., Hu, W., Leskovec, J., and Jegelka,...
-
[9]
Find k nearest neighbors (kNN).For each node in the target mesh, identify the k closest nodes in the source mesh. For example, as illustrated in Figure 10, the darker blue nodes represent the three nearest neighbors of the darker yellow node
-
[10]
3.Unknown quantity.The value at the target node, denoted byy 0
Known information.The nodal positions of the k nearest source nodes pi (1≤i≤k ), their values yi, and the target node positionp 0. 3.Unknown quantity.The value at the target node, denoted byy 0
-
[11]
The interpolated value at the target nodey 0 is then obtained as y0 = Pk i=1 wiyi Pk i=1 wi
Compute the target node value via weighted averaging.The interpolation weight for each neighbor is defined as the inverse squared distance from the target node: wi = 1 d(p0, pi)2 , whered(·,·)denotes the Euclidean distance. The interpolated value at the target nodey 0 is then obtained as y0 = Pk i=1 wiyi Pk i=1 wi . 16 Semi-Supervised Neural Super-Resolut...
work page 2024
-
[12]
• Force prediction: forces depend on relative distances, not absolute positions
Scientific tasks • V orticity prediction: the vorticity field depends on the local rotational structure, not the mean velocity. • Force prediction: forces depend on relative distances, not absolute positions
-
[13]
General graph learning tasks • Node classification: predictions rely mainly on relational structures, not absolute feature scales. • Link prediction: predictions depend on similarity between features rather than the absolute feature scale. These tasks may benefit from our inductive biases. 35 Semi-Supervised Neural Super-Resolution for Mesh-Based Simulati...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.