Recognition: 2 theorem links
· Lean TheoremGenerating Complex Code Analyzers from Natural Language Questions
Pith reviewed 2026-05-12 04:58 UTC · model grok-4.3
The pith
Merlin converts natural language questions into reliable CodeQL queries that let programmers analyze million-line codebases more accurately and quickly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
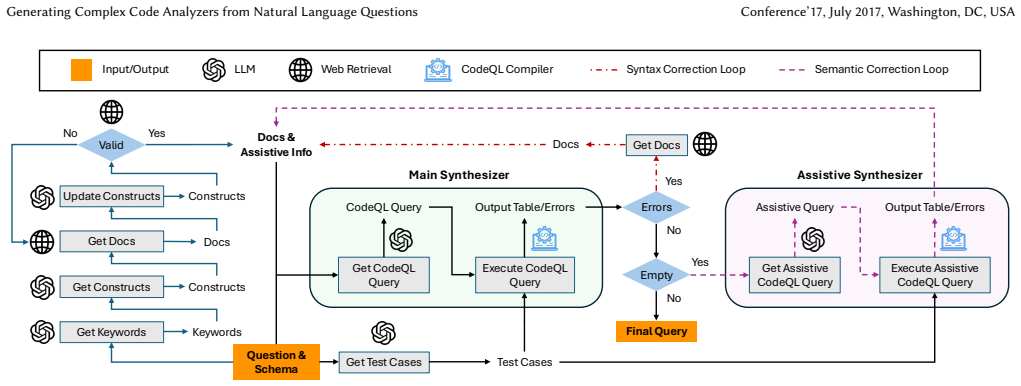
Merlin integrates an LLM with CodeQL through a RAG-based iterative query-generation approach and a novel self-test technique that builds assistive queries to generate witnesses exposing flaws in candidate queries, thereby producing non-degenerate and semantically correct analyzers from natural language questions about large codebases.
What carries the argument
RAG-based iterative query-generation combined with the assistive-query self-test technique that produces concrete witnesses to debug semantic flaws in candidate CodeQL queries.
If this is right
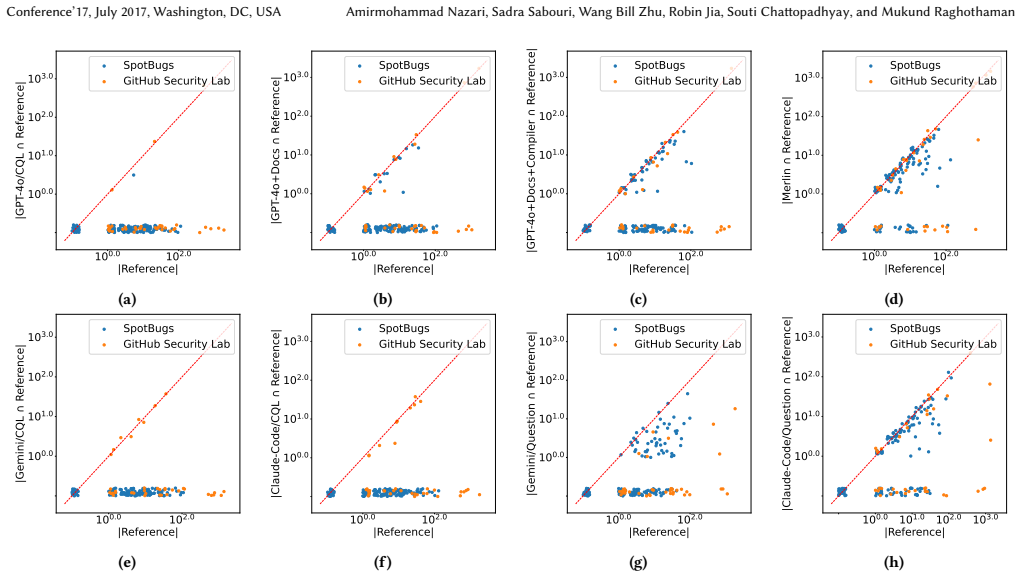
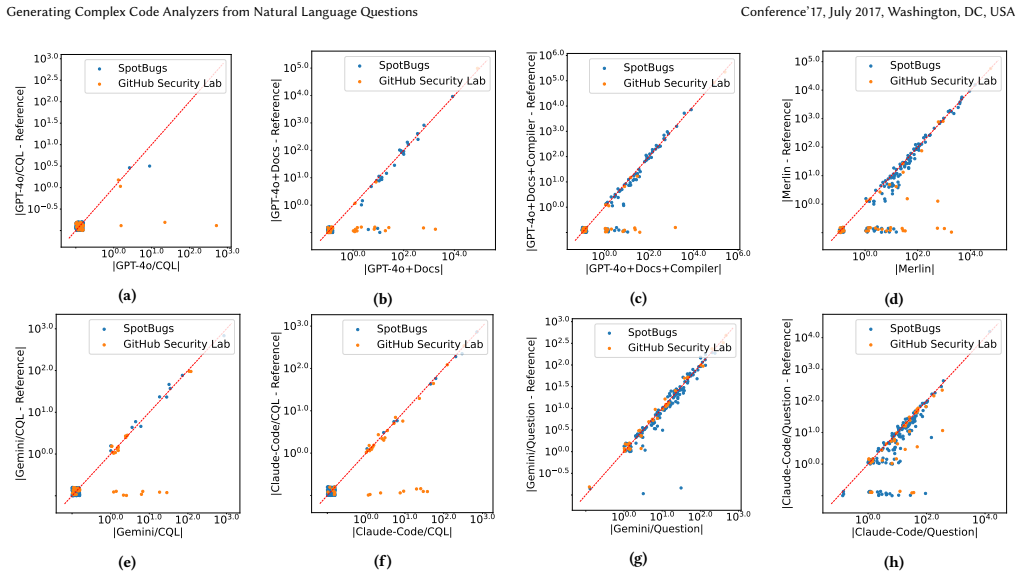
- Merlin recovers the majority of software issues reported by other approaches and additionally finds issues that would otherwise remain undetected.
- Programmers using Merlin complete analysis tasks with 3.8 times higher accuracy on average.
- Access to Merlin reduces the total time programmers spend on the same set of tasks by 31 percent.
- The system can answer questions that demand semantic or inter-procedural reasoning beyond the reach of simple text search tools.
Where Pith is reading between the lines
- The assistive-query debugging pattern could be applied to refine LLM outputs in other program-analysis or query languages.
- Embedding Merlin-style assistance inside development environments might let non-experts perform advanced static analysis without learning query syntax.
- The same iterative refinement loop may shorten the time needed to adapt CodeQL queries to new codebases or new classes of bugs.
Load-bearing premise
The RAG-based iterative query-generation approach together with the assistive-query self-test will reliably yield non-degenerate and semantically correct CodeQL queries for diverse natural language questions on large codebases.
What would settle it
A test set of natural language questions drawn from real bug-finding tasks where Merlin produces mostly empty or incorrect CodeQL queries that fail to detect known issues in a million-line codebase.
Figures






read the original abstract
Many software development tasks, such as implementing features and fixing bugs, begin with developers posing questions about a codebase. However, answering questions about codebases that span millions of lines of code across thousands of files is non-trivial. Standard tools like grep cannot answer questions requiring semantic or inter-procedural reasoning, and large language models (LLMs) struggle with large codebases due to resource and context constraints. In this paper, we present Merlin, a new system for answering free-form questions that require analytical reasoning about code. Merlin integrates an LLM with CodeQL, a program analysis framework that supports expressive queries over large codebases. We face two principal challenges in the design of such systems: First, program analysis queries are diverse and semantically complex; as a result, even syntactically well-formed queries frequently produce degenerate/empty results. Furthermore, relatively few CodeQL queries are available online, limiting the out-of-the-box effectiveness of LLMs as CodeQL query generators. We address these challenges by developing a RAG-based iterative query-generation approach and a novel self-test technique. Our query debugging technique builds on the idea of assistive queries, which generate concrete witnesses that expose and explain semantic flaws in candidate queries. We evaluate Merlin through both experimental and user studies. Over a set of natural language questions derived from common bug-finding tasks, Merlin discovered not only the majority of software issues reported by other approaches, but also issues that would have otherwise remained undetected. Through a within-subject user study, we found that access to Merlin increased task accuracy by an average of 3.8* and simultaneously reduced the time for programmers to complete all tasks by 31%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Merlin, a system that combines LLMs with CodeQL to answer free-form natural language questions about large codebases requiring semantic or inter-procedural reasoning. It tackles challenges of query diversity and limited training examples via a RAG-based iterative query-generation approach and a self-test technique using assistive queries that produce concrete witnesses to expose semantic flaws. Experimental evaluation on bug-finding tasks shows Merlin recovers most issues found by prior approaches while detecting additional ones; a within-subject user study reports that Merlin access yields 3.8x higher task accuracy and 31% lower completion time.
Significance. If the user-study results hold after addressing potential confounds, the work would meaningfully advance automated code analysis by providing a practical natural-language interface to expressive static-analysis frameworks. The RAG-plus-self-test pipeline offers a concrete, reproducible method for generating reliable CodeQL queries from informal questions, which could reduce the barrier to using program analysis in everyday development. The empirical demonstration that the system both matches and exceeds existing bug finders on real tasks is a strength.
major comments (1)
- User-study section: The central claim of 3.8x accuracy gain and 31% time reduction rests on a within-subject design, yet the manuscript provides no description of counterbalancing task order, randomizing condition sequence, or analyzing per-participant ordering effects. Without these controls, learning or familiarity with the codebases on the second exposure could account for a substantial fraction of the reported deltas, undermining causal attribution to Merlin.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address the concern regarding the user study design below and will incorporate the necessary clarifications in the revised manuscript.
read point-by-point responses
-
Referee: User-study section: The central claim of 3.8x accuracy gain and 31% time reduction rests on a within-subject design, yet the manuscript provides no description of counterbalancing task order, randomizing condition sequence, or analyzing per-participant ordering effects. Without these controls, learning or familiarity with the codebases on the second exposure could account for a substantial fraction of the reported deltas, undermining causal attribution to Merlin.
Authors: We agree that the current manuscript lacks sufficient detail on these controls, which is necessary to fully support causal claims about Merlin's impact. In the revised version, we will expand the User Study section to describe the counterbalancing of task order across participants, the randomization of condition sequences (Merlin vs. baseline), and any post-experiment analysis of per-participant ordering effects. These additions will allow readers to evaluate the robustness of the 3.8x accuracy and 31% time improvements. revision: yes
Circularity Check
No significant circularity in empirical system evaluation
full rationale
The paper describes the Merlin system architecture (RAG-based iterative query generation plus assistive-query self-test) and supports its claims solely through independent experimental benchmarks and a within-subject user study reporting measured accuracy and time deltas. No equations, fitted parameters, self-definitional constructs, or derivation steps appear in the abstract or described content. The evaluation results are presented as direct measurements on external tasks and participants rather than reductions of outputs to inputs by construction. Self-citations, if present in the full text, are not load-bearing for the central empirical claims.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearMerlin integrates an LLM with CodeQL... RAG-based iterative query-generation approach and a novel self-test technique... assistive queries...
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearaccess to Merlin increased task accuracy by an average of 3.8× and simultaneously reduced the time... by 31%.
Reference graph
Works this paper leans on
-
[1]
Amazon. 2025.Amazon CodeGuru Reviewer. https://docs.aws.amazon.com/ codeguru/latest/reviewer-ug/welcome.html
work page 2025
-
[2]
Shengnan An, Zexiong Ma, Zeqi Lin, Nanning Zheng, Jian-Guang Lou, and Weizhu Chen. 2024. Make your llm fully utilize the context.Advances in Neural Information Processing Systems37 (2024), 62160–62188
work page 2024
-
[3]
Anthropic. 2025. Your code’s new collaborator. https://www.anthropic.com/claude-code. https://www.anthropic.com/claude- code
work page 2025
-
[4]
Pavel Avgustinov, Oege de Moor, Michael Peyton Jones, and Max Schäfer. 2016. QL: Object-oriented Queries on Relational Data. InProceedings of the European Conference on Object-Oriented Programming (ECOOP)
work page 2016
-
[5]
Cristian Cadar, Daniel Dunbar, and Dawson Engler. 2008. KLEE: unassisted and automatic generation of high-coverage tests for complex systems programs. InProceedings of the 8th USENIX Conference on Operating Systems Design and Implementation(San Diego, California)(OSDI’08). USENIX Association, USA, 209–224
work page 2008
-
[6]
2024.Multiline & Structural Code Search
CodeQue.co. 2024.Multiline & Structural Code Search. https://marketplace. visualstudio.com/items?itemName=CodeQue.codeque
work page 2024
-
[7]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. 2025. Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multi- modality, Long Context, and Next Generation Agentic Capabilities.arXiv preprint arXiv:2507.06261(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Cursor. 2025. The AI Code Editor. https://cursor.com/en. https://cursor.com/en
work page 2025
- [9]
-
[10]
Philipp Eibl, Sadra Sabouri, and Souti Chattopadhyay. 2025. Exploring the Chal- lenges and Opportunities of AI-assisted Codebase Generation. In2025 IEEE Sym- posium on Visual Languages and Human-Centric Computing (VL/HCC). IEEE, 241–252
work page 2025
-
[11]
Andrea Fioraldi, Dominik Maier, Heiko Eißfeldt, and Marc Heuse. 2020. AFL++: combining incremental steps of fuzzing research. InProceedings of the 14th USENIX Conference on Offensive Technologies (WOOT’20). USENIX Association, USA, Article 10, 1 pages
work page 2020
-
[12]
GitHub. 2021.GitHub Copilot. Retrieved 19 July, 2025 from https://github.com/ features/copilot
work page 2021
-
[13]
2025.Expr.MethodCall — CodeQL Standard Libraries
GitHub. 2025.Expr.MethodCall — CodeQL Standard Libraries. https: //codeql.github.com/codeql-standard-libraries/java/semmle/code/java/Expr.qll/ type.Expr$MethodCall.html
work page 2025
- [14]
-
[15]
David Hovemeyer and William Pugh. 2004. Finding bugs is easy.SIGPLAN Not. 39, 12 (Dec. 2004), 92–106. doi:10.1145/1052883.1052895
-
[16]
2024.Structural search and replace
JetBrains. 2024.Structural search and replace. https://www.jetbrains.com/help/ idea/structural-search-and-replace.html
work page 2024
-
[17]
2024.Joern: The Bug Hunter’s Workbench
joern.io. 2024.Joern: The Bug Hunter’s Workbench. Retrieved 29 January, 2026 from https://github.com/joernio/joern
work page 2024
-
[18]
Mary Beth Kery and Brad A Myers. 2017. Exploring exploratory programming. In2017 IEEE Symposium on Visual Languages and Human-Centric Computing (VL/HCC). IEEE, 25–29
work page 2017
-
[19]
Joshua Klayman. 1995. Varieties of confirmation bias.Psychology of learning and motivation32 (1995), 385–418
work page 1995
-
[20]
Ko, Rebecca DeLine, and Gina Venolia
Andrew J. Ko, Rebecca DeLine, and Gina Venolia. 2007. Information needs in collocated software development teams. InProceedings of the 29th International Conference on Software Engineering (ICSE). IEEE, 344–353
work page 2007
-
[21]
Amy J. Ko, Brad A. Myers, Michael J. Coblenz, and Htet Htet Aung. 2006. An Exploratory Study of How Developers Seek, Relate, and Collect Relevant In- formation during Software Maintenance Tasks.IEEE Transactions on Software Engineering32, 12 (2006), 971–987. doi:10.1109/TSE.2006.116
-
[22]
Thomas D LaToza and Brad A Myers. 2010. Hard-to-answer questions about code. InEvaluation and usability of programming languages and tools. 1–6
work page 2010
-
[23]
Thomas D. LaToza and Brad A. Myers. 2010. Hard-to-answer questions about code. InEvaluation and Usability of Programming Languages and Tools(Reno, Nevada)(PLATEAU ’10). Association for Computing Machinery, New York, NY, USA, Article 8, 6 pages. doi:10.1145/1937117.1937125
-
[24]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-augmented generation for knowledge-intensive NLP tasks. InProceedings of the 34th International Conference on Neural Information Processing Systems(Van...
work page 2020
-
[25]
Penghui Li, Songchen Yao, Josef Sarfati Korich, Changhua Luo, Jianjia Yu, Yinzhi Cao, and Junfeng Yang. 2025. Automated Static Vulnerability Detection via a Holistic Neuro-symbolic Approach. arXiv:2504.16057 [cs.CR] https://arxiv.org/ abs/2504.16057
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [26]
- [27]
-
[28]
2011.The CERT Oracle Secure Coding Standard for Java
Fred Long, Dhruv Mohindra, Robert Seacord, Dean Sutherland, and David Svo- boda. 2011.The CERT Oracle Secure Coding Standard for Java. Addison-Wesley
work page 2011
-
[29]
Roberto Minelli, Andrea Mocci, and Michele Lanza. 2015. I know what you did last summer-an investigation of how developers spend their time. In2015 IEEE 23rd international conference on program comprehension. IEEE, 25–35
work page 2015
-
[30]
2008.MET05-J: Ensure that constructors do not call overridable methods
Dhruv Mohindra. 2008.MET05-J: Ensure that constructors do not call overridable methods. Retrieved 19 July, 2025 from https://wiki.sei.cmu.edu/confluence/ display/java/MET05-J.+Ensure+that+constructors+do+not+call+overridable+ methods
work page 2008
-
[31]
Nicholas Nethercote and Julian Seward. 2007. Valgrind: a framework for heavy- weight dynamic binary instrumentation.SIGPLAN Not.42, 6 (June 2007), 89–100. doi:10.1145/1273442.1250746
-
[32]
Juri Opitz. 2024. A Closer Look at Classification Evaluation Metrics and a Critical Reflection of Common Evaluation Practice.Transactions of the Association for Computational Linguistics12 (2024), 820–836. doi:10.1162/tacl_a_00675
-
[33]
Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language Models are Unsupervised Multitask Learners. (2019)
work page 2019
-
[34]
Sadra Sabouri, Philipp Eibl, Xinyi Zhou, Morteza Ziyadi, Nenad Medvidovic, Lars Lindemann, and Souti Chattopadhyay. 2025. Trust Dynamics in AI-Assisted Development: Definitions, Factors, and Implications . In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE Computer Society, 736–736. doi:10.1109/ICSE55347.2025.00199
-
[35]
Konstantin Serebryany, Derek Bruening, Alexander Potapenko, and Dmitry Vyukov. 2012. AddressSanitizer: A Fast Address Sanity Checker. InUSENIX ATC 2012. https://www.usenix.org/conference/usenixfederatedconferencesweek/ addresssanitizer-fast-address-sanity-checker
work page 2012
-
[36]
Jonathan Sillito, Gail C. Murphy, and Kris De Volder. 2008. Asking and answering questions during a programming change task.IEEE Transactions on Software Engineering34, 4 (2008), 434–451
work page 2008
-
[37]
M.-A. Storey. 2005. Theories, methods and tools in program comprehension: past, present and future. In13th International Workshop on Program Comprehension (IWPC’05). 181–191. doi:10.1109/WPC.2005.38
-
[38]
GitHub Security Lab Team. 2025.GitHub Security Lab. Retrieved 19 July, 2025 from https://github.com/github/securitylab
work page 2025
-
[39]
Semgrep Core Team. 2020.Semgrep. Retrieved 19 July, 2025 from https://semgrep. dev
work page 2020
-
[40]
2025.SpotBugs: Find Bugs in Java Programs
SpotBugs Core Team. 2025.SpotBugs: Find Bugs in Java Programs. Retrieved 19 July, 2025 from https://spotbugs.github.io/ Generating Complex Code Analyzers from Natural Language Questions Conference’17, July 2017, Washington, DC, USA
work page 2025
-
[41]
2024.Comby - Structural code search and replace for every language
Rijnard van Tonder. 2024.Comby - Structural code search and replace for every language. https://comby.dev/
work page 2024
-
[42]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2023. Attention Is All You Need. arXiv:1706.03762 [cs.CL] https://arxiv.org/abs/1706.03762
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
Zhangchen Xu, Yang Liu, Yueqin Yin, Mingyuan Zhou, and Radha Poovendran
-
[44]
Kodcode: A diverse, challenging, and verifiable synthetic dataset for coding
KodCode: A Diverse, Challenging, and Verifiable Synthetic Dataset for Coding. arXiv:2503.02951 [cs.LG] https://arxiv.org/abs/2503.02951
-
[45]
Michael JQ Zhang and Eunsol Choi. 2025. Clarify When Necessary: Resolving Ambiguity Through Interaction with LMs. InFindings of the Association for Computational Linguistics: NAACL 2025, Luis Chiruzzo, Alan Ritter, and Lu Wang (Eds.). Association for Computational Linguistics, Albuquerque, New Mexico, 5526–5543. doi:10.18653/v1/2025.findings-naacl.306
- [46]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.