Recognition: 2 theorem links
· Lean TheoremYour Simulation Runs but Solves the Wrong Physics: PDE-Grounded Intent Verification for LLM-Generated Multiphysics Simulation Code
Pith reviewed 2026-05-12 03:49 UTC · model grok-4.3
The pith
LLM-generated multiphysics code can execute and converge while encoding physics different from the user's intent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A generated input file can run, mesh, and converge while encoding governing equations that differ from the user's intent. We call this mismatch the comprehension-generation gap. In MOOSE, Kernel and BC objects enable deterministic reconstruction of the encoded PDE for comparison to an intended contract via the Intent Fidelity Score. A PDE-grounded refinement loop corrects generated code iteratively, improving mean IFS with larger gains on hard cases, and revealing that executability and intent fidelity are separable failure modes.
What carries the argument
The compositional mapping from MOOSE Kernel and BC objects to weak-form residual terms, which supports deterministic PDE reconstruction and comparison through the Intent Fidelity Score.
Load-bearing premise
Kernel and BC objects in MOOSE map compositionally to weak-form residual terms in a way that permits deterministic and complete reconstruction of the encoded PDE.
What would settle it
A generated MOOSE input file whose reconstructed PDE matches the intended contract under IFS yet produces physically inconsistent results in independent validation runs, or a case where the refinement loop reports violations but leaves IFS unchanged on a known test PDE.
Figures










read the original abstract
Execution-based evaluation of LLM-generated code implicitly treats successful execution as a proxy for correctness. In scientific simulation, this proxy is insufficient: a generated input file can run, mesh, and converge while encoding governing equations that differ from the user's intent. We call this mismatch between intended physics and generated code the comprehension-generation gap. We instantiate this in MOOSE, where Kernel and BC objects map compositionally to weak-form residual terms, enabling deterministic reconstruction of the encoded PDE and comparison against an intended contract. We formalize this comparison as the Intent Fidelity Score (IFS), a structural metric covering governing terms, BCs, ICs, coefficients, and time scheme. Building on IFS, we develop a PDE-grounded refinement loop that uses deterministic violation reports to correct generated code iteratively. We evaluate on MooseBench, a 220-case multiphysics benchmark with PDE-level ground truth released with this work. On this benchmark, our method consistently improves mean IFS over direct generation, with gains concentrated on hard cases. On the subset where direct generation falls below IFS 0.7, refinement adds +0.22 to +0.41 absolute IFS. In the deployment audit, execution-only repair improves execution success while leaving 39-40% of all 220 cases runnable but still solving the wrong physics across the three main deployment-audit models, exposing executability and intent fidelity as separable failure modes. Static proof-of-concept experiments on four PDE-oriented DSLs (UFL/FEniCS, FreeFEM, FiPy, and Devito) suggest that the reconstruction-and-comparison pattern extends beyond MOOSE. These findings reinforce that executable simulation code should be verified against the mathematical structure it is intended to encode, not accepted on execution alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that execution success is an insufficient proxy for correctness in LLM-generated multiphysics simulation code, as a runnable input file may still encode governing equations differing from user intent (the 'comprehension-generation gap'). It instantiates this for MOOSE by asserting that Kernel/BC objects map compositionally to weak-form residuals, enabling deterministic PDE reconstruction and comparison via the new Intent Fidelity Score (IFS) metric (covering terms, BCs, ICs, coefficients, time scheme). It introduces a PDE-grounded iterative refinement loop using IFS violation reports, releases MooseBench (220-case benchmark with PDE ground truth), reports consistent mean IFS gains (concentrated on hard cases, +0.22 to +0.41 on low-IFS subset), and shows via deployment audit that execution-only repair leaves 39-40% of cases runnable but solving wrong physics. Static experiments suggest the pattern extends to UFL/FEniCS, FreeFEM, FiPy, and Devito.
Significance. If the reconstruction is reliable and complete, the work is significant for exposing a separable failure mode (executability vs. intent fidelity) in scientific code generation evaluation, providing a released benchmark with explicit PDE-level ground truth, and demonstrating a practical refinement method. Credit is due for the reproducible benchmark release and the audit results that quantify the gap across models.
major comments (2)
- [Abstract and §3] Abstract and §3 (reconstruction procedure): the claim that 'Kernel and BC objects map compositionally to weak-form residual terms, enabling deterministic reconstruction' is load-bearing for both IFS and the refinement loop. However, kernels depending on Materials, Functions, coupled variables, or AD-resolved coefficients resolve their actual residual contributions only at runtime; if the procedure inspects only top-level blocks without fully resolving these, the recovered PDE can differ from the assembled one, undermining IFS reliability on multiphysics MooseBench cases.
- [§5] §5 (deployment audit and results): the 39-40% figure for runnable-but-wrong-physics cases is a key finding, but requires explicit description of how intended contracts were encoded for all 220 cases and how IFS was computed during the audit (including any handling of non-static dependencies) to support the separability claim.
minor comments (2)
- [Figures/Tables] Figure and table captions should explicitly state the number of runs or seeds used for the reported mean IFS gains to allow reproducibility assessment.
- [Introduction] Add a short related-work subsection contrasting IFS with existing static analysis or symbolic verification tools for simulation codes.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments, which highlight important aspects of our reconstruction procedure and audit methodology. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (reconstruction procedure): the claim that 'Kernel and BC objects map compositionally to weak-form residual terms, enabling deterministic reconstruction' is load-bearing for both IFS and the refinement loop. However, kernels depending on Materials, Functions, coupled variables, or AD-resolved coefficients resolve their actual residual contributions only at runtime; if the procedure inspects only top-level blocks without fully resolving these, the recovered PDE can differ from the assembled one, undermining IFS reliability on multiphysics MooseBench cases.
Authors: We appreciate the referee highlighting this important nuance regarding runtime resolution. In §3, our reconstruction procedure parses the MOOSE input file blocks to identify declared Kernel, BC, Material, Function, and variable objects along with their parameters and couplings; these declarations directly encode the structural contributions to the weak-form residuals in a compositional manner, as MOOSE's object system is designed for static specification of physics. While actual numerical evaluation of Materials, Functions, or AD coefficients occurs at runtime, the symbolic structure (term types, coefficient dependencies, and variable couplings) is recoverable from the input without execution. For the MooseBench cases, which use standard multiphysics compositions, this yields reliable IFS values. That said, we agree that the manuscript would benefit from greater explicitness on these points. In the revision, we will expand §3 with additional text and a clarifying example illustrating how non-static elements are handled in reconstruction, along with a brief discussion of scope and limitations for fully dynamic cases. This will reinforce the deterministic nature of the procedure for the benchmark while acknowledging the distinction between structural and fully evaluated residuals. revision: yes
-
Referee: [§5] §5 (deployment audit and results): the 39-40% figure for runnable-but-wrong-physics cases is a key finding, but requires explicit description of how intended contracts were encoded for all 220 cases and how IFS was computed during the audit (including any handling of non-static dependencies) to support the separability claim.
Authors: We agree that these methodological details are necessary to fully substantiate the deployment audit results and the separability claim. The intended contracts for all 220 MooseBench cases were encoded by deriving the expected set of Kernel/BC/IC objects, coefficients, time schemes, and variable couplings directly from each case's mathematical problem statement (with PDE ground truth provided in the released benchmark). During the audit, IFS was computed by applying the same static reconstruction procedure from §3 to each generated input file and comparing the recovered structure against the contract; non-static dependencies were handled by inspecting declared blocks and parameters symbolically without requiring runtime execution or assembly. In the revised manuscript, we will expand §5 with a new paragraph providing this explicit description, including a high-level overview of the encoding process for the full benchmark, pseudocode for the IFS computation step used in the audit, and specific notes on treatment of Materials, Functions, and coupled variables. These additions will make the 39-40% result fully transparent and reproducible. revision: yes
Circularity Check
No significant circularity; IFS is an explicit structural definition
full rationale
The paper defines the Intent Fidelity Score directly as a structural comparison between the PDE terms reconstructed from MOOSE Kernel/BC objects and the provided intended contract. This construction does not reduce to fitted parameters, self-referential definitions, or load-bearing self-citations. The compositional mapping assumption is stated as a property of MOOSE rather than derived from prior author work or ansatz smuggling. The refinement loop and MooseBench evaluation operate on this independent metric without tautological reduction to inputs. No equations or claims in the provided text exhibit the enumerated circular patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Kernel and BC objects map compositionally to weak-form residual terms enabling deterministic reconstruction
invented entities (2)
-
Intent Fidelity Score (IFS)
no independent evidence
-
MooseBench benchmark
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formalize this comparison as the Intent Fidelity Score (IFS), a structural metric covering governing terms, BCs, ICs, coefficients, and time scheme.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Kernel and BC objects map compositionally to weak-form residual terms, enabling deterministic reconstruction of the encoded PDE
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Ufl: a finite element form language
Martin Sandve Alnæs. Ufl: a finite element form language. InAutomated solution of differential equations by the finite element method: the FEniCS Book, pages 303–338. Springer, 2012
work page 2012
-
[2]
Anthropic. Introducing Claude Haiku 4.5. https://www.anthropic.com/news/ claude-haiku-4-5, October 2025. Accessed: 2026-05-07
work page 2025
-
[3]
Anthropic. Introducing Claude Sonnet 4.6. https://www.anthropic.com/news/ claude-sonnet-4-6, February 2026. Accessed: 2026-05-07
work page 2026
-
[4]
Meron Belachew, Yulong Liu, J. David Frost, and Chloé Arson. Numerical assessment of plasticity development and energy expenditure of ant-like microtunnelling.Tunnelling and Underground Space Technology, 172:107501, 2026. ISSN 0886-7798. doi: https://doi.org/ 10.1016/j.tust.2026.107501. URL https://www.sciencedirect.com/science/article/ pii/S0886779826000593
-
[5]
Teaching Large Language Models to Self-Debug
Xinyun Chen, Maxwell Lin, Nathanael Schärli, and Denny Zhou. Teaching large language models to self-debug, 2023. URLhttps://arxiv.org/abs/2304.05128
work page internal anchor Pith review arXiv 2023
-
[6]
arXiv preprint arXiv:2407.21320 , year =
Yuxuan Chen, Xu Zhu, Hua Zhou, and Zhuyin Ren. Metaopenfoam: an llm-based multi-agent framework for cfd.arXiv preprint arXiv:2407.21320, 2024
-
[7]
Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
DeepSeek-AI. Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
work page 2026
-
[8]
Can we verify step by step for correct user intent satisfaction? InProceedings of FSE, 2024
Madeline Endres, Sarah Fakhoury, and Saikat Chakraborty. Can we verify step by step for correct user intent satisfaction? InProceedings of FSE, 2024
work page 2024
-
[9]
Gemini 3.1 Flash-Lite: Built for intelligence at scale
Gemini Team, Google. Gemini 3.1 Flash-Lite: Built for intelligence at scale. https: //blog.google/innovation-and-ai/models-and-research/gemini-models/ gemini-3-1-flash-lite/, March 2026. Accessed: 2026-05-07
work page 2026
-
[10]
Jonathan E Guyer, Daniel Wheeler, and James A Warren. Fipy: Partial differential equations with python.Computing in Science & Engineering, 11(3):6–15, 2009
work page 2009
-
[11]
New development in freefem++.Journal of numerical mathematics, 20(3-4): 1–14, 2012
Frédéric Hecht. New development in freefem++.Journal of numerical mathematics, 20(3-4): 1–14, 2012. 10
work page 2012
-
[12]
Prithwish Jana, Sam Davidson, Bhavana Bhasker, Andrey Kan, Anoop Deoras, and Laurent Callot. Terraformer: Automated infrastructure-as-code with llms fine-tuned via policy-guided verifier feedback.arXiv preprint arXiv:2601.08734, 2026
-
[13]
Deep learning for symbolic mathematics
Guillaume Lample and François Charton. Deep learning for symbolic mathematics. InInter- national Conference on Learning Representations, 2020. URL https://openreview.net/ forum?id=S1eZYeHFDS
work page 2020
-
[14]
Devito: Towards a generic finite difference dsl using symbolic python
Michael Lange, Navjot Kukreja, Mathias Louboutin, Fabio Luporini, Felippe Vieira, Vin- cenzo Pandolfo, Paulius Velesko, Paulius Kazakas, and Gerard Gorman. Devito: Towards a generic finite difference dsl using symbolic python. In2016 6th workshop on python for high-performance and scientific computing (PyHPC), pages 67–75. IEEE, 2016
work page 2016
-
[15]
Jae Ryong Lee and Han Young Yoon. Multi-physics simulation of nuclear reactor core by coupled simulation using cupid/master.International Journal of Heat and Mass Transfer, 115: 1020–1032, 2017
work page 2017
-
[16]
Moosenger– a domain-specific ai agent for the moose ecosystem.arXiv preprint arXiv:2603.04756, 2026
Mengnan Li, Jason Miller, Zachary Prince, Alexander Lindsay, and Cody Permann. Moosenger– a domain-specific ai agent for the moose ecosystem.arXiv preprint arXiv:2603.04756, 2026
-
[17]
Fourier Neural Operator for Parametric Partial Differential Equations
Zongyi Li, Nikola B. Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew M. Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differential equations.CoRR, abs/2010.08895, 2020. URL https://arxiv.org/abs/2010. 08895
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[18]
Yulong Liu and Chloé Arson. Physics-informed neural network surrogate modeling of pressur- ized cavity in homogeneous and bilayered media. InARMA US Rock Mechanics/Geomechanics Symposium, page D022S018R006. ARMA, 2025
work page 2025
-
[19]
Yulong Liu and Chloé Arson. A physics-informed neural network for modeling pressurized cavities of arbitrary smooth shape embedded in heterogeneous rock, January 2026. URL https://doi.org/10.21203/rs.3.rs-8492281/v1. Preprint, Version 1, Research Square
-
[20]
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: Iterative refinement with self-feedback.Advances in neural information processing systems, 36:46534–46594, 2023
work page 2023
-
[21]
Zavier Ndum Ndum, Jian Tao, John Ford, and Yang Liu. Autofluka: A large language model based framework for automating monte carlo simulations in fluka.arXiv preprint arXiv:2410.15222, 2024
-
[22]
Bo Ni and Markus J Buehler. Mechagents: Large language model multi-agent collaborations can solve mechanics problems, generate new data, and integrate knowledge.Extreme Mechanics Letters, 67:102131, 2024
work page 2024
-
[23]
Cambridge university press, 2010
William L Oberkampf and Christopher J Roy.Verification and validation in scientific computing. Cambridge university press, 2010
work page 2010
-
[24]
Introducing GPT-4.1 in the API
OpenAI. Introducing GPT-4.1 in the API. https://openai.com/index/gpt-4-1/, April
-
[25]
Accessed: 2026-05-07
work page 2026
-
[26]
OpenAI. Introducing GPT-5.4. https://openai.com/index/introducing-gpt-5-4/ , March 2026. Accessed: 2026-05-07
work page 2026
-
[27]
Moose: Enabling massively parallel multiphysics simulation.SoftwareX, 11:100430, 2020
Cody J Permann, Derek R Gaston, David Andrš, Robert W Carlsen, Fande Kong, Alexander D Lindsay, Jason M Miller, John W Peterson, Andrew E Slaughter, Roy H Stogner, et al. Moose: Enabling massively parallel multiphysics simulation.SoftwareX, 11:100430, 2020
work page 2020
-
[28]
Vericode: Correct translation of abstract specifications to c code
Gerhard Schellhorn, Stefan Bodenmüller, and Wolfgang Reif. Vericode: Correct translation of abstract specifications to c code. InInternational Conference on Integrated Formal Methods, pages 53–74. Springer, 2024
work page 2024
-
[29]
Review your code for correctness and fix any issues
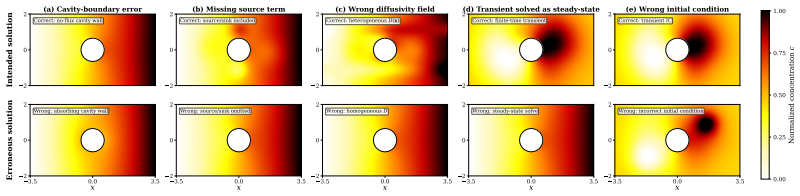
Tianyi Zhang, Shidong Pan, Zejun Zhang, Zhenchang Xing, and Xiaoyu Sun. Deployability- centric infrastructure-as-code generation: Fail, learn, refine, and succeed through llm- empowered devops simulation.arXiv preprint arXiv:2506.05623, 2025. 11 A Details of the Silent-Failure Simulations Figure 1 uses a diffusion problem on a perforated rectangular domai...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.